知识蒸馏DEiT算法实战:使用RegNet蒸馏DEiT模型
摘要
论文翻译:【第58篇】DEiT:通过注意力训练数据高效的图像transformer &蒸馏
DEiT通过引入一个蒸馏token实现蒸馏,蒸馏的方式有两种:
- 1、将蒸馏token作为Teacher标签。两个token通过注意力在transformer中相互作用。实现蒸馏。用法参考:
DEiT实战:使用DEiT实现图像分类任务(一) - 2、通过卷积神经网络去蒸馏蒸馏token,让transformer从卷积神经网络学习一些卷积特征,比如归纳偏置这样的特征。这一点作者也是表示疑问。
这篇文章就是从第二点入手,使用卷积神经网络蒸馏DEiT。
讲解视频:https://www.zhihu.com/zvideo/1588881049425276928
最终结论
先把结论说了吧! Teacher网络使用RegNet的regnetx_160网络,Student网络使用DEiT的deit_tiny_distilled_patch16_224模型。如下表
| 网络 | epochs | ACC |
|---|---|---|
| DEiT | 100 | 94% |
| RegNet | 100 | 96% |
| DEiT+Hard | 100 | 95% |
项目结构
DeiT_dist_demo├─data│ ├─train│ │ ├─Black-grass│ │ ├─Charlock│ │ ├─Cleavers│ │ ├─Common Chickweed│ │ ├─Common wheat│ │ ├─Fat Hen│ │ ├─Loose Silky-bent│ │ ├─Maize│ │ ├─Scentless Mayweed│ │ ├─Shepherds Purse│ │ ├─Small-flowered Cranesbill│ │ └─Sugar beet│ └─val│ ├─Black-grass│ ├─Charlock│ ├─Cleavers│ ├─Common Chickweed│ ├─Common wheat│ ├─Fat Hen│ ├─Loose Silky-bent│ ├─Maize│ ├─Scentless Mayweed│ ├─Shepherds Purse│ ├─Small-flowered Cranesbill│ └─Sugar beet├─models│ └─models.py├─losses.py├─teacher_train.py├─student_train.py├─train_kd.py└─test.pydata:数据集,分为train和val。
models:存放模型文件。
losses.py:loss文件,计算外部蒸馏loss。
teacher_train.py:训练Teacher模型
student_train.py:训练Student模型
train_kd.py:训练蒸馏模型
test:测试结果。
模型和loss
模型模型models.py和loss脚本losses.py需要从官方模型获取,链接:https://github.com/facebookresearch/deit。
model.py代码
# Copyright (c) 2015-present, Facebook, Inc.# All rights reserved.import torchimport torch.nn as nnfrom functools import partialfrom timm.models.vision_transformer import VisionTransformer, _cfgfrom timm.models.registry import register_modelfrom timm.models.layers import trunc_normal___all__ = [ 'deit_tiny_patch16_224', 'deit_small_patch16_224', 'deit_base_patch16_224', 'deit_tiny_distilled_patch16_224', 'deit_small_distilled_patch16_224', 'deit_base_distilled_patch16_224', 'deit_base_patch16_384', 'deit_base_distilled_patch16_384',]class DistilledVisionTransformer(VisionTransformer): def __init__(self, *args, kwargs): super().__init__(*args, kwargs) self.dist_token = nn.Parameter(torch.zeros(1, 1, self.embed_dim)) num_patches = self.patch_embed.num_patches self.pos_embed = nn.Parameter(torch.zeros(1, num_patches + 2, self.embed_dim)) self.head_dist = nn.Linear(self.embed_dim, self.num_classes) if self.num_classes > 0 else nn.Identity() trunc_normal_(self.dist_token, std=.02) trunc_normal_(self.pos_embed, std=.02) self.head_dist.apply(self._init_weights) def forward_features(self, x): # taken from https://github.com/rwightman/pytorch-image-models/blob/master/timm/models/vision_transformer.py # with slight modifications to add the dist_token B = x.shape[0] x = self.patch_embed(x) cls_tokens = self.cls_token.expand(B, -1, -1) # stole cls_tokens impl from Phil Wang, thanks dist_token = self.dist_token.expand(B, -1, -1) x = torch.cat((cls_tokens, dist_token, x), dim=1) x = x + self.pos_embed x = self.pos_drop(x) for blk in self.blocks: x = blk(x) x = self.norm(x) return x[:, 0], x[:, 1] def forward(self, x): x, x_dist = self.forward_features(x) x = self.head(x) x_dist = self.head_dist(x_dist) if self.training: return x, x_dist else: # during inference, return the average of both classifier predictions return (x + x_dist) / 2@register_modeldef deit_tiny_patch16_224(pretrained=False, kwargs): model = VisionTransformer( patch_size=16, embed_dim=192, depth=12, num_heads=3, mlp_ratio=4, qkv_bias=True, norm_layer=partial(nn.LayerNorm, eps=1e-6), kwargs) model.default_cfg = _cfg() if pretrained: checkpoint = torch.hub.load_state_dict_from_url( url="https://dl.fbaipublicfiles.com/deit/deit_tiny_patch16_224-a1311bcf.pth", map_location="cpu", check_hash=True ) model.load_state_dict(checkpoint["model"]) return model@register_modeldef deit_small_patch16_224(pretrained=False, kwargs): model = VisionTransformer( patch_size=16, embed_dim=384, depth=12, num_heads=6, mlp_ratio=4, qkv_bias=True, norm_layer=partial(nn.LayerNorm, eps=1e-6), kwargs) model.default_cfg = _cfg() if pretrained: checkpoint = torch.hub.load_state_dict_from_url( url="https://dl.fbaipublicfiles.com/deit/deit_small_patch16_224-cd65a155.pth", map_location="cpu", check_hash=True ) model.load_state_dict(checkpoint["model"]) return model@register_modeldef deit_base_patch16_224(pretrained=False, kwargs): model = VisionTransformer( patch_size=16, embed_dim=768, depth=12, num_heads=12, mlp_ratio=4, qkv_bias=True, norm_layer=partial(nn.LayerNorm, eps=1e-6), kwargs) model.default_cfg = _cfg() if pretrained: checkpoint = torch.hub.load_state_dict_from_url( url="https://dl.fbaipublicfiles.com/deit/deit_base_patch16_224-b5f2ef4d.pth", map_location="cpu", check_hash=True ) model.load_state_dict(checkpoint["model"]) return model@register_modeldef deit_tiny_distilled_patch16_224(pretrained=False, kwargs): model = DistilledVisionTransformer( patch_size=16, embed_dim=192, depth=12, num_heads=3, mlp_ratio=4, qkv_bias=True, norm_layer=partial(nn.LayerNorm, eps=1e-6), kwargs) model.default_cfg = _cfg() print(model.default_cfg) if pretrained: checkpoint = torch.hub.load_state_dict_from_url( url="https://dl.fbaipublicfiles.com/deit/deit_tiny_distilled_patch16_224-b40b3cf7.pth", map_location="cpu", check_hash=True ) model.load_state_dict(checkpoint["model"]) return model@register_modeldef deit_small_distilled_patch16_224(pretrained=False, kwargs): model = DistilledVisionTransformer( patch_size=16, embed_dim=384, depth=12, num_heads=6, mlp_ratio=4, qkv_bias=True, norm_layer=partial(nn.LayerNorm, eps=1e-6), kwargs) model.default_cfg = _cfg() if pretrained: checkpoint = torch.hub.load_state_dict_from_url( url="https://dl.fbaipublicfiles.com/deit/deit_small_distilled_patch16_224-649709d9.pth", map_location="cpu", check_hash=True ) model.load_state_dict(checkpoint["model"]) return model@register_modeldef deit_base_distilled_patch16_224(pretrained=False, kwargs): model = DistilledVisionTransformer( patch_size=16, embed_dim=768, depth=12, num_heads=12, mlp_ratio=4, qkv_bias=True, norm_layer=partial(nn.LayerNorm, eps=1e-6), kwargs) model.default_cfg = _cfg() if pretrained: checkpoint = torch.hub.load_state_dict_from_url( url="https://dl.fbaipublicfiles.com/deit/deit_base_distilled_patch16_224-df68dfff.pth", map_location="cpu", check_hash=True ) model.load_state_dict(checkpoint["model"]) return model@register_modeldef deit_base_patch16_384(pretrained=False, kwargs): model = VisionTransformer( img_size=384, patch_size=16, embed_dim=768, depth=12, num_heads=12, mlp_ratio=4, qkv_bias=True, norm_layer=partial(nn.LayerNorm, eps=1e-6), kwargs) model.default_cfg = _cfg() if pretrained: checkpoint = torch.hub.load_state_dict_from_url( url="https://dl.fbaipublicfiles.com/deit/deit_base_patch16_384-8de9b5d1.pth", map_location="cpu", check_hash=True ) model.load_state_dict(checkpoint["model"]) return model@register_modeldef deit_base_distilled_patch16_384(pretrained=False, kwargs): model = DistilledVisionTransformer( img_size=384, patch_size=16, embed_dim=768, depth=12, num_heads=12, mlp_ratio=4, qkv_bias=True, norm_layer=partial(nn.LayerNorm, eps=1e-6), kwargs) model.default_cfg = _cfg() if pretrained: checkpoint = torch.hub.load_state_dict_from_url( url="https://dl.fbaipublicfiles.com/deit/deit_base_distilled_patch16_384-d0272ac0.pth", map_location="cpu", check_hash=True ) model.load_state_dict(checkpoint["model"]) return modellosses.py代码
# Copyright (c) 2015-present, Facebook, Inc.# All rights reserved."""Implements the knowledge distillation loss"""import torchfrom torch.nn import functional as Fclass DistillationLoss(torch.nn.Module): """ This module wraps a standard criterion and adds an extra knowledge distillation loss by taking a teacher model prediction and using it as additional supervision. """ def __init__(self, base_criterion: torch.nn.Module, teacher_model: torch.nn.Module, distillation_type: str, alpha: float, tau: float): super().__init__() self.base_criterion = base_criterion self.teacher_model = teacher_model assert distillation_type in ['none', 'soft', 'hard'] self.distillation_type = distillation_type self.alpha = alpha self.tau = tau def forward(self, inputs, outputs, labels): """ Args: inputs: The original inputs that are feed to the teacher model outputs: the outputs of the model to be trained. It is expected to be either a Tensor, or a Tuple[Tensor, Tensor], with the original output in the first position and the distillation predictions as the second output labels: the labels for the base criterion """ outputs_kd = None if not isinstance(outputs, torch.Tensor): # assume that the model outputs a tuple of [outputs, outputs_kd] outputs, outputs_kd = outputs base_loss = self.base_criterion(outputs, labels) if self.distillation_type == 'none': return base_loss if outputs_kd is None: raise ValueError("When knowledge distillation is enabled, the model is " "expected to return a Tuple[Tensor, Tensor] with the output of the " "class_token and the dist_token") # don't backprop throught the teacher with torch.no_grad(): teacher_outputs = self.teacher_model(inputs) if self.distillation_type == 'soft': T = self.tau # taken from https://github.com/peterliht/knowledge-distillation-pytorch/blob/master/model/net.py#L100 # with slight modifications distillation_loss = F.kl_div( F.log_softmax(outputs_kd / T, dim=1), #We provide the teacher's targets in log probability because we use log_target=True #(as recommended in pytorch https://github.com/pytorch/pytorch/blob/9324181d0ac7b4f7949a574dbc3e8be30abe7041/torch/nn/functional.py#L2719) #but it is possible to give just the probabilities and set log_target=False. In our experiments we tried both. F.log_softmax(teacher_outputs / T, dim=1), reduction='sum', log_target=True ) * (T * T) / outputs_kd.numel() #We divide by outputs_kd.numel() to have the legacy PyTorch behavior. #But we also experiments output_kd.size(0) #see issue 61(https://github.com/facebookresearch/deit/issues/61) for more details elif self.distillation_type == 'hard': distillation_loss = F.cross_entropy(outputs_kd, teacher_outputs.argmax(dim=1)) loss = base_loss * (1 - self.alpha) + distillation_loss * self.alpha return loss训练Teacher模型
Teacher选用regnetx_160,这个模型的预训练模型比较大,如果不能直接下来,可以借助下载工具,比如某雷下载。
步骤
新建teacher_train.py,插入代码:
导入需要的库
import torch.optim as optimimport torchimport torch.nn as nnimport torch.nn.parallelimport torch.utils.dataimport torch.utils.data.distributedimport torchvision.transforms as transformsfrom torchvision import datasetsfrom torch.autograd import Variablefrom timm.models import regnetx_160import jsonimport os# 定义训练过程定义训练和验证函数
# 设置随机因子def seed_everything(seed=42): os.environ['PYHTONHASHSEED'] = str(seed) torch.manual_seed(seed) torch.cuda.manual_seed(seed) torch.backends.cudnn.deterministic = True# 训练函数def train(model, device, train_loader, optimizer, epoch): model.train() sum_loss = 0 total_num = len(train_loader.dataset) print(total_num, len(train_loader)) for batch_idx, (data, target) in enumerate(train_loader): data, target = Variable(data).to(device), Variable(target).to(device) out = model(data) loss = criterion(out, target) optimizer.zero_grad() loss.backward() optimizer.step() print_loss = loss.data.item() sum_loss += print_loss if (batch_idx + 1) % 10 == 0: print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format( epoch, (batch_idx + 1) * len(data), len(train_loader.dataset), 100. * (batch_idx + 1) / len(train_loader), loss.item())) ave_loss = sum_loss / len(train_loader) print('epoch:{},loss:{}'.format(epoch, ave_loss))Best_ACC=0# 验证过程@torch.no_grad()def val(model, device, test_loader): global Best_ACC model.eval() test_loss = 0 correct = 0 total_num = len(test_loader.dataset) print(total_num, len(test_loader)) with torch.no_grad(): for data, target in test_loader: data, target = Variable(data).to(device), Variable(target).to(device) out = model(data) loss = criterion(out, target) _, pred = torch.max(out.data, 1) correct += torch.sum(pred == target) print_loss = loss.data.item() test_loss += print_loss correct = correct.data.item() acc = correct / total_num avgloss = test_loss / len(test_loader) if acc > Best_ACC: torch.save(model, file_dir + '/' + 'best.pth') Best_ACC = acc print('\nVal set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format( avgloss, correct, len(test_loader.dataset), 100 * acc)) return acc定义全局参数
if __name__ == '__main__': # 创建保存模型的文件夹 file_dir = 'TeacherModel' if os.path.exists(file_dir): print('true') os.makedirs(file_dir, exist_ok=True) else: os.makedirs(file_dir) # 设置全局参数 modellr = 1e-4 BATCH_SIZE = 16 EPOCHS = 100 DEVICE = torch.device('cuda' if torch.cuda.is_available() else 'cpu') SEED=42 seed_everything(SEED)图像预处理与增强
# 数据预处理7 transform = transforms.Compose([ transforms.RandomRotation(10), transforms.GaussianBlur(kernel_size=(5, 5), sigma=(0.1, 3.0)), transforms.ColorJitter(brightness=0.5, contrast=0.5, saturation=0.5), transforms.Resize((224, 224)), transforms.ToTensor(), transforms.Normalize(mean=[0.44127703, 0.4712498, 0.43714803], std=[0.18507297, 0.18050247, 0.16784933]) ]) transform_test = transforms.Compose([ transforms.Resize((224, 224)), transforms.ToTensor(), transforms.Normalize(mean=[0.44127703, 0.4712498, 0.43714803], std=[0.18507297, 0.18050247, 0.16784933]) ])读取数据
使用pytorch默认读取数据的方式。
# 读取数据 dataset_train = datasets.ImageFolder('data/train', transform=transform) dataset_test = datasets.ImageFolder("data/val", transform=transform_test) with open('class.txt', 'w') as file: file.write(str(dataset_train.class_to_idx)) with open('class.json', 'w', encoding='utf-8') as file: file.write(json.dumps(dataset_train.class_to_idx)) # 导入数据 train_loader = torch.utils.data.DataLoader(dataset_train, batch_size=BATCH_SIZE, shuffle=True) test_loader = torch.utils.data.DataLoader(dataset_test, batch_size=BATCH_SIZE, shuffle=False)设置模型和Loss
# 实例化模型并且移动到GPU criterion = nn.CrossEntropyLoss() model_ft = regnetx_160(pretrained=True) model_ft.reset_classifier(num_classes=12) model_ft.to(DEVICE) # 选择简单暴力的Adam优化器,学习率调低 optimizer = optim.Adam(model_ft.parameters(), lr=modellr) cosine_schedule = optim.lr_scheduler.CosineAnnealingLR(optimizer=optimizer, T_max=20, eta_min=1e-9) # 训练 val_acc_list= {} for epoch in range(1, EPOCHS + 1): train(model_ft, DEVICE, train_loader, optimizer, epoch) cosine_schedule.step() acc=val(model_ft, DEVICE, test_loader) val_acc_list[epoch]=acc with open('result.json', 'w', encoding='utf-8') as file: file.write(json.dumps(val_acc_list)) torch.save(model_ft, 'TeacherModel/model_final.pth')完成上面的代码就可以开始训练Teacher网络了。
学生网络
学生网络选用deit_tiny_distilled_patch16_224,是一个比较小一点的网络了,模型的大小有20M。训练100个epoch。
步骤
新建student_train.py,插入代码:
导入需要的库
import torch.optim as optimimport torchimport torch.nn as nnimport torch.nn.parallelimport torch.utils.dataimport torch.utils.data.distributedimport torchvision.transforms as transformsfrom torchvision import datasetsfrom torch.autograd import Variablefrom models.models import deit_tiny_distilled_patch16_224import jsonimport os定义训练和验证函数
# 设置随机因子def seed_everything(seed=42): os.environ['PYHTONHASHSEED'] = str(seed) torch.manual_seed(seed) torch.cuda.manual_seed(seed) torch.backends.cudnn.deterministic = True# 定义训练过程def train(model, device, train_loader, optimizer, epoch): model.train() sum_loss = 0 total_num = len(train_loader.dataset) print(total_num, len(train_loader)) for batch_idx, (data, target) in enumerate(train_loader): data, target = Variable(data).to(device), Variable(target).to(device) out = model(data)[0] loss = criterion(out, target) optimizer.zero_grad() loss.backward() optimizer.step() print_loss = loss.data.item() sum_loss += print_loss if (batch_idx + 1) % 10 == 0: print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format( epoch, (batch_idx + 1) * len(data), len(train_loader.dataset), 100. * (batch_idx + 1) / len(train_loader), loss.item())) ave_loss = sum_loss / len(train_loader) print('epoch:{},loss:{}'.format(epoch, ave_loss))Best_ACC=0# 验证过程@torch.no_grad()def val(model, device, test_loader): global Best_ACC model.eval() test_loss = 0 correct = 0 total_num = len(test_loader.dataset) print(total_num, len(test_loader)) with torch.no_grad(): for data, target in test_loader: data, target = Variable(data).to(device), Variable(target).to(device) out = model(data) loss = criterion(out, target) _, pred = torch.max(out.data, 1) correct += torch.sum(pred == target) print_loss = loss.data.item() test_loss += print_loss correct = correct.data.item() acc = correct / total_num avgloss = test_loss / len(test_loader) if acc > Best_ACC: torch.save(model, file_dir + '/' + 'best.pth') Best_ACC = acc print('\nVal set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format( avgloss, correct, len(test_loader.dataset), 100 * acc)) return acc这里要注意一点,由于我们使用的官方的模型,在做正常的训练时,返回值有两个,分别是x和x_dist。
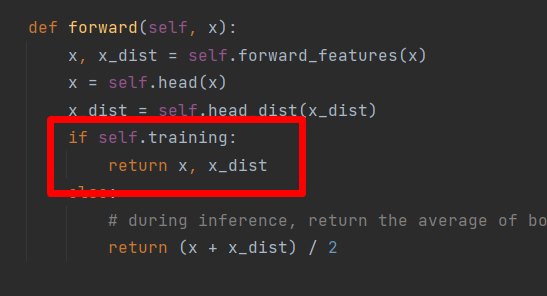
loss计算只需前一个值,即:
out = model(data)[0]在验证的时候,返回一个值。所以不用做上面的操作了,即:
out = model(data)定义全局参数
if __name__ == '__main__': # 创建保存模型的文件夹 file_dir = 'StudentModel' if os.path.exists(file_dir): print('true') os.makedirs(file_dir, exist_ok=True) else: os.makedirs(file_dir) # 设置全局参数 modellr = 1e-4 BATCH_SIZE = 16 EPOCHS = 100 DEVICE = torch.device('cuda' if torch.cuda.is_available() else 'cpu') SEED=42 seed_everything(SEED)图像预处理与增强
# 数据预处理7 transform = transforms.Compose([ transforms.RandomRotation(10), transforms.GaussianBlur(kernel_size=(5, 5), sigma=(0.1, 3.0)), transforms.ColorJitter(brightness=0.5, contrast=0.5, saturation=0.5), transforms.Resize((224, 224)), transforms.ToTensor(), transforms.Normalize(mean=[0.44127703, 0.4712498, 0.43714803], std=[0.18507297, 0.18050247, 0.16784933]) ]) transform_test = transforms.Compose([ transforms.Resize((224, 224)), transforms.ToTensor(), transforms.Normalize(mean=[0.44127703, 0.4712498, 0.43714803], std=[0.18507297, 0.18050247, 0.16784933]) ])读取数据
使用pytorch默认读取数据的方式。
# 读取数据 dataset_train = datasets.ImageFolder('data/train', transform=transform) dataset_test = datasets.ImageFolder("data/val", transform=transform_test) with open('class.txt', 'w') as file: file.write(str(dataset_train.class_to_idx)) with open('class.json', 'w', encoding='utf-8') as file: file.write(json.dumps(dataset_train.class_to_idx)) # 导入数据 train_loader = torch.utils.data.DataLoader(dataset_train, batch_size=BATCH_SIZE, shuffle=True) test_loader = torch.utils.data.DataLoader(dataset_test, batch_size=BATCH_SIZE, shuffle=False)设置模型和Loss
# 实例化模型并且移动到GPU criterion = nn.CrossEntropyLoss() model_ft = deit_tiny_distilled_patch16_224(pretrained=True) num_ftrs = model_ft.head.in_features model_ft.head = nn.Linear(num_ftrs, 12) num_ftrs_dist = model_ft.head_dist.in_features model_ft.head_dist = nn.Linear(num_ftrs_dist, 12) print(model_ft) model_ft.to(DEVICE) # 选择简单暴力的Adam优化器,学习率调低 optimizer = optim.Adam(model_ft.parameters(), lr=modellr) cosine_schedule = optim.lr_scheduler.CosineAnnealingLR(optimizer=optimizer, T_max=20, eta_min=1e-9) # 训练 val_acc_list= {} for epoch in range(1, EPOCHS + 1): train(model_ft, DEVICE, train_loader, optimizer, epoch) cosine_schedule.step() acc=val(model_ft, DEVICE, test_loader) val_acc_list[epoch]=acc with open('result_student.json', 'w', encoding='utf-8') as file: file.write(json.dumps(val_acc_list)) torch.save(model_ft, 'StudentModel/model_final.pth')完成上面的代码就可以开始训练Student网络了。
蒸馏学生网络
学生网络继续选用deit_tiny_distilled_patch16_224,使用Teacher网络蒸馏学生网络,训练100个epoch。
步骤
新建train_kd.py.py,插入代码:
导入需要的库
import torch.optim as optimimport torchimport torch.nn as nnimport torch.nn.parallelimport torch.utils.dataimport torch.utils.data.distributedimport torchvision.transforms as transformsfrom timm.loss import LabelSmoothingCrossEntropyfrom torchvision import datasetsfrom models.models import deit_tiny_distilled_patch16_224import jsonimport osfrom losses import DistillationLoss定义训练和验证函数
# 设置随机因子def seed_everything(seed=42): os.environ['PYHTONHASHSEED'] = str(seed) torch.manual_seed(seed) torch.cuda.manual_seed(seed) torch.backends.cudnn.deterministic = True # 定义训练过程def train(s_net,t_net, device,criterionKD,train_loader, optimizer, epoch): s_net.train() sum_loss = 0 total_num = len(train_loader.dataset) print(total_num, len(train_loader)) for batch_idx, (data, target) in enumerate(train_loader): data, target = data.to(device), target.to(device) optimizer.zero_grad() out_s = s_net(data) loss = criterionKD(data,out_s, target) loss.backward() optimizer.step() print_loss = loss.data.item() sum_loss += print_loss if (batch_idx + 1) % 10 == 0: print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format( epoch, (batch_idx + 1) * len(data), len(train_loader.dataset), 100. * (batch_idx + 1) / len(train_loader), loss.item())) ave_loss = sum_loss / len(train_loader) print('epoch:{},loss:{}'.format(epoch, ave_loss))Best_ACC=0# 验证过程@torch.no_grad()def val(model, device,criterionCls, test_loader): global Best_ACC model.eval() test_loss = 0 correct = 0 total_num = len(test_loader.dataset) print(total_num, len(test_loader)) with torch.no_grad(): for data, target in test_loader: data, target = data.to(device), target.to(device) out_s = model(data) loss = criterionCls(out_s, target) _, pred = torch.max(out_s.data, 1) correct += torch.sum(pred == target) print_loss = loss.data.item() test_loss += print_loss correct = correct.data.item() acc = correct / total_num avgloss = test_loss / len(test_loader) if acc > Best_ACC: torch.save(model, file_dir + '/' + 'best.pth') Best_ACC = acc print('\nVal set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format( avgloss, correct, len(test_loader.dataset), 100 * acc)) return acc定义全局参数
if __name__ == '__main__': # 创建保存模型的文件夹 file_dir = 'KDModel' if os.path.exists(file_dir): print('true') os.makedirs(file_dir, exist_ok=True) else: os.makedirs(file_dir) # 设置全局参数 modellr = 1e-4 BATCH_SIZE = 4 EPOCHS = 100 DEVICE = torch.device('cuda' if torch.cuda.is_available() else 'cpu') SEED=42 seed_everything(SEED) distillation_type='hard' #['none', 'soft', 'hard'] distillation_alpha=0.5 distillation_tau=1.0distillation_type:蒸馏的类型,本文选用hard。
distillation_alpha:α系数,蒸馏loss的权重系数。
distillation_tau:T,蒸馏温度的意思。
图像预处理与增强
# 数据预处理7 transform = transforms.Compose([ transforms.RandomRotation(10), transforms.GaussianBlur(kernel_size=(5, 5), sigma=(0.1, 3.0)), transforms.ColorJitter(brightness=0.5, contrast=0.5, saturation=0.5), transforms.Resize((224, 224)), transforms.ToTensor(), transforms.Normalize(mean=[0.44127703, 0.4712498, 0.43714803], std=[0.18507297, 0.18050247, 0.16784933]) ]) transform_test = transforms.Compose([ transforms.Resize((224, 224)), transforms.ToTensor(), transforms.Normalize(mean=[0.44127703, 0.4712498, 0.43714803], std=[0.18507297, 0.18050247, 0.16784933]) ])读取数据
使用pytorch默认读取数据的方式。
# 读取数据 dataset_train = datasets.ImageFolder('data/train', transform=transform) dataset_test = datasets.ImageFolder("data/val", transform=transform_test) with open('class.txt', 'w') as file: file.write(str(dataset_train.class_to_idx)) with open('class.json', 'w', encoding='utf-8') as file: file.write(json.dumps(dataset_train.class_to_idx)) # 导入数据 train_loader = torch.utils.data.DataLoader(dataset_train, batch_size=BATCH_SIZE, shuffle=True) test_loader = torch.utils.data.DataLoader(dataset_test, batch_size=BATCH_SIZE, shuffle=False)设置模型和Loss
model_ft = deit_tiny_distilled_patch16_224(pretrained=True) num_ftrs = model_ft.head.in_features model_ft.head = nn.Linear(num_ftrs, 12) num_ftrs_dist = model_ft.head_dist.in_features model_ft.head_dist = nn.Linear(num_ftrs_dist, 12) print(model_ft) model_ft.to(DEVICE) # 选择简单暴力的Adam优化器,学习率调低 optimizer = optim.Adam(model_ft.parameters(), lr=modellr) cosine_schedule = optim.lr_scheduler.CosineAnnealingLR(optimizer=optimizer, T_max=20, eta_min=1e-9) teacher_model=torch.load('TeacherModel/best.pth') teacher_model.eval() # 实例化模型并且移动到GPU criterion = LabelSmoothingCrossEntropy(smoothing=0.1) criterionKD = DistillationLoss( criterion, teacher_model, distillation_type, distillation_alpha, distillation_tau ) criterionCls = nn.CrossEntropyLoss() # 训练 val_acc_list= {} for epoch in range(1, EPOCHS + 1): train(model_ft,teacher_model, DEVICE,criterionKD, train_loader, optimizer, epoch) cosine_schedule.step() acc=val(model_ft,DEVICE,criterionCls , test_loader) val_acc_list[epoch]=acc with open('result_kd.json', 'w', encoding='utf-8') as file: file.write(json.dumps(val_acc_list)) torch.save(model_ft, 'KDModel/model_final.pth')完成上面的代码就可以开始蒸馏模式!!!
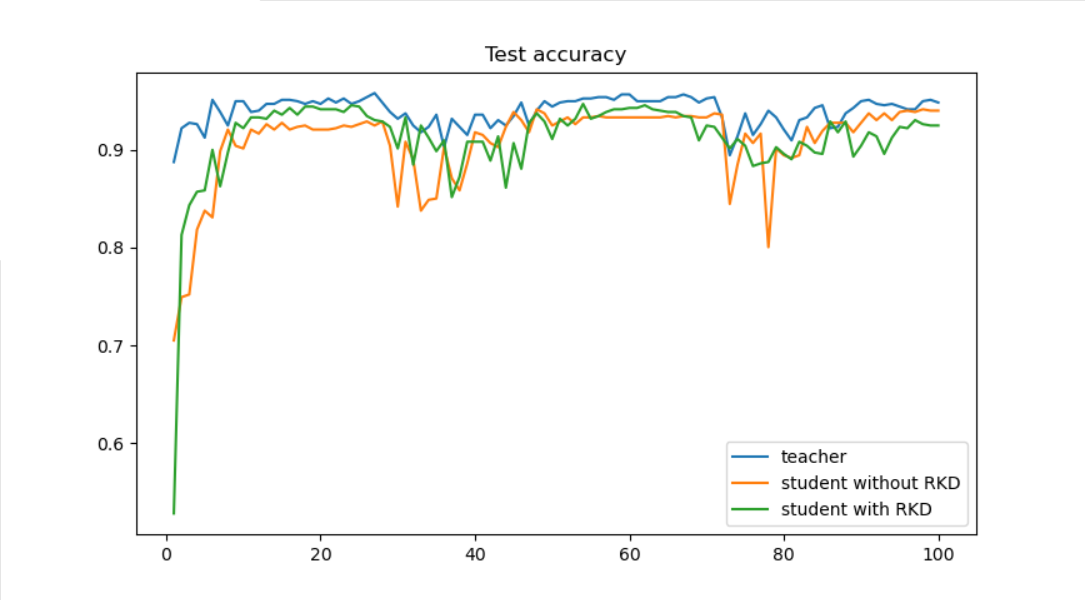
结果比对
加载保存的结果,然后绘制acc曲线。
import numpy as npfrom matplotlib import pyplot as pltimport jsonteacher_file='result.json'student_file='result_student.json'student_kd_file='result_kd.json'def read_json(file): with open(file, 'r', encoding='utf8') as fp: json_data = json.load(fp) print(json_data) return json_datateacher_data=read_json(teacher_file)student_data=read_json(student_file)student_kd_data=read_json(student_kd_file)x =[int(x) for x in list(dict(teacher_data).keys())]print(x)plt.plot(x, list(teacher_data.values()), label='teacher')plt.plot(x,list(student_data.values()), label='student without IRG')plt.plot(x, list(student_kd_data.values()), label='student with IRG')plt.title('Test accuracy')plt.legend()plt.show()
总结
本文重点讲解了如何使用外部模型蒸馏算法对DeiT模型进行蒸馏。希望能帮助到大家,如果觉得有用欢迎收藏、点赞和转发;如果有问题也可以留言讨论。
本次实战用到的代码和数据集详见:
https://download.csdn.net/download/hhhhhhhhhhwwwwwwwwww/87323531

