【AC.HASH】OpenHarmony啃论文俱乐部——基于最优排序的局部敏感哈希索引之浅析
- 本文出自 AC.HASH团队,ACAdaptive Creator,适应性创作者,旨在于能够在未来新领域下创造出新的哈希算法以应对未来局面。
- 产出本文的成员:
- 四名中原工学院大一在校生
- 我们是来自同一个班级的同学,我们在OpenHarmony成长计划啃论文俱乐部里,与华为、软通动力、润和软件、拓维信息、深开鸿等公司一起,学习和研究操作系统技术…
-
Table of Contents
【本期看点】
【智慧场景】
1.在局部敏感哈希研究与应用方面的介绍
2.相关概念
2.1解读局部敏感哈希(LSH)
2.2基于LSH的近邻候选点鉴别机制
3.基于空间曲线进一步改善I/O性能
3.1介绍现有外存索引I/O性能
3.2简要分析几种空间曲线及其特性
4局部敏感哈希(O2LSH)索引方案
4.1索引结构
4.3近邻查询效果分析
4.4复杂度分析
5实验结果与分析
6总结
7.参考文献
【本期看点】
主题:《老子到此一游系列》之 老子游玩了一条河
基于最优排序的局部敏感哈希在索引方面的应用
【智慧场景】

1介绍
近年来最近邻(Nearest Neighbor,NN)查询被广泛应用于文本信息检索、搜索引擎、基于图像内容的信息查询、数据重复性检测等地方.在这些领域中,难免少不了一些占用庞大存储空间的数据,所以想要快速、有效的进行相关查询提具有一定的难度,同时也给最近邻查询带来的巨大的挑战.具体表现在高维空间中的“维数灾难”难以克服,使得越来越多的研究者开始关注近似最近(Approximate Nearest Neighbor,ANN)查询算法,即在误差较小的的范围内通过寻找出近似解从而达到查询速度的提升。因为海量数据集一般体量巨大,内存空间较小,所以在外存空间里储存成为了更加合理的的一种选择.但是在内存中查询的速度比在外存中查询的速度快很多,这样使得二者之间的通信(即I/O)代价变得十分昂贵.如果通信次数过多,或者访问外存的方式不太合理,会消耗大量的查询时间,降低查询的效率,学术上称之为I/O性能瓶颈。
据了解现有外存ANN查询方案主要包括局部敏感哈希系列技术(Locality Sensitive Hashing,LSH)、乘积量化技术(Product Quantization,PQ)和近邻图技术(Nearest Neighbor Graph,NNG)等。在几种查询方法中,LSH的误差较小并且计算的效率也比较高,是目前解决ANN查询使用最为广泛的技术。
LSH是一种特殊的哈希函数,能够将原始空间中邻近的点较大概率的映射到相同的哈希桶,简单的来说就是使真实位置和近似值更加的接近。通过构建复合LSH函数 (Compound LSH Function)和建立多索引哈希表的方法来提升相似点之间的碰撞的概率,从而可以大大的减少近邻点的误报(False Positive,FP)和漏报(False Negative,FN)现象.据调查目前学术上先进的外存 LSH方案主要有LSB—Forest、C2LSH、SRS和QALSH等.它们的查询算法一般分为两个部分:
- 在内存中过滤无关数据并确立近邻候选点,并将这些点转移向外存;
- 从外存读入候选点的相关数据,通过相关算法计算出最近邻结果;
值得一提的是,它们都有一个共性的问题,方案中确立的候选点大部分都随机分布在磁盘上.然而研究者为了保证查询精度,一般需要从外存中读入大量的候选点,这样就会消耗大量的查询的时间和查询的能力,使得近邻查询的速度大大降低.研究发现,为提高ANN查询的I/O效率,有研究者提出一种基于排序的LSH索引方案SK—LSH.它利用row—wise空间填充曲线(简称空间曲线)为复合哈希键值构造一种空间线序(简称线序) 并对其排序.将原始的数据重新按照新的顺序在磁盘上进行排列。这样可以让更多近邻候选点更加靠近,同时,在一个磁盘页面一般可以存储多个候选点,因此一次I/O可以同时加载到更多候选点。但是在实际ANN查询时一般会存在三个局限:
(1)row—wise线序在局部排列时会发生漏报;
(2)线序的局部排列效果会对LSH关键参数变化敏感,依赖较大的桶宽,影响算法实用性;
(3)桶宽越大会引入更多近邻干扰点,此时就会更多哈希函数来过滤,这样会大大降低计算的效率。
本文第2节介绍LSH相关基本概念和鉴别机制;第3节分析了一些现有外存索引研究的现状,并对不同曲线下的近邻分布质量展开研究;第4节得出了索引构建和查询算法;第5节进行了相关的实验对比;第6节进行总结和结果的分析.
2相关概念
2.1局部敏感哈希(LSH)
2.1.1条件
给定一个高维特征向量集Rd∈D,共包含n个 d维空间的特征向量(或特征点),令||代表两个点间的欧式距离.对于查询点q∈Rd,ANN查询是指从D中搜索到一点x,使得||q,x||≤c||q,x*||其中 x*是q在D中的真实最近邻,c>1是近似查询的比率.
2.1.2定义
LSH函数:令B(q,r)表示d维空间 中以p为中心点,半径为r的超球.给定近似比率c和两个概率值p1、p2(p1>p2)对于于Rd空间中任意两点x、q,如果函数组H={h:Rd→Z}满足如下两个条件,则称H是(r,cr,p1,p2)-敏感的:

其中(1)在欧式空间中比较常用,且h(x)的计算方法如下:

第一步生成一个d维向量n,且n的每个维度的分量都遵循标准正态分布的规律,其次可将n所在的方向直线分成单位宽度为W的等区间.此时可以使数据集D中任意一点x在a上投影,并让x沿着a的方向移动b的长度,x最终落入的区间的编号即是哈希值h(x)。其中,b是一个随机数,可由用户自己定义,但需要服从[0,W)上的均匀分布.
对于上面h(x)中,相距s的两个点x1,x2落在相同区段的概率可由如下公式计算:
该公式表明,桶宽w固定时,x1,x2发生碰撞的概率随二者之间距离s的增加而单调递减.反之,随距离s的减小而增大。

2.2基于LSH的近邻候选点鉴别机制
LSH能够让原始空间中邻近的点碰撞的几率变大。且假如在单个LSH函数中,可以在原始空间中取与查询点q落入相同区间的点作为近邻候选点,大大的提高的查询的准确性.但仍然会有一些距离q点较远的点也能与q点碰撞,这些点被称作假阳性点(False Positive,FP).通常可以使用复合哈希函数进行联合过滤。复合哈希函数能有效解决假阳性问题,但也会产生另外一个问题:假阴性现象。原因在于随着哈希函数数量的增多,一些原本较近的点可能被错误地排除掉,这些点称为假阴性点(False Negative,FN).FN点同样会降低查询精度.目前学术上的解决办法是建立多组复合哈希函数。
3基于空间曲线进一步改善I/O性能
3.1现有外存索引I/O性能
首先普及一下I/O是什么,通俗来说就是进行内外存交互,应用于本篇主要是进行ANN查询过程中访问磁盘的次数。众所周知,内存空间小但跑的速度快,外存空间大但跑的速度慢。这就需要大量的数据储存在外存中,调用时进行内外存交互。这个消耗的时间就成了一个技术点。在面对庞大的数据读取运用时,其消耗的时间是非常可观的,消耗不起,也不敢消耗。
而目前主要问题就是I/O(内外存通信)效率低下。造成这的主要原因是因为候选点是随机分布的又由于先确定候选点,然后再读入,精炼。为了保证近邻查询的精度需要加载足够多的候选点(I/O次数多了)十分耗时容易形成速度瓶颈。在这里提出了两种方案:第一是降低I/O次数。 第二是优化I/O方式。
对应的也提出了一些解决方案。
- 一种缓存候选点紧凑编码的技术在候选点加载前利用紧凑编码进行上下界判断,能够较早地将一些无关点排除.不过本质上其候选点仍旧是随机加载,存在加载效率低的问题.如图:

2.基于排序的LsH索引方案SK—LSH[15|,借助空问填充曲线技术实现候选点的局部分布,可以同时实现以上两个目标.
3.2简要分析几种空间曲线及其特性
这些模型都涉及到了空间降维技术,空间降维技术通俗来讲就是多维空间映射到一维空间,实现:将多维空间划分成超立方体网格,按照某种规则不重复地遍历所有网格并递增地为所遍历网格分配一个独特的编号,编号递增的顺序就是曲线为多维空间规定的一维空间线序。空间曲线的一个特性: 曲线上编号邻近的网格在实际空间中往往也是邻近的,如果数据依照空间线序在磁盘上存放,就能实现让很多邻近点在磁盘局部聚集存放的目标.
在这方面:LSB—Forest是最早将空间曲线技术引LSH索引的方法,但其进行近邻查询时仍旧需要耗费大量的随机I/O;sK—LsH率先指出了空间曲线下近邻候选点的局部分布对改善I/O效率的意义,但仅选择了一种较为简单的row—wise曲线构造空间线序,导致近邻查询算法依旧存在多种局限.
下面介绍两种填充特性分别是维度优先遍历和邻域优先遍历.其使用原理都是利用空间曲线进行相应的特性填充.现在我们要找要找一个较好近邻候选点局部分布质量曲线其评价标准为一条空间填充曲线,如果能在相同的局部范围内汇集更多近邻点,就称该曲线能够产生更好的近邻候选点局部分布.
维度优先遍历以row--wise曲线为例如图:

row--wise较下述曲线最明显的区别体现在曲线填充时优先级的分配上,如X维度的填 充优先级要大于y维度.因此,曲线会率先填充高优先级的x维度,完成之后进入次高优先级的y维 度上移动一个网格,然后返回高优先级的X维度继续填充这实现了数据的保护但会导致一些问题.如图中的圆圈O相当于一个哈希桶,半径R为桶半径,当R=1时达到50%发召回率,当R=3时会把F点召回,但图中F点不在划分的哈希桶中这就产生了误报,给F点提供的服务质量非常的不好,当R=8时,才能满足100%的召回率,但这样会使数据的读取量非常庞大,导致I/O次数增多,会降低用户的体验感.
邻域优先遍历如图:

以Hilbert曲线为例如图:

与row--wise曲线同样取的一个圆圈O为一个空间划分区域通过半径的变化来比较其召回率当R=1时也达到了50%发召回率.当R=3时会召回率达到了75%.当R=5时,一进达到了100%的召回率.其相对于维度优先遍历较好的避免了.
其各自优劣总结如下
- row--wise曲线能够较好地召回高优先级维度上的近邻点,但是也容易在高优先级维度上引入误报点,而处在较低优先级维度上的近邻则比较容易形成漏报点;
- Hilbert曲线曲线由于优先遍历邻域,能够较好地避免非邻域中的点成为误报点的情况,且对于处在曲线遍历邻域中的近邻也能够较好的召回.但是对于跨越了多个曲线填充时划分的子空问的近邻邻域,则有可能形成漏报点.
4局部敏感哈希(O2LSH)索引方案
4.1索引结构
步骤1.求原始数据点的线序值
给定d维数据点p∈R^d,其在复合哈希函数G下的哈希值k=
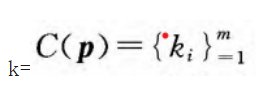
是一个m元组.构造m维空间的Hilbert曲线将K在曲线上映射,得到一个整数值,称其为p的线序值,记为Op
步骤2.构造结构
2.1数据中的每一个点利用上述公式求出哈希函数值,在将哈希值映射到Hilbert曲线上,这样将会得到一个整数值,该整数值成为线序值
2.2对所求得的所有线序值进行排序
2.3利用重新排好的顺序在对原先的数据进行排序,得到一个重新排序的数据集,再把该数据集保存在网页上
2.4对于每一个网页,利用第一个线序值和最后一个线序值,把两个线序值提取出来,然后构造b+树结构,就可以对原始的所有数据值进行查询
如图:

4.2最近邻查询算法
该算法查询过程可以分为两个阶段,第一阶段是确定候选页面,从众多的候选页面中选出最优的页面,也就是查询点到该页面的距离最近的页面,第二个阶段是所有候选点的加载以及最近邻验证的阶段
4.3近邻查询效果分析
02LSH使用了NFT特性的曲线,能够使近邻候选点的分布更加均匀,使其在局部区域内分布更加公平,从而在近邻查询过程中能够查询到更多高质量的候选点,大大提升了查询效果,从而获得更好的查询性能,02LSH使用了NFT特性的曲线.
4.4复杂度分析
(1)空间复杂度
假设02LSH的索引结构共包含N个哈希表,每一个哈希表均有一个b+树和一个数据集组成,假设一个网页能存入B个数据点,则一个B+树的空间开销是O(nm/B),其中n是数据集规模,m是复合哈希键值的维度.因此02LSH总共的空间开销是O(Nn(m/B+d)).通常情况下m/B<<d,因此可以看到02LSH索引中最主要的空问开销是原始数据.
(2)时间复杂度
02LSH的总时间主要包括两部分:(1)在N个B+树中搜索定位所有网页的时间;(2)加载并处理N个候选网页的时间.
5实验结果与分析
我们可以从三个方面衡量算法再外存环境下进行ANN查询的性能,包括:ratio,I/O,和空间开销,ratio用于评估ANN查询的准确率,I/O是算法进行ANN查询过程中访问磁盘页面的次数,空间开销.是算法进行ANN查询所需数据总的存储开销,一般包括数据集和索引两个部分。将所有查询点的平均性能作为最终性能。
由于O2LSH与SK-LSH都是基于空间线序的LSH索引技术,将二者的在四个不同参数的变化下的性能对比,得出在一定条件下,O2LSH性能比较优越的结论。具体如下:
- SK-LSH的准确率对桶宽变化十分敏感,只有在设置合适的桶宽时才能取得最好的准确率,而O2LSH的准确率相对比较稳定,在一定范围内都能取到最优值,且最优值优于SK-LSH的最优值,但桶宽不能过大,在w取1000和更大数值时,O2LSH的ratio开始变差,出现和SK-LSH性能重叠的现象。如图:

- SK-LSH和O2LSH的ratio一开始都会随复合哈希函数中LSH函数个数m的增大而下降,当m增大到一定程度,ratio趋于平稳,说明存在一定的哈希函数数量可以充分过滤掉假阳性点,从下图实验数据可以看出,O2LSH使用了一半的哈希函数开销取得了和SK-LSH相当甚至更优的查询准确率。

- 允许加载的候选页面个数增大,局部搜索的范围增大,可以考察更多的候选点,提升查询准确率,但是同时也会增加算法的I/O开销和时间开销,实际查询中,需要根据需求决定。
- 同允许加载的候选页面个数类似,更多的哈希表一定程度也能提升查询准确率,,但更多的哈希表意味着更大的空间开销,所以需权衡查询精度和效率最终决定。
根据研究表示,O2LSH几乎在所有数据集上都能以最少的I/O开销取得最好的查询准确率,优于其他方案,且领先性不受数据集维度和数据集规模的影响。
6总结
基于排序的LSH索引有助于克服外存环境下海量高维ANN查询面临的问题,O2LSH最大程度地改善了近邻候选点的局部分布,提升ANN查询的I/O效率和精度,降低对关键参数变化的敏感性,更加高效实用。构建索引方案是为了提高整体的查询效率,能够更方便更简洁更快速的查询到原始数据,该方案主要依据最近邻查询算法,该算法比以往的算法有更高的查询性能,因此索引结构大大提高了工作效率。局部敏感哈希函数掺杂于正态分布的一些理论和知识,且引用了概率学中的相关碰撞问题,以客观抽象的实例来将哈希函数实体化,同时引用一些数学概念和线性曲线更好的解释了其筛选的机制。
-
参考文献
[1]基于最优排序的局部敏感哈希索引冯小康, 彭延国,崔江涛 刘英帆,李辉。计 算 机 学 报V01.43 No.5 Mav 2020 .
如有侵权请及时联系删除。

