Pytorch神经网络实战学习笔记_30 自编码神经网络专题(二):【实战】构建变分自编码神经网络模型生成模拟数据

1 变分自编码神经网络生成模拟数据案例说明
变分自编码里面真正的公式只有一个KL散度。
1.1 变分自编码神经网络模型介绍
主要由以下三个部分构成:
1.1.1 编码器
由两层全连接神经网络组成,第一层有784个维度的输入和256个维度的输出;第二层并列连接了两个全连接神经网络,每个网络都有两个维度的输出,输出的结果分别代表数据分布的均值与方差。
1.1.2 采样器
根据编码器得到的均值与方差计算出数据分布情况,从数据分布情况中采样取得数据特征z,并将z传递到两节点为开始的解码器部分。
1.1.3 解码器
由两个全连接神经网络构成,第一层有两个维度的输入和256个维度的输出;第二层有256个维度的输入和784哥维度的输出。
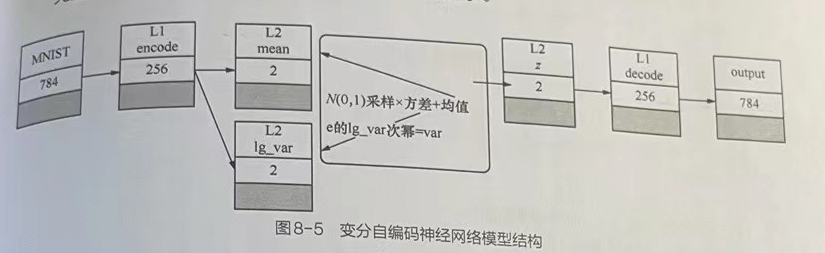
- 采样器的左侧是编码器。
- 圆角方框是采样器部分,其工作步骤如下。(1)用lg_var.exp()方法算出真正的方差值。(2)用方差值的sqrt0方法执行开平方运算得到标准差。(3)在符合标准正态分布的空间里随意采样,得到一个具体的数。(4)将该数乘以标准差,再加上均值,得到符合编码器输出的数据分布(均值为mean、方差为sigma)集合中的一个点(sigma是指网络生成的lg_var经过变换后的值)。
- 采样器的右侧是解码器。 经过采样器之后所合成的点可以输入解码器进行模拟样本的生成。
1.1.4 小总结
在神经网络中,可以为模型的输出值赋于任意一个意义,并通过训练得到对应的关系。具体做法是:将代表该意义的值代入相应的公式(要求该公式必须能够支持返向传播),计算公式的输出值与目标值的误差,并将误差放到优化器里,然后通过多次选代的方式进行训练。
2 变分自编码神经网络模型的反向传播与KL散度的应用
变分自编码神经网络模型是假设编码器输出的数据分布属于高斯分布,只有在编码器能够输出符合高斯分布数据集的前提上,才可以将一个符合标准高斯分布中的点x通过mean+sigma × x的方式进行转化(mean表示均值、sigma表示标准差),完成在解码器输出空间中的采样功能。
2.1 变分自编码神经网络的损失函数
变分自编码神经网络的损失函数不但需要计算输出结果与输入之间的个体差异,而且需要计算输出分布与高斯分布之间的差异。
输出与输入之间的损失函数可以使用MSE算法来计算,输出分布与标准高斯分布之损失函数可以使用KL散度距离进行计算。
2.2 KL散度
KL散度是相对熵的意思。KL散度在本例中的应用可以理解为在模型的训练过程中令输出的数据分布与标准高斯分布之间的差距不断缩小。
设P(x)、Q(x)是离散随机变量集合X中取值x的两个概率分布函数,它们的结果分别为p和q,则p对q的相对熵如下:
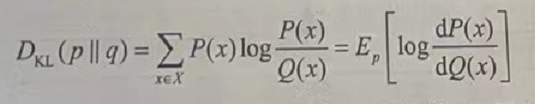
由式可知,当P(x)和Q(x)两个概率分布函数相同时,相对熵为0(因为log1=0)并且相对熵具有不对称性,“Ep”代表期望,期望是指每次可能结果的概率乘以结果的总和。
将高斯分布的密度函数代入上式中,可以得到:
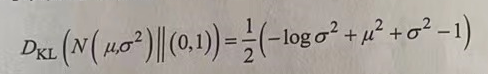
为输出分布与标准高斯分布之间的KL散度距离。它与MSE算法一起构成变分自编码神经网络的损失函数。
3 实例代码编写
3.1 代码实战:引入模块并载入样本----Variational_selfcoding.py(第1部分)
import torchimport torchvisionfrom cv2 import waitKeyfrom torch import nnimport torch.nn.functional as Ffrom torch.utils.data import DataLoaderfrom torchvision import transformsimport numpy as npfrom scipy.stats import norm # 在模型可视化时使用该库的norm接口从标准的高斯分布中获取数值import matplotlib.pylab as pltimport osos.environ['KMP_DUPLICATE_LIB_OK'] = 'True' # 可能是由于是MacOS系统的原因# 1.1 引入模块并载入样本:定义基础函数,并且加载FashionMNIST数据集# 定义样本预处理接口img_transform = transforms.Compose([transforms.ToTensor()])def to_img(x): # 将张量转化为图片 x = 0.5 * (x + 1) x = x.clamp(0,1) x = x.reshape(x.size(0),1,28,28) return xdef imshow(img): # 显示图片 npimg = img.numpy() plt.axis('off') plt.imshow(np.transpose(npimg,(1,2,0))) plt.show()data_dir = './fashion_mnist/' # 加载数据集train_dataset = torchvision.datasets.FashionMNIST(data_dir,train=True,transform=img_transform,download=True)# 获取训练数据集train_loader = DataLoader(train_dataset,batch_size=128,shuffle=True)# 获取测试数据集val_dataset = torchvision.datasets.FashionMNIST(data_dir,train=False,transform=img_transform)test_dataset = DataLoader(val_dataset,batch_size=10,shuffle=False)# 指定设备device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")print("所使用的设备为:",device)3.2 代码实战:定义变分自编码神经网络的正向模型----Variational_selfcoding.py(第2部分)
# 1.2 定义变分自编码神经网络模型的正向结构class VAE(nn.Module): def __init__(self,hidden_1=256,hidden_2=256,in_decode_dim=2,hidden_3=256): super(VAE, self).__init__() self.fc1 = nn.Linear(784, hidden_1) self.fc21 = nn.Linear(hidden_2, 2) self.fc22 = nn.Linear(hidden_2, 2) self.fc3 = nn.Linear(in_decode_dim, hidden_3) self.fc4 = nn.Linear(hidden_3, 784) def encode(self,x): # 编码器方法:使用两层全连接网络将输入的图片进行压缩,对第二层中两个神经网络的输出结果代表均值(mean)与取对数(log)以后的方差(lg_var)。 h1 = F.relu(self.fc1(x)) return self.fc21(h1),self.fc22(h1) def reparametrize(self,mean,lg_var): # 采样器方法:对方差(lg_var)进行还原,并从高斯分布中采样,将采样数值映射到编码器输出的数据分布中。 std = lg_var.exp().sqrt() # torch.FloatTensor(std.size())的作用是,生成一个与std形状一样的张量。然后,调用该张量的normal_()方法,系统会对该张量中的每个元素在标准高斯空间(均值为0、方差为1)中进行采样。 eps = torch.FloatTensor(std.size()).normal_().to(device) # 随机张量方法normal_(),完成高斯空间的采样过程。 return eps.mul(std).add_(mean) # 在torch.FloatTensor() # 函数中,传入Tensor的size类型,返回的是一个同样为size的张量。假如std的size为[batch,dim],则返回形状为[batch,dim]的未初始化张量,等同于torch.FloatTensor( # batch,dim),但不等同于torchFloatTensor([batch,dim),这是值得注意的地方。 def decode(self,z): # 解码器方法:输入映射后的采样值,用两层神经网络还原出原始图片。 h3 = F.relu(self.fc3(z)) return self.fc4(h3) def forward(self,x,*arg): # 正向传播方法:将编码器,采样器,解码器串联起来,根据输入的原始图片生成模拟图片 mean,lg_var = self.encode(x) z = self.reparametrize(mean=mean,lg_var=lg_var) return self.decode(z),mean,lg_var3.3 代码实战:损失函数与训练函数的完善----Variational_selfcoding.py(第3部分)
# 1.3 完成损失函数和训练函数reconstruction_function = nn.MSELoss(size_average=False)def loss_function(recon_x,x,mean,lg_var): # 损失函数:将MSE的损失缩小到一半,再与KL散度相加,目的在于使得输出的模拟样本可以有更灵活的变化空间。 MSEloss = reconstruction_function(recon_x,x) # MSE损失 KLD = -0.5 * torch.sum(1 + lg_var - mean.pow(2) - lg_var.exp()) return 0.5 * MSEloss + KLDdef train(model,num_epochs = 50): # 训练函数 optimizer = torch.optim.Adam(model.parameters(),lr=1e-3) display_step = 5 for epoch in range(num_epochs): model.train() train_loss = 0 for batch_idx, data in enumerate(train_loader): img,label = data img = img.view(img.size(0),-1).to(device) y_one_hot = torch.zeros(label.shape[0],10).scatter_(1,label.view(label.shape[0],1),1).to(device) optimizer.zero_grad() recon_batch, mean, lg_var = model(img, y_one_hot) loss = loss_function(recon_batch, img, mean, lg_var) loss.backward() train_loss += loss.data optimizer.step() if epoch % display_step == 0: print("Epoch:", '%04d' % (epoch + 1), "cost=", "{:.9f}".format(loss.data)) print("完成训练 cost=",loss.data)3.4 代码实战:训练模型并输出可视化结果----Variational_selfcoding.py(第4部分)
# 1.4 训练模型并输出可视化结果if __name__ == '__main__': model = VAE().to(device) # 实例化模型 train(model, 50) # 训练模型 test_loader = DataLoader(val_dataset, batch_size=len(val_dataset), shuffle=False) # 获取全部测试数据 # 可视化结果 sample = iter(test_loader) images, labels = sample.next() images2 = images.view(images.size(0), -1) with torch.no_grad(): pred, mean, lg_var = model(images2.to(device)) pred = to_img(pred.cpu().detach()) rel = torch.cat([images, pred], axis=0) imshow(torchvision.utils.make_grid(rel, nrow=10)) # 上一语句的生成结果中,第1行是原始的样本图片,第2行是使用变分自编码重建后生成的图片可以看到,生成的样本并不会与原始的输入样本完全一致。这表明模型不是一味地学习样本个体,而是通过数据分布的方式学习样本的分布规则。 waitKey(30)
3.5 代码实战:提取样本的低维数据并可视化----Variational_selfcoding.py(第5部分)
# 1.5 提取样本的低维特征并可视化: 编写代码实现对原始数据的维度进行压缩,利用解码器输出的均值和方差从解码器输出的分布空间中取样,并将其映到直角坐标系中展现出来,具体代码如下。 sample = iter(test_loader) images, labels = sample.next() with torch.no_grad(): # 将数据输入模型获得低维度特征: mean, lg_var = model.encode(images.view(images.size(0), -1).to(device))# 将数据输入模型获得低维度特征: z = model.reparametrize(mean, lg_var)# 将数据输入模型获得低维度特征:在输出样本空间中采样 z =z.cpu().detach().numpy() plt.figure(figsize=(6, 6)) plt.scatter(z[:, 0], z[:, 1], c=labels) # 在坐标轴中显示 plt.colorbar() plt.show() # 根据结果显示,数据集中同一类样本的特征分布还是比较集中的。这说明变分自编码神经网络具有降维功能,也可以用于进行分类任务的数据降维预处理。
3.6 代码实战:可视化模型的输出空间----Variational_selfcoding.py(第6部分)
#1.6 可视化模型的输出空间 n = 15 # 生成15个图片 digit_size = 28 figure = np.zeros((digit_size * n, digit_size * n)) # norm代表标准高斯分布,ppf代表累积分布函数的反函数。累积积分布的意思是,在一个集合里所有小于指定值出现的概率的和。举例,x=ppf(0.05)就代表每个小于x的数在集合里出现的概率的总和等于0.05。 # norm.ppf()函数的作用是使用百分比从按照大小排列后的标准高斯分布中取值 # p.linspace(0.05,0.95,n)的作用是将整个高斯分布数据集从大到小排列,并将其分成100份,再将第5份到第95份之间的数据取出、最后,将取出的数据分成n份,返回每一份最后一个数据的具体数值。 grid_x = norm.ppf(np.linspace(0.05, 0.95, n)) grid_y = norm.ppf(np.linspace(0.05, 0.95, n)) for i, yi in enumerate(grid_x): for j, xi in enumerate(grid_y): z_sample = torch.FloatTensor([[xi, yi]]).reshape([1, 2]).to(device) x_decoded = model.decode(z_sample).cpu().detach().numpy() digit = x_decoded[0].reshape(digit_size, digit_size) figure[i * digit_size: (i + 1) * digit_size, j * digit_size: (j + 1) * digit_size] = digit plt.figure(figsize=(10, 10)) plt.imshow(figure, cmap='Greys_r') plt.show() #从上一语句的生成结果中可以清楚地看到鞋子、手提包和服装商品之间的过渡。变分自编码神经网络生成的分布样本很有规律性,左下方侧重的图像较宽和较高,右上方侧重的图像较宽和较矮,左上方侧重的图像下方较宽、上方较窄,右下方侧重的图像较窄和较高。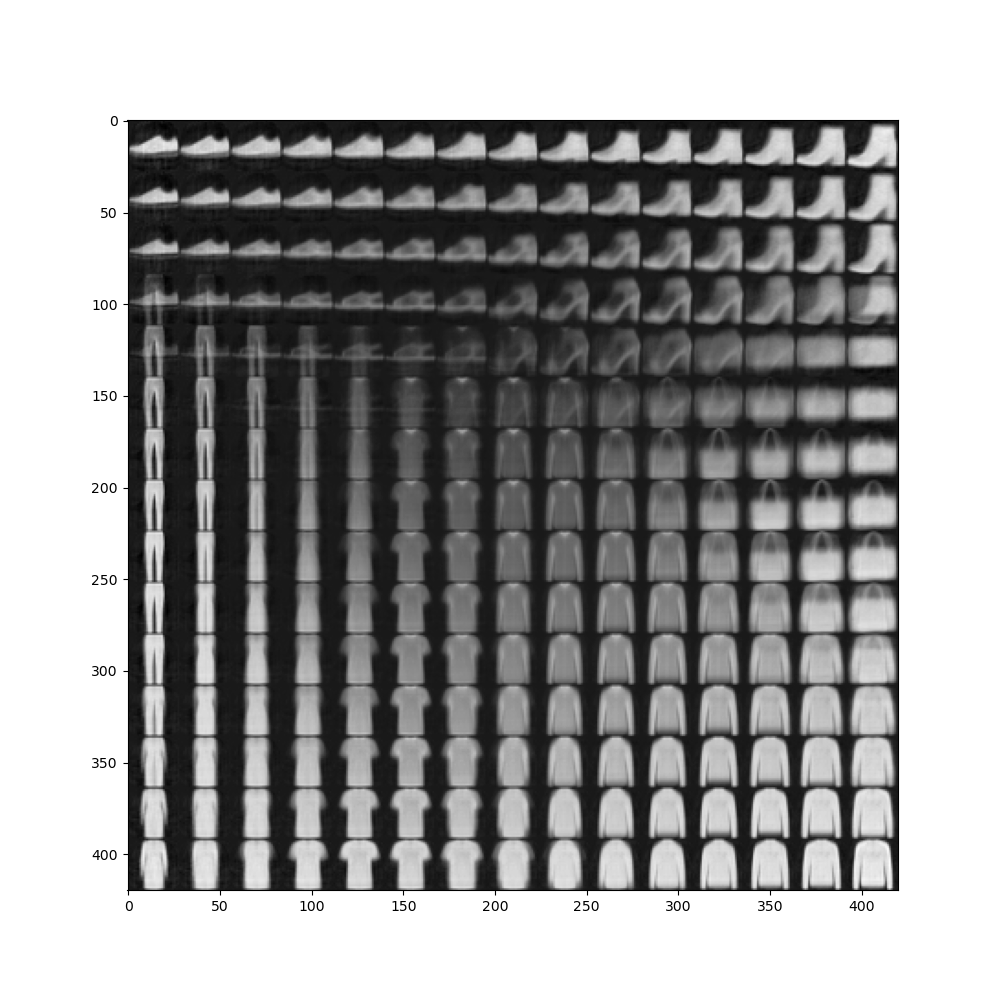
4 代码汇总(Variational_selfcoding.py)
import torchimport torchvisionfrom cv2 import waitKeyfrom torch import nnimport torch.nn.functional as Ffrom torch.utils.data import DataLoaderfrom torchvision import transformsimport numpy as npfrom scipy.stats import norm # 在模型可视化时使用该库的norm接口从标准的高斯分布中获取数值import matplotlib.pylab as pltimport osos.environ['KMP_DUPLICATE_LIB_OK'] = 'True' # 可能是由于是MacOS系统的原因# 1.1 引入模块并载入样本:定义基础函数,并且加载FashionMNIST数据集# 定义样本预处理接口img_transform = transforms.Compose([transforms.ToTensor()])def to_img(x): # 将张量转化为图片 x = 0.5 * (x + 1) x = x.clamp(0,1) x = x.reshape(x.size(0),1,28,28) return xdef imshow(img): # 显示图片 npimg = img.numpy() plt.axis('off') plt.imshow(np.transpose(npimg,(1,2,0))) plt.show()data_dir = './fashion_mnist/' # 加载数据集train_dataset = torchvision.datasets.FashionMNIST(data_dir,train=True,transform=img_transform,download=True)# 获取训练数据集train_loader = DataLoader(train_dataset,batch_size=128,shuffle=True)# 获取测试数据集val_dataset = torchvision.datasets.FashionMNIST(data_dir,train=False,transform=img_transform)test_dataset = DataLoader(val_dataset,batch_size=10,shuffle=False)# 指定设备device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")print("所使用的设备为:",device)# 1.2 定义变分自编码神经网络模型的正向结构class VAE(nn.Module): def __init__(self,hidden_1=256,hidden_2=256,in_decode_dim=2,hidden_3=256): super(VAE, self).__init__() self.fc1 = nn.Linear(784, hidden_1) self.fc21 = nn.Linear(hidden_2, 2) self.fc22 = nn.Linear(hidden_2, 2) self.fc3 = nn.Linear(in_decode_dim, hidden_3) self.fc4 = nn.Linear(hidden_3, 784) def encode(self,x): # 编码器方法:使用两层全连接网络将输入的图片进行压缩,对第二层中两个神经网络的输出结果代表均值(mean)与取对数(log)以后的方差(lg_var)。 h1 = F.relu(self.fc1(x)) return self.fc21(h1),self.fc22(h1) def reparametrize(self,mean,lg_var): # 采样器方法:对方差(lg_var)进行还原,并从高斯分布中采样,将采样数值映射到编码器输出的数据分布中。 std = lg_var.exp().sqrt() # torch.FloatTensor(std.size())的作用是,生成一个与std形状一样的张量。然后,调用该张量的normal_()方法,系统会对该张量中的每个元素在标准高斯空间(均值为0、方差为1)中进行采样。 eps = torch.FloatTensor(std.size()).normal_().to(device) # 随机张量方法normal_(),完成高斯空间的采样过程。 return eps.mul(std).add_(mean) # 在torch.FloatTensor() # 函数中,传入Tensor的size类型,返回的是一个同样为size的张量。假如std的size为[batch,dim],则返回形状为[batch,dim]的未初始化张量,等同于torch.FloatTensor( # batch,dim),但不等同于torchFloatTensor([batch,dim),这是值得注意的地方。 def decode(self,z): # 解码器方法:输入映射后的采样值,用两层神经网络还原出原始图片。 h3 = F.relu(self.fc3(z)) return self.fc4(h3) def forward(self,x,*arg): # 正向传播方法:将编码器,采样器,解码器串联起来,根据输入的原始图片生成模拟图片 mean,lg_var = self.encode(x) z = self.reparametrize(mean=mean,lg_var=lg_var) return self.decode(z),mean,lg_var# 1.3 完成损失函数和训练函数reconstruction_function = nn.MSELoss(size_average=False)def loss_function(recon_x,x,mean,lg_var): # 损失函数:将MSE的损失缩小到一半,再与KL散度相加,目的在于使得输出的模拟样本可以有更灵活的变化空间。 MSEloss = reconstruction_function(recon_x,x) # MSE损失 KLD = -0.5 * torch.sum(1 + lg_var - mean.pow(2) - lg_var.exp()) return 0.5 * MSEloss + KLDdef train(model,num_epochs = 50): # 训练函数 optimizer = torch.optim.Adam(model.parameters(),lr=1e-3) display_step = 5 for epoch in range(num_epochs): model.train() train_loss = 0 for batch_idx, data in enumerate(train_loader): img,label = data img = img.view(img.size(0),-1).to(device) y_one_hot = torch.zeros(label.shape[0],10).scatter_(1,label.view(label.shape[0],1),1).to(device) optimizer.zero_grad() recon_batch, mean, lg_var = model(img, y_one_hot) loss = loss_function(recon_batch, img, mean, lg_var) loss.backward() train_loss += loss.data optimizer.step() if epoch % display_step == 0: print("Epoch:", '%04d' % (epoch + 1), "cost=", "{:.9f}".format(loss.data)) print("完成训练 cost=",loss.data)# 1.4 训练模型并输出可视化结果if __name__ == '__main__': model = VAE().to(device) # 实例化模型 train(model, 50) # 训练模型 test_loader = DataLoader(val_dataset, batch_size=len(val_dataset), shuffle=False) # 获取全部测试数据 # 可视化结果 sample = iter(test_loader) images, labels = sample.next() images2 = images.view(images.size(0), -1) with torch.no_grad(): pred, mean, lg_var = model(images2.to(device)) pred = to_img(pred.cpu().detach()) rel = torch.cat([images, pred], axis=0) imshow(torchvision.utils.make_grid(rel, nrow=10)) # 上一语句的生成结果中,第1行是原始的样本图片,第2行是使用变分自编码重建后生成的图片可以看到,生成的样本并不会与原始的输入样本完全一致。这表明模型不是一味地学习样本个体,而是通过数据分布的方式学习样本的分布规则。 waitKey(30) # 1.5 提取样本的低维特征并可视化: 编写代码实现对原始数据的维度进行压缩,利用解码器输出的均值和方差从解码器输出的分布空间中取样,并将其映到直角坐标系中展现出来,具体代码如下。 sample = iter(test_loader) images, labels = sample.next() with torch.no_grad(): # 将数据输入模型获得低维度特征: mean, lg_var = model.encode(images.view(images.size(0), -1).to(device))# 将数据输入模型获得低维度特征: z = model.reparametrize(mean, lg_var)# 将数据输入模型获得低维度特征:在输出样本空间中采样 z =z.cpu().detach().numpy() plt.figure(figsize=(6, 6)) plt.scatter(z[:, 0], z[:, 1], c=labels) # 在坐标轴中显示 plt.colorbar() plt.show() # 根据结果显示,数据集中同一类样本的特征分布还是比较集中的。这说明变分自编码神经网络具有降维功能,也可以用于进行分类任务的数据降维预处理。#1.6 可视化模型的输出空间 n = 15 # 生成15个图片 digit_size = 28 figure = np.zeros((digit_size * n, digit_size * n)) # norm代表标准高斯分布,ppf代表累积分布函数的反函数。累积积分布的意思是,在一个集合里所有小于指定值出现的概率的和。举例,x=ppf(0.05)就代表每个小于x的数在集合里出现的概率的总和等于0.05。 # norm.ppf()函数的作用是使用百分比从按照大小排列后的标准高斯分布中取值 # p.linspace(0.05,0.95,n)的作用是将整个高斯分布数据集从大到小排列,并将其分成100份,再将第5份到第95份之间的数据取出、最后,将取出的数据分成n份,返回每一份最后一个数据的具体数值。 grid_x = norm.ppf(np.linspace(0.05, 0.95, n)) grid_y = norm.ppf(np.linspace(0.05, 0.95, n)) for i, yi in enumerate(grid_x): for j, xi in enumerate(grid_y): z_sample = torch.FloatTensor([[xi, yi]]).reshape([1, 2]).to(device) x_decoded = model.decode(z_sample).cpu().detach().numpy() digit = x_decoded[0].reshape(digit_size, digit_size) figure[i * digit_size: (i + 1) * digit_size, j * digit_size: (j + 1) * digit_size] = digit plt.figure(figsize=(10, 10)) plt.imshow(figure, cmap='Greys_r') plt.show() #从上一语句的生成结果中可以清楚地看到鞋子、手提包和服装商品之间的过渡。变分自编码神经网络生成的分布样本很有规律性,左下方侧重的图像较宽和较高,右上方侧重的图像较宽和较矮,左上方侧重的图像下方较宽、上方较窄,右下方侧重的图像较窄和较高。
