datax的使用
目录
- 简介
- 语法
- Support Data Channels
- 1.MysqlReader
- 2.MysqlWriter
- 3.HdfsReader
- 4.HdfsWriter
- DataX安装部署及测试
- 1.下载压缩包
- 2.安装
- 3.测试
- 使用DataX将mysql数据导入到oracle中
- 1.配置json
- 2.cmd执行
- DataX常用Job样例
- 1.hdfs2mysql
- 2.hdfs2mysql
正文
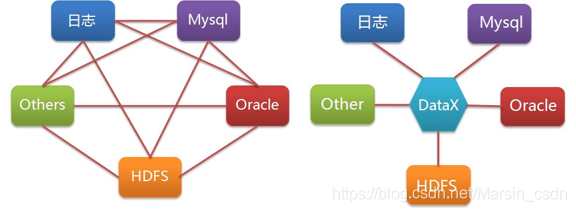
简介
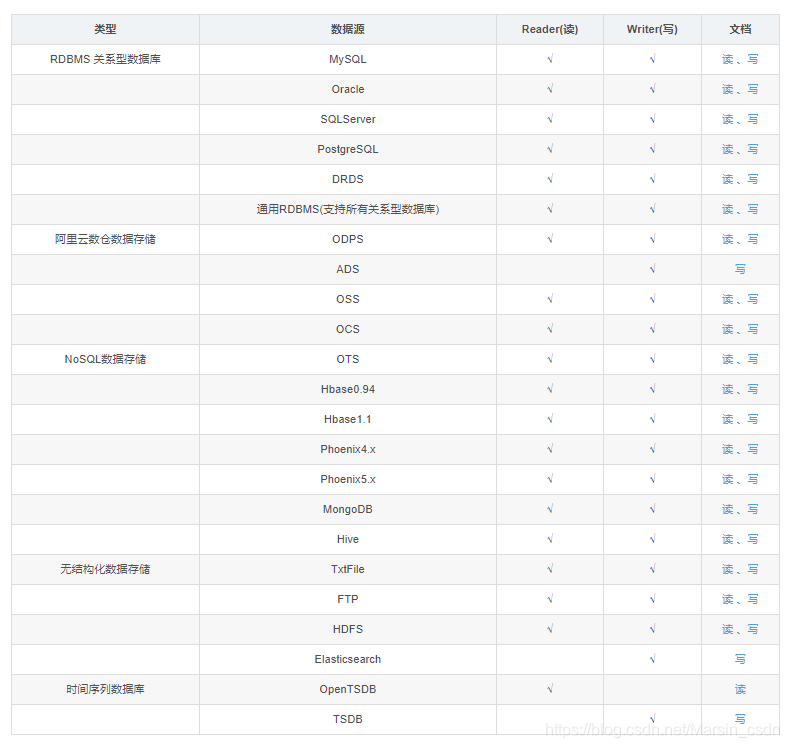
DataX 是阿里巴巴集团内被广泛使用的离线数据同步工具/平台,实现包括 MySQL、Oracle、HDFS、Hive、OceanBase、HBase、OTS、ODPS 等各种异构数据源之间高效的数据同步功能。DataX采用了框架 + 插件 的模式,目前已开源,代码托管在github。
语法
DataX本身作为离线数据同步框架,采用Framework + plugin架构构建。将数据源读取和写入抽象成为Reader/Writer插件,纳入到整个同步框架中。
-
Reader:Reader为数据采集模块,负责采集数据源的数据,将数据发送给Framework。
"reader": {"name": "mysqlreader", #从mysql数据库获取数据(也支持sqlserverreader,oraclereader)"name": "txtfilereader", #从本地获取数据"name": "hdfsreader", #从hdfs文件、hive表获取数据"name": "streamreader", #从stream流获取数据(常用于测试)"name": "httpreader", #从http URL获取数据} -
Writer: Writer为数据写入模块,负责不断向Framework取数据,并将数据写入到目的端。
"writer": { "name":"hdfswriter", #向hdfs,hive表写入数据 "name":"mysqlwriter ", #向mysql写入数据(也支持sqlserverwriter,oraclewriter) "name":"streamwriter ", #向stream流写入数据。(常用于测试) } -
Framework:Framework用于连接reader和writer,作为两者的数据传输通道,并处理缓冲,流控,并发,数据转换等核心技术问题。
Support Data Channels
MysqlReader
回到顶部
{"job": {"setting": {"speed": {"channel": 3},"errorLimit": {"record": 0,"percentage": 0.02}},"content": [{"reader": {"name": "mysqlreader","parameter": {"username": "root","password": "","column": ["id","name"],"splitPk": "db_id","connection": [{"table": ["table"],"jdbcUrl": ["jdbc:mysql://127.0.0.1:3306/database"]}]}},"writer": {"name": "streamwriter","parameter": {"print": true}}}]}}{"job": {"setting": {"speed": {"channel": 1}},"content": [{"reader": {"name": "mysqlreader","parameter": {"username": "root","password": "","connection": [{"querySql": ["select db_id,on_line_flag from db_info where db_id < 10;"],"jdbcUrl": ["jdbc:mysql://bad_ip:3306/database", "jdbc:mysql://127.0.0.1:bad_port/database", "jdbc:mysql://127.0.0.1:3306/database"]}]}},"writer": {"name": "streamwriter","parameter": {"print": false,"encoding": "UTF-8"}}}]}}jdbcUrl
- 描述:描述的是到对端数据库的JDBC连接信息,使用JSON的数组描述,并支持一个库填写多个连接地址。之所以使用JSON数组描述连接信息,是因为阿里集团内部支持多个IP探测,如果配置了多个,MysqlReader可以依次探测ip的可连接性,直到选择一个合法的IP。如果全部连接失败,MysqlReader报错。 注意,jdbcUrl必须包含在connection配置单元中。对于阿里集团外部使用情况,JSON数组填写一个JDBC连接即可。
- 必选:是
- 默认值:无
username
- 描述:数据源的用户名。
- 必选:是
- 默认值:无
password
- 描述:目的表需要写入数据的字段,字段之间用英文逗号分隔。例如: “column”: [“id”,“name”,“age”]。如果要依次写入全部列,使用表示, 例如: “column”: [""]。
- 必选:是
- 默认值:无
table
- 描述:所选取的需要同步的表。使用JSON的数组描述,因此支持多张表同时抽取。当配置为多张表时,用户自己需保证多张表是同一schema结构,MysqlReader不予检查表是否同一逻辑表。注意,table必须包含在connection配置单元中。
- 必选:是
- 默认值:无
column
- 描述:配置的表中需要同步的列名集合,使用JSON的数组描述字段信息。用户使用代表默认使用所有列配置,例如[’’]。
- 支持列裁剪,即列可以挑选部分列进行导出。
- 支持列换序,即列可以不按照表schema信息进行导出。
- 支持常量配置,用户需要按照Mysql SQL语法格式: [“id”, “
table”, “1”, “‘bazhen.csy’”, “null”, “to_char(a + 1)”, “2.3” , “true”] id为普通列名,table为包含保留在的列名,1为整形数字常量,'bazhen.csy’为字符串常量,null为空指针,to_char(a + 1)为表达式,2.3为浮点数,true为布尔值。
- 必选:是
- 默认值:无
splitPk
- 描述:MysqlReader进行数据抽取时,如果指定splitPk,表示用户希望使用splitPk代表的字段进行数据分片,DataX因此会启动并发任务进行数据同步,这样可以大大提供数据同步的效能。
- 推荐splitPk用户使用表主键,因为表主键通常情况下比较均匀,因此切分出来的分片也不容易出现数据热点。
- 目前splitPk仅支持整形数据切分,不支持浮点、字符串、日期等其他类型。如果用户指定其他非支持类型,MysqlReader将报错!
- 如果splitPk不填写,包括不提供splitPk或者splitPk值为空,DataX视作使用单通道同步该表数据。
- 必选:否
- 默认值:空
where
-
描述:筛选条件,MysqlReader根据指定的column、table、where条件拼接SQL,并根据这个SQL进行数据抽取。在实际业务场景中,往往会选择当天的数据进行同步,可以将where条件指定为gmt_create > $bizdate 。注意:不可以将where条件指定为limit 10,limit不是SQL的合法where子句。
- where条件可以有效地进行业务增量同步。如果不填写where语句,包括不提供where的key或者value,DataX均视作同步全量数据。
必选:否
- where条件可以有效地进行业务增量同步。如果不填写where语句,包括不提供where的key或者value,DataX均视作同步全量数据。
-
默认值:无
querySql
-
描述:在有些业务场景下,where这一配置项不足以描述所筛选的条件,用户可以通过该配置型来自定义筛选SQL。当用户配置了这一项之后,DataX系统就会忽略table,column这些配置型,直接使用这个配置项的内容对数据进行筛选,例如需要进行多表join后同步数据,使用select a,b from table_a join table_b on table_a.id = table_b.id
- 当用户配置querySql时,MysqlReader直接忽略table、column、where条件的配置,querySql优先级大于table、column、where选项。
-
必选:否
-
默认值:无
类型转换
目前MysqlReader支持大部分Mysql类型,但也存在部分个别类型没有支持的情况,请注意检查你的类型。
下面列出MysqlReader针对Mysql类型转换列表:
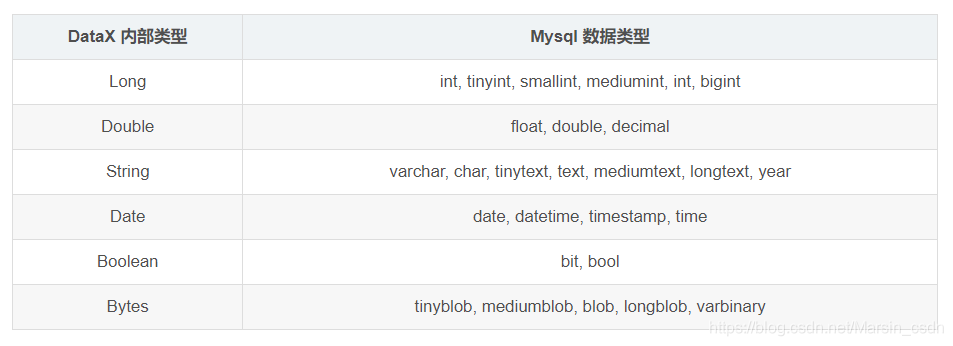
- 除上述罗列字段类型外,其他类型均不支持。
tinyint(1) DataX视作为整形。year DataX视作为字符串类型bit DataX属于未定义行为。
MysqlWriter
回到顶部
{"job": {"setting": {"speed": {"channel": 1}},"content": [{"reader": {"name": "streamreader","parameter": {"column": [{"value": "DataX","type": "string"},{"value": 12138110,"type": "long"},{"value": "2021-03-18 08:08:08","type": "date"},{"value": true,"type": "bool"},{"value": "test","type": "bytes"}],"sliceRecordCount": 1000}},"writer": {"name": "mysqlwriter","parameter": {"writeMode": "insert","username": "root","password": "root","column": ["id","name"],"session": ["set session sql_mode='ANSI'"],"preSql": ["delete from test"],"connection": [{"jdbcUrl": "jdbc:mysql://127.0.0.1:3306/datax?useUnicode=true&characterEncoding=gbk","table": ["test"]}]}}}]}}column
- 描述:目的表需要写入数据的字段,字段之间用英文逗号分隔。例如: “column”: [“id”,“name”,“age”]。如果要依次写入全部列,使用表示, 例如: “column”: [""]。
- 必选:是
- 默认值:否
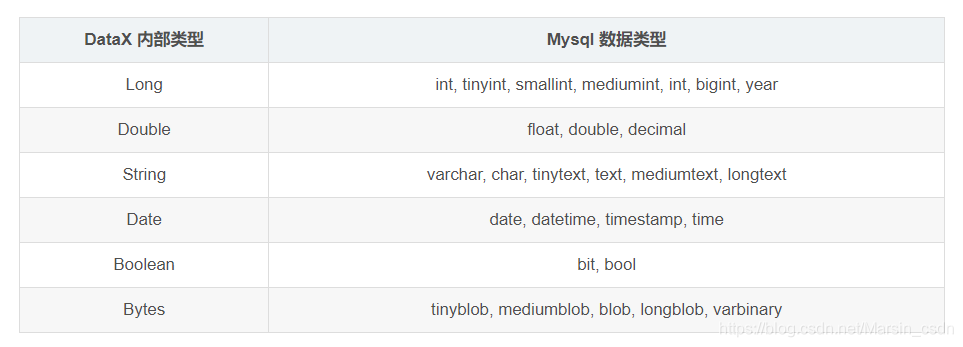
类似 MysqlReader ,目前 MysqlWriter 支持大部分 Mysql 类型,但也存在部分个别类型没有支持的情况,请注意检查你的类型。
下面列出 MysqlWriter 针对 Mysql 类型转换列表:
HdfsReader
回到顶部
HdfsReader实现了从Hadoop分布式文件系统Hdfs中读取文件数据并转为DataX协议的功能。textfile是Hive建表时默认使用的存储格式,数据不做压缩,本质上textfile就是以文本的形式将数据存放在hdfs中,对于DataX而言,HdfsReader实现上类比TxtFileReader,有诸多相似之处。orcfile,它的全名是Optimized Row Columnar file,是对RCFile做了优化。据官方文档介绍,这种文件格式可以提供一种高效的方法来存储Hive数据。HdfsReader利用Hive提供的OrcSerde类,读取解析orcfile文件的数据。目前HdfsReader支持的功能如下:
- 支持textfile、orcfile、rcfile、sequence file和csv格式的文件,且要求文件内容存放的是一张逻辑意义上的二维表。
- 支持多种类型数据读取(使用String表示),支持列裁剪,支持列常量。
- 支持递归读取、支持正则表达式("*“和”?")。
- 支持orcfile数据压缩,目前支持SNAPPY,ZLIB两种压缩方式。
- 多个File可以支持并发读取。
- 支持sequence file数据压缩,目前支持lzo压缩方式。
- csv类型支持压缩格式有:gzip、bz2、zip、lzo、lzo_deflate、snappy。
- 目前插件中Hive版本为1.1.1,Hadoop版本为2.7.1(Apache[为适配JDK1.7],在Hadoop 2.5.0, Hadoop 2.6.0 和Hive 1.2.0测试环境中写入正常;其它版本需后期进一步测试;
- 支持kerberos认证(注意:如果用户需要进行kerberos认证,那么用户使用的Hadoop集群版本需要和hdfsreader的Hadoop版本保持一致,如果高于hdfsreader的Hadoop版本,不保证kerberos认证有效)
暂时不能做到:
- 单个File支持多线程并发读取,这里涉及到单个File内部切分算法。
- 目前还不支持hdfs HA;
{"job": {"setting": {"speed": {"channel": 3}},"content": [{"reader": {"name": "hdfsreader","parameter": {"path": "/user/hive/warehouse/table/*","defaultFS": "hdfs://xxx:port","column": [{"index": 0,"type": "long"},{"index": 1,"type": "boolean"},{"type": "string","value": "hello"},{"index": 2,"type": "double"}],"fileType": "orc","encoding": "UTF-8","fieldDelimiter": ","}},"writer": {"name": "streamwriter","parameter": {"print": true}}}]}}path
-
描述:要读取的文件路径,如果要读取多个文件,可以使用正则表达式"*",注意这里可以支持填写多个路径。
- 当指定单个Hdfs文件,HdfsReader暂时只能使用单线程进行数据抽取。二期考虑在非压缩文件情况下针对单个File可以进行多线程并发读取。
- 当指定多个Hdfs文件,HdfsReader支持使用多线程进行数据抽取。线程并发数通过通道数指定。
- 当指定通配符,HdfsReader尝试遍历出多个文件信息。例如: 指定/代表读取/目录下所有的文件,指定/bazhen/*代表读取bazhen目录下游所有的文件。HdfsReader目前只支持"“和”?"作为文件通配符。
- 特别需要注意的是,DataX会将一个作业下同步的所有的文件视作同一张数据表。用户必须自己保证所有的File能够适配同一套schema信息。并且提供给DataX权限可读。
-
必选:是
-
默认值:无
defaultFS
- 描述:Hadoop hdfs文件系统namenode节点地址。
- 目前HdfsReader已经支持Kerberos认证,如果需要权限认证,则需要用户配置kerberos参数,见下面
- 必选:是
- 默认值:无
fileType
- 描述:文件的类型,目前只支持用户配置为"text"、“orc”、“rc”、“seq”、“csv”。
- text表示textfile文件格式
- orc表示orcfile文件格式
- rc表示rcfile文件格式
- seq表示sequence file文件格式
- csv表示普通hdfs文件格式(逻辑二维表)
- 特别需要注意的是,HdfsReader能够自动识别文件是orcfile、textfile或者还是其它类型的文件,但该项是必填项,HdfsReader则会只读取用户配置的类型的文件,忽略路径下其他格式的文件
- 另外需要注意的是,由于textfile和orcfile是两种完全不同的文件格式,所以HdfsReader对这两种文件的解析方式也存在差异,这种差异导致hive支持的复杂复合类型(比如map,array,struct,union)在转换为DataX支持的String类型时,转换的结果格式略有差异,比如以map类型为例:
orcfile map类型经hdfsreader解析转换成datax支持的string类型后,结果为"{job=80, team=60, person=70}"
textfile map类型经hdfsreader解析转换成datax支持的string类型后,结果为"job:80,team:60,person:70"
从上面的转换结果可以看出,数据本身没有变化,但是表示的格式略有差异,所以如果用户配置的文件路径中要同步的字段在Hive中是复合类型的话,建议配置统一的文件格式。 - 如果需要统一复合类型解析出来的格式,我们建议用户在hive客户端将textfile格式的表导成orcfile格式的表
- 必选:是
- 默认值:无
column
- 描述:读取字段列表,type指定源数据的类型,index指定当前列来自于文本第几列(以0开始),value指定当前类型为常量,不从源头文件读取数据,而是根据value值自动生成对应的列。
- 默认情况下,用户可以全部按照String类型读取数据,配置如下:
“column”: ["*"] - 用户可以指定Column字段信息,配置如下:
{ “type”: “long”, “index”: 0 //从本地文件文本第一列获取int字段 },
{ “type”: “string”, “value”: “alibaba” //HdfsReader内部生成alibaba的字符串字段作为当前字段 }
- 默认情况下,用户可以全部按照String类型读取数据,配置如下:
- 必选:是
- 默认值:无
fieldDelimiter
- 描述:读取的字段分隔符
- 另外需要注意的是,HdfsReader在读取textfile数据时,需要指定字段分割符,如果不指定默认为’,’,HdfsReader在读取orcfile时,用户无需指定字段分割符
- 必选:否
- 默认值:,
encoding
- 描述:读取文件的编码配置。
- 必选:否
- 默认值:utf-8
nullFormat
- 描述:文本文件中无法使用标准字符串定义null(空指针),DataX提供nullFormat定义哪些字符串可以表示为null。
- 例如如果用户配置: nullFormat:"\N",那么如果源头数据是"\N",DataX视作null字段。
- 必选:否
- 默认值:无
compress
- 描述:当fileType(文件类型)为csv下的文件压缩方式,目前仅支持 gzip、bz2、zip、lzo、lzo_deflate、hadoop-snappy、framing-snappy压缩;
- lzo存在两种压缩格式:lzo和lzo_deflate,用户在配置的时候需要留心,不要配错了;另外,由于snappy目前没有统一的stream format,datax目前只支持最主流的两种:hadoop-snappy(hadoop上的snappy stream format)和framing-snappy(google建议的snappy stream format);orc文件类型下无需填写。
- 必选:否
- 默认值:无
hadoopConfig
- 描述:hadoopConfig里可以配置与Hadoop相关的一些高级参数,比如HA的配置。
"hadoopConfig":{ "dfs.nameservices": "testDfs", "dfs.ha.namenodes.testDfs": "namenode1,namenode2", "dfs.namenode.rpc-address.aliDfs.namenode1": "", "dfs.namenode.rpc-address.aliDfs.namenode2": "", "dfs.client.failover.proxy.provider.testDfs": "org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider"} - 必选:否
- 默认值:无
HdfsWriter
回到顶部
- 目前HdfsWriter仅支持textfile和orcfile两种格式的文件,且文件内容存放的必须是一张逻辑意义上的二维表;
- 由于HDFS是文件系统,不存在schema的概念,因此不支持对部分列写入;
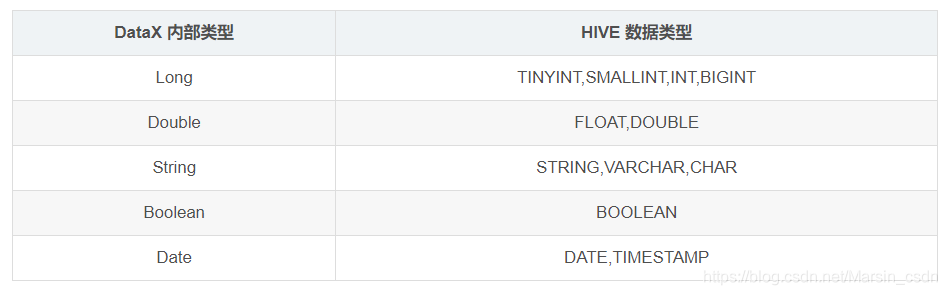
- 目前仅支持与以下Hive数据类型: 数值型:TINYINT,SMALLINT,INT,BIGINT,FLOAT,DOUBLE 字符串类型:STRING,VARCHAR,CHAR 布尔类型:BOOLEAN 时间类型:DATE,TIMESTAMP 目前不支持:decimal、binary、arrays、maps、structs、union类型;
- 对于Hive分区表目前仅支持一次写入单个分区;
- 对于textfile需用户保证写入hdfs文件的分隔符与在Hive上创建表时的分隔符一致,从而实现写入hdfs数据与Hive表字段关联;
- HdfsWriter实现过程是:首先根据用户指定的path,创建一个hdfs文件系统上不存在的临时目录,创建规则:path_随机;然后将读取的文件写入这个临时目录;全部写入后再将这个临时目录下的文件移动到用户指定目录(在创建文件时保证文件名不重复); 最后删除临时目录。如果在中间过程发生网络中断等情况造成无法与hdfs建立连接,需要用户手动删除已经写入的文件和临时目录。
- 目前插件中Hive版本为1.1.1,Hadoop版本为2.7.1(Apache[为适配JDK1.7],在Hadoop 2.5.0, Hadoop 2.6.0 和Hive 1.2.0测试环境中写入正常;其它版本需后期进一步测试;
- 目前HdfsWriter支持Kerberos认证(注意:如果用户需要进行kerberos认证,那么用户使用的Hadoop集群版本需要和hdfsreader的Hadoop版本保持一致,如果高于hdfsreader的Hadoop版本,不保证kerberos认证有效)
{ "setting": {}, "job": { "setting": { "speed": { "channel": 2 } }, "content": [ { "reader": { "name": "txtfilereader", "parameter": { "path": ["/usr/local/workplace/txtWorkplace/job/test.txt"], "encoding": "UTF-8", "column": [{ "index": 0, "type": "long"},{ "index": 1, "type": "long"},{ "index": 2, "type": "long"},{ "index": 3, "type": "long"},{ "index": 4, "type": "DOUBLE"},{ "index": 5, "type": "DOUBLE"},{ "index": 6, "type": "STRING"},{ "index": 7, "type": "STRING"},{ "index": 8, "type": "STRING"},{ "index": 9, "type": "BOOLEAN"},{ "index": 10, "type": "date"},{ "index": 11, "type": "date"} ], "fieldDelimiter": "\t" } }, "writer": { "name": "hdfswriter", "parameter": { "defaultFS": "hdfs://xxx:port", "fileType": "orc", "path": "/user/hive/warehouse/writerorc.db/orcfull", "fileName": "xxxx", "column": [{ "name": "col1", "type": "TINYINT"},{ "name": "col2", "type": "SMALLINT"},{ "name": "col3", "type": "INT"},{ "name": "col4", "type": "BIGINT"},{ "name": "col5", "type": "FLOAT"},{ "name": "col6", "type": "DOUBLE"},{ "name": "col7", "type": "STRING"},{ "name": "col8", "type": "VARCHAR"},{ "name": "col9", "type": "CHAR"},{ "name": "col10", "type": "BOOLEAN"},{ "name": "col11", "type": "date"},{ "name": "col12", "type": "TIMESTAMP"} ], "writeMode": "append", "fieldDelimiter": "\t", "compress":"NONE" } } } ] }}defaultFS
- 描述:Hadoop hdfs文件系统namenode节点地址。格式:hdfs://ip:端口;例如:hdfs://127.0.0.1:9000
- 必选:是
- 默认值:无
fileType
- 描述:文件的类型,目前只支持用户配置为"text"或"orc"。
- text表示textfile文件格式
- orc表示orcfile文件格式
- 必选:是
- 默认值:无
path
-
描述:存储到Hadoop hdfs文件系统的路径信息,HdfsWriter会根据并发配置在Path目录下写入多个文件。为与hive表关联,请填写hive表在hdfs上的存储路径。例:Hive上设置的数据仓库的存储路径为:/user/hive/warehouse/ ,已建立数据库:test,表:hello;则对应的存储路径为:/user/hive/warehouse/test.db/hello
-
必选:是
-
默认值:无
fileName
- 描述:HdfsWriter写入时的文件名,实际执行时会在该文件名后添加随机的后缀作为每个线程写入实际文件名。
- 必选:是
- 默认值:无
column
- 描述:写入数据的字段,不支持对部分列写入。为与hive中表关联,需要指定表中所有字段名和字段类型,其中:name指定字段名,type指定字段类型。
- 用户可以指定Column字段信息,配置如下:
"column": [{"name": "userName","type": "string"},{"name": "age","type": "long"}]
- 用户可以指定Column字段信息,配置如下:
- 必选:是
- 默认值:无
writeMode
- 描述:hdfswriter写入前数据清理处理模式:
- append,写入前不做任何处理,DataX hdfswriter直接使用filename写入,并保证文件名不冲突。
- nonConflict,如果目录下有fileName前缀的文件,直接报错。
- 必选:是
- 默认值:无
fieldDelimiter
- 描述:hdfswriter写入时的字段分隔符,需要用户保证与创建的Hive表的字段分隔符一致,否则无法在Hive表中查到数据。
- 必选:是
- 默认值:无
compress
- 描述:hdfs文件压缩类型,默认不填写意味着没有压缩。其中:text类型文件支持压缩类型有gzip、bzip2;orc类型文件支持的压缩类型有NONE、SNAPPY(需要用户安装SnappyCodec)。
- 必选:否
- 默认值:无压缩
hadoopConfig
- 描述:hadoopConfig里可以配置与Hadoop相关的一些高级参数,比如HA的配置。
- 必选:否
- 默认值:无
encoding
- 描述:读取文件的编码配置。
- 必选:否
- 默认值:utf-8
类型转换
目前 HdfsWriter 支持大部分 Hive 类型,请注意检查你的类型。
下面列出 HdfsWriter 针对 Hive 数据类型转换列表:
DataX安装部署及测试
回到顶部
下载压缩包
下载页面地址:https://github.com/alibaba/DataX
在页面中【Quick Start】—>【Download DataX下载地址】进行下载。下载后的包名:datax.tar.gz。
解压后{datax}目录下有{bin conf job lib log log_perf plugin script tmp}几个目录。
安装
将下载后的压缩包直接解压后可用,前提是对应的java及python环境满足要求。
- JDK(1.6以上,推荐1.8)
- Python(推荐Python2.7.X)一定要为python2,因为后面执行datax.py的时候,里面的python的print会执行不了,导致运行不成功,会提示你print语法要加括号,python2中加不加都行 python3中必须要加,否则报语法错
- Apache Maven 3.x (Compile DataX)
测试
进入datax目录下的bin中,里面有datax.py文件,可以在cmd中测试:
python D:\datax\bin\datax.py D:\datax\job\job.json使用即执行一个python脚本,传入json配置文件
配置文件,可以查看模版样例,模版
如果乱码,可以在cmd中输入:
CHCP 65001使用DataX将mysql数据导入到oracle中
回到顶部
配置json
{ "job": { "content": [ { "reader": { "name": "mysqlreader", "parameter": { "username": "", "password": "", "column": ["username","payment"], "connection": [{ "table": [ "salary" ], "jdbcUrl": [ "jdbc:mysql://127.0.0.1:3306/test" ]} ] } }, "writer": { "name": "oraclewriter", "parameter": { "username": "", "password": "", "column": ["rank","payment" ], "preSql": ["delete from oracle_test" ], "connection": [{ "jdbcUrl": "jdbc:oracle:thin:@127.0.0.1:1521:test", "table": [ "oracle_test" ]} ] } } } ], "setting": { "speed": { "channel": 1 } } }}cmd执行
python d:\datax\bin\datax.py E:\datax\Mysql2Oracle.jsonDataX常用Job样例
hdfs2mysql
回到顶部
{ "job": { "setting": { "speed": { "channel": 3, "record": -1, "batchSize": 2048 }, "errorLimit": { "record": 0, "percentage": 0.019999999552965164 } }, "content": [ { "reader": { "name": "hdfsreader", "parameter": { "path": "/user/hive/dataWarehouse/dwd.db/data-integration//ff8080817814aa2901782079d3d5046a/a3e00948d07c424cb2f31c2b46a362ad/part-00000", "fieldDelimiter": "\t", "encoding": "UTF-8", "fileType": "text", "column": [{ "index": "0", "type": "string"},{ "index": "1", "type": "string"},{ "index": "12", "type": "string"},{ "index": "11", "type": "string"},{ "index": "9", "type": "string"},{ "index": "7", "type": "string"},{ "index": "6", "type": "string"} ], "defaultFS": "hdfs://master:8020" } }, "writer": { "name": "mysqlwriter", "parameter": { "username": "root", "writeMode": "update", "preSql": [], "session": [], "column": ["report_error_id","task_info_id","report_error_extend","report_error_des","report_error_content","column_name","table_name" ], "connection": [{ "jdbcUrl": "jdbc:mysql://hadoop-02:3306/test", "table": [ "t_inspect_error" ]} ], "splitPk": "", "password": "Dgms2019!" } } } ] }}mysql2hdfs
回到顶部
{"job": {"setting": {"speed": {"channel": 3},"errorLimit": {"record": 0,"percentage": 0.02}},"content": [{"reader": {"name": "mysqlreader","parameter": {"username": "root","password": "123456","column": ["name","age"],"splitPk": "age","connection": [{"table": ["USER"],"jdbcUrl": ["jdbc:mysql://hadoop-02:3306/test"]}]}},"writer": {"name": "hdfswriter","parameter": {"defaultFS": "hdfs://hadoop-01:9000","fileType": "text","path": "/input/mysql2hive","fileName": "1.dat","column": [{"name": "name","type": "STRING"},{"name": "name","type": "int"}],"writeMode": "append","fieldDelimiter": "\t",}}}]}}
