【数据结构】哈希表详解 -- 学懂全靠这篇文章啦
【哈希表】目录
- 1. 什么是哈希表 ?
- 2. 什么是 key ?
- 3. 什么是哈希冲突 ?
- 4. 怎样尽可能降低冲突率 ?
- 5.如何处理哈希冲突 ?
-
- 5.1 开放地址法 (闭散列)
-
- (1). 线性探测
- (2). 二次探测
- (3). 再哈希法
- 5.2 链表法 (开散列、哈希桶)
- 6. 哈希表主要方法实现
-
- get() 方法
- put() 方法
- growCapacity() 扩容方法
- remove() 方法
- size() 方法
- isEmpty() 方法
- 总结
1. 什么是哈希表 ?
哈希表 :Hash table,也叫散列表,它是专门研究动态数据集查找的数据集结构,根据键(key)分类而直接访问在内存存储位置。也就是说,它通过计算一个关于键值的函数,将所需查询的数据映射到表中一个位置来访问记录
分类标准:以 Hash 函数形式体现
Hash 函数要求
硬性要求:同一个 key,经过多次 Hash,结果应该是一致的
软性要求:Hash 后的结果要尽可能均匀
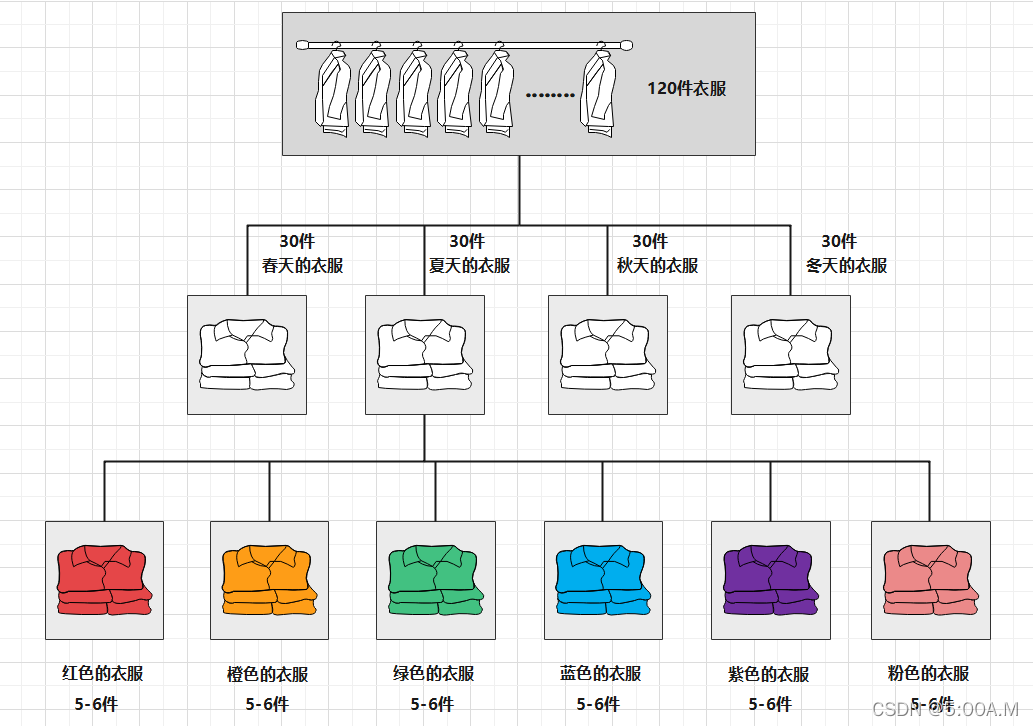
举一个生活中的例子
假设我有 120 件甚至更多的衣服,每次找衣服的时候按照常规的找法一件一件找的话是很费时间的,所以我们可以将这些衣服先进行分类放入不同的衣柜,可以分为春、夏、秋、冬四个季节的衣服,然后每个季节的衣服又可以分为各种颜色的衣服,还可以将各种颜色的衣服再分为不同材料的衣服,直到每一类的衣服中的数量足够小,这样在找衣服的时候只需要根据想要找的衣服的适用季节、衣服颜色以及衣服材料就可以很快的找到想要找的衣服
其中
放衣服就相当于是插入操作,根据所对应的类别,找到指定衣柜放入衣服
找衣服就相当于是查找操作,根据所对应的类别,去指定的衣柜去找衣服
卖衣服就相当于是删除操作,根据所对应的类别,去指定的衣柜取掉衣服
我们需要将元素放入到数组当中,也就是相当于将衣服放在指定的衣柜中
衣柜[ ] 数组;
int index = 函数(衣服);
衣柜 yg = 数组[index];
遍历衣柜中的衣服进行查找,因为每个衣柜的衣服数量比较少,所以遍历速度很快
2. 什么是 key ?
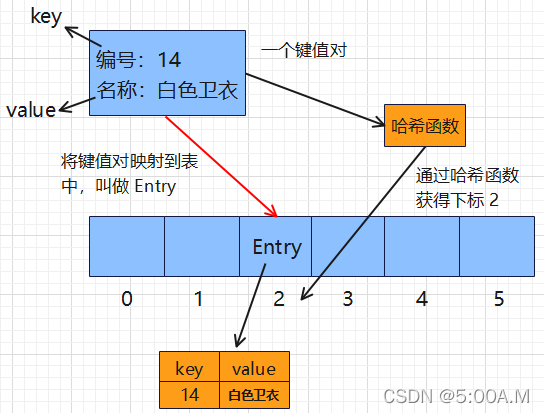
key :就是关键值的意思,在哈希表中的 key 值是不允许重复的,就说明它是唯一的,可以通过唯一的 key 来查找相应的 value 值
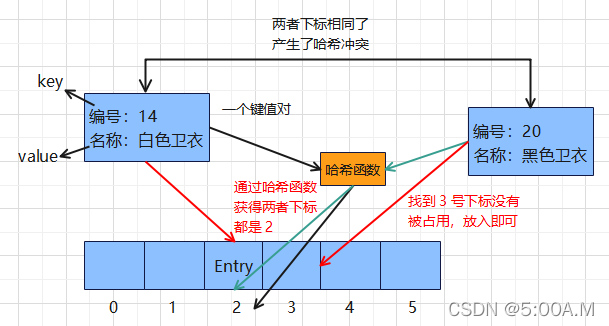
key - value 哈希表中的一对键值对
一对键值对通过哈希函数获得对应下标并映射到表中
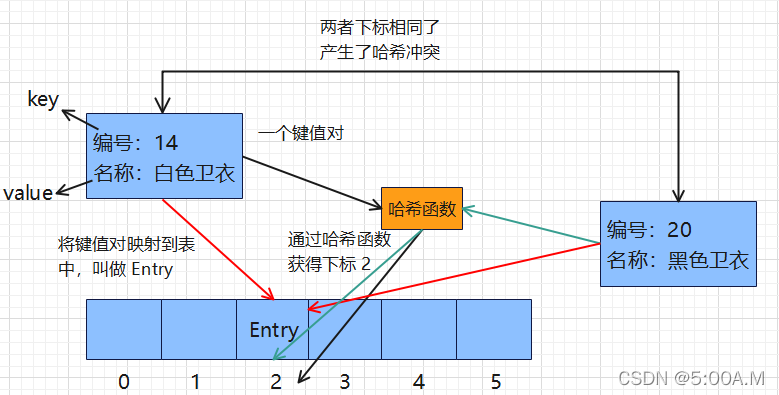
3. 什么是哈希冲突 ?
如果 k1 == k2,则 hash(k1) = h1,hash(k2) = h2,那么 h1 == h2 只要值相等,那么哈希后的结果一定相等
如果 k1 != k2,但是有 hash(k1) = h1,hash(k2) = h2 ,且 h1 == h2,那么这种现象就是哈希冲突,也叫哈希碰撞
通俗的说就是两个不相等的 key,通过 hash 函数获得了相同的下标,在往哈希表中映射时两者的位置产生冲突
思考
1.冲突多了是好事情么?
不是特别好的事情,冲突越多就相当于每个衣柜里的衣服越多,查找的时候就慢了
2.冲突可以完全避免嘛?
理论上说是可以完全避免的(只要衣柜的数量足够多,代表每个衣柜中不会有两件衣服),这样就可以完全避免冲突,但实际几乎做不到 !
4. 怎样尽可能降低冲突率 ?
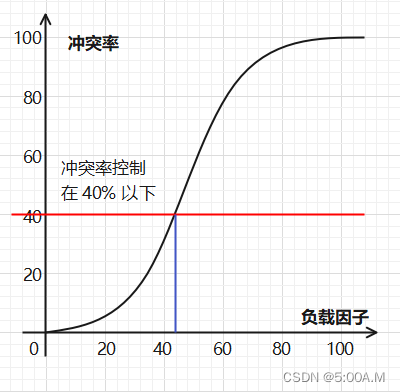
冲突率:新放入一个元素,它的冲突概率
负载因子:哈希表中已有的元素 / 哈希表的长度 (刚开始的时候没有元素,不会冲突,随着放入的元素越来越多,只要一直放入,总会让冲突率达到 100%)
所以要把负载因子控制在一个阈值之下
负载因子 size / length ,我们要想将其控制到一个阈值之内,要么减少 size,要么增大 length,但是减少 size 的情况我们一般不去考虑,那么就只有增加 length 这个方法,那么就要对哈希表进行扩容
一般将负载因子为 3 / 4 作为扩容的临界点
5.如何处理哈希冲突 ?
5.1 开放地址法 (闭散列)
开放地址法简单来说就是,如果位置已经被占用了,那么就另外再找一个没有被占用位置进行插入就可以了,寻找另外的位置要怎么找呢?基本被分为一下几种:
(1). 线性探测
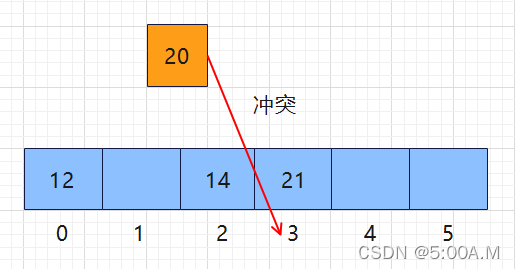
线性探测就是在遇到冲突时,从当前的下标按当前位置 + 1依次往后找 ,直到找到没有被占用的位置进行放入即可
下图中两者通过哈希后下标都为 2,那么就继续往后找,发现 3 号下标没有元素,那么直接放入,若再有其他元素要放入,按照此规则以此类推
(2). 二次探测
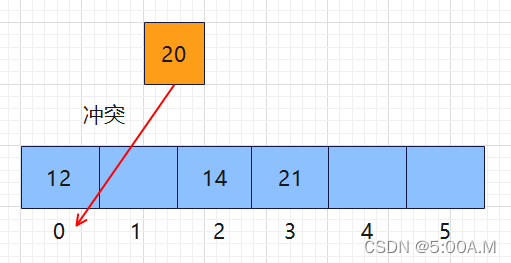
二次探测就是将线性探测每次向后探测的步长由 1 步,变为 index + 12、index + 22、index + 32、index + 42 … 依次增加,直到找到未被占用的地方为止
哈希表中已经放入 12、14、21 三个元素,现在要放入元素 20,那么先计算它的 index = 20 % 6 = 2,但 2 号下标已经被占用产生冲突,那么就从 2 号下标开始往后走 12 步,发现该位置也被占用,无法放入元素
那么就开始第二次探测,从 2 号下标开始向后走 22 步,走到 5 号下标后从 0 号下标继续往后走,发现该位置的下标也被占用产生冲突,无法放入元素
紧接着开始第三次探测,从 2 号下标开始向后走 32 步,发现该位置没有被占用,那么就不会产生冲突,直接放入元素

(3). 再哈希法
这种方法顾名思义就是在一次哈希后产生冲突了,那么我们对其再进行一次哈希产生新的 index 进行查找,若还是冲突就继续进行哈希,直到某次哈希后不会产生冲突,那么就可以进行放入了
5.2 链表法 (开散列、哈希桶)
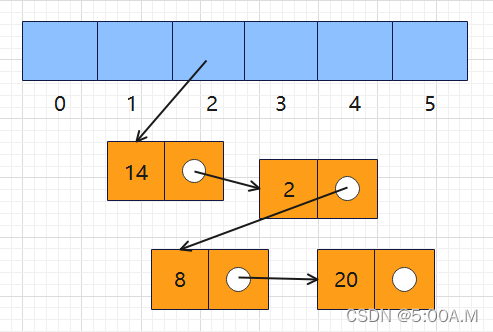
链表法其实就是在将元素放入哈希表过程中发生冲突的时候,将冲突的元素组成一条链表放在相应的哈希表的数组下标位置,就像一开始举得衣服的例子一样,将冲突的衣服放在衣柜的衣架上,衣架上挂着冲突的衣服,就像冲突的元素组织成的链表
14、2、8、20 四个元素通过哈希得到的下标都是 2,14 最先占住了这个位置,之后的元素找到下标后,元素14 的 next 就会指向元素 2,从而形成一条链表保存在下标 2 的位置。再有元素要放入下标 2 的位置时,做法还是相同的
在 java 中的 HashSet 和 HashMap 用的就使用的是开散列的方法
6. 哈希表主要方法实现
首先创建我门将的 Node 类,代表的是链表的结点
public class Node { public String key; public Long value; public Node next; public Node(String key, Long value) { this.key = key; this.value = value; }}再创建一个 MyHashMap 类,来存放哈希表的属性以及各种方法的实现
public class MyHashMap { private static final double THRESHOLD = 0.75;// 扩容的临界值 // 元素类型是链表(以链表的头结点代表)的数组 private Node[] array;// 数组的每个元素都代表一条独立的链表 private int size; public MyHashMap() { array = new Node[7]; size = 0; }get() 方法
get() 方法是用来查找哈希表中的某个元素
1.首先获取 key 的 hashCode 值,将 key 转化成一个整型,然后通过哈希化,变为一个合法的数组下标 index
2.根据 index 可以获得一条链表
3.遍历链表,查找链表中的 key 是否和 传入的 key 相等,若查询到就返回该 key 的 value 值,否则返回 null
public Long get(String key) { int n = key.hashCode(); //获取 key 的 hashCode 值 //把 n 这个整型转换成一个合法的数组下标(假设 n >= 0) int index = n % array.length; // 我们已经有了 index 这个下标,所以,可以从数组中得到一条链表 // 这个链表的头结点就是 array[index]; Node head = array[index]; //遍历整条链表 for (Node cur = head; cur != null; cur = cur.next) { // 比较 key 和 cur.key 是否相等 if (key.equals(cur.key)) { // 要用 equals 比较 // 查询到就返回该 key 的 value 值 return cur.value; } } // 说明链表都遍历完了,也没有找到 key,说明 key 不在哈希表中 // 返回 null,表示没有找到 return null; }put() 方法
put() 方法就是在哈希表中放入或者修改某个数据的操作
1.首先获取 key 的 hashCode 值,将 key 转化成一个整型,然后通过哈希化,变为一个合法的数组下标 index
2.根据 index 可以获得一条链表
3.遍历链表,查找链表中的 key 与 传入的 key 是否相等,相等则将原有的 value 值更新为传入的 value,否则将传入的 key - value 以头插方式放入链表
4.放入元素后 size++
5.判断是否需要扩容
public Long put(String key, Long value) { // 放入 or 更新 //要求和 get 必须统一 int n = key.hashCode(); //要求和 get 必须统一 int index = n % array.length; //得到代表链表的头结点 Node head = array[index]; //遍历链表,查找 key 是否存在(如果存在,则是更新操作;否则是放入操作) for (Node cur = head; cur != null; cur = cur.next) { if (key.equals(cur.key)) { // 找到了说明存在,进行更新操作 Long oldValue = cur.value; cur.value = value; return oldValue; // 返回原来的 value ,代表是更新 } } // 遍历完成,没有找到,则进行插入操作 //把 key、value 装到链表的结点中 Node node = new Node(key, value); // 使用头插 node.next = array[index]; array[index] = node; //增加 size size++; //扩容 if (1.0 * size / array.length > THRESHOLD) { growCapacity(); } //返回 null,代表插入 return null; }growCapacity() 扩容方法
growCapacity() 方法就是再负载因子大于 3 / 4 时对哈希表进行扩容来保证冲突率控制在一定范围以下
1.考虑到扩容以后,数组 length 变大,使得原来的元素的 index 会产生变化,所以需要把哈希表中的每一个 key - value 对重新计算它的 index
2.遍历数组中的每个元素(每条链表),再遍历每个链表中的每个结点(每对 key - value),重新计算其 index
3.一个个头插元素,更新它们的 next 属性
private void growCapacity() {//扩大 length Node[] newArray = new Node[array.length * 2]; for (int i = 0; i < array.length; i++) { // 遍历数组中的每个元素(每条链表) Node next; for (Node cur = array[i]; cur != null; cur = next) { // 遍历链表中的每个结点 int n = cur.key.hashCode(); int index = n % newArray.length;//重新计算 index // 按照头插的方式,将结点,插入到 newArray 的 [index] 位置的新链表中 next = cur.next; // 因为要把结点插入到新链表中,所有 next 会变化 // 为了能让老链表继续遍历下去,需要提前记录老的 next cur.next = newArray[index]; // 头插 newArray[index] = cur; } } array = newArray; }remove() 方法
remove() 方法就是再哈希表中查找某个元素并将其进行删除
1.首先获取 key 的 hashCode 值,将 key 转化成一个整型,然后通过哈希化,变为一个合法的数组下标 index
2.根据 index 可以获得一条链表
3.遍历链表,若第一个结点就是要删除的 key,那么直接让头结点变为第一个结点的下一个结点
4.若不是第一个结点,证明该结点有前驱结点,让 pre.next = cur.next,然后返回删除结点的 value
5.若没找到 key 那么就返回 null
public Long remove(String key) { // 删除 int n = key.hashCode(); int index = n % array.length; // 如果第一个结点的 key 就是要删除的 key,没有前驱结点 if (array[index] != null && key.equals(array[index].key)) { Node head = array[index]; array[index] = array[index].next; return head.value; } Node prev = null;//记录前驱结点 Node cur = array[index]; while (cur != null) { if (key.equals(cur.key)) { // 删除链表中的结点,需要前驱结点 prev.next = cur.next; // 删除 cur 结点 return cur.value; } prev = cur; cur = cur.next; } return null; }size() 方法
size() 方法就是获取哈希表中元素个数的操作
直接返回 size 即可
public int size() { return size; }isEmpty() 方法
isEmpty() 方法是判断哈希表是否为空
直接判断 size() 是否为 0
public boolean isEmpty() { return size == 0; }总结
相信到这里大家已经对哈希表有了很完整的了解,大家可以尝试着自己去完成哈希表代码的实现,并且可以去尝试刷一些相关的题目
同时大家还可以学习关于数据结构的其他相关知识
【数据结构】二叉树详解
【数据结构】二叉树的遍历(非递归)
【数据结构】五种基本排序算法

