01.深入理解乱码的原理
1. 前言
专栏介绍本篇文章是此专栏的第一篇文章,在这之前,请允许我介绍一下本专栏:你是否在学习过程中遇见了不认识的名词一脸懵逼?你是否因为计算机的基础知识不合格陷入了学不会的死循环?你是否在老师讲课的时候被抛出来的一系列名词不知所措?本专栏就是为了解决这方面的问题本专栏一周保持一篇左右的更新喜欢的点点关注 非常感谢2.什么是乱码
- 这里不放任何的定义和理论,只用最简单的话来讲
- 乱码就是你所遇到的"锟斤拷烫烫烫"和一些很奇怪的字符,它们就是乱码
3.逆向分析
我们在因特网上随便复制一段乱码,将它保存为UTF-8格式,使用VS编辑器打开.
3.1 开始分析

- 现在展现给我们的是一段乱码,我们开始对这段乱码进行逆向分析
- 我们要找到这些特殊字符是什么
3.2 二进制分析
- 要想知道一段乱码的默认格式是什么,我们先从二进制开始分析
- 使用Visual Studio二进制方式进行打开
- 如图,出现的都是二进制数字,以十六进制进行展示.
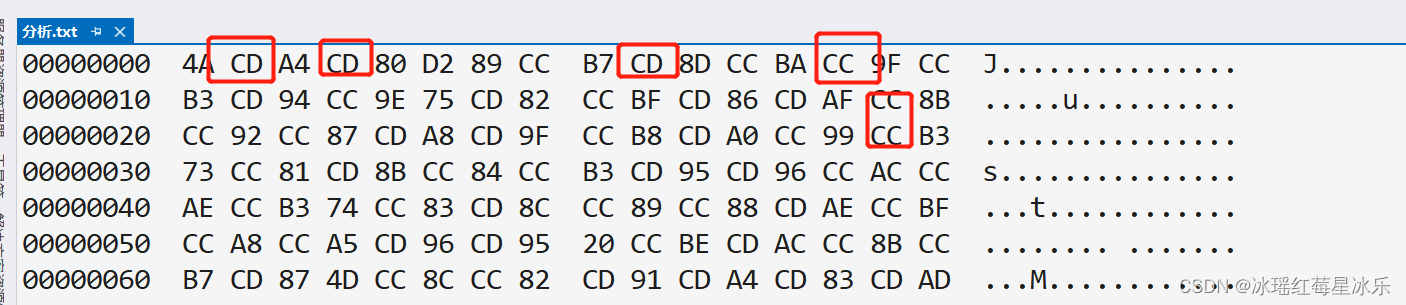
- 我们可以看到很多CD 和CC开头的数据
- 结合UTF-8编码知识

- 由此我们可以推断出,CC和CD并不是代表1字符,而是和后面的A4一起,两个字节代表出的一个字符
3.3 验证
- 为了验证我们上面的猜想,我们把别的数据全部删除,把CD和A4多重复几次.

- 保存一下,以文本方式打开

- 现在就变成了一个字符了,因此,我们的猜想正确
- 复制到网页里,就能查看到效果了
- 数一下字符上面的符号,正好和我们CD A4的数量一致

- 因此 我们可以说 我们目前为止的推断完全正确
3.4 这个字符是什么
- 我们可以从此出发,推断出 : 就是这个字符导致了奇怪的形式
- 因此,我们去查看一下这个字符在Unicode的编号
- CD A4只是UTF-8的编号,而不并不是Unicode的编号
- 根据UTF-8的编码规则,逆向推论,得到编码 : 0364
- 去搜索0364的unicode,得到结果 : 拉丁的小字母 e

- 因此,我们得到了结果 : 这个乱码是Unicode中的拉丁小字母e

