Pytorch神经网络实战学习笔记_36 神经网络中散度的应用:F散度+f-GAN的实现+互信息神经估计+GAN模型训练技巧

1 散度在无监督学习中的应用
在神经网络的损失计算中,最大化和最小化两个数据分布间散度的方法,已经成为无监督模型中有效的训练方法之一。
在无监督模型训练中,不但可以使用K散度JS散度,而且可以使用其他度量分布的方法。f-GAN将度量分布的做法总结起来并找出了其中的规律,使用统一的f散度实现了基于度量分布的方法实现基于度量分布方法训练GAN模型的通用框架。
1.1 f-GAN简述
f-GAN是是一套训练GAN的框架总结,它不是具体的GAN方法,它可以在GAN的训练中很容易实现各种散度的应用,即f-GAN是一个生产GAN模型的“工厂”。
它所生产的GAN模型都有一个共同特点:不进行任何先验假设,对要生成的样本分布使用最小化差异的度量方法,尝试解决一般性的数据样本生成问题(常用于无监督训练)。
1.2 基于f散度的变分散度最小化方法(Variational Divergence Minimization,VDM)
变分散度最小化方法是指通过最小化两个数据分布间的变分距离来训练模型中参数,这是f-GAN所使用的通用方法。在f-GAN中,数据分布间的距离使用f散度来度量。
1.2.1 变分散度最小化方法的适用范围
WGAN模型的训练方法、分自编码的训练方法也属于VDM方法。所有符合f-GAN框架的GAN模型都可以使用VDM方法进行训练。VDM方法适用于GAN模型的训练。
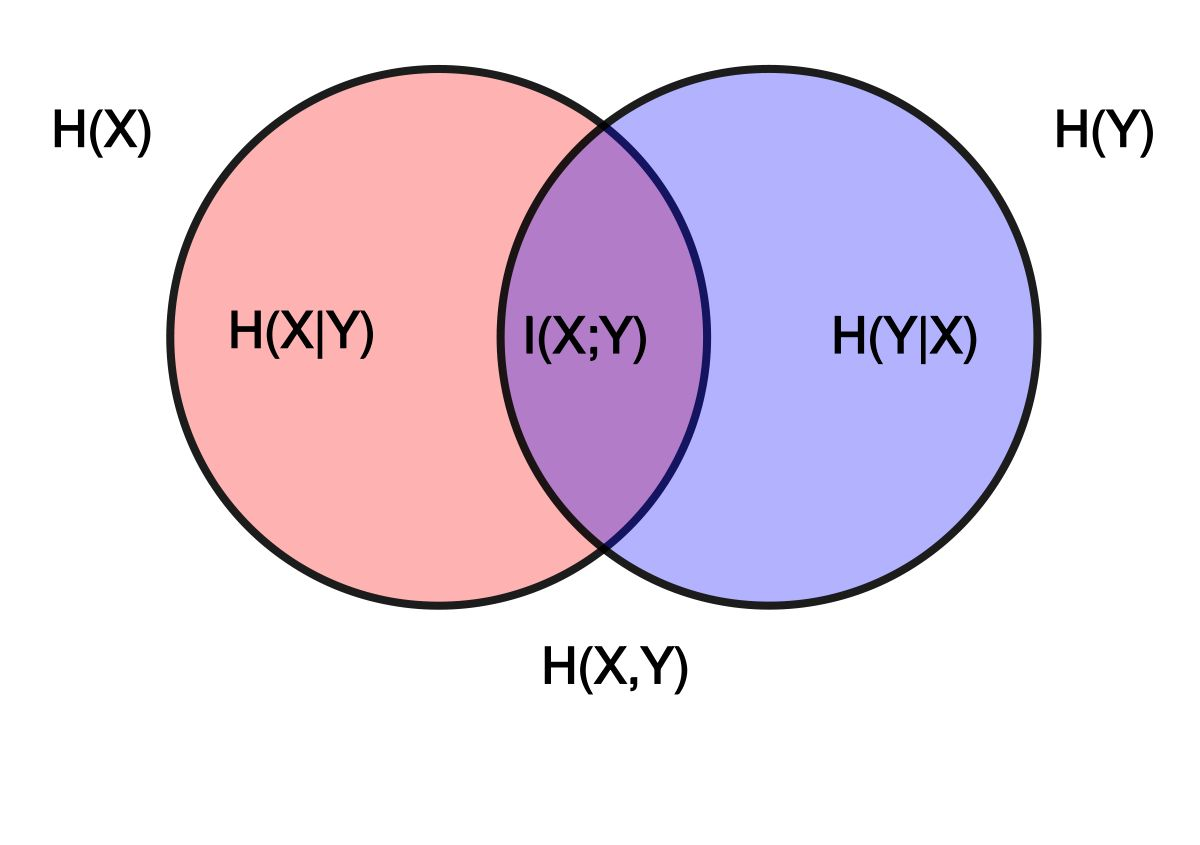
1.2.1 f散度
给定两个分布P、Q,p(x)和q(x)分别是x对应的概率函数,则f散度可以表示为;
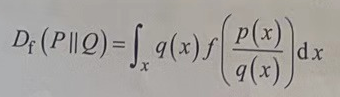
f散度相当于一个散度“工厂”,在使用它之前必须为式中的生成函数f(x)指定具体内容。f散度会根据生成函数f(x)对应的具体内容,生成指定的度量算法。
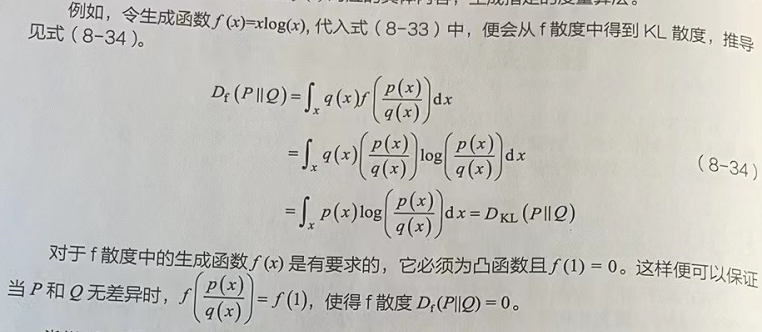

2 用Fenchel共轭函数实现f-GAN
2.1 .Fenchel共轭函数的定义(Fenchel conjugate)
Fenchel共轭/凸共轭函数,是指对于每个凸函数且满足下半连续的f(x),都有一个共轭函数f*的定义为:

式中的f*(t)是关于t的函数,其中t是变量;dom(f)为f(x)的定义域;max即求当横坐标取t时,纵坐标在多条表达式为{xt-f(x)}的直线中取最大那条直线上所对应的点,如图所示。
2.2 Fenchel共扼函数的特性
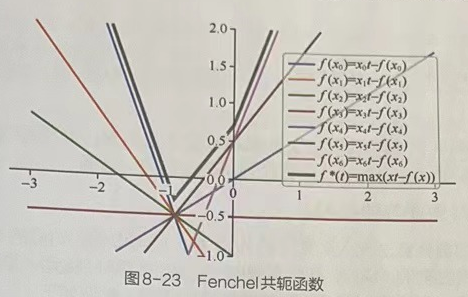
图8-23中有1条粗线和若干条细直线,这些细直线是由随机采样的几个x值所生成的f(x),粗线是生成函数的共轭函数f*。图8-23中的生成函数是f(x)=|x-1|÷2,该函数对应的算法是总变分(Total Variation,TV)算法。TV算法常用于对图像的去噪和复原。

2.3 将Fenchel共轭函数运用到f散度中


2.4 用f-GAN生成各种GAN
将图8-22中的具体算法代入到式(8-40)中,便可以得到对应的GAN。有趣的是,对于通过f-GAN计算出来的GAN,可以找到好多已知的GAN模型。这种通过规律的视角来反向看待个体的模型,会使我们对GAN的理解更加透彻。举例如下:

2.5 f-GAN中判别器的激活函数




3 互信息神经估计
互信息神经估计(Mutual Information Neural Estimation,MlNE)是一种基于神经网络估计互信息的方法。它通过BP算法进行训练,对高维度的连续随机变量间的互信息进行估计,可以最大化或者最小化互信息,提升生成模型的对抗训练,突破监督学习分类任务的瓶颈。(参见的论文编号为arX:1801.04062,2018)
3.1 将互信息转化为KL散度
在前面介绍过互信息的公式。它可以表示为两个随机变量XY的边缘分布的乘积相对行太、Y联合概率分布的相对熵,即
![]() 。
。
这表明E信息可以通过求KL散度的方法进行计算。
3.2 KL散度的两种对偶表示
KL散度具有不对称性,可以将其转化为具有对偶性的表示方式进行计算,基于散度的对偶表示公式有两种。

其中dual f-divergence表示相对于Donsker-Varadhan表示有更低的下界,会导致估计结果更加宽松和不准确。因此,一般使用Donsker-Varadhan表示。
3.3 神经网络中的KL散度的应用

4 稳定训练GAN的经验与技巧
4.1 GAN训练失败的分类
GAN模型的训练是神经网络中公认的难题。对于众多训练失败的情况,主要分为两情况:模式丢弃(mode dropping)和模式崩塌(mode collapsing)
- 模式丢弃是指模型生成的模拟样本中,缺乏多样性的问题,即生成的模拟数据是原始数摆集中的一个子集。刚如,MNST数据分布一共有10个分类,而生成器所生成的模拟数据只有其中某个数字。
- 模式崩塌:生成器所生成的模拟样本非常模湖,质量很低。
4.2 GAN训练技巧
4.2.1 降低学习率
通常,当使用更大的批次训练横型时,可以设置更高的学习率。但是,当模型发生模式透弃情况时,可以尝试降低模型的学习率,并从头开始训练。
4.2.2 标签平滑
标签平滑可以有效地改善训练中模式崩塌的情况。这种方法也非常容易理解和实现,如奥真实图像的标签设置为1,就将它改成一个低一点的值(如0.9)。这个解决方案阻止判别器过于相信分类标签,即不依赖非常有限的一组特征来判断图像是真还是假。
4.2.3 多尺度梯度
这种技术常用于生成较大(1024像素×1024像素)的模拟图像。该方法的处理方式与传统的用于语义分割的U-Net类似。模型更关注的是多尺度梯度,将真实图片通过下采样方式获得的多尺度图片与生成器的多跳连接部分输出的多尺度向量一起送入判别器,形成MSG-GAN架构。(参见的论文编号为arXv:1903.06048,2019)
4.2.4 更换损失函数
在f-GAN系列的训练方法中,由于散度的度量不同,导致训练不稳定性问题的存在。在这种情况下,可以在模型中使用不同的度量方法作为损失函数,找到更适合的解决方法。
4.2.5 借助互信息估计方法
在训练模型时,还可以使用MNE方法来辅助模型训练。
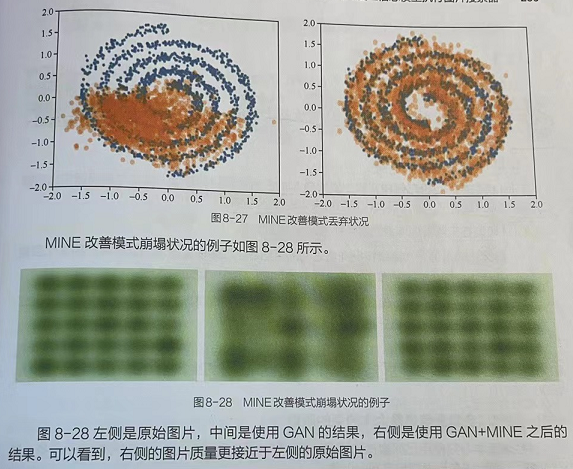
MINE方法是一个通用的训练方法,可以用于各种模型(自编码神经网络、对抗神经网络)。在GAN的训练过程中,使用MINE方法辅助训练模型会有更好的表现,如图8-27所示。
图8-27左侧是GAN模型生成的结果;右侧是使用MINE辅助训练后的生成结果。可以看到,图中右侧的模拟数据(黄色的点)所覆盖的空间与原始数据(蓝色的点)更一致。
4.3 MINE方法概述
MINE方法中主要使用了两种技术:互信息转为神经网络模型技术和使用对偶KL散度计算损失技术。最有价值的是这两种技术的思想,利用互信息转为神经网络模型技术,可应用到更多的提示结构中,同时损失函数也可以根据具体的任务而使用不同的分布度量算法。【详见下一节实战】