Pytorch神经网络实战学习笔记_37 【实战】最大化深度互信信息模型DIM实现搜索最相关与最不相关的图片

图片搜索器分为图片的特征提取和匹配两部分,其中图片的特征提取是关键。将使用一种基于无监督模型的提取特征的方法实现特征提取,即最大化深度互信息(DeepInfoMax,DIM)方法。
1 最大深度互信信息模型DIM简介
在DIM模型中,结合了自编码和对抗神经网络,损失函数使用了MINE与f-GAN方法的结合。在此之上,DM模型又从全局损失、局部损失和先验损失3个损失出发进行训练。
1.1 DIM模型原理
性能好的编码器应该能够提取出样本中最独特、具体的信息,而不是单纯地追求过小的重构误差。而样本的独特信息可以使用互信息(MutualInformation,MI)来衡量。
因此,在DIM模型中,编码器的目标函数不是最小化输入与输出的MSE,而是最大化输入与输出的互信息。
1.2 DIM模型的主要思想
DIM模型中的互信息解决方案主要来自MINE方法,即计算输入样本与编码器输出的转征向量之间的互信息,通过最大化互信息来实现模型的训练。
1.2.1 DIM模型在无监督训练中的两种约束。
- 最大化输入信息和高级特征向量之间的互信息:如果模型输出的低维特征能够代表输入样本,那么该特征分布与输入样本分布的互信息一定是最大的。
- 对抗匹配先验分布:编码器输出的高级特征要更接近高斯分布,判别器要将编码器生成的数据分布与高斯分布区分。
在实现时,DlM模型使用了3个判别器,分别从局部互信息最大化、全局互信息最大化和先验分布匹配最小化的3个角度对编码器的输出结果进行约束。(论文arXv:1808.06670,2018)
1.3 局部与全局互信息最大化约束的原理
许多表示学习只使用已探索过的数据空间(称为像素级别),当一小部分数据十分关心语义级别时,表明该表示学习将不利于训练。
对于图片,它的相关性更多体现在局部。图片的识别、分类等应该是一个从局部到整体的过程,即全局特征更适合用于重构,局部特征更适合用于下游的分类任务。
局部特征可以理解为卷积后得到的特征图,全局特征可以理解为对特征图进行编码得到的特征向量。
DIM模型从局部和全局两个角度出发对输入和输出执行互信息计算。
1.4 先验分布匹配最小化约束原理
先验匹配的目的是对编码器生成向量形式进行约束,使其更接近高斯分布。
DIM模型的编码器的主要思想是:在对输入数据编码成特征向量的同时,还希望这个特征向量服从于标准的高斯分布。这种做法使编码空间更加规整,甚至有利于解耦特征,便于后续学习,与变分自编码中编码器的使命是一样的。
因此,在DIM模型中引入变分自编码神经网络的原理,将高斯分布当作先验分布,对编码器输出的向量进行约束。
2 DIM模型的结构
2.1 DIM模型结构图
DIM模型的结构DIM模型由4个子模型构成:1个编码器、3个判别器。其中解码器的作用主要是对图进行特征提取,3个判器需分别从局部、全局、先验匹配3个角度对编码器的输出结果进行约束。
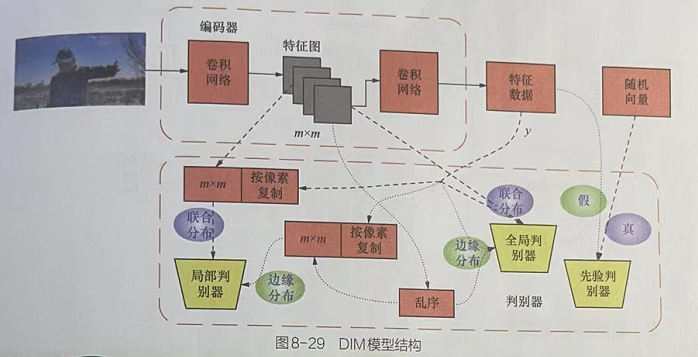
2.2 DlM模型的特殊之处
在DlM模型的实际实现过程中,没有直接对原始的输入数据与编码器输出的特征数据执行最大化互信息计算,而使用了编码器中间过程中的特征图与最终的特征数据执行互信息计算。
根据MINE方法,利用神经网络计算互信息的方法可以换算成计算两个数据集的联合分布和边缘分布间的散度,即将判别器处理特征图和特征数据的结果当作联合分布,将乱序后的特征图和特征数据输入判别器得到边缘分布。
DIM模型打乱特征图的批次顺序后与编码器输出的提示特征向量一起作为判别器的输入,即令输入判别器的特征图与特征向量各自独立(破坏特征图与特征向量间的对应关系),详见互信息神经估计的原理介绍。
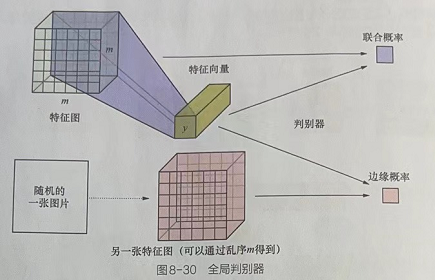
2.3 全局判别器模型
如图8-29,全局判别器的输入值有两个:特征图和特征数据y。在计算互信息的过程中,联合分布的特征图和特征数据y都来自编码神经网络的输出。计算边缘分布的特征图是由改变特征图的批次顺序得来的,特征数据y来自编码神经网络的输出,如图8-30所示。
在全局判别器中,具体的处理步骤如下。
(1)使用卷积层对特征图进行处理,得到全局特征。
(2)将该全局特征与特征数据y用torch.cat()函数连接起来。
(3)将连接后的结果输入全连接网络(对两个全局特征进行判定),最终输出判别结果(一维向量)。
2.4 局部判别器模型
如图8-29所示,局部判别器的输入值是一个特殊的合成向量:将编码器输出的特征数据y按照特征图的尺寸复制成m×m份。令特征图中的每个像素都与编码器输出的全局特征数据ν相连。这样,判别器所做的事情就变成对每个像素与全局特征向量之间的互信息进行计算。因此,该判别器称为局部判别器。
在局部判别器中,计算互信息的联合分布和边缘分布方式与全局判别器一致,如图8-31所示,在局部判别器中主要使用了1×1的卷积操作(步长也为1)。因为这种卷积操作不会改变特征图的尺寸(只是通道数的变换),所以判别器的最终输出也是大小为m×m的值。
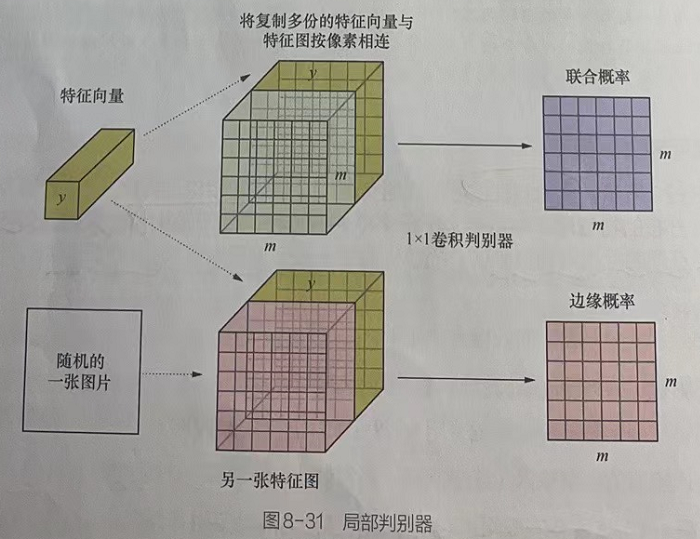
局部判别器通过执行多层的1×1卷积操作,将通道数最终变成1,并作为最终的判别结果。该过程可以理解为,同时对每个像素与全局特征计算互信息。
2.5 先验判别器模型
先验判别器模型主要是辅助编码器生成的向量趋近于高斯分布,其做法与普通的对抗神经网络一致。先验判别器模型输出的结果只有0或1:令判别器对高斯分布采样的数据判定为真(1),对编码器输出的特征向量判定为假(0),如图8-32所示。
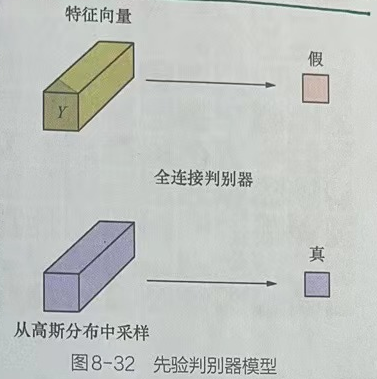
先验判别器模型如图8-32所示,先验判别器模型的输入只有一个特征向量。其结构主要使用了全连接神经网络,最终会输出“真”或“假”的判定结果。
2.6 损失函数
在DIM模型中,将MINE方法中的KL散度换成JS散度来作为互信息的度量。这样做的原因是:JS散度是有上界的,而KL散度是没有上界的。相比之下,JS散度更适合在最大化任务中使用,因为它在计算时不会产生特别大的数,并且JS散度的梯度又是无偏的。
在f-GAN中可以找到JS散度的计算公式,见式(8-46)(其原理在式(8-46)下面的提示部分进行了阐述)。

先验判别器的损失函数非常简单、与原始的GAN模型(参见的论文编号为anXiv:1406.2661,2014)中的损失函数一致,对这3个判别器各自损失函数的计算结果加权求和,便得到整个DM模型的损失函数。
3 实战案例简介与代码实现(训练模型代码实现)
使用最大化深度互信息模型提取图片信息,并用提取出来的低维特征制作图片搜索器。
3.1 CIFAR数据集
本例使用的数据集是ClFAR,它与Fashion-MNIST数据集类似,也是一些图片。ClFAR比Fashion-MNIST更为复杂,而且由彩色图像组成,相比之下,与实际场景中接触的样本更为接近。
3.1.1 CIFAR数据集的组成
CIFAR数据集的版本因为起初的数据集共将数据分为10类,分别为飞机、汽车、鸟、猫、鹿、狗、青蛙、马、船、卡车,所以ClFAR的数据集常以CIFAR-10命名,其中包含60000张32像素×32像素的彩色图像(包含50000张训练图片、10000张测试图片),没有任何类型重叠的情况。因为是彩色图像,所以这个数据集是三通道的,具有R、G、B这3个通道。
CIFAR又推出了一个分类更多的版本:ClFAR-100,从名字也可以看出,其将数据分为100类。它将图片分得更细,当然,这对神经网络图像识别是更大的挑战,有了这数据,我们可以把精力全部投入在网络优化上。
3.2 获取数据集
ClFAR数据集是已经打包好的文件,分为Python、二进制bin文件包,方便不同的程序读取,本次使用的数据集是ClFAR-10版本中的Python文件包,对应的文件名称为“cifar-10-pyhon.tar.gz”。该文件可以在官网上手动下载,也可以使用与获取Fashion-MNIST类似的方法,通过PyTorch的内嵌代码进行下载。
3.3 加载并显示CIFAR数据集------DIM_CIRFAR_train.py(第1部分)
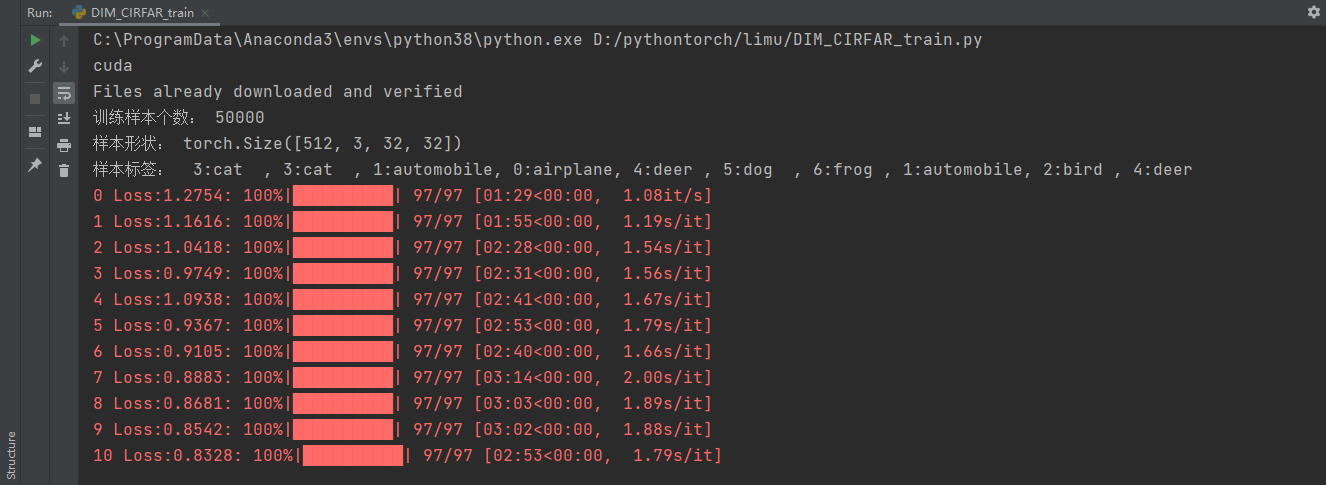
import torchfrom torch import nnimport torch.nn.functional as Fimport torchvisionfrom torch.optim import Adamfrom torchvision.transforms import ToTensorfrom torch.utils.data import DataLoaderfrom torchvision.datasets.cifar import CIFAR10from matplotlib import pyplot as pltimport numpy as npfrom tqdm import tqdmfrom pathlib import Pathfrom torchvision.transforms import ToPILImageimport osos.environ["KMP_DUPLICATE_LIB_OK"]="TRUE"# 1.1 获取数据集并显示数据集# 指定运算设备device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')print(device)# 加载数据集batch_size = 512data_dir = r'./cifar10/'# 将CIFAR10数据集下载到本地:共有三份文件,标签说明文件batches.meta,训练样本集data_batch_x(一共五个,包含10000条训练样本),测试样本test.batchtrain_dataset = CIFAR10(data_dir,download=True,transform=ToTensor())train_loader = DataLoader(train_dataset,batch_size=batch_size,shuffle=True,drop_last=True,pin_memory=torch.cuda.is_available())print("训练样本个数:",len(train_dataset))# 定义函数用于显示图片def imshowrow(imgs,nrow): plt.figure(dpi=200) # figsize=(9,4) # ToPILImage()调用PyTorch的内部转换接口,实现张量===>PLImage类型图片的转换。 # 该接口主要实现。(1)将张量的每个元素乘以255。(2)将张量的数据类型由FloatTensor转化成uint8。(3)将张量转化成NumPy的ndarray类型。(4)对ndarray对象执行transpose(1,2,0)的操作。(5)利用Image下的fromarray()函数,将ndarray对象转化成PILImage形式。(6)输出PILImage。 _img = ToPILImage()(torchvision.utils.make_grid(imgs,nrow=nrow)) # 传入PLlmage()接口的是由torchvision.utis.make_grid接口返回的张量对象 plt.axis('off') plt.imshow(_img) plt.show()# 定义标签与对应的字符classes = ('airplane', 'automobile', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck')# 获取一部分样本用于显示sample = iter(train_loader)images,labels = sample.next()print("样本形状:",np.shape(images))print('样本标签:',','.join('%2d:%-5s' % (labels[j],classes[labels[j]]) for j in range(len(images[:10]))))imshowrow(images[:10],nrow=10)输出:

3.5 定义DIM模型------DIM_CIRFAR_train.py(第2部分)
# 1.2 定义DIM模型class Encoder(nn.Module): # 通过多个卷积层对输入数据进行编码,生成64维特征向量 def __init__(self): super().__init__() self.c0 = nn.Conv2d(3, 64, kernel_size=4, stride=1) # 输出尺寸29 self.c1 = nn.Conv2d(64, 128, kernel_size=4, stride=1) # 输出尺寸26 self.c2 = nn.Conv2d(128, 256, kernel_size=4, stride=1) # 输出尺寸23 self.c3 = nn.Conv2d(256, 512, kernel_size=4, stride=1) # 输出尺寸20 self.l1 = nn.Linear(512*20*20, 64) # 定义BN层 self.b1 = nn.BatchNorm2d(128) self.b2 = nn.BatchNorm2d(256) self.b3 = nn.BatchNorm2d(512) def forward(self, x): h = F.relu(self.c0(x)) features = F.relu(self.b1(self.c1(h)))#输出形状[b 128 26 26] h = F.relu(self.b2(self.c2(features))) h = F.relu(self.b3(self.c3(h))) encoded = self.l1(h.view(x.shape[0], -1))# 输出形状[b 64] return encoded, featuresclass DeepInfoMaxLoss(nn.Module): # 实现全局、局部、先验判别器模型的结构设计,合并每个判别器的损失函数,得到总的损失函数 def __init__(self,alpha=0.5,beta=1.0,gamma=0.1): super().__init__() # 初始化损失函数的加权参数 self.alpha = alpha self.beta = beta self.gamma = gamma # 定义局部判别模型 self.local_d = nn.Sequential( nn.Conv2d(192,512,kernel_size=1), nn.ReLU(True), nn.Conv2d(512,512,kernel_size=1), nn.ReLU(True), nn.Conv2d(512,1,kernel_size=1) ) # 定义先验判别器模型 self.prior_d = nn.Sequential( nn.Linear(64,1000), nn.ReLU(True), nn.Linear(1000,200), nn.ReLU(True), nn.Linear(200,1), nn.Sigmoid() # 在定义先验判别器模型的结构时,最后一层的激活函数用Sigmoid函数。这是原始GAN模型的标准用法(可以控制输出值的范围为0-1),是与损失函数配套使用的。 ) # 定义全局判别器模型 self.global_d_M = nn.Sequential( nn.Conv2d(128,64,kernel_size=3), # 输出形状[b,64,24,24] nn.ReLU(True), nn.Conv2d(64,32,kernel_size=3), # 输出形状 [b,32,32,22] nn.Flatten(), ) self.global_d_fc = nn.Sequential( nn.Linear(32*22*22+64,512), nn.ReLU(True), nn.Linear(512,512), nn.ReLU(True), nn.Linear(512,1) ) def GlobalD(self, y, M): h = self.global_d_M(M) h = torch.cat((y, h), dim=1) return self.global_d_fc(h) def forward(self,y,M,M_prime): # 复制特征向量 y_exp = y.unsqueeze(-1).unsqueeze(-1) y_exp = y_exp.expand(-1,-1,26,26) # 输出形状[b,64,26,26] # 按照特征图的像素连接特征向量 y_M = torch.cat((M,y_exp),dim=1) # 输出形状[b,192,26,26] y_M_prime = torch.cat((M_prime,y_exp),dim=1)# 输出形状[b,192,26,26] # 计算局部互信息---互信息的计算 Ej = -F.softplus(-self.local_d(y_M)).mean() # 联合分布 Em = F.softplus(self.local_d(y_M_prime)).mean() # 边缘分布 LOCAL = (Em - Ej) * self.beta # 最大化互信息---对互信息执行了取反操作。将最大化问题变为最小化问题,在训练过程中,可以使用最小化损失的方法进行处理。 # 计算全局互信息---互信息的计算 Ej = -F.softplus(-self.GlobalD(y, M)).mean() # 联合分布 Em = F.softplus(self.GlobalD(y, M_prime)).mean() # 边缘分布 GLOBAL = (Em - Ej) * self.alpha # 最大化互信息---对互信息执行了取反操作。将最大化问题变为最小化问题,在训练过程中,可以使用最小化损失的方法进行处理。 # 计算先验损失 prior = torch.rand_like(y) # 获得随机数 term_a = torch.log(self.prior_d(prior)).mean() # GAN损失 term_b = torch.log(1.0 - self.prior_d(y)).mean() PRIOR = -(term_a + term_b) * self.gamma # 最大化目标分布---实现了判别器的损失函数。判别器的目标是将真实数据和生成数据的分布最大化,因此,也需要取反,通过最小化损失的方法来实现。 return LOCAL + GLOBAL + PRIOR# # 在训练过程中,梯度可以通过损失函数直接传播到编码器模型,进行联合优化,因此,不需要对编码器额外进行损失函数的定义!3.6 实例化DIM模型并训练------DIM_CIRFAR_train.py(第3部分)
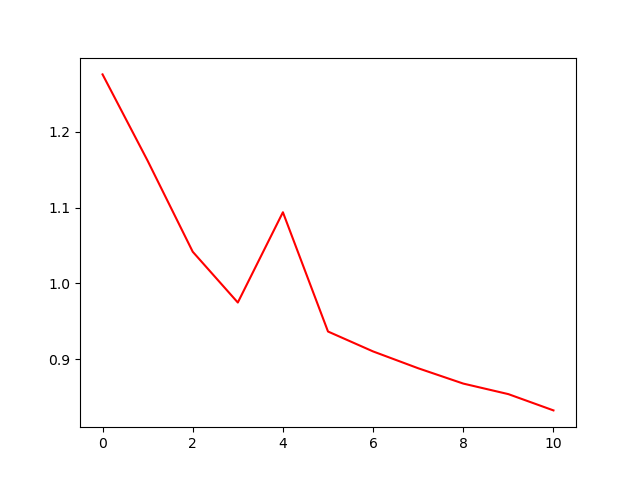
# 1.3 实例化DIM模型并训练:实例化模型按照指定次数迭代训练。在制作边缘分布样本时,将批次特征图的第1条放到最后,以使特征图与特征向量无法对应,实现与按批次打乱顺序等同的效果。totalepoch = 100 # 指定训练次数if __name__ == '__main__': encoder =Encoder().to(device) loss_fn = DeepInfoMaxLoss().to(device) optim = Adam(encoder.parameters(),lr=1e-4) loss_optim = Adam(loss_fn.parameters(),lr=1e-4) epoch_loss = [] for epoch in range(totalepoch +1): batch = tqdm(train_loader,total=len(train_dataset)//batch_size) train_loss = [] for x,target in batch: # 遍历数据集 x = x.to(device) optim.zero_grad() loss_optim.zero_grad() y,M = encoder(x) # 用编码器生成特征图和特征向量 # 制作边缘分布样本 M_prime = torch.cat((M[1:],M[0].unsqueeze(0)),dim=0) loss =loss_fn(y,M,M_prime) # 计算损失 train_loss.append(loss.item()) batch.set_description(str(epoch) + ' Loss:%.4f'% np.mean(train_loss[-20:])) loss.backward() optim.step() # 调用编码器优化器 loss_optim.step() # 调用判别器优化器 if epoch % 10 == 0 : # 保存模型 root = Path(r'./DIMmodel/') enc_file = root / Path('encoder' + str(epoch) + '.pth') loss_file = root / Path('loss' + str(epoch) + '.pth') enc_file.parent.mkdir(parents=True, exist_ok=True) torch.save(encoder.state_dict(), str(enc_file)) torch.save(loss_fn.state_dict(), str(loss_file)) epoch_loss.append(np.mean(train_loss[-20:])) # 收集训练损失 plt.plot(np.arange(len(epoch_loss)), epoch_loss, 'r') # 损失可视化 plt.show()结果:
3.7 加载模型并搜索图片------DIM_CIRFAR_loadpath.py
import torchimport torch.nn.functional as Ffrom tqdm import tqdmimport random# 功能介绍:载入编码器模型,对样本集中所有图片进行编码,随机取一张图片,找出与该图片最接近与最不接近的十张图片## 引入本地库#引入本地代码库from DIM_CIRFAR_train import ( train_loader,train_dataset,totalepoch,device,batch_size,imshowrow, Encoder)# 加载模型model_path = r'./DIMmodel/encoder%d.pth'% (totalepoch)encoder = Encoder().to(device)encoder.load_state_dict(torch.load(model_path,map_location=device))# 加载模型样本,并调用编码器生成特征向量batchesimg = []batchesenc = []batch = tqdm(train_loader,total=len(train_dataset)//batch_size)for images ,target in batch : images = images.to(device) with torch.no_grad(): encoded,features = encoder(images) # 调用编码器生成特征向量 batchesimg.append(images) batchesenc.append(encoded)# 将样本中的图片与生成的向量沿第1维度展开batchesenc = torch.cat(batchesenc,axis = 0)batchesimg = torch.cat(batchesimg,axis = 0)# 验证向量的搜索功能index = random.randrange(0,len(batchesenc)) # 随机获取一个索引,作为目标图片batchesenc[index].repeat(len(batchesenc),1) # 将目标图片的特征向量复制多份# 使用F.mse_loss()函数进行特征向量间的L2计算,传入了参数reduction='none',这表明对计算后的结果不执行任何操作。如果不传入该参数,那么函数默认会对所有结果取平均值(常用在训练模型场景中)l2_dis = F.mse_loss(batchesenc[index].repeat(len(batchesenc),1),batchesenc,reduction='none').sum(1) # 计算目标图片与每个图片的L2距离findnum = 10 # 设置查找图片的个数# 使用topk()方法获取L2距离最近、最远的图片。该方法会返回两个值,第一个是真实的比较值,第二个是该值对应的索引。_,indices = l2_dis.topk(findnum,largest=False ) # 查找10个最相近的图片_,indices_far = l2_dis.topk(findnum,) # 查找10个最不相关的图片# 显示结果indices = torch.cat([torch.tensor([index]).to(device),indices])indices_far = torch.cat([torch.tensor([index]).to(device),indices_far])rel = torch.cat([batchesimg[indices],batchesimg[indices_far]],axis = 0)imshowrow(rel.cpu() ,nrow=len(indices))# 结果显示:结果有两行,每行的第一列是目标图片,第一行是与目标图片距离最近的搜索结果,第二行是与目标图片距离最远的搜索结果。
4 代码总览
4.1 训练模型:DIM_CIRFAR_train.py
import torchfrom torch import nnimport torch.nn.functional as Fimport torchvisionfrom torch.optim import Adamfrom torchvision.transforms import ToTensorfrom torch.utils.data import DataLoaderfrom torchvision.datasets.cifar import CIFAR10from matplotlib import pyplot as pltimport numpy as npfrom tqdm import tqdmfrom pathlib import Pathfrom torchvision.transforms import ToPILImageimport osos.environ["KMP_DUPLICATE_LIB_OK"]="TRUE"# 1.1 获取数据集并显示数据集# 指定运算设备device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')print(device)# 加载数据集batch_size = 512data_dir = r'./cifar10/'# 将CIFAR10数据集下载到本地:共有三份文件,标签说明文件batches.meta,训练样本集data_batch_x(一共五个,包含10000条训练样本),测试样本test.batchtrain_dataset = CIFAR10(data_dir,download=True,transform=ToTensor())train_loader = DataLoader(train_dataset,batch_size=batch_size,shuffle=True,drop_last=True,pin_memory=torch.cuda.is_available())print("训练样本个数:",len(train_dataset))# 定义函数用于显示图片def imshowrow(imgs,nrow): plt.figure(dpi=200) # figsize=(9,4) # ToPILImage()调用PyTorch的内部转换接口,实现张量===>PLImage类型图片的转换。 # 该接口主要实现。(1)将张量的每个元素乘以255。(2)将张量的数据类型由FloatTensor转化成uint8。(3)将张量转化成NumPy的ndarray类型。(4)对ndarray对象执行transpose(1,2,0)的操作。(5)利用Image下的fromarray()函数,将ndarray对象转化成PILImage形式。(6)输出PILImage。 _img = ToPILImage()(torchvision.utils.make_grid(imgs,nrow=nrow)) # 传入PLlmage()接口的是由torchvision.utis.make_grid接口返回的张量对象 plt.axis('off') plt.imshow(_img) plt.show()# 定义标签与对应的字符classes = ('airplane', 'automobile', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck')# 获取一部分样本用于显示sample = iter(train_loader)images,labels = sample.next()print("样本形状:",np.shape(images))print('样本标签:',','.join('%2d:%-5s' % (labels[j],classes[labels[j]]) for j in range(len(images[:10]))))imshowrow(images[:10],nrow=10)# 1.2 定义DIM模型class Encoder(nn.Module): # 通过多个卷积层对输入数据进行编码,生成64维特征向量 def __init__(self): super().__init__() self.c0 = nn.Conv2d(3, 64, kernel_size=4, stride=1) # 输出尺寸29 self.c1 = nn.Conv2d(64, 128, kernel_size=4, stride=1) # 输出尺寸26 self.c2 = nn.Conv2d(128, 256, kernel_size=4, stride=1) # 输出尺寸23 self.c3 = nn.Conv2d(256, 512, kernel_size=4, stride=1) # 输出尺寸20 self.l1 = nn.Linear(512*20*20, 64) # 定义BN层 self.b1 = nn.BatchNorm2d(128) self.b2 = nn.BatchNorm2d(256) self.b3 = nn.BatchNorm2d(512) def forward(self, x): h = F.relu(self.c0(x)) features = F.relu(self.b1(self.c1(h)))#输出形状[b 128 26 26] h = F.relu(self.b2(self.c2(features))) h = F.relu(self.b3(self.c3(h))) encoded = self.l1(h.view(x.shape[0], -1))# 输出形状[b 64] return encoded, featuresclass DeepInfoMaxLoss(nn.Module): # 实现全局、局部、先验判别器模型的结构设计,合并每个判别器的损失函数,得到总的损失函数 def __init__(self,alpha=0.5,beta=1.0,gamma=0.1): super().__init__() # 初始化损失函数的加权参数 self.alpha = alpha self.beta = beta self.gamma = gamma # 定义局部判别模型 self.local_d = nn.Sequential( nn.Conv2d(192,512,kernel_size=1), nn.ReLU(True), nn.Conv2d(512,512,kernel_size=1), nn.ReLU(True), nn.Conv2d(512,1,kernel_size=1) ) # 定义先验判别器模型 self.prior_d = nn.Sequential( nn.Linear(64,1000), nn.ReLU(True), nn.Linear(1000,200), nn.ReLU(True), nn.Linear(200,1), nn.Sigmoid() # 在定义先验判别器模型的结构时,最后一层的激活函数用Sigmoid函数。这是原始GAN模型的标准用法(可以控制输出值的范围为0-1),是与损失函数配套使用的。 ) # 定义全局判别器模型 self.global_d_M = nn.Sequential( nn.Conv2d(128,64,kernel_size=3), # 输出形状[b,64,24,24] nn.ReLU(True), nn.Conv2d(64,32,kernel_size=3), # 输出形状 [b,32,32,22] nn.Flatten(), ) self.global_d_fc = nn.Sequential( nn.Linear(32*22*22+64,512), nn.ReLU(True), nn.Linear(512,512), nn.ReLU(True), nn.Linear(512,1) ) def GlobalD(self, y, M): h = self.global_d_M(M) h = torch.cat((y, h), dim=1) return self.global_d_fc(h) def forward(self,y,M,M_prime): # 复制特征向量 y_exp = y.unsqueeze(-1).unsqueeze(-1) y_exp = y_exp.expand(-1,-1,26,26) # 输出形状[b,64,26,26] # 按照特征图的像素连接特征向量 y_M = torch.cat((M,y_exp),dim=1) # 输出形状[b,192,26,26] y_M_prime = torch.cat((M_prime,y_exp),dim=1)# 输出形状[b,192,26,26] # 计算局部互信息---互信息的计算 Ej = -F.softplus(-self.local_d(y_M)).mean() # 联合分布 Em = F.softplus(self.local_d(y_M_prime)).mean() # 边缘分布 LOCAL = (Em - Ej) * self.beta # 最大化互信息---对互信息执行了取反操作。将最大化问题变为最小化问题,在训练过程中,可以使用最小化损失的方法进行处理。 # 计算全局互信息---互信息的计算 Ej = -F.softplus(-self.GlobalD(y, M)).mean() # 联合分布 Em = F.softplus(self.GlobalD(y, M_prime)).mean() # 边缘分布 GLOBAL = (Em - Ej) * self.alpha # 最大化互信息---对互信息执行了取反操作。将最大化问题变为最小化问题,在训练过程中,可以使用最小化损失的方法进行处理。 # 计算先验损失 prior = torch.rand_like(y) # 获得随机数 term_a = torch.log(self.prior_d(prior)).mean() # GAN损失 term_b = torch.log(1.0 - self.prior_d(y)).mean() PRIOR = -(term_a + term_b) * self.gamma # 最大化目标分布---实现了判别器的损失函数。判别器的目标是将真实数据和生成数据的分布最大化,因此,也需要取反,通过最小化损失的方法来实现。 return LOCAL + GLOBAL + PRIOR# # 在训练过程中,梯度可以通过损失函数直接传播到编码器模型,进行联合优化,因此,不需要对编码器额外进行损失函数的定义!# 1.3 实例化DIM模型并训练:实例化模型按照指定次数迭代训练。在制作边缘分布样本时,将批次特征图的第1条放到最后,以使特征图与特征向量无法对应,实现与按批次打乱顺序等同的效果。totalepoch = 10 # 指定训练次数if __name__ == '__main__': encoder =Encoder().to(device) loss_fn = DeepInfoMaxLoss().to(device) optim = Adam(encoder.parameters(),lr=1e-4) loss_optim = Adam(loss_fn.parameters(),lr=1e-4) epoch_loss = [] for epoch in range(totalepoch +1): batch = tqdm(train_loader,total=len(train_dataset)//batch_size) train_loss = [] for x,target in batch: # 遍历数据集 x = x.to(device) optim.zero_grad() loss_optim.zero_grad() y,M = encoder(x) # 用编码器生成特征图和特征向量 # 制作边缘分布样本 M_prime = torch.cat((M[1:],M[0].unsqueeze(0)),dim=0) loss =loss_fn(y,M,M_prime) # 计算损失 train_loss.append(loss.item()) batch.set_description(str(epoch) + ' Loss:%.4f'% np.mean(train_loss[-20:])) loss.backward() optim.step() # 调用编码器优化器 loss_optim.step() # 调用判别器优化器 if epoch % 10 == 0 : # 保存模型 root = Path(r'./DIMmodel/') enc_file = root / Path('encoder' + str(epoch) + '.pth') loss_file = root / Path('loss' + str(epoch) + '.pth') enc_file.parent.mkdir(parents=True, exist_ok=True) torch.save(encoder.state_dict(), str(enc_file)) torch.save(loss_fn.state_dict(), str(loss_file)) epoch_loss.append(np.mean(train_loss[-20:])) # 收集训练损失 plt.plot(np.arange(len(epoch_loss)), epoch_loss, 'r') # 损失可视化 plt.show()4.2 加载模型:DIM_CIRFAR_loadpath.py
import torchimport torch.nn.functional as Ffrom tqdm import tqdmimport random# 功能介绍:载入编码器模型,对样本集中所有图片进行编码,随机取一张图片,找出与该图片最接近与最不接近的十张图片## 引入本地库#引入本地代码库from DIM_CIRFAR_train import ( train_loader,train_dataset,totalepoch,device,batch_size,imshowrow, Encoder)# 加载模型model_path = r'./DIMmodel/encoder%d.pth'% (totalepoch)encoder = Encoder().to(device)encoder.load_state_dict(torch.load(model_path,map_location=device))# 加载模型样本,并调用编码器生成特征向量batchesimg = []batchesenc = []batch = tqdm(train_loader,total=len(train_dataset)//batch_size)for images ,target in batch : images = images.to(device) with torch.no_grad(): encoded,features = encoder(images) # 调用编码器生成特征向量 batchesimg.append(images) batchesenc.append(encoded)# 将样本中的图片与生成的向量沿第1维度展开batchesenc = torch.cat(batchesenc,axis = 0)batchesimg = torch.cat(batchesimg,axis = 0)# 验证向量的搜索功能index = random.randrange(0,len(batchesenc)) # 随机获取一个索引,作为目标图片batchesenc[index].repeat(len(batchesenc),1) # 将目标图片的特征向量复制多份# 使用F.mse_loss()函数进行特征向量间的L2计算,传入了参数reduction='none',这表明对计算后的结果不执行任何操作。如果不传入该参数,那么函数默认会对所有结果取平均值(常用在训练模型场景中)l2_dis = F.mse_loss(batchesenc[index].repeat(len(batchesenc),1),batchesenc,reduction='none').sum(1) # 计算目标图片与每个图片的L2距离findnum = 10 # 设置查找图片的个数# 使用topk()方法获取L2距离最近、最远的图片。该方法会返回两个值,第一个是真实的比较值,第二个是该值对应的索引。_,indices = l2_dis.topk(findnum,largest=False ) # 查找10个最相近的图片_,indices_far = l2_dis.topk(findnum,) # 查找10个最不相关的图片# 显示结果indices = torch.cat([torch.tensor([index]).to(device),indices])indices_far = torch.cat([torch.tensor([index]).to(device),indices_far])rel = torch.cat([batchesimg[indices],batchesimg[indices_far]],axis = 0)imshowrow(rel.cpu() ,nrow=len(indices))# 结果显示:结果有两行,每行的第一列是目标图片,第一行是与目标图片距离最近的搜索结果,第二行是与目标图片距离最远的搜索结果。
