Mysql索引与优化
文章目录
- 摘要
- 一、Mysql中的索引
- 二、EXPLAIN介绍
-
- EXPLAIN说明
- Extra
- 三、注意
-
- 慢查询分析
- 分页查询分析
- 有时候全表扫描比索引快
摘要
我们使用数据库都希望数据库的查询效率快一点好,这个时候一般都是增加索引,MySQL中的索引有哪些?怎么判断一个SQL语句的好坏?如何去优化SQL语句,本文将进行简单的讲解。
一、Mysql中的索引
Mysql中的索引类型主要分为下面几类:
| 类型 | 解释 |
|---|---|
| 普通索引 | 这是Mysql中最基本的索引,没有任何限制。 |
| 唯一索引 | 唯一索引要求建立索引的列值必须唯一,可以存在NULL。 |
| 主键索引 | 主键索引指的是在主键上面建立的索引。 |
| 复合索引 | 上面说的三种索引都是针对的一列,复合索引是多列建立的索引。 |
| 全文索引 | 全文索引是建立在文本上面的,主要针对文本like查询效率较慢做的索引。 |
在Mysql5.6之前的时候,全文索引只存在MyISAM存储引擎中,从Mysql5.6开始InnoDB也增加了全文索引的支持。全文索引优点类似于ES搜索引擎,ES是通过IK分词器把内容分割成不同的词组,全文索引同样是将存储的文本分割词组,如果做文本搜索的话还是建议使用搜索引擎。
复合索引的应用常见于我们平常做的列表页面上面经常会有多个筛选条件,这样就可以使用筛选条件字段建立复合索引,复合索引遵循最左前缀原则。最左前缀原则指的是组合成索引的多个字段必须从左边开始才能生效,如果跳过左侧字段直接使用右侧字段是无效的。
例如有个天气表,使用了城市名、日期、天气建立名叫index_left的索引。
EXPLAIN SELECT * FROM weather WHERE cityname = '呼和浩特市' AND date = '2021-10-26'使用上面SQL进行查询,可以看到查询分析上面使用了索引。

而我们跳过左边的城市名,查询日期看结果没有使用索引。

二、EXPLAIN介绍
上面我们使用到了一个命令叫EXPLAIN,这是Mysql中提供的用来分析SELECT查询语句的,再次使用一下上面的查询结果来看一下。
EXPLAIN说明

EXPLAIN出来的结果中有这么几个重要的字段信息:
- select_type: 查询的类型,SIMPLE(简单的查询)、PRIMARY(最外层的查询)、UNION(连表后续的查询)、SUBQUERY(SELECT子查询语句)等类型。
- type: 查询数据是采用的方式,ALL(全表扫描)、index(基于索引的全表扫描)、range(索引范围查询)、ref(非唯一索引的单值查询)、const(唯一索引常量查询)、NULL(没有查询表)。
- possible_keys: 表示查询过程中可能用到的索引,查询语句where中使用到了建立索引的字段,所以SQL有可能用到该索引。
- key: 表示查询过程中真正用到的索引,虽然where使用到了索引字段,但是写法不合格所以有可能没有用到索引,所以这里的显示有可能比possible_keys少。
- rows: 表示查询过程中扫描的行数,使用索引了就扫描索引行,没有就全表扫描为表中数据数量。
- Extra: 查询过程中的其他信息,using where(通过索引回表查询数据)、using index(只通过索引就查询到了)、using filesort(查询结果需要二外排序)等信息。
当然当我们EXPLAIN的结果显示没有使用索引的时候肯定是比较慢的,这时候需要考虑优化SQL语句了。前面几个字段咱就不看了,只要判断是否使用索引就可以了,咱重点看一下最后一个字段Extra信息。
Extra
要了解Extra中显示的内容是什么意思,先介绍几个概念。
辅助索引: 辅助索引指的是不是主键ID建立起来的索引,为什么要叫辅助索引呢,因为其在查询的时候有辅助功能,看一下下图:
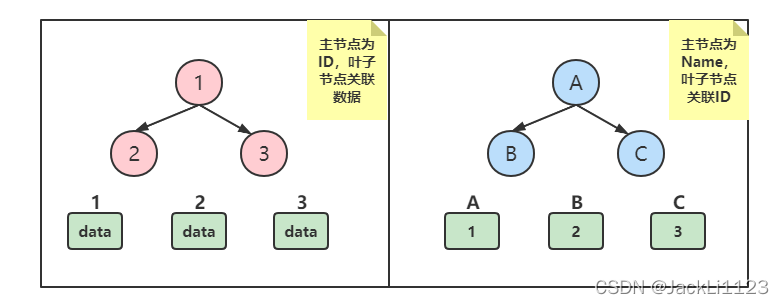
我们知道Mysql中InnoDB使用的是B+树来实现的,假设我们建立的表中使用了主键索引,所以生成了第一个B+树,这个树的叶子节点是通过ID关联的数据;如果我们通过name建立了另一个索引,那么就会再生成一个辅助的树,而辅助的树是通过name字段关联的ID。那么这里就又产生了一个概念叫做回表扫描,回表扫描是这样产生的,假设我们使用Name字段作为查询条件查询所有字段,那么就会走辅助树,通过Name查询到ID,然后再到主树里面通过ID找到所有的数据,扫描了两遍,这就叫做回表扫描。
下面来看一下Extra里面产生的信息都是什么意思:
- Using where: 本身其实和是否使用索引无关,它表示的是Server层对存储引擎层返回的数据所做的过滤。当然该过滤可能会回表,也可能不会回表,取决于查询字段是否被索引覆盖。
EXPLAIN SELECT * FROM weather WHERE date = '2020-3-2' 看这个SQL语句,因为date上面没有使用索引,而且查询的是全部,所以使用的using where

- Using index: 表示直接访问索引就足够获取到所需要的数据,不需要通过索引回表;
EXPLAIN SELECT cityname FROM weather WHERE cityname = '呼和浩特市' 因为查询的cityname是建立有索引的,而且返回的字段也是索引字段,所以使用了Using index,假如返回的字段里面包含非索引字段就不用这个了。

- Using index condition: 查找使用了索引,但是需要回表查询数据。
EXPLAIN SELECT * FROM weather WHERE cityname = '呼和浩特市' AND weather = '晴' order by date看一下这种情况,查询的字段使用到了索引,但是返回的信息是所有的数据,并且还排了序,而且排序字段没有使用索引,所以一开始需要使用辅助树找到ID,然后再通过ID获取具体的数据,然后根据数据中的date排序,这时候就回表扫描了。

- Using filesort mysql: 会对结果使用一个外部索引排序,而不是按索引次序从表里读取行。
EXPLAIN SELECT id FROM weather WHERE cityname = '2020-3-2' order by wind_speed同样查询的字段包括返回字段都使用到了索引,正常应该是Using index的,但是又通过了一个非索引字段进行排序,所以先查询到数据然后再进行的排序。filesort有两种排序算法:双路算法(第一次读取排序字段进行排序,第二次读取其他字段),当查询的数据大于max_length_for_sort_data使用双路排序;单路算法(读取所有内容在内存中进行排序后返回结果)。如果数据量较大的情况下超出sort_buffer会进行多次磁盘读取产生IO交互。

三、注意
慢查询分析
所以平常在写SQL语句的时候最好提前先执行EXPLAIN,尽量使用性能比价好的SQL写法。对于上线项目还有一种方法,在测试的时候开启Mysql中的慢查询语句,测试结束后查看慢查询中的日志信息,对于其中需要优化的SQL语句统一EXPLAIN进行调试修改。开启慢查询的方法:
SET global slow_query_log = ON;
SET global slow_query_log_file = ‘slow.log’;
SET global log_queries_not_using_indexes = ON;
SET long_query_time = 1; //这里的单位是秒
分页查询分析
还是使用天气表,里面存放了大约不到300W条数据,我们来看一下使用分页查询的效率。
select * from weather limit 10000,10; 结果为0.032秒select * from weather limit 10000,100; 结果为0.034秒select * from weather limit 10000,1000; 结果为0.080秒可以看出来查询的效率与后面查询的记录数有关,记录数越多查询的效率越慢。
select * from weather limit 1,10; 结果为0.024秒select * from weather limit 10000,10; 结果为0.032秒select * from weather limit 1000000,10; 结果为0.846秒这个执行结果可以看出来查询的效率与起始的位置有关,起始位置越靠后查询越慢。
第一种分析结果其实影响不算太大,因为正常业务上面的分页基本不会超过100条数据,看到10条和100条的差距不大,主要对于第二种情况,百万数据分页的时候后面的数据查询效率明细很慢了,超过100W条数据之后都要秒级别查询了。
对于第二种情况进行EXPLAIN查看一下,进行了全表扫描,那我们可不可以在查询语句上面使用到索引呢?我们知道一般表都会有主键索引,那我们可不可以先找到第100W条数据的主键,然后开始往后数呢?
select * from weather where id > (select id from weather limit 1000000,1) LIMIT 10; 结果为0.156秒看这个SQL语句,从第100W条数据的主键往后数,当然要使用这种SQL分页那么就必须从一开始就使用这种语句,如果前面使用正常分页后面使用这种明显查询结果会错乱。
同样对前面的数据进行查询,看是否影响前面的查询效率:
select * from weather where id > (select id from weather limit 1,1) LIMIT 10; 结果为0.024秒select * from weather where id > (select id from weather limit 10000,1) LIMIT 10; 结果为0.026秒可以看到对前面的分页也会稍微提高查询效率。
有时候全表扫描比索引快
咱看下面一种情况,cityname存在了索引,但是为什么最后type还是使用了全表扫描呢?因为Mysql中执行优化器的时候认为全表扫描比用索引查询快。
EXPLAIN SELECT * FROM weather WHERE cityname > '济南'
怎么看出来全表扫描比优化快呢?咱通过一个参数设置来观察一下,先执行一下这行SQL
SET optimizer_trace='enabled=on',end_markers_in_json=on;在同时执行下面两行SQL
EXPLAIN SELECT * FROM weather WHERE cityname > '济南';SELECT * FROM information_schema.OPTIMIZER_TRACE;可以看到第二个执行的结果里面有个TRACE,这里面记录了这个SQL执行的过程。

将这个JSON拷贝出来,并且格式化,具体怎么分析这个JSON就不说了可以看到下面位置执行优化器的时候的分析情况:

看这个图,这里记录了假设使用全表扫描的时候要扫描270W行数据,花费时间为290552。
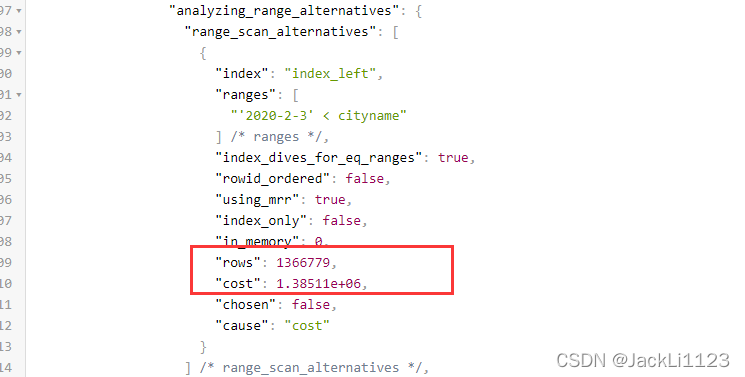
再看这幅图,这里是生产的另一个执行计划,这是使用索引查询的情况,虽然扫描的行数比较少,但是最终的执行时间是1385110>290552,所以就会认为全表扫描比使用索引查询快,最终走了全表扫描。

