Input operand 1 has a mismatch in its core dimension 0, with gufunc signature (n?,k),(k,m?)->(n?,m?)
ValueError: matmul: Input operand 1 has a mismatch in its core dimension 0, with gufunc signature (n?,k),(k,m?)->(n?,m?) (size 1 is different from 368)
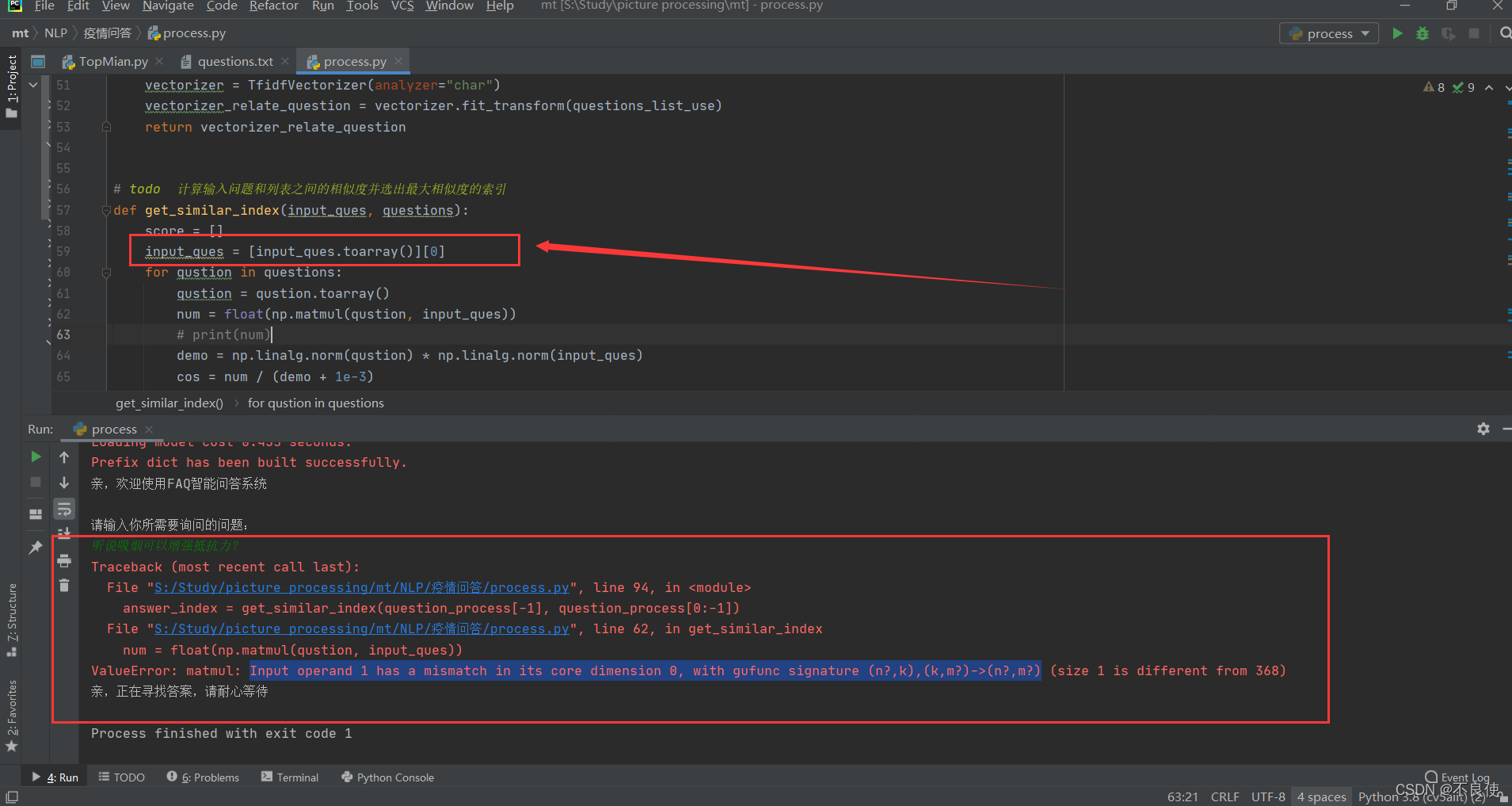
在网上搜说是版本高了,不可以,试了好久,就差把所有的版本都下下来试试了,然后偶然想到,是不是类型错了。于是就断点调试一步步网上调试。他不是直接和你说这句话有问题,而是拐弯抹角的和你说,就是很烦。最后在input_ques = [input_ques.toarray()][0]发现了错误,你见过toarray()外面的括号是列表形式的???
恍然大悟,括号(可以理解为元组)写成列表([])了。
我的代码如下:
# TODO 鸟欲高飞,必先展翅# TODO 向前的人 :Jhonimport reimport jiebaimport numpy as npfrom sklearn.feature_extraction.text import TfidfVectorizer# todo 格式化代码快捷键 Alt+Ctrl+L# todo 读取文件def read_corpus(file): list = [] with open(file, "r", encoding="UTF-8") as f: lines = f.readlines() for i in lines: list.append(i) return list# todo 对问题进行分词、正则化处理def get_questions(questions): if len(questions) == 1: # todo 正则化处理 ,过滤标点符号和无效字符 new_sent = re.sub(r'[^\w]', '', questions[0]) # todo isalnum()用来判断一个字符是否为数字或者字母 new_sent = " ".join(i for i in new_sent if i.isalnum()) new_sent = " ".join(jieba.lcut(new_sent)) return new_sent else: question_list = [] for setence in questions: # todo 正则化处理 ,过滤标点符号和无效字符 new_sent = re.sub(r'^\w', "", setence) # todo isalnum()用来判断一个字符是否为数字或者字母 new_sent = " ".join(i for i in setence if i.isalnum()) seg_list = " ".join(jieba.lcut(new_sent)) question_list.append(seg_list) return question_list# todo 定义函数输入处理输入的问题def solove_questions(questions_list, input_ques): # todo 输入问题正则化、jieba分词后加入到问题列表中 questions_list_use = questions_list.copy() # 备份 input_quession = [input_ques] input_quessions = get_questions(input_quession) questions_list_use.append(input_quessions) # todo 用TF-IDF 向量化新的问题列表 vectorizer = TfidfVectorizer(analyzer="char") vectorizer_relate_question = vectorizer.fit_transform(questions_list_use) return vectorizer_relate_question# todo 计算输入问题和列表之间的相似度并选出最大相似度的索引def get_similar_index(input_ques, questions): score = [] input_ques = (input_ques.toarray())[0] for qustion in questions: qustion = qustion.toarray() num = float(np.matmul(qustion, input_ques)) # print(num) demo = np.linalg.norm(qustion) * np.linalg.norm(input_ques) cos = num / (demo + 1e-3) score.append(cos) if max(score) < 0.1: print("亲,对不起,本FAQ中暂时还没有收录你所提到的问题,我们将会继续改进!") else: best_index = score.index(max(score)) return best_indexif __name__ == '__main__': # todo 获取问题列表和答案列表冰进行预处理 # todo 获取问题和列表 这里建议问题和答案放在一行,不然会一个答案出现问题(缺失),后面的答案会乱序 questions = read_corpus("./data/questions.txt") answers = read_corpus("./data/answers.txt") # todo 对问题列表进行预处理 questions_list = get_questions(questions) print("亲,欢迎使用FAQ智能问答系统") while True: print("") input_ques = input("请输入你所需要询问的问题:\n") if input_ques.upper() == "Q": print("觉得有帮助可以来个三连!") break else: # todo 处理输入的问题 question_process = solove_questions(questions_list, input_ques) # todo 获取最大问题相似度的索引并给出相应的答案 print("亲,正在寻找答案,请耐心等待") answer_index = get_similar_index(question_process[-1], question_process[0:-1]) if answer_index is not None: print("亲,我们为你找到的答案如下:\n", answers[answer_index]) print("亲,你可能还想了解这些问题", questions[answer_index])结果: