计算机架构的新黄金时代,GPU能否继续保持辉煌?

撰文|吕坚平
2018年6月4日,John Hennessy和David Patterson以2017年图灵奖(被誉为“计算机界的诺贝尔奖”)的获得者身份发表了演讲《计算机架构新的黄金时代》。讲座有三个关键见解:
1、软件的进步将激发架构的创新。
2、硬件/软件接口的进化为架构创新创造了机会。
3、关于架构的争论最终将由市场需求解决。
我想再补充第四点,补全这个闭环:
在竞争中的首选架构将促进后续的软件进化。
在Hennessy/Patterson演讲之后,我们发现市场几乎已经在AI领域中实现了第三条见解 #3(关于架构的争论最终将由市场需求解决),并将图形处理单元(GPU)选为推动人工智能革命的“获胜”架构。在本文中,我将探讨AI革命是如何激发架构创新和重塑GPU的,我希望本文能够回答这个重要问题:GPU能否在计算机架构新的黄金时代继续保持辉煌?
1
特定领域架构
Henessy和Patterson提出了特定领域架构(DSA)的概念,旨在为计算机架构带来创新并努力迈向新的黄金时代。顾名思义,GPU是用于3D图形领域的 DSA。它的目标是在3D虚拟世界中渲染照片般逼真的图像;然而,几乎所有人工智能研究人员都使用 GPU 来探索超越3D图形领域的概念,并在人工智能的“软件”也就是神经网络架构方面取得了一系列的突破。
GPU在3D世界仍然是不可或缺的,同时因为它促进了AI的软件创新,已成为人工智能世界的“CPU”。除了3D用途之外,GPU架构师一直在努力将GPU的计算资源用于非3D用途。我们将这种设计理念称为通用GPU,即GPGPU。
如今,我们看到越来越多的AI DSA来抢占GPGPU的市场,试图用更好的性能来取代GPU。甚至GPU本身也在它的双重人格(即AI DSA和3D DSA)之间挣扎。原因是AI DSA需要加速张量运算,这在 AI 中是很常见的运算,但在3D世界中却不是;与此同时,3D固定功能硬件对于AI来说似乎是多余的。
因此,关于架构争论的主要方向应集中在以下几个方面:
1、GPU能否稳坐“AI世界CPU”的宝座?
2、GPU是否会分成两种DSA,一种用于AI,另一种用于3D?
我的预测如下:
1、GPU硬件/软件接口将继续使GPU成为“AI世界的CPU”。
2、基于 AI 的渲染会让张量加速成为GPU中的主流。
3、虚拟世界和现实世界互相映射的数字孪生理念将主导市场,最终解决架构争论。
2
GPU硬件/软件接口
我们可以将GPU在3D领域中的主导地位和在AI世界中取得的巨大成功归功于它的硬件/软件接口,GPU和3D图形软件架构师正努力采用这种接口。这种接口是解决以下悖论的关键: GPU社区正在继续优化GPU的通用性,但业界的其他人为应对摩尔定律消退的困境已开始转向更专用的硬件。
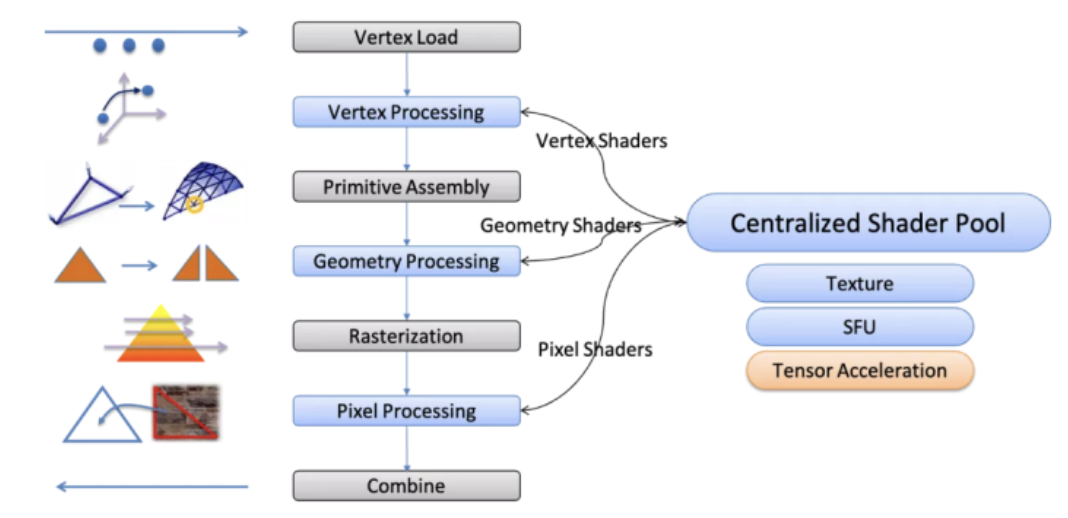
GPU管线(图片来源:本文作者)
3
双层可编程性
理论上讲,GPU是处理阶段的长长的线性管线(Pipeline)。不同类型的工作项(Work items)在通过管线时被处理。在早期,每个处理阶段都是一个固定的功能块,程序员对GPU的唯一控制就是调整每个区间的参数。
如今,GPU硬件/软件接口让程序员可以自由地处理每个工作项,无论是顶点还是像素。没有必要在每个顶点或像素循环中处理循环头,因为GPU架构师在一个固定的函数中实现了核心功能。这种架构选择让程序员仅仅关注他们自己的循环体或“着色器”,这通常以工作项的类型命名,如处理顶点的“顶点着色器”和处理像素的“像素着色器”。
现代游戏如何使用这种线性管线制作出令人惊叹的画面?除了通过管线一次控制不同类型的着色器,程序员可以多次通过同一个管线产生中间图像,最终产生在荧幕上看到的最终图像。程序员还可以创建一个计算图,描述中间图像之间的关系,图中的每个节点表示通过GPU管线一次。
4
中心化的通用计算资源池
一个中心化的通用计算资源池可以在多个处理阶段之间共享,完成繁重的工作。这种方案的最初动机是负载均衡;在不同的使用场景中,各个处理阶段的工作负载可能有很大的变化。
因此,计算资源,也就是被称为着色器核心的部件逐渐变得更具通用性,以实现灵活性和产品差异化。GPU架构师尝试将中央着色器池提供给非3D应用程序,如GPGPU,这种设计方案使GPU能在兼顾运行人工智能任务方面取得突破。
5
平衡专门器件的比例
GPU架构师经常在不改变硬件/软件接口的情况下添加协同处理单元“加速”或“特殊优化”着色器池。纹理单元就是这样一个协处理单元,可以用来把纹理元素从纹理贴图中提取并过滤到着色器池中。特殊函数单元(SFU)是负责执行超越数学函数的另一种协处理单元,处理对数、平方根倒数等函数。
虽然有多个功能单元听起来很像CPU中的超标量设计,但它们有一个显著区别:GPU 架构师根据着色器程序使用协处理单元的平均频次来配置协处理单元的吞吐量。例如,如果我们假设纹理操作出现在基准测试或游戏中的时间平均为八分之一,就可以为纹理单元提供着色器池吞吐量的八分之一。当协处理单元处于繁忙状态时,GPU会切换任务以让自己的资源被充分利用。
6
张量如何加速3D应用
在前文中,我提到了GPU在3D用途中难以利用张量加速。让我们看看如果改变GPU 渲染典型游戏帧的方式,这种状况能否改变。GPU首先生成并存储所有必要的信息,以便为每个像素在G-buffer中着色。从 G-buffer中,我们会计算如何点亮一个像素,紧随其后的是几个处理步骤,包括:
1.去除锯齿边缘(抗锯齿(AA))
2.将低分辨率图像升级为高辨率图像(超分辨率(SR))
3.将整帧画面添加一些特定视觉效果,例如环境光遮蔽、运动模糊、布隆过滤器或景深等。
因为对像素的着色是“延迟”的,直到每个像素都获得所需的信息后才开始,我们称这种渲染方案为延迟着色。我们将光照之后的处理步骤称为后处理。今天,后处理消耗了大约 90% 的渲染时间,这意味着 GPU 的荧幕时间主要用在2D而非3D上!
NVIDIA已经为AA和SR演示了基于AI的DLSS 2.0,声称可以生成比没用DLSS 2.0的原生渲染更好看的图像。此外,NVIDIA 还为光线追踪提供了基于 AI 的蒙特卡罗去噪算法,这样我们就可以使用很少的光线来实现原本需要更多光线才能做到的画面质量。另外,AI技术为其他许多后处理类型提供了一类新的解决方案,例如用于环境遮蔽的NNAO 和用于景深的 DeepLens。
如果基于AI的后处理成为主流,张量加速将成为GPU在3D用途上的支柱,GPU 分化为 3D DSA和AI DSA的可能性也会降低。
7
3D/AI融合
为了解决架构争论,我们需解决最后一个难题:我们最后是否应该移除3D渲染中的专用功能硬件,尤其是在用于 AI 用途时是不是更需要这样做?请注意,通过GPGPU, GPU可以作为纯“软件”来进行3D渲染,而不需要使用任何专用功能硬件。
严格意义上讲,在给定场景参数的情况下,3D渲染模拟了光子如何从光源穿越空间传输到3D虚拟世界中与物体交互。GPU的传统3D渲染过程是这个方法的一个非常粗略的近似。因此,微软将光线追踪宣传为“未来的完整3D效果”时表示,“[基于传统光栅化的]3D图形是一个谎言”。然而,3D 渲染纯粹主义者可能仍然不会接受光线追踪技术,因为在光线追踪过程中,我们是从像素到 3D 虚拟世界来反向追踪光线来实现 3D 渲染的,这也不是真实的。
这两种方法都是基于模拟的3D渲染的近似方案。在两种方案下,我们都会将 3D 虚拟世界的建模或者说内容创建与渲染分离开来。第一步,,对 3D 虚拟世界建模需要工程师和艺术家进行大量艰苦而富有创造性的工作,以描述每个对象及其与光线交互的物理属性。第二步,因为我们需要彻底简化3D渲染以在资源预算内满足多个性能目标,通过渲染做到完全真实是不可能的。
相比使用广为人知的科学知识和数学理论为给定问题寻找解决方案,人工智能方法是从数据中“学习”计算模型,或者说神经网络。我们通过反复试验迭代地调整网络参数,通过上一个版本的参数估计向前运行网络并测量不匹配或“损失”。然后根据其梯度调整参数以减少损失,有效地引导损失景观向与梯度相反的方向移动。这种机制称为反向传播,它要求沿着前向路径的所有计算都是可微的,以参与计算梯度。
神经渲染是一个新兴的人工智能研究领域,它使用上述方法来研究3D渲染。下面是我用来跟踪神经渲染进展的思维导图:
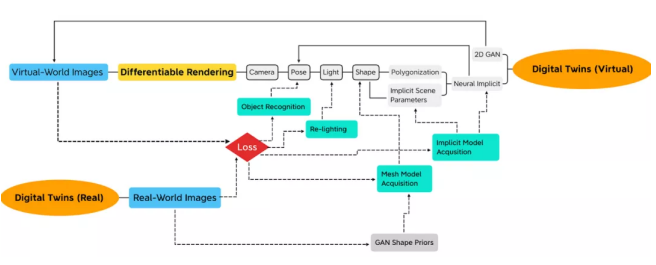
这个 3D 虚拟世界模型被隐含地表示为神经网络参数(参见 NeRF、GRAF、GIRAFFE),这些参数是我们通过比较真实世界的图像和我们从虚拟世界渲染的图像来推断的。我们反向传播比较梯度来调整神经网络参数。或者,我们可以从数据中学习显式 3D 网格(参见 DeepMarching Cube,GAN2Shape)。实际上,对 3D 虚拟世界建模与学习神经网络参数是一回事。这个过程要求我们在前向路径中包含一个 3D 渲染管线,并在紧密的循环中集成3D虚拟世界的建模和渲染。通过对真实世界图像的迭代渲染和测试,我们获得了可用于渲染虚拟世界新视图的所需模型和场景参数。
在这个框架内,我们可以选择性地不对所有参数进行调整,例如,保持物体的形状不变但估计其位置(参见 iNeRF)。这样,我们可以高效地尝试识别和定位问题中的对象,而不是对其建模。建模和识别任务之间不再存在区别。相反,问题在于我们想要“学习”或“估计”哪些场景参数。
8
结论
因此,在人工智能解决问题的范式下,3D渲染的目标不仅是生成 3D 虚拟世界的逼真图像,还可以根据现实世界来构建虚拟世界。此外,新框架通过以下方式重新定义了3D和AI:
1. 3D渲染成为AI训练流程中必不可少的操作。
2. 训练或“梯度下降”,过去只出现在云端神经网络训练过程,现在则是推理的一部分。
3. 真实渲染的真实感是为了保持真实世界和虚拟世界之间的一致性,从而看起来很棒。
数字孪生理念要求将庞大且不断变化的现实世界带到其尚未开发的孪生虚拟世界中,并保持孪生之间的一致性。通过神经渲染获得的虚拟对象需要与通过经典方法构建的虚拟对象共存。因此,我相信神经渲染和传统渲染将利用其成熟和高性能的3D管线在GPU上融合。数字孪生的需求将落在未来GPU的肩上。我们还需要在GPU端做很多工作来实现“可微”,以参与AI训练流程的梯度计算。
假设GPU因满足3D世界中的AI方法的进展而获得原生可微和张量加速能力,我预计GPU的“双重人格”将化为一体。
最终,GPU会卫冕其首选架构的宝座,以促进AI软件的进一步发展,并最终成为计算机架构新的黄金时代的明星。
(本文由作者吕坚平博士授权后发布,原文:
https://medium.com/m/global-identity?redirectUrl=https%3A%2F%2Ftowardsdatascience.com%2Fwill-the-gpu-star-in-a-new-golden-age-of-computer-architecture-3fa3e044e313)

作者简介:吕坚平毕业于耶鲁大学并获计算机科学博士学位,曾在英伟达、英特尔、三星等跨国半导体巨头担任要职,是GPU领域的著名专家,去年九月,吕博士正式加盟上海天数智芯半导体有限公司,任首席技术官(CTO)。
其他人都在看
-
OneFlow实习岗位热招
-
计算机架构的新黄金时代
-
那些在开源世界顶半边天的女同胞们
-
黄仁勋口述:英伟达的发展之道和星辰大海
-
Tenstorrent虫洞分析:挑战英伟达的新玩家
-
30年做成三家独角兽公司,AI芯片创业的底层逻辑
欢迎下载体验OneFlow新一代开源深度学习框架:GitHub - Oneflow-Inc/oneflow: OneFlow is a performance-centered and open-source deep learning framework.![]() https://github.com/Oneflow-Inc/oneflow/
https://github.com/Oneflow-Inc/oneflow/

