和Sidecars说再见,看eBPF如何解决服务网格
和Sidecars说再见,看eBPF如何解决服务网格
How eBPF will solve Service Mesh - Goodbye Sidecars
https://isovalent.com/blog/post/2021-12-08-ebpf-servicemesh
作者:Thomas Graf 发表于 December 8, 2021
CTO / Co-Founder of @isovalent , Cilium, Kernel Developer, eBPF, Linux Networking, Open Source, Mountains & Trail running http://cilium.io | http://ebpf.io | http://isovalent.com
服务mesh 是描述了用于通信,可见性和安全性的现代云原生程序的要求的概念。此概念的当前实现涉及在每个工作负载或POD中运行Sidecar代理。这是解决这些要求的相当低效的方式。在这篇文章中,我们将在ebpf的帮助下,在Sidecar模型中查看Sidecar模型的替代方案,该模型在低复杂度下提供高效率。
服务网格是什么?
随着分布式应用的引入,额外的可视性,连接和安全要求已经浮出水面。应用程序组件通过云和船舶边界的不受信任的网络进行通信,因此需要负载均衡来了解应用程序协议,弹性正变得至关重要,并且安全性必须发展到发件人和接收方可以识别彼此的身份的模型。在分布式应用程序的早期,通过直接将所需的逻辑直接嵌入到应用程序中,解决了这些要求。服务网格从应用中提取这些功能,并将其作为用于所有应用程序的基础架构的一部分,因此不再需要更改每个应用程序。
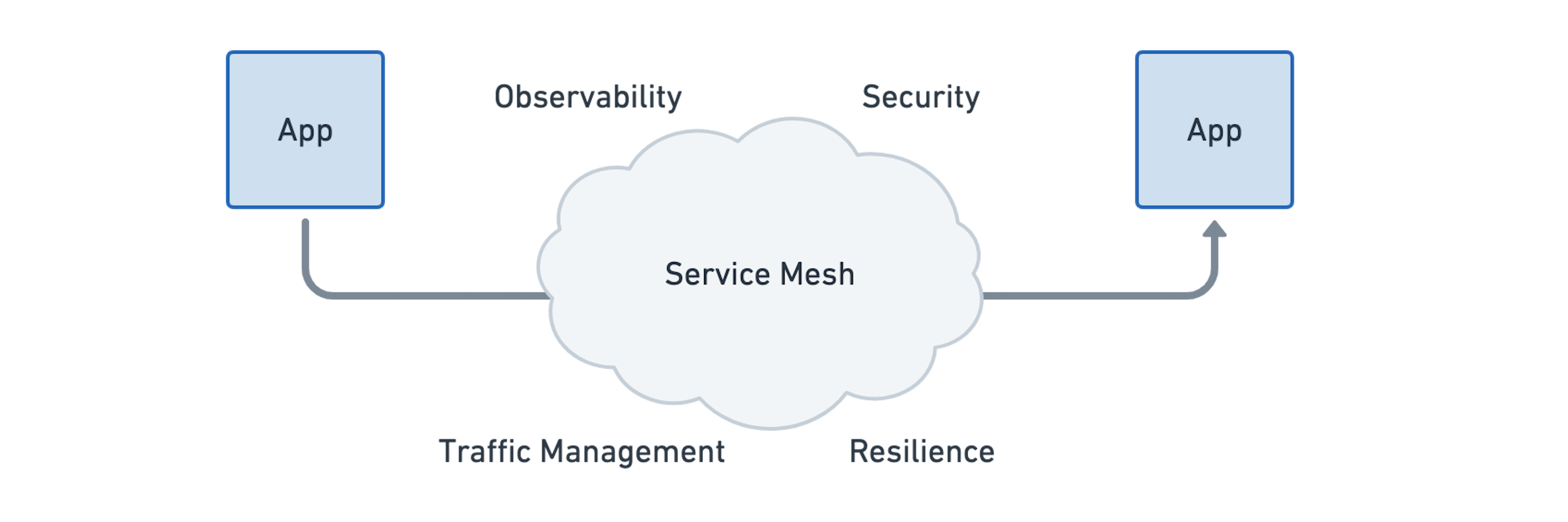
查看今天服务网格的功能集,可以归纳如下:
- 弹性连接(Resilient Connectivity):必须在云,集群和场所等边界中进行服务通信服务。通信必须是弹性和容错的。
- L7流量管理(L7 Traffic Management):负载平衡,速率限制和弹性必须是L7感知(HTTP,REST,GRPC,WebSocket,…)。
- 基于身份的安全性(Identity-based Security):依赖于网络标识符来实现安全性不再足够,发送和接收服务都必须能够基于身份而不是网络标识符彼此进行身份验证。
- 可观察性和追踪(Observability & Tracing):跟踪和度量标准形式的可观察性对于了解,监控和解决应用稳定性,性能和可用性至关重要。
- 透明度(Transparency):必须以透明方式可用的功能,即,不需要更改应用程序代码。
在早期,服务网格功能通常是在库中实现的,要求网格中的每个应用程序链接到在应用程序语言框架中编写的库。在互联网的早期发生类似的事情:回到如今的应用程序,用于运送自己的TCP / IP堆栈!正如我们在本文中讨论的那样,服务网格正在不断发展成为内核责任,就像网络堆栈一样。

如今,使用称为Sidecar模型的架构通常实现服务网格。该架构封装了将上述功能的代码封装到第4层代理中,然后依赖于从和向服务重定向到该所谓的Sidecar代理的业务。它被称为Sidecar,因为每个应用程序都有一个代理,就像Sidecar附在摩托车上一样。
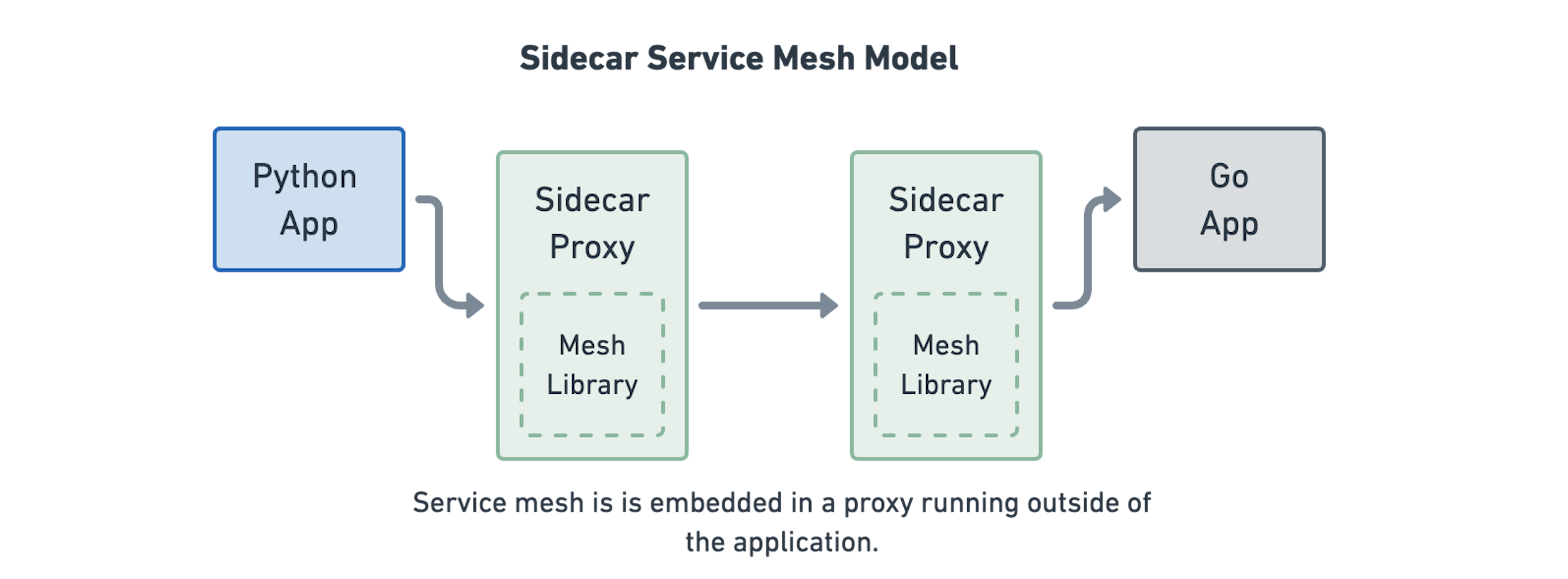 此架构的优点是不再需要服务来实现服务网格功能本身。如果使用不同语言编写的许多服务或者您正在运行不可变的第三方应用程序,这是有益的。
此架构的优点是不再需要服务来实现服务网格功能本身。如果使用不同语言编写的许多服务或者您正在运行不可变的第三方应用程序,这是有益的。
该模型的缺点是大量代理,许多额外的网络连接,以及将网络流量馈送到代理中的复制重定向逻辑。首先,还有局限性在哪种类型的网络流量可以被重定向到第4层代理。代理是有限的,它们可以支持哪些网络协议。
将连接迁移到内核的历史
在应用程序之间提供安全可靠的连接是几十年来操作系统的责任。您中的一些人可能会记得早期UNIX和Linux的 TCP Wrappers和tcpd 。它可以被认为是最初的sidecar。tcpd 允许用户透明地添加日志记录,访问控制,主机名验证,并对应用程序进行欺骗保护,而无需修改它们。它使用libwrap,并且,在与服务网格的一个有趣的并行,同一库是先前链接的应用程序以提供这些功能。tcpd能够透明地将功能添加到现有应用程序的情况下而不修改它们。 最终,所有这些功能都发现它进入到Linux,并以更高效和强大的方式可用的所有应用程序。今天,这已经发展到我们所谓的iptables。
然而,由于它专门在网络级别运行并缺乏对应用协议层的任何理解,因此可以清楚地不适合解决现代应用的连接,安全性和可观察性要求。 当然,最小成本实现模型就是使用库实现Sidecar模型。现在我们正处于有意义的位置,在操作系统中支持此方式,以获得最佳的透明度,效率和安全性。
 曾经在tcpd的日子里返回的是什么样的追踪。IP级别的访问控制已在应用程序协议级别的授权中演变为授权,例如使用JWT。主机名验证已被更换更强大的认证,例如相互TLS。网络负载均衡已扩展L7流量管理。HTTP重试是新的TCP重新传输。What used to be solved with blackhole routes is called circuit breaking today. None are fundamentally new but the required context and control have evolved.
曾经在tcpd的日子里返回的是什么样的追踪。IP级别的访问控制已在应用程序协议级别的授权中演变为授权,例如使用JWT。主机名验证已被更换更强大的认证,例如相互TLS。网络负载均衡已扩展L7流量管理。HTTP重试是新的TCP重新传输。What used to be solved with blackhole routes is called circuit breaking today. None are fundamentally new but the required context and control have evolved.
扩展内核Namespace 概念
Linux内核已经有一个共享常用功能的概念,并使其可用于系统上运行的许多应用程序。这一概念被称为Namespace ,它为今天所知道的,它形成了容器技术的基础。Namespace (内核类型,而不是Kubernetes版本)存在各种抽象,包括文件系统,用户管理,已安装的设备,流程,网络以及几个额外的抽象。这是允许单独的容器呈现文件系统的不同视图,不同的用户集,以及多个容器在单个主机上绑定到同一网络端口的内容。在CGroups的帮助下,此概念将扩展,以应用CPU,内存和网络等资源的资源管理和优先级。从云本机应用程序开发人员的角度来看,CGroups和资源紧紧地集成到我们所知道的“容器”的概念中。
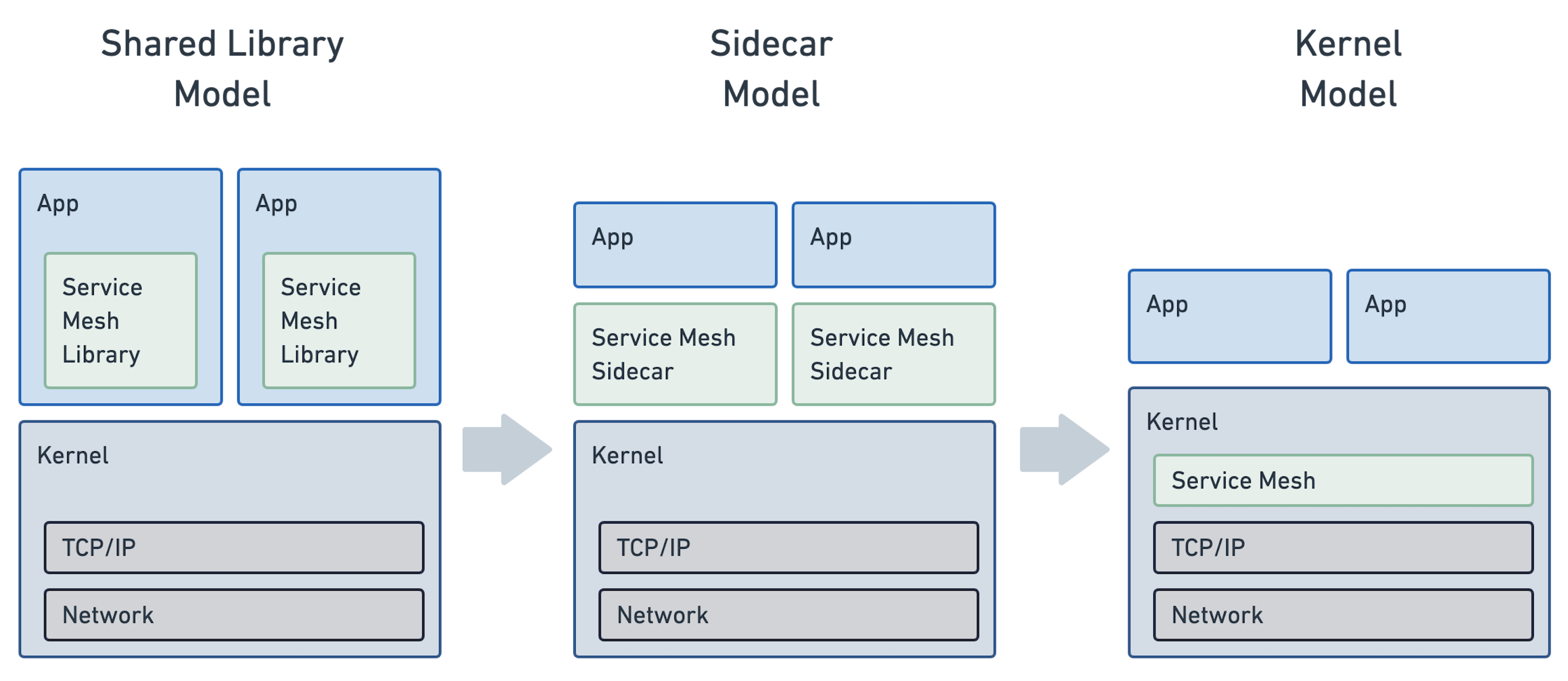
如果我们假设服务mesh 作为操作系统的一部分,那么它必须符合并与名称空间和CGroups的概念集成。这将看起来像这样:
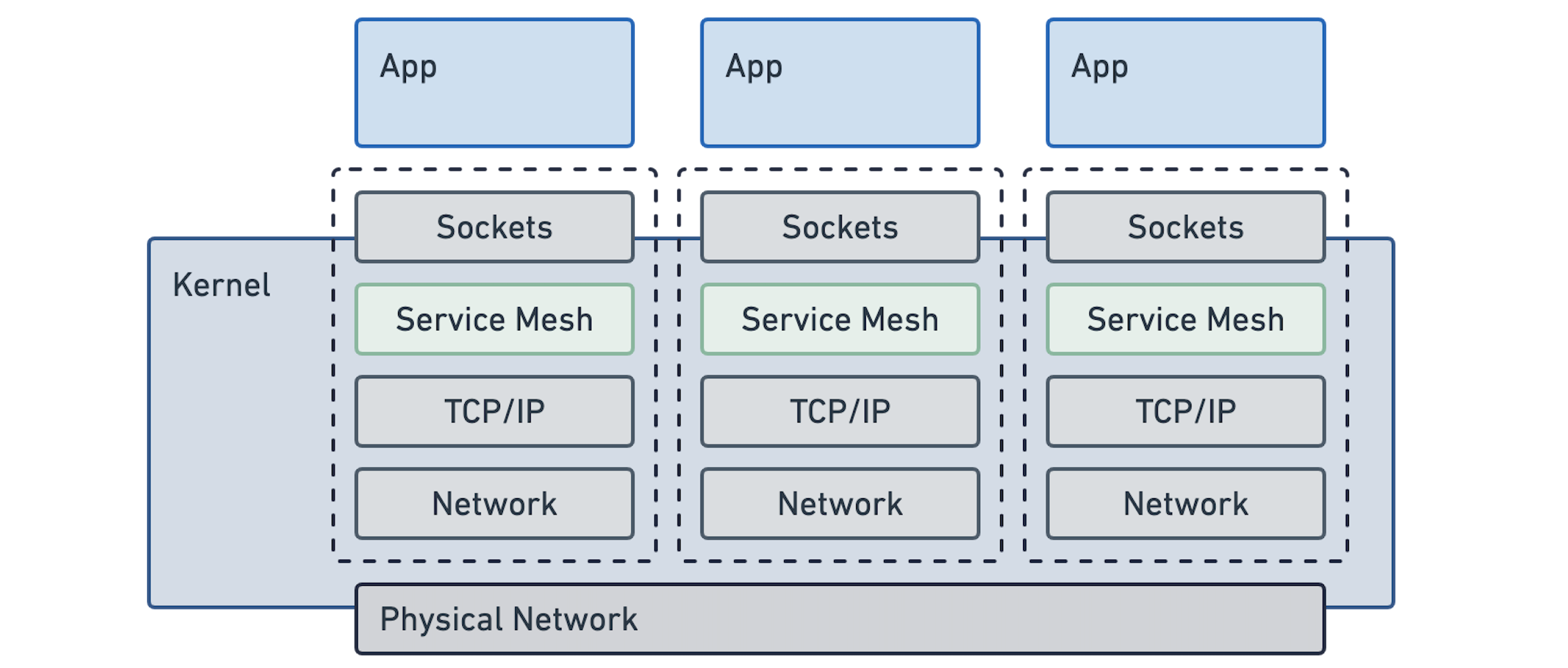 不出所料,这看起来非常自然,可能是大多数用户对简单的角度来看的。应用程序保持不变,它们继续使用套接字以始终拥有。理想的服务网格功能是透明地提供的,作为Linux的一部分。它就在那里,就像今天的TCP一样。
不出所料,这看起来非常自然,可能是大多数用户对简单的角度来看的。应用程序保持不变,它们继续使用套接字以始终拥有。理想的服务网格功能是透明地提供的,作为Linux的一部分。它就在那里,就像今天的TCP一样。
Sidecar 注入的成本
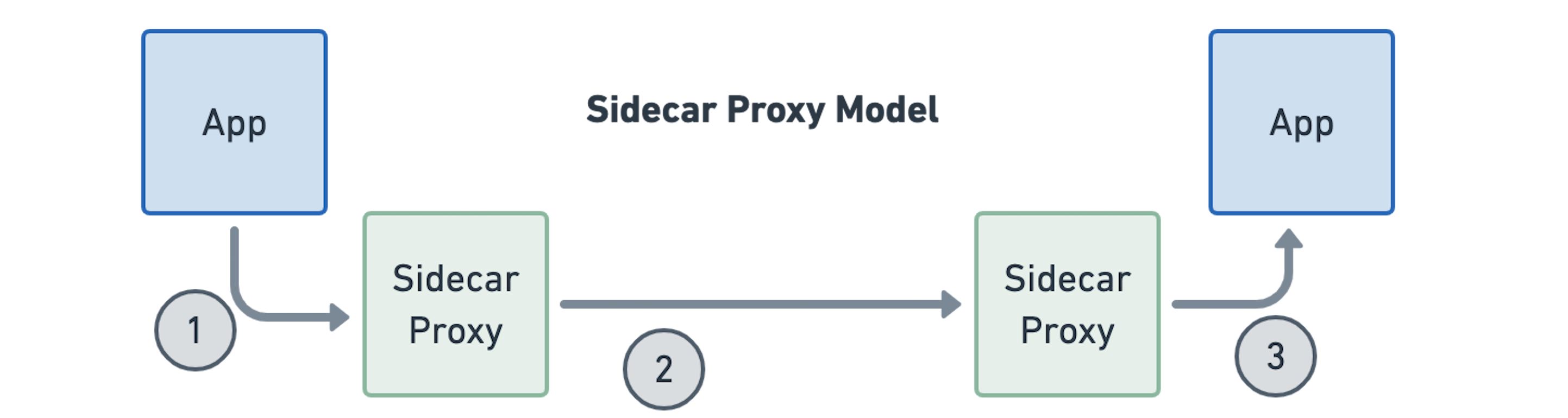
如果我们看起来更接近Sidecar模型,我们会注意到它实际上是试图模拟此模型。应用程序继续使用套接字,并将所有内容填充到Linux内核的网络命名空间中。 但是,它比看起来更复杂,需要许多额外的步骤来透明地注入Sidecar代理:
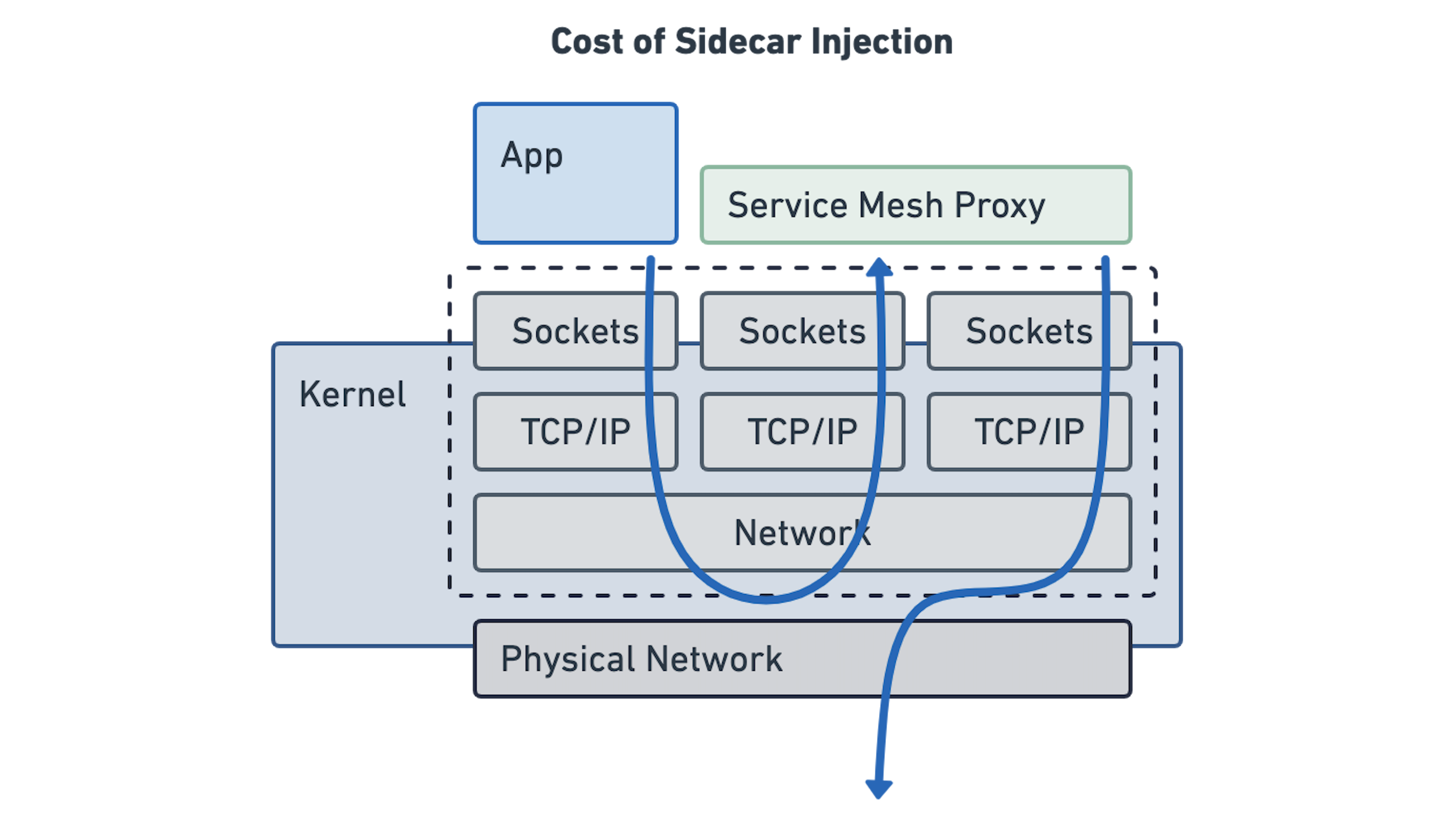
在延迟和额外资源消耗方面,这种额外的复杂性具有很大的成本。早期基准测试表明,这可能会影响到3-4倍的延迟,并且所有代理都需要大量的额外存储器。当我们将其与基于eBPF的模型进行比较时,我们将在此帖子中调查稍后介绍。
使用EBPF解锁内核服务网格
为什么我们之前没有在内核中创建服务网格?Kube-Proxy是一个很好的例子,Linux内核能够实现服务网格,同时依赖于使用iptables实现的传统网络的功能。但是,它是不够的,因为L7上下文缺失。Kube-Proxy专门在网络数据包级别运行。L7流量管理,追踪,认证和现代应用需要额外的可靠性保证。Kube-Proxy无法在网络级别提供此功能。
eBPF 改变了这个等式。它允许动态扩展Linux内核的功能。我们一直在使用eBPF for Cilium来构建一个高效的网络,安全性和可观察性datapath ,可直接嵌入Linux内核。 应用同一概念,我们也可以在内核级别解决服务网格要求。事实上,Cilium 已经实现了各种所需的概念,如基于身份的安全性,L3-L7可观察性和授权,加密和负载平衡。 缺失的部分现在即将来临。您将找到有关如何加入在本博客结束时由Cilium社区驱动的Cilium Service Mesh Beta程序的详细信息。
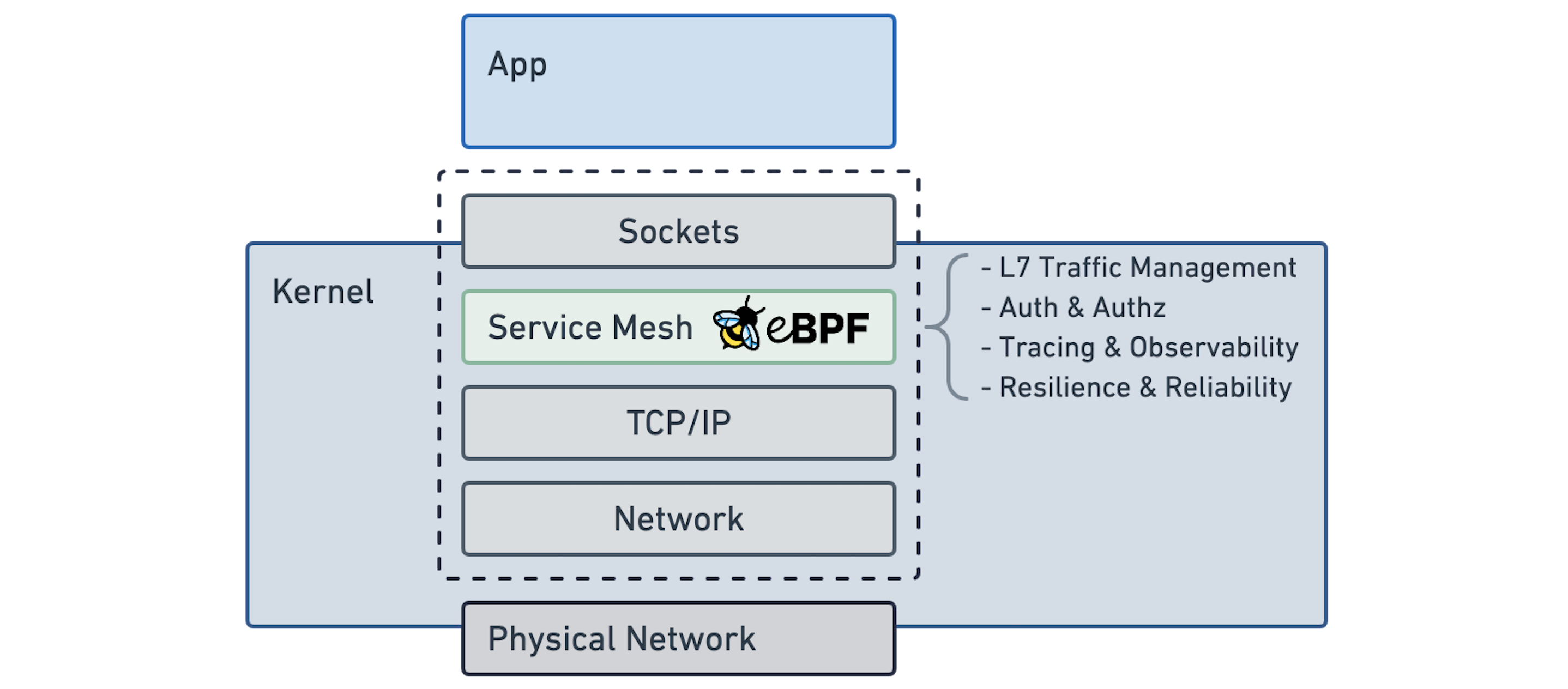 有些人可能想知道为什么Linux内核社区没有直接解决这些要求。eBPF 具有大量优势。eBPF代码可以在运行时插入到类似于Linux内核模块的现有Linux内核中,但与内核模块不同,它可以以安全和便携的方式完成。这允许EBPF实现继续与服务网格社区的发展。新的内核版本需要数年才能将其交给用户手中。eBPF是允许Linux内核跟上快速不断变化的云原生技术栈的关键技术。
有些人可能想知道为什么Linux内核社区没有直接解决这些要求。eBPF 具有大量优势。eBPF代码可以在运行时插入到类似于Linux内核模块的现有Linux内核中,但与内核模块不同,它可以以安全和便携的方式完成。这允许EBPF实现继续与服务网格社区的发展。新的内核版本需要数年才能将其交给用户手中。eBPF是允许Linux内核跟上快速不断变化的云原生技术栈的关键技术。
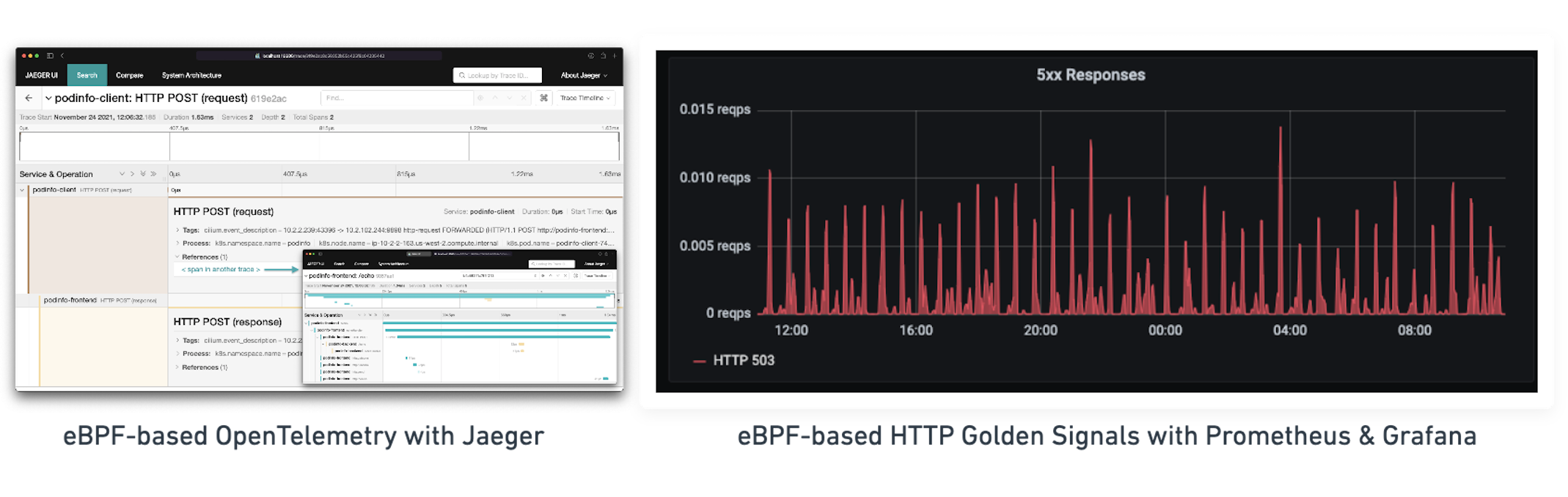
基于eBPF的L7追踪和指标,没有Sidecars
让我们看一下L7跟踪和度量可观察性,作为一种基于eBPF的服务网格的具体示例,对保留低延迟并保持可观察性低的成本。应用团队依靠应用程序可见性和监控作为基本要求,这包括诸如请求跟踪,HTTP响应率和服务延迟信息等功能。然而,这种可观察性应无重大成本(延迟,复杂性,资源,…)。
 在下面的基准测试中,我们看到早期测量如何使用EBPF或Sidecar方法实现HTTP可见性影响延迟。设置在两个不同节点上运行的两个窗口之间的固定数量的连接数上运行一个稳定的10k HTTP请求,并测量请求的平均延迟。
在下面的基准测试中,我们看到早期测量如何使用EBPF或Sidecar方法实现HTTP可见性影响延迟。设置在两个不同节点上运行的两个窗口之间的固定数量的连接数上运行一个稳定的10k HTTP请求,并测量请求的平均延迟。
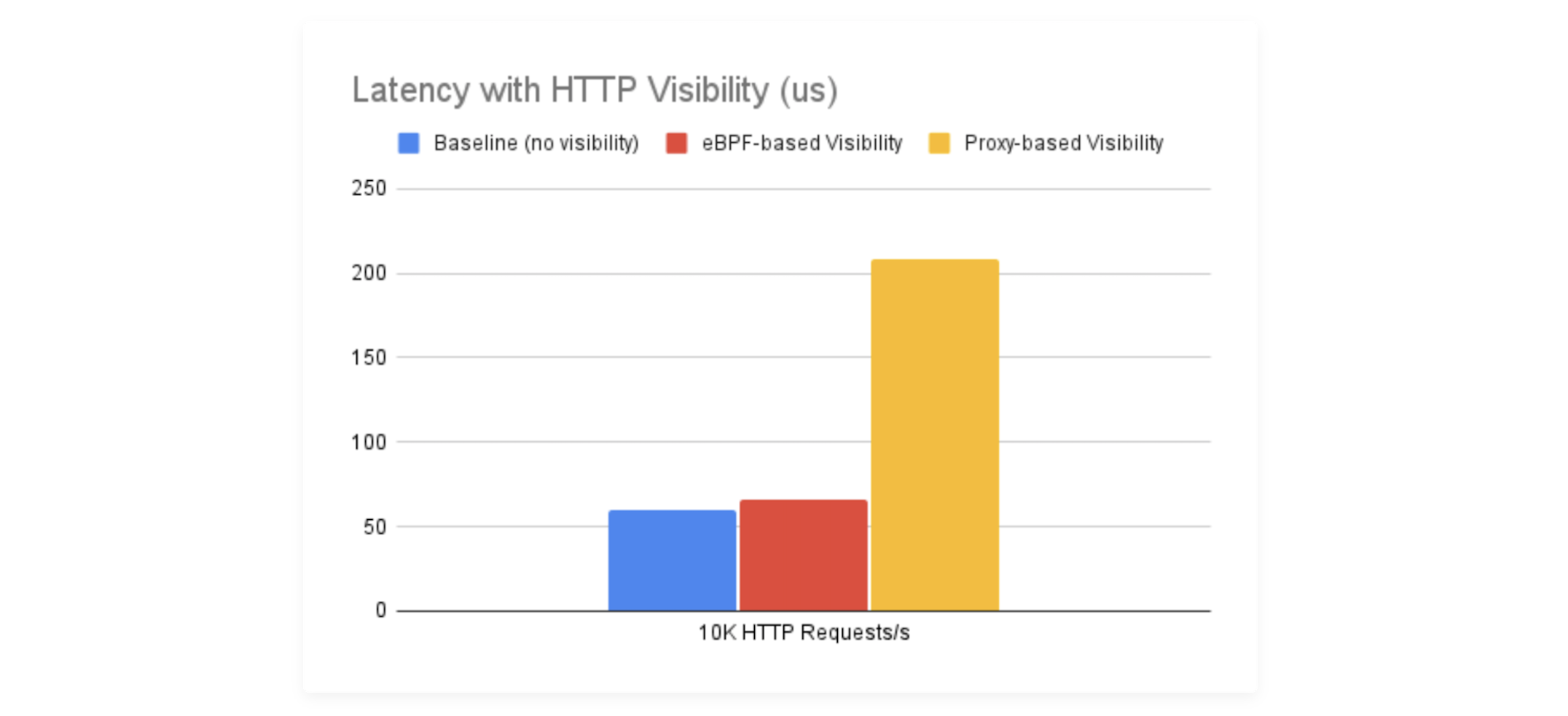
我们故意没有提及这些测量中使用的特定代理,因为它无关紧要。对于我们测试的所有代理,结果几乎相同。要清楚,这不是关于Envoy,Linkerd,nginx还是另一个更快的代理。所提到的代理有差异,但与首先注入代理的成本相比,它们是微不足道的。几乎没有一个开销来自代理本身的逻辑。通过注入代理,将网络流量重定向到它,终止连接和启动新连接导致增加开销。
这些早期的测量使得基于eBPF的内核方法非常有前途,并且可以在没有明显的开销下实现完全透明的服务网格功能的愿望。
eBPF加速每个节点代理
使用此eBPF的方法可以涵盖越来越多的使用情况,因此完全没有使用L4代理。对于某些用例,仍然需要代理。例如,当Connections需要拼接时,当正在执行TLS终止时,或用于某种形式的HTTP授权时。
我们的eBPF 服务网格努力将继续关注最多的场景。如果您必须执行TLS终止,您可能无法介入一次与代理的连接一次,如果您必须执行TLS终止。但是,您将更多地关心将两个代理注入每个连接到每一个连接的路径的影响,以便提取HTTP指标和跟踪数据。
当使用eBPF的方法无法实现使用情况时,网格可以返回到每个节点代理模型,该模型直接与内核的套接字层集成了代理。
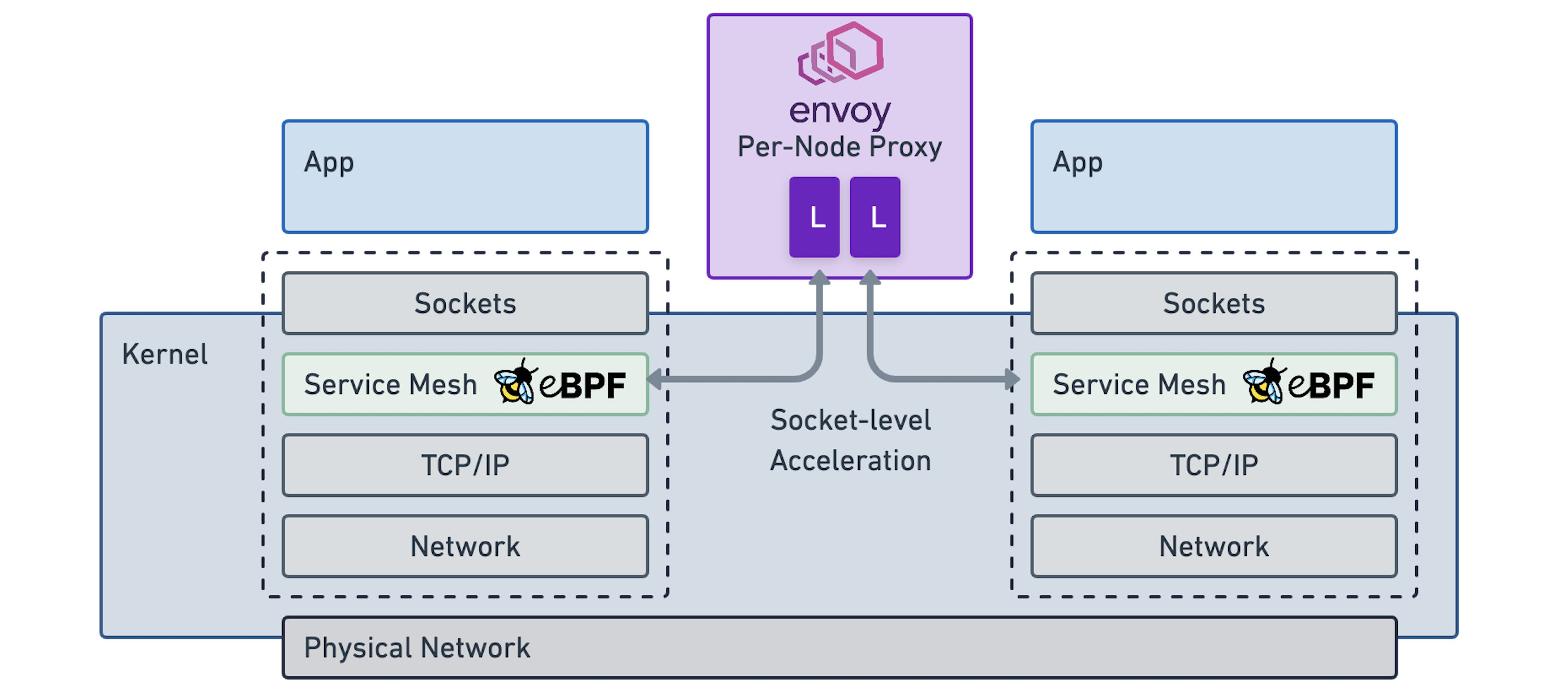 eBPF 不能依赖网络级重定向,而是可以直接在套接字级别注入代理,保持最短路径。在Cilium下,使用Envoy虽然从架构的角度来看,可以将任何代理集成到该模型中。概念上,这允许将Linux内核网络命名空间的概念直接扩展到Envoy 侦听器配置的概念,使Envoy 转变为多租户代理。
eBPF 不能依赖网络级重定向,而是可以直接在套接字级别注入代理,保持最短路径。在Cilium下,使用Envoy虽然从架构的角度来看,可以将任何代理集成到该模型中。概念上,这允许将Linux内核网络命名空间的概念直接扩展到Envoy 侦听器配置的概念,使Envoy 转变为多租户代理。
Sidecar vs per-node proxy
即使需要代理,代理的成本也会因部署的架构而异。让我们看看每个节点代理模型与Sidecar模型相比,看看它们是如何比较的。
每个连接代理
所需的网络连接数量会根据图片中是否在图片中而异。最简单的方案是无sidecar的模型,这意味着没有对网络连接数的更改。单个连接将满足请求,eBPF 将提供服务网格功能,例如在现有连接上进行跟踪或负载平衡。
提供具有Sidecar模型的相同功能,需要将代理注入两次,这导致需要维护的三个连接。这导致所有额外的套接字缓冲区所需内存的开销和乘法增加,这在更高级服务到服务延迟。这是我们在Sidecarless L7可见性部分之前看到的Sidecar开销。
 切换到每个节点代理模型允许我们摆脱一个代理,因为我们不再依赖于每个工作负载内部运行sidecar。仍然不太理想,而不是额外的必要连接,但优于始终需要两个附加连接。
切换到每个节点代理模型允许我们摆脱一个代理,因为我们不再依赖于每个工作负载内部运行sidecar。仍然不太理想,而不是额外的必要连接,但优于始终需要两个附加连接。

总代理所需的数量
在每个工作量中运行Sidecar可能导致大量代理。即使每个单独的代理实例都在其内存占用空间中非常优化,均为庞大的实例将导致繁重的全面影响。此外,每个代理维护数据结构,例如随着群集增长而生长的路由和端点表,因此群集的每个代理的存储器消耗越大。今天某些服务网格试图通过将部分路由表推向单个代理来解决这个问题,限制他们路由。
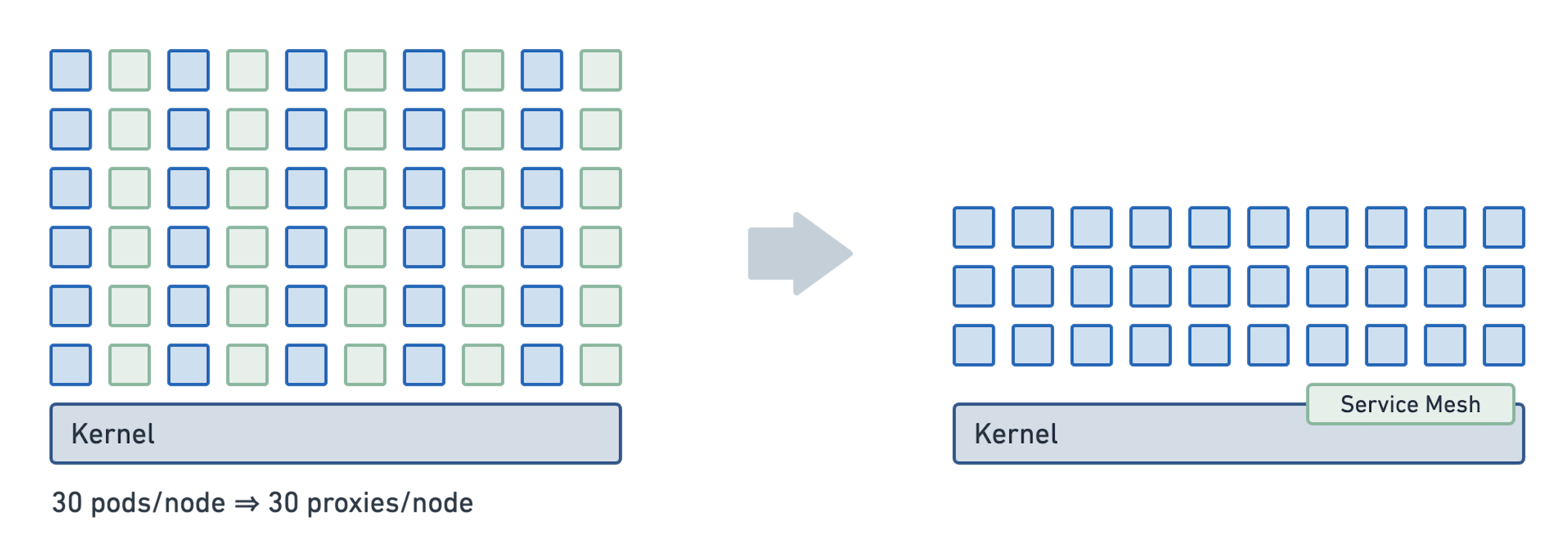
让我们假设500节点集群中的30个Pods /节点,基于Sidecar的架构将需要运行15k代理。每个代理消耗的70MB内存(已经假设严重优化的路由表),这仍然会导致群集中的所有Sidecars消耗的1TB内存。在每个节点模型中,使用每个代理的相同假定的内存占用空间,500个代理将消耗不超过34GB的内存。
多租户
当我们从Sidecar模型移动到每个节点(per-node)模型时,代理将为多个应用程序提供服务。代理必须成为多租户。 这与我们从使用单独的虚拟机转换为使用容器时,这完全相同的转换。当我们使用全部虚拟机中运行的操作系统的完全单独的副本停止并开始与多个应用程序共享操作系统时,Linux必须成为多租户感知。这就是为什么存在命名空间和cgroups。没有它们,一个容器可以消耗系统和容器的所有资源可以以不受控制的方式访问彼此的文件系统。
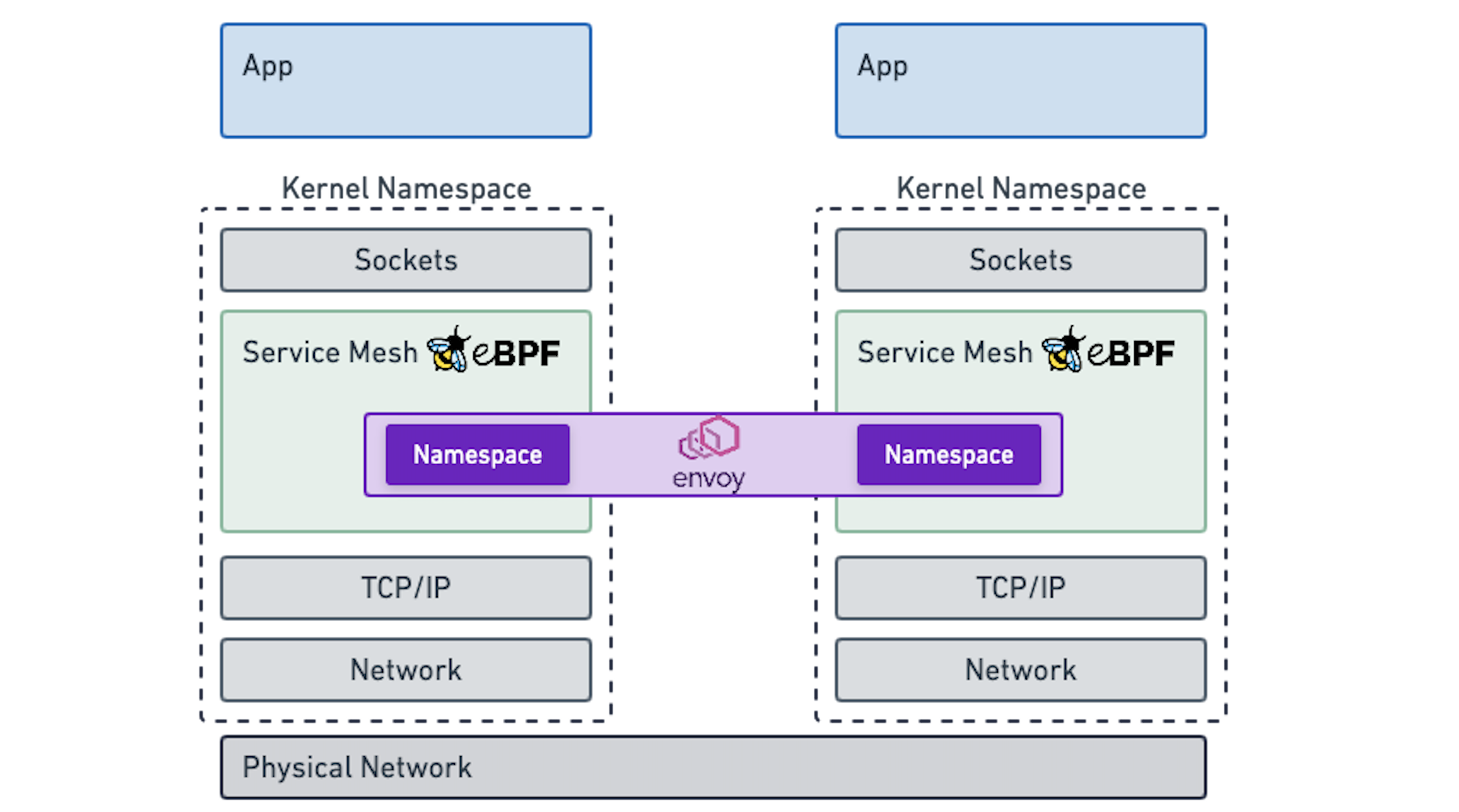
如果在服务网格级别的网络资源表现完全相同,那么它不会很好吗?Envoy 已经有一个名称空间的初始概念,它们被称为侦听器。 侦听器可以携带各个配置并独立运行。这将全新的可能性开放:突然间,我们可以轻松控制资源消耗并建立公平的排队规则,并将可用资源同样地分发到所有应用程序或根据指定的规则分发。这可以看起来与我们在今天定义Kubernetes中的应用程序的CPU和内存约束完全相同。如果您想了解有关此主题的更多信息,我已经在Envoycon上发表了关于此信息(Envoy Namespaces - Operating an Envoy-based Service Mesh at a Fraction of the Cost, Thomas Graf, EnvoyCon 2019)操作基于Envoy的服务网格。
想参与吗? - 加入Cilium Service Mesh Beta
凭借即将到来的Cilium 1.11发布,Cilium社区正在托管一个新的Cilium 服务网格测试程序。它具有一个新的构建,可以提供以下功能:
- L7 Traffic Management & Load-balancing (HTTP, gRPC, …)
- Topology Aware Routing across clusters, clouds, and premises
TLS Termination - Canary Rollouts, Retries, Rate Limiting, Circuit Breaking, etc, configured through Envoy
- Tracing with OpenTelemetry & Jaeger integration
- Built-in Kubernetes Ingress Support
GitHub.com/cilium/cilium上的feature 分支提供以上所有功能。Beta程序允许Cilium维护者直接与用户与用户一起参与他们的需求。要注册,您可以直接填写此表格,或者您可以在Cilium社区宣布公告中阅读有关该计划的更多信息。
总结
eBPF 是提供本机和高效服务网格实现的答案。它将释放我们的Sidecar模型,并允许将现有的代理技术集成到现有的内核命名范围概念中,允许它们成为我们已经每天使用的美丽容器抽象的一部分。在此之上,EBPF将能够卸载更多和更多的功能,该功能是通过代理执行的,以进一步降低开销和复杂性。通过能够集成几乎任何现有的代理,该体系结构还允许与大多数现有服务网格控制(Istio,SMI,Linkerd,…)集成。这将使eBPF 可用于广泛的终端用户。
如果您有兴趣探索此空间,我们很乐意收到您的来信。通过伸出Twitter或EBPF和Cilium Slack,可以随意接触。
更多阅读
How eBPF Streamlines the Service Mesh, Liz Rice, The New Stack
Cilium Service Mesh Beta Program, Cilium Community
Learn more about Cilium

