基于声学模型共享的零资源韩语识别系统
声学模型共享方法是极低资源小语种语音识别一种解决方案,能够实现不需要任何语音数据的语音识别。本文介绍清华大学语音与音频技术实验室的零资源韩语语音系统,其在不使用任何韩语语音数据的情况下,在Zeroth韩语数据集上的测试CER达到了27.33%。
01 声学模型共享与零资源ASR
小语种语音识别一直是语音领域值得关注的问题之一,几千种小语种普遍面临着训练数据不足、收集训练数据困难等问题,而声学模型共享方法则可以实现不需训练数据的语音识别,从而为这一问题提供了一个方向。这一方法利用语种之间的相似性,直接使用常见语言的声学模型,结合低资源语言的语言模型、发音字典以及两种语言之间的音素映射关系等专家知识,就可以构建较为精准的语音识别系统。
我们将声学模型共享方法扩展到了零资源韩语语音识别上。我们使用Kaldi工具包,利用汉语训练声学模型,根据汉语和韩语两种语言之间的音素相似性设置了两种不同的音素映射方案,并比较了不同方案的优劣。实验结果表明,我们的系统可以在不使用任何韩语训练数据的情况下达到27.33%的CER。
02 韩语的声学模型共享
在书写上,韩语是一种表音文字,其书写体系中的符号与音素存在着紧密的对应关系。在发音上,韩语是一种音节语言,一个韩语音节由一个元音(中声),元音前的一个可选的辅音(初声)和元音后的一个可选的辅音(终声)构成。韩语包含19个辅音和21个元音。在韩语中,根据上下文的不同,音素可能被替换、删除或是添加,两个相邻的音素可能会发生合并,因此即使韩语是完全的表音文字,一个句子的字面内容和其发音仍可能存在不同。
为了实现声学模型共享,我们需要建立韩语和汉语之间的音素对应关系。一种方法是将汉语词用韩语音素表示(zh2kr)。这种方法在训练过程中就引入音素对应关系,训练集中的汉语被转写为相近的韩语音素,而得到的模型可以被视为一个用汉语语音学习得到的韩语语音识别模型。

汉语音素到韩语音素的对应关系(部分)
另一种方法是将韩语词用汉语音素表示(kr2zh)。这种方法是在声学模型训练完成后引入音素对应关系。通过修改发音词典,将韩语词统一表示为相近的汉语音素,使用汉语正常训练的声学模型就可以用来识别韩语。

韩语音素到汉语音素的对应关系(部分)
03 实验设置与结果
我们使用Aishell1数据集训练汉语声学模型,测试集则选用Zeroth开源韩语数据集的测试集。声学模型结构方面,我们使用了11层TDNN,输入为40维MFCC特征;语言模型方面,我们使用Zeroth训练集文本训练了3-gram语言模型。我们的基线系统是使用Zeroth的90小时韩语数据训练得到的相同结构的TDNN模型。
实验结果表明,尽管与使用充足有标注数据训练的ASR模型仍有较大差距,我们的零资源语音识别模型仍能实现较低的错误率。另外,相比kr2zh方法,zh2kr方法的精度有大幅度的下降。
我们认为,这是由于zh2kr方法需要为汉语中存在而韩语中不存在的音素指定近似的对应关系,这使得模型学习到的韩语音素对应的汉语声学特征与测试集中真正的韩语声学特征的分布有较大差异,这些人工引入的额外的领域漂移影响了最终的识别效果。
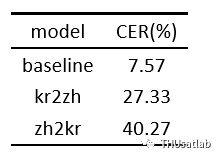
不同映射方法与有监督方法的比较。零资源方法能达到较低的CER,而kr2zh方法要优于zh2kr方法
我们的方法将无监督预训练模型应用于零资源语音识别任务,在不使用目标语种的任何语音数据的情况下实现了平均33%的WER。在无训练数据或可获得的训练数据小于10小时的情况下,我们的零资源方法相比有监督方法有较大优势。
作者简介
王皓宇,清华大学电子工程系语音与音频技术实验室研究生二年级学生,主要研究方向为低资源语音识别和预训练模型蒸馏。

