Redis7.0代码分析总结之:底层数据结构listpack实现原理
文章目录
一、前言
listpack压缩列表。作为ziplist的替代品,从2017年引入Redis后,到redis7.0已经完全取代ziplist
作为redis底层存储数据结构之一。
相对于ziplist,listpack内存更紧凑,实现更简洁。下面详细分析这一底层数据结构的实现原理。
二、实现原理
2.1 、内存结构
listpack作为ziplist的替代者,它的内存布局、实现原理和listpack非常相似。比如:都是连续的一块内存,前端都有表示内存大小、元素个数;尾部都有终结标志等元数据。但是他们彼此之间又有差异。下面分别通过对比的方式,对listpack内存布局进行重点说明.
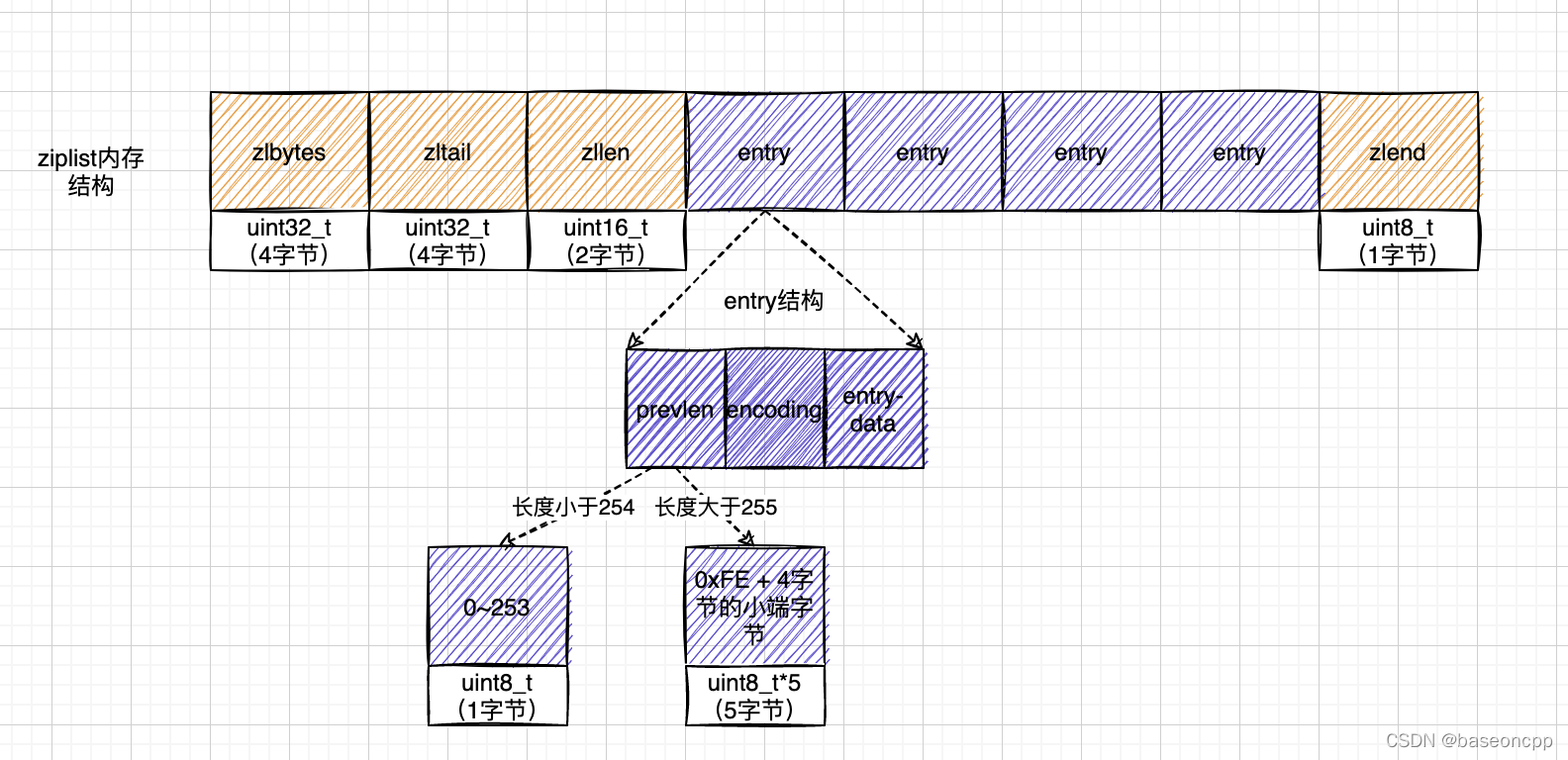
2.1.1、ziplist内存布局:
2.2.2、listpack内存布局:
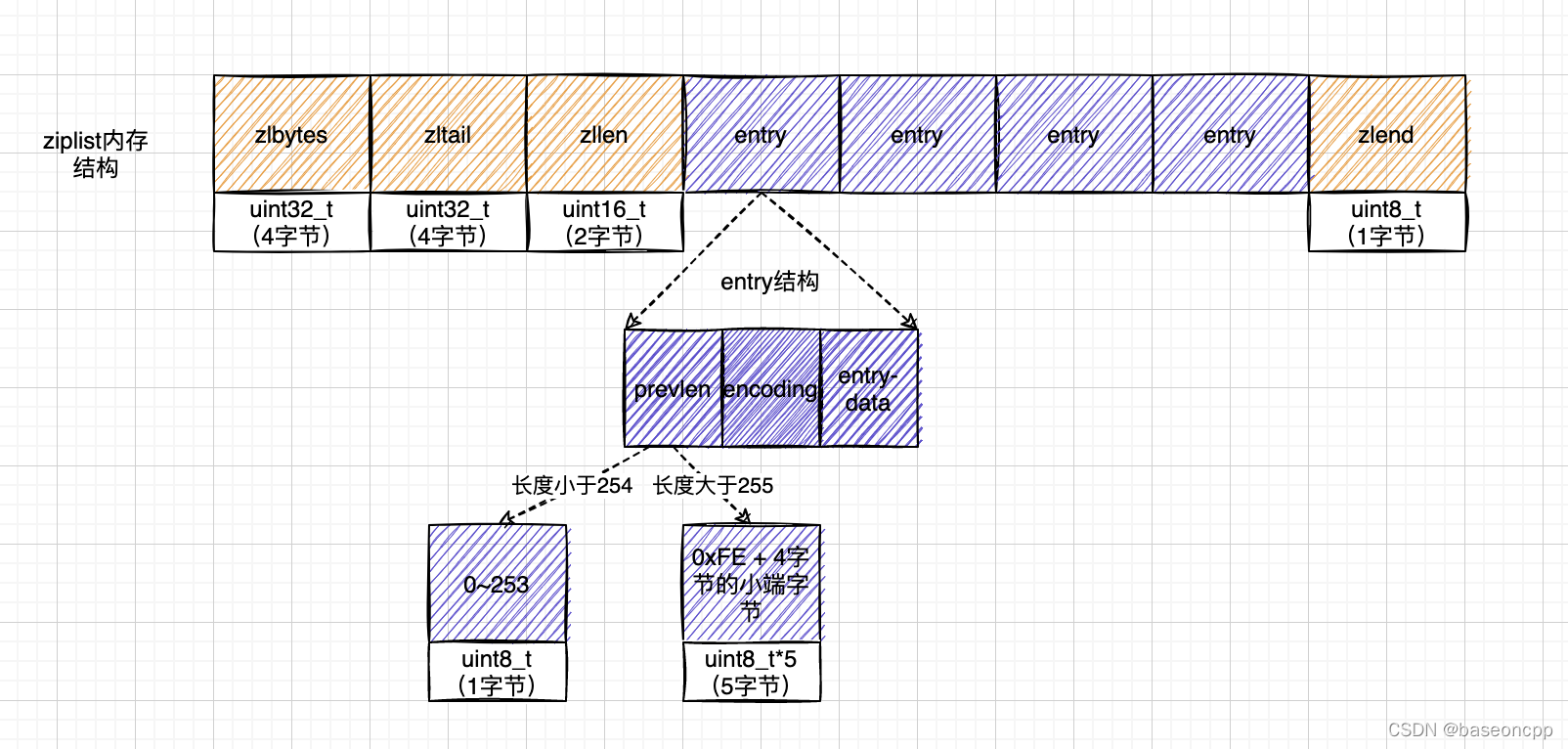
通过以上两个内存结构图,可以直观看出```ziplist```内存结构比```listpack```稍微复杂。彼此之间的差异如下:相同点:
- 头部都用4个字节的无符号整数记录了使用内存的大小;
- 内存块尾部最后一个字节都用来表示列表的终结,而且内容都是
0xFF; - 列表元素(entry)都是根据不同的数据内容编码后存储,条目都包含了三部分内容:编码、长度、数据。
差异点:
- 结构组成不同:
ziplist内存结构分了四个功能块:ziplist总长度,元素个数,最后元素的偏移和结尾标志;而listpack只有三个功能块:listpack总长度,元素个数和结尾标志,少了最后元素的偏移; - 数据长度不同:两者的
包含元素个数使用的字节长度不一样ziplist是4个字节的uint32_t类型数据,而listpack则是两个字节的unint16_t类型数据,单从这个数据的长度来看,listpack能存储的数据个数是比ziplist少的。因为uint16_t能容纳的数据比uint32_t要少。 - 两者元素结构不同:
ziplist元素的三个组成部分分别是:前置元素(entry)的长度数据,本条目的编码方案(包含数据长度)和具体的数据内容;而listpack元素的三个组成部分则是:本条目的编码方案(包含数据长度)、具体的数据内容和本条目前面两个条目数据长度编码后需要的字节数。就是说ziplist条目保存了上一个条目的长度信息,而listpack则保存了自己的长度信息。这两者有很明显的区别,而且这个区别,将影响两者操作的完全不同。
下面将详细描述listpack的条目编码方案。
2.2、 数据存储编码方案
listpack使用1个字节,对其存储的数据制定了11种编码方式。7种用于整数和整数数字组成的字符串编码,内部通过整数的方式压缩存储;3种用户普通字符串数据编码,内部直接使用原字符串的方式进行存储;1种用来表示listpack结束标识的编码。
2.2.1、数字编码
数字编码主要是用于整数数值和数字组成的字符串。
对于数字组成的字符串,先尝试转换为对应的整数数值,然后根据其大小范围分别采取不同的编码方式和字节长度存储。
下图就是7种不同的编码规则:
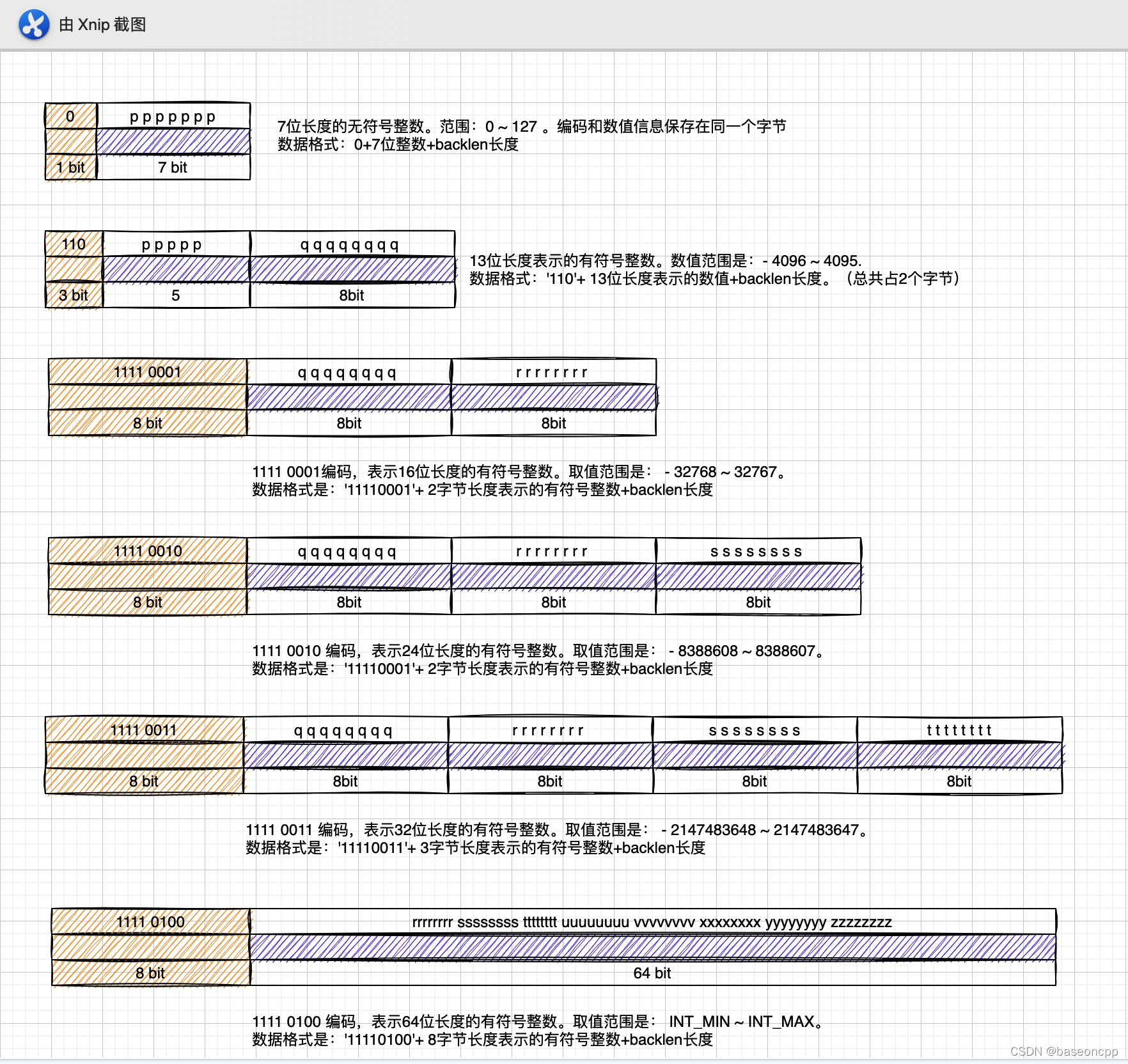
此外,对于负数的数值,通过转换为同样长度下能表现的正数进行存储。
通过整数编码存储的数据,它内部是没有专门表示长度的部分。具体使用多少长度进行存储,通过编码方式就可以获取到,每种编码的长度都不同,故此编解码时候无需这个特定的长度信息。
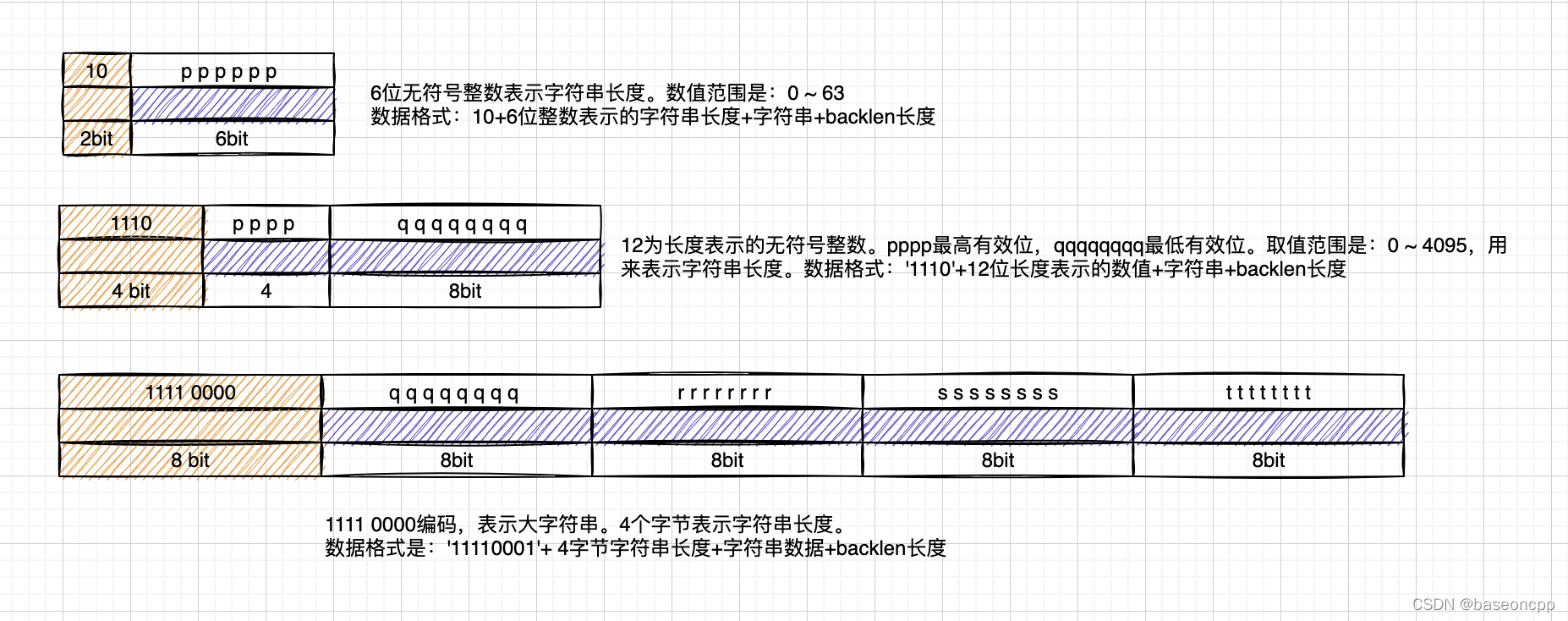
2.2.2、字符串编码
3种字符串编码,分别根据不同的字符串长度,采取不同的编码方式。使用字符串编码的数据,其内容无法通过整数数字压缩编码:包含非数字、不可打印的二进制字符等。以下图片列出了三种字符编码规则:
2.3、 backlen长度编码方案
listpack每个数据元素尾部都包含一个表示当前数据长度占用总字节数的长度数据。这部分内容主要是用来从右往左遍历、搜索数据使用。其内部也采取了一种编码机制进行数据编码后存储。
下面图片描述了这中编码方式:
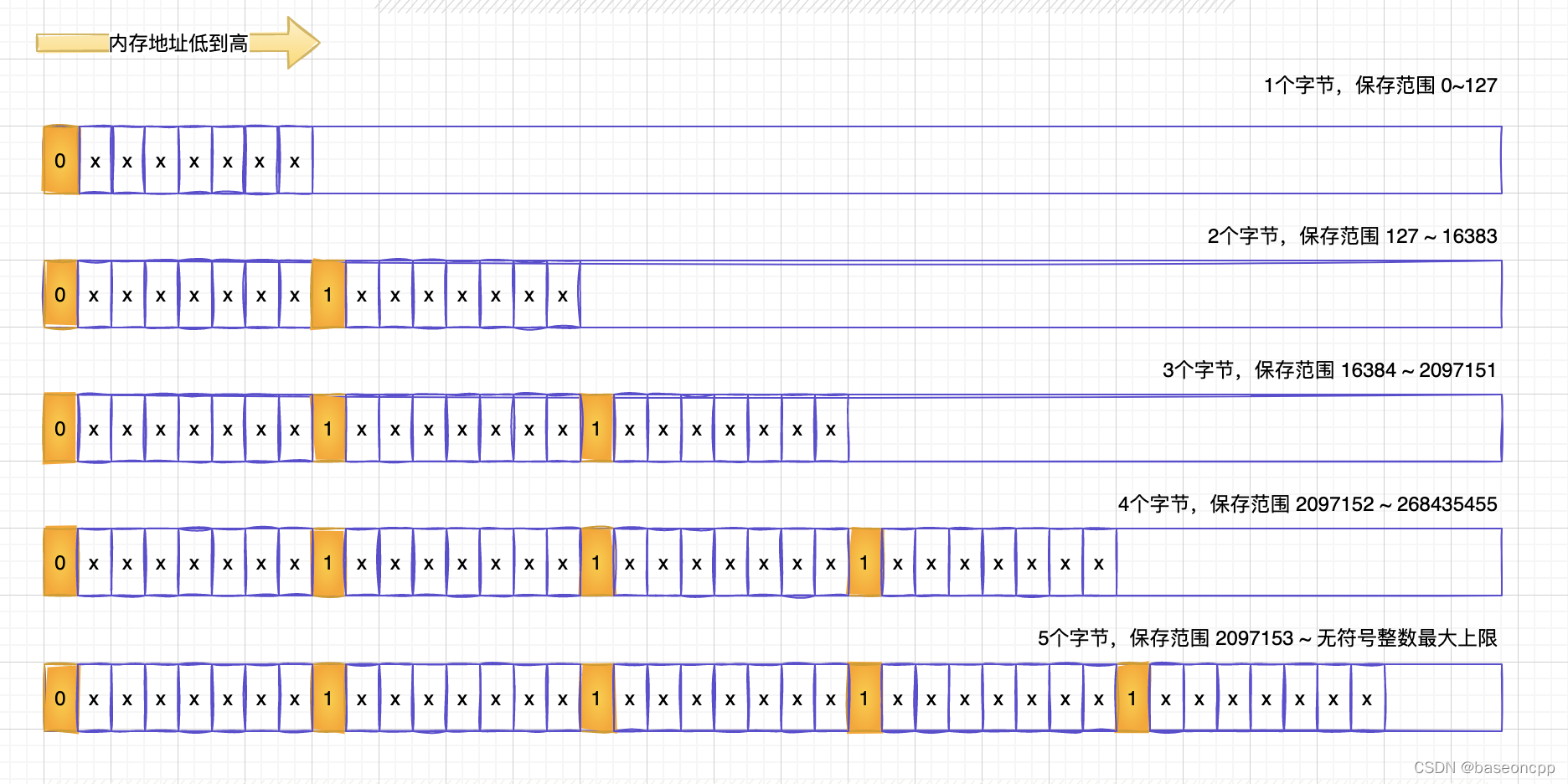
listpack内部进行编解码的函数分别为:lpEncodeBackLen和lpDecodeBackLen。
下面采取一个具体数值分别描述编解码过程:
编码规则:
编码从低位到高位填充内存字节,即从左到右;
解码从高位到低位读取内存字节,即从右到左;
每个字节8位,只用低7位保存数值,最高位用来表示当前字节是否还有更多字节,0表示没有了,1表示还有。
编码的时候,除第一个字节,其他后续所有字节高位都为1;解码的时候,根据这个标志位来判断什么时候终止。
例子:268435400。其二进制表示如下:0b1111111111111111111111001000(28位)按照一个字节7位,刚好填满4个字节的28位。
按照以上规则 大于 2097152,小于268435455。因此需要4个字节来存放。
存放的内存地址用p指针指向
编码顺序如下:
- 1,右移21位,留下高7位。即 剩下0b1111111(7位)对应16进制为0x7F;把0X7F保存在p[0]位置;
- 2,右移14位,留下高14位,因为最高的7位,步骤1已经处理了,在这里值需要处理剩下的7位,故此将其与127(即低7位全部为1)与运算,截取这7位内容,假如这个结果暂时保存在变量T中。由于编码规则是:“除了第一个字节高位为0,其他任何字节的高位都为1",因此p[1]第1位也需要是1;那么只需要把T和128(128二进制是b1000 0000)相或即可;最后把或的结果保存在p[1]位置。
- 3,右移7位,留下高21位,步骤1,2处理掉了这剩余21位中的高14位,在此也只需要处理21位中的低7位。方式如步骤2,先与127与运算,结果在和128或运算,然后再保存在p[3]位置;
- 4,步骤1,2,3都处理高21位,现在只剩下低7位。到此只需要和127与,再和128或,就可以得到应该保存在p[3]位置的值。
以上4个步骤就是对数字268435400的编码过程。编码结果保存在p0-p4之间的内存空间。
下面是每个最终的保存内存结果示意图:

解码顺序如下:
【解码是从右往左,假设当前指针p指向的是p[4]的内存地址。结果保存在v变量】
- 1,首先解码p[3]地址的字节:与127相与,取低7位的数值:0xC8 & 127 = 72; 保存在v中(v = 72) 测试该字节的第8位是否为1,与128与运算。0xC8 & 128 = 128,即该位为1,因为128二进制表示,第8位为1;继续步骤2,
- 2,解码p[2]地址的字节:与127相与,取低7位的数值:0xFF & 127 = 127;因为这是第二个字节,故此其内容应该是原数据的低8到14位的内容。因此需要左移7位,即127 << 7 = 16256。将其和步骤1的v相加,即v = 72+16256 = 16328,这数值是原数据的0-14位的值;测试该字节的第8位是否为1,与128与运算。0xFF & 128 = 128, 即该位为1, 继续步骤3;
- 3, 解码p[1]地址的字节:与127相与,取低7位的数值: 0xFF & 127 = 127; 这是第三个字节,内容应该是属于原数据的 15到21位的内容。因此需要左移14位,即127 << 14 = 2080768。将其和步骤2的v相加,即v = 2080768 + 16328 = 2097096,, 这是原数据的 0- 21位的内容。 测试该字节的第8位是否为1,与128与运算。0xFF & 128 = 128, 即该位为1, 继续步骤4;
- 4, 解码p[0]地址的字节:与127相与,取低7位的数值:0x7F & 127 = 127 ;这是第四个字节,内容应该是属于元数据的22-28位的内容。因此需要左移21位,即127 << 21 = 266338304。将其和步骤3中的v相加,即v =266338304 + 2097096 = 268435400。这是原数据的0-28位的内容。测试该字节的第8位是否为1, 与128与运算。0x7F & 128 = 0, 即该位为0。0表示当前解码的数值,没有后续的字节了。
- 解码到此结束。当前解码得到的v值就是原来的数值。
即268435400!
三、主要API介绍
3.1、创建&删除列表:
创建一个listpack逻辑比较简单,直接传递一个标识容量大小的参数capacity调用lpNew()函数即可。函数内部根据参数的大小,验证合法后,从堆内存申请一个连续空间,最后按照listpack内存规则,进行初始化。
以下是附带注释的函数代码:
/ * 创建一个新的listpack,元素为0:++ * @param capacity * @return 创建成功返回指向listpack的内存地址;创建失败NULL */unsigned char *lpNew(size_t capacity) { //LP_HDR_SIZE + 1 = 7, 最小分配7个字节的空间 unsigned char *lp = lp_malloc(capacity > LP_HDR_SIZE+1 ? capacity : LP_HDR_SIZE+1); if (lp == NULL) return NULL; lpSetTotalBytes(lp,LP_HDR_SIZE+1);//listpack总容量大小 lpSetNumElements(lp,0);//设置元素个数 lp[LP_HDR_SIZE] = LP_EOF;//lp[6]即第7个字节,设置为0XFF return lp;}详细逻辑可以参考代码及注释,这里有一点需要注意的是:不管分配的内存多大,新创建的listpack,其内存布局如以下的图片:
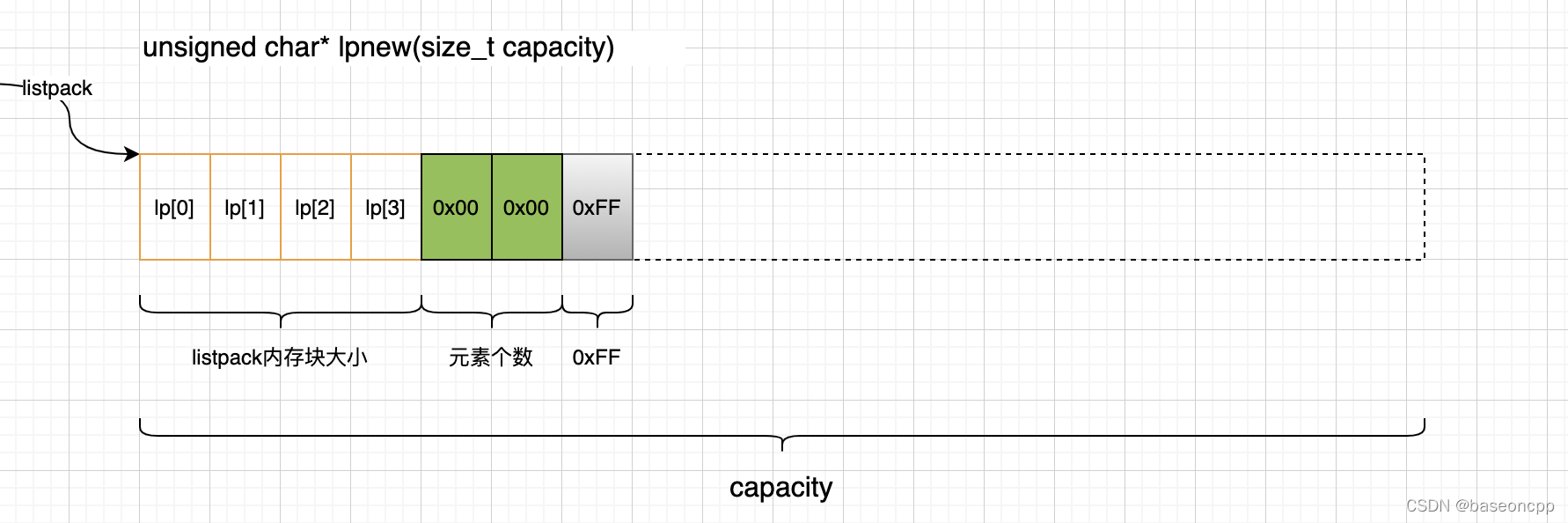
4个字节用来表示当前内存块的大小,2个字节表示元素个数,初始化为0,因为是空的列表,紧跟着是列表终结符:0xFF。剩余的内存空间,暂时不用。
列表删除则通过void lpFree(unsigned char *lp)函数,直接把lp指向的内存地址释放。
3.2、插入、更新、删除
listpack因为内存模型是一整块连续的线性内存,虽然插入、删除和更新等操作接口或许参数不同,实现的功能不同,但是他们内部的操作都是通过内存数据移动和拷贝赋值来进行的。下面概要描述这三类函数的操作思路:
- 插入:对待插入数据进行编码完成后,判断是否需要内存进行扩容处理,需要则扩容,否则,搜索、定位到具体插入位置偏移,通过调用memmove函数把该位置的数据往后移动,腾出匹配长度的空位,然后把新条目数据填写到该空位当中,最后更新
listpack的元素个数。 - 删除:搜索、定位到具体删除位置偏移,计算待删除的数据元素总长度n,把待删除条目后续所有的元素数据统一往前移动n偏移量,这样数据就被删除了(实际上是覆盖了待删除的数据);最后检查是否需要对容量进行缩减;
- 更新:更新操作稍微复杂点,需要计算新旧数据的长度差异化diff。新数据比旧数据长,判断是否需要内存进行扩容处理,需要则扩容。然后待更新元素后续的全部元素需要往后(右)移动diff偏移,以便新数据够空间容纳;如果新数据比旧数据短,待更新元素后续的所有元素数据往前(左)移动diff偏移;然后把跟新的数据填写到新的空位当中,最后检查是否需要对容量进行缩减;
以上基本上是对listpack进行增、删、该的主要操作思路。具体的细节,可以参考代码逻辑,但是代码较多,文章就不一一列出。
3.3、查找、遍历
查找和遍历,listpack内部条目前后部分都有相关长度信息,从左到右(前到后)搜索遍历,用编码标记后续的长度信息(不同编码方式,存储长度信息的字节大小不同)计算条目编码字节和数据存储字节长度,最后在计算backlen占用字节长度,通过指针移动的方式,线性遍历;而从右往左遍历,相对比较简单,直接解码backlen(具体解码方式参考上文描述),计算当前元素占用自己大小,往前移动相应的偏移,就是上一个元素。
这就是搜索和查找listpack元素的主要操作思路。
四、总结:
listpack作为ziplist替代方案。它实现主要目的是底层数据存储,故实现上更偏向空间换时间。对内存空间的使用可以说是“字(节)字较真”,与此同时规定一个listpack最大内存使用不能超过1GB,所以哪怕有部分函数,操作上来看,时间复杂度是0(N),但结合Redis内部对该数据结构的使用方式,其实也在可接受范围内。就比如用作hash底层的实现方案之一,在特定元素数量超过一定数量后,该位hash存储结构。那么数量不多的时候采取listpack作为底层数据存储方案,即使是对其数据进行全量搜索,其耗时也不至于不可接受!
以上便是对Redis7.0代码中的listpack的分析总结,具体什么情况下使用ziplist以及使用它存储数据的上限控制等,后续分析其他数据结构和逻辑再进行补充说明。

