hadoop环境搭建
文章目录
- 网络配置
-
- 防火墙
- 设置主机名
- 修改域名映射
- 配置静态ip
- 远程拷贝
- 配置免密登录
- 文件操作常用指令
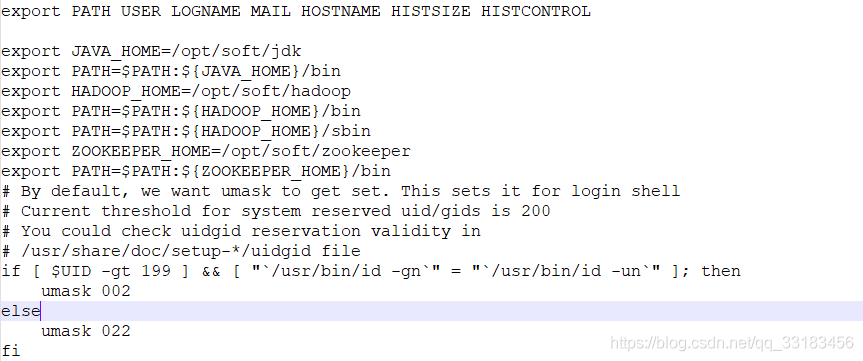
- 配置java环境路径;
- hadoop伪分布式环境搭建与测试单词统计(wordcount)
- 分布式hadoop环境搭建
网络配置
防火墙
查看防火墙状态 systemctl status firewalld 启动防火墙 systemctk start firewalld 停止防火墙 systemctl stop firewalld 禁用防火墙(永久) systemctl disable firewalld 启动网络 service network start systemctl start network 停用网络 service network stop systemctl stop network 重启网络systemctl restart networkservice network restart 查看ip ifconfig设置主机名
vim /etc/hostname //修改为master 删掉原来的localdomain hostnamectl set-hostname master //配置立即生效修改域名映射
vim /etc/hosts 127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4::1 localhost localhost.localdomain localhost6 localhost6.localdomain6192.168.242.150 master //主192.168.242.151 slave01 //从192.168.242.152 slave02 //从配置静态ip
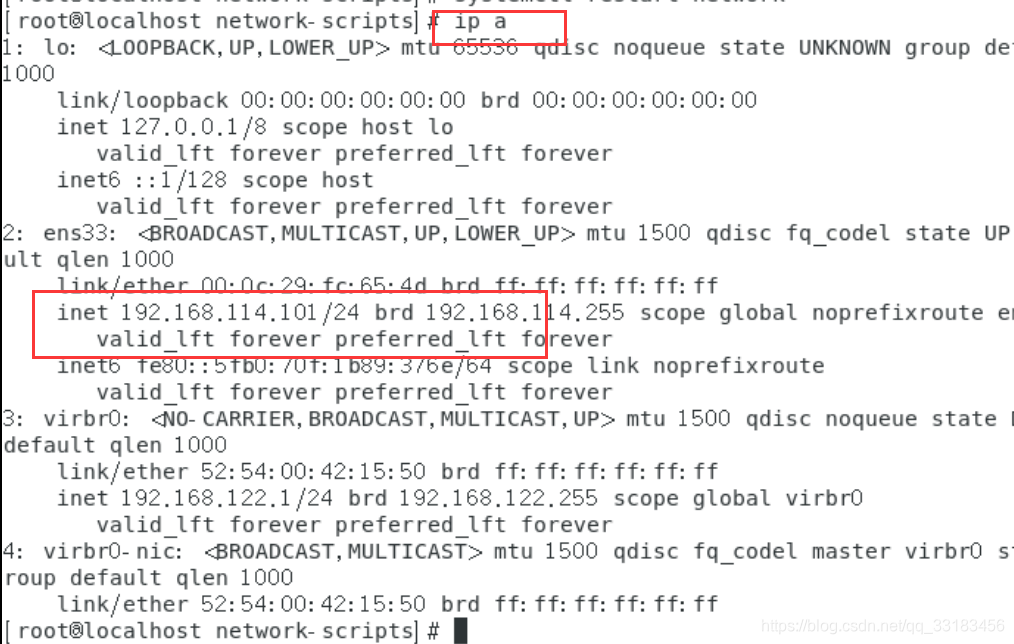
vim /etc/sysconfig/network-scripts/ifcfg-ens33TYPE=EthernetPROXY_METHOD=noneBROWSER_ONLY=noBOOTPROTO=static //static表示静态DEFROUTE=yesIPV4_FAILURE_FATAL=noIPV6INIT=yesIPV6_AUTOCONF=yesIPV6_DEFROUTE=yesIPV6_FAILURE_FATAL=noIPV6_ADDR_GEN_MODE=stable-privacyNAME=ens33UUID=43e9406b-777b-43cc-aa8a-9f664c069fe4DEVICE=ens33ONBOOT=yes //yes表示随着开机生效IPADDR=192.168.242.150 //静态ip的地址GATEWAY=192.168.242.2 //网关DNS=114.114.114.114 //dns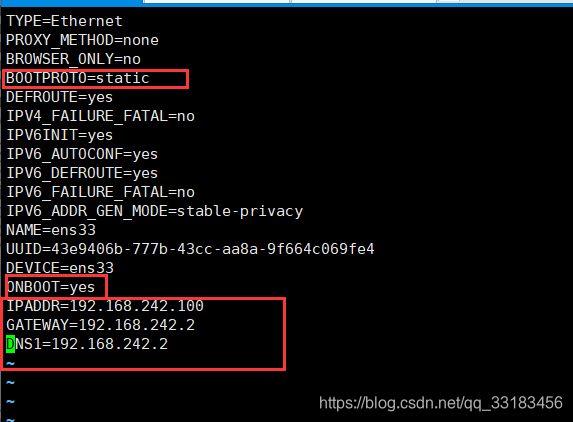
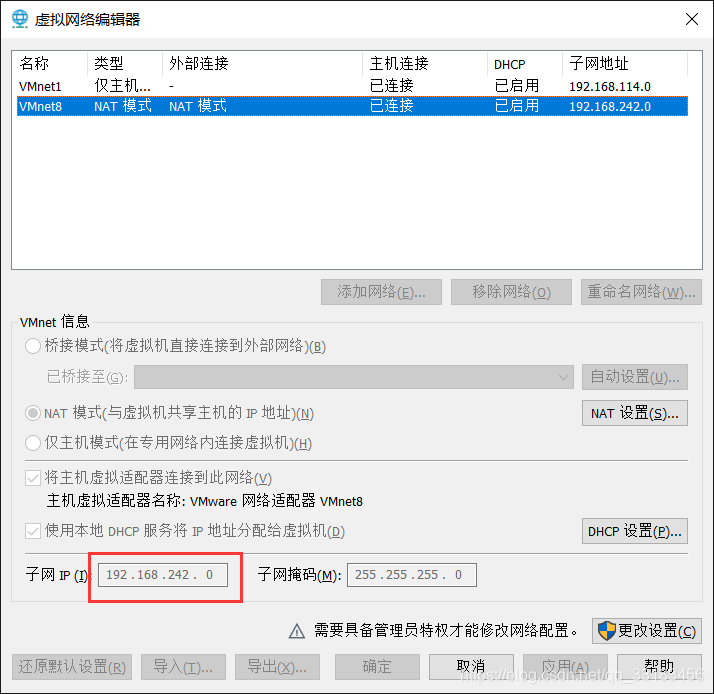
一般最好和虚拟机网络编辑器里的vmnet8的ip处于同一网段和网关一致。网络模式为NAT模式,不适用桥接模式



vim /etc/hosts
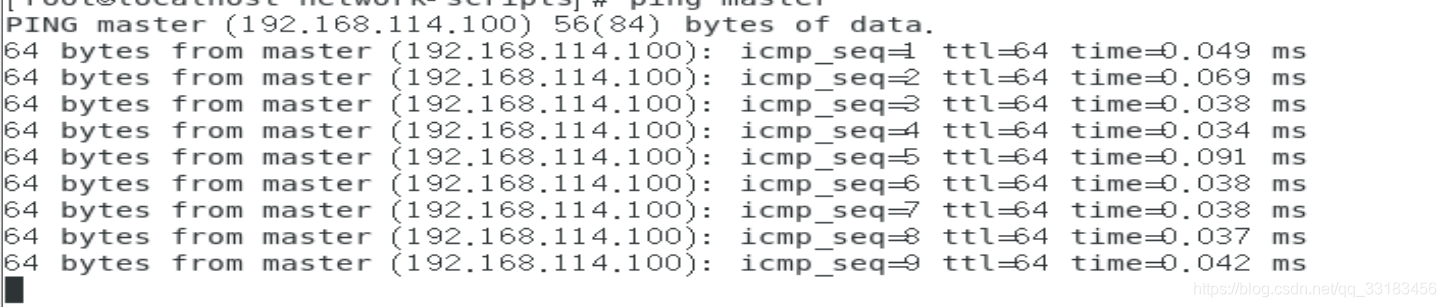
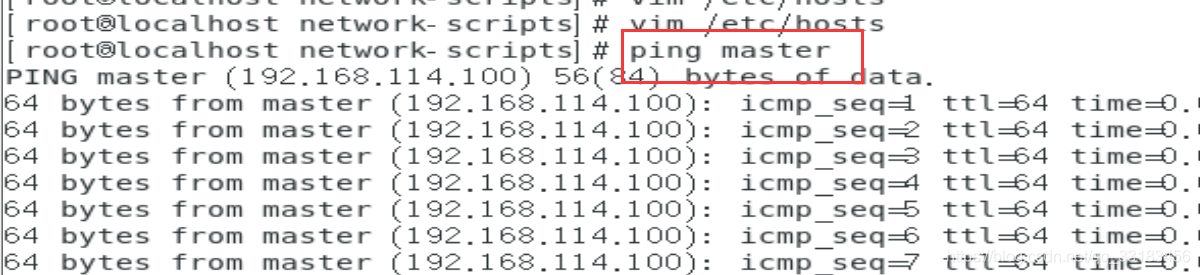


修改完host要重启一下network

远程拷贝

配置免密登录
备份和下发给其他主机

解压 zoopkeeper jdk hadoop

删除压缩包
rm -f ....tar.gz改名
mv 
修改master /etc/profie文件
文件操作常用指令
ls 查看某个目录ls / 查看根目录 ls -a /opt/soft 查看隐藏文件ls -l 表示以列表详细信息查看ls -la - 表示文件d 表示目录cd ~ 回到当前用户对应的根目录 cd .. 回到上级目录pwd 查看当前目录文件权限
chmod [-R] 数字标识 文件或目录chmod read4/write2/exucte1 所有7代表可读可写可执行chmod 777 /opt第一个代表当前用户第二个代表当前用户所在的用户组第三个表示其他chmod 640 /test 表示当前用户可读可写 同组用户可读不能写不能执行 其他用户没有任何权限文件创建
mkdir s mkdir -p s/childs 创建多级目录 要加-prm -r 删除目录 递归删除 有提示rm -f 删除文件 强制删除文件复制
cp a b 复制a到bscp test slave01:/opt 远程拷贝文件test 到slave01机器的opt目录scp -r testdirec slave01:/opt 远程拷贝文件夹 -r表递归文件移动
mv hadoop24.12 hadoop 移动或改名 解压缩
压缩tar -czf test.tar.gz /test/*tar -zxvf 配置java环境路径;
查看系统自带的jdk
rpm -qa |grep jdk卸载所有的jdk
yum -y remove java-1.*方法一:较安全,配置出错不会影响系统
cd /etc/profile.d //profiled.d 目录下的sh脚本开机启动会执行,所以将配置文件写在这下面vim hadoop-env.sh JAVA_HOME=/usr/local/src/jdk //定义java环境变量 PATH=$JAVA_HOME:$PATH // 把javahome追加到path之前 PATH=$PATH :$JAVA_HOME追加到path之后source hadoop-env.sh //让环境立即生效方法二:
在/etc/profile中进行配置
vim /etc/profile export JAVA_HOME=/usr/local/src/jdk export PATH=$PATH:$JAVA_HOME/bin方法三
在用户的根目录下进行配置,只对当前用户生效。
cd ~vim .bash_profile export JAVA_HOME=/usr/local/src/jdk export PATH=$PATH:$JAVA_HOME/bin配置完成后使用source指令将配置信息应用一下
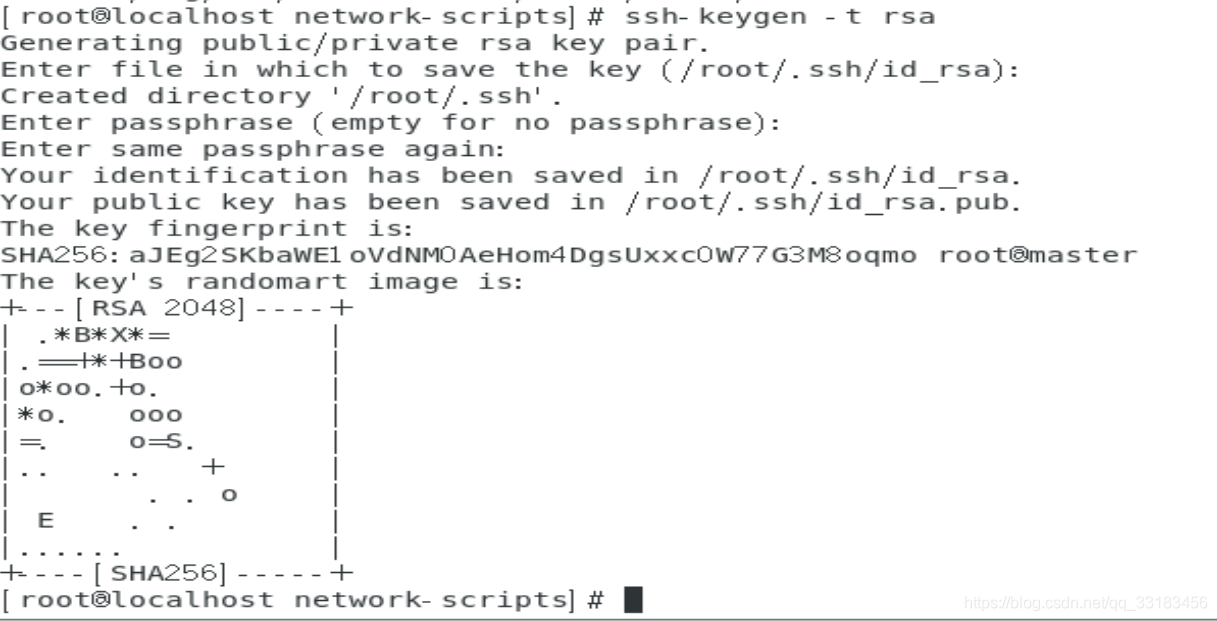
配置免密登录
ssh-keygen -t rsa 生成公钥 ssh-copy-id -i root@master 将公钥下发给要远程连接的服务。自己也得保存一份(hadoop操作本机时,hadoop相对于第三方)hadoop伪分布式环境搭建与测试单词统计(wordcount)
hadoop核心组件
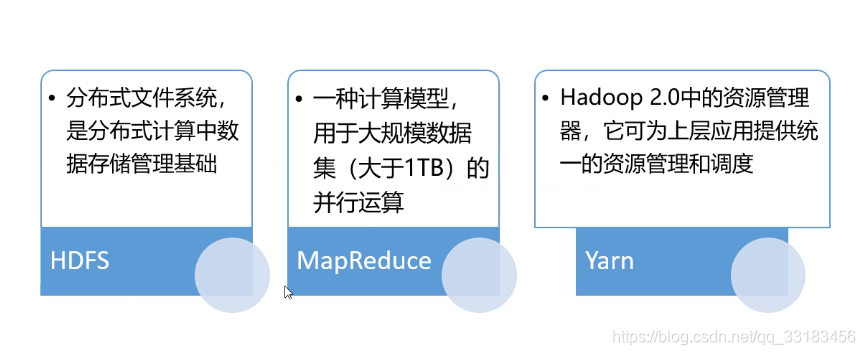
hadoop伪分布式环境搭建:
1.使用xftp上传hadoop...gz包到指定路径2.解压hadoop包到/usr/local/src下 : tar -zxvf hadoop...文件名 -C /usr/local/src3.重命名 mv 改名为hadoop: mv hadoopXX.... hadoop4、配置环境变量,将hadoop下的bin和sbin追加到系统PATH中方法一:将下面两句追加到/etc/profile文件中 export HADOOP_HOME=/usr/....../hadoop export PATH=$PATH:$HADOOP_HOME/bin$HADOOP_HOME/sbin: 方法二:追加脚本至/etc/profile.d/hadoop-env.sh JAVA_HOME=/usr/local/src/jdkPATH=$JAVA_HOME/bin:$PATHHADOOP_HOME=/usr/local/src/hadoopPATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin source /etc/profile.d/hadoop-env.sh 应用下追加的环境变量 hadoop version 查看hadoop版本 5、修改hadoop相关配置文件: 1)hadoop-env.sh 修改jdk的路径即可:export JAVA_HOME=/usr/local/src/jdk 2)core-site.xml fs.defaultFShdfs://master:9000 hadoop.tmp.dir/opt/hadoop/data 3)hdfs-site.xml dfs.replication 1 4)mapred-site.xml 需要先根据模板拷贝一个出来: cp mapred-site.xml.template mapred-site.xml mapreduce.framework.name yarn 5)yarn-site.xml yarn.resourcemanager.hostname master //主机节点名称 yarn.nodemanager.aux-services mapreduce_shuffle 6、格式化hdfs(格式化后不要再次格式化,报错,除非将元数据目录删除掉再格式化) hdfs namenode -format7、启动hadoop 1)单节点启动(不推荐,麻烦) 2)脚本启动 start-all.sh(相当于下面2个合而为一) 分开:start-dfs.sh ---启动hdfs文件存储系统 start-yarn.sh ---启动yarn资源管理调度mapreduce运行服务8、启动后能够看到下面的进程(表示配置正确,如果缺少的,则代表对应配置存在问题,可查询对应日志来进行配置更改): DataNode ResourceManager NameNode SecondaryNameNode NodeManager9、通过浏览器访问hdfs文件系统: http://主机IP:50070 通过浏览器访问yarn资源管理界面 http://主机IP:808810、停止hadoop: stop-all.sh测试单词计数:
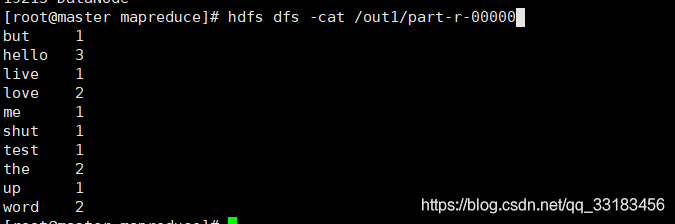
1.在hdfs文件空间里面创建文件夹hdfs dfs -mkdir /test2.上传文件到hdfshdfs dfs -put word.txt /test //将文件上传至/test目录下 word.txt提前编辑好下载hdfs dfs -get /test/word.txt downloadword.txt //下载文件到当前目录 并重命名未downloadword.txt3.启动wordcount完成单词计数hadoop jar hadoop-mapreduce-examples-2.6.0.jar wordcount /test/word.txt /out1 ----/out1必须是一个不存在的目录4.查看计数结果hdfs dfs -cat /out1/part-r-00000