深度解剖数据在内存中存储(1)
文章目录
前言
一、数据类型介绍
>>1.1 类型的基本归类
二、整形在内存中的存储
>>2.1 原码、反码、补码
>>2.2 大小端介绍
总结
前言
大家好,我是耶鲁。本篇深度解剖了数据在内存中的储存等知识介绍我会尽可能的使文章看起来图文并茂,且生动形象地为大家逐一讲解。废话不多说,满满的干货,快来签收吧!!(*^▽^*)

一、 数据类型介绍
我们熟知的C语言常见且基本的内置类型:
|
32位机器(X86) / (byte) |
64位机(X64) / (byte) |
||
|
char |
1 |
1 |
字符数据类型 |
|
short int |
2 |
2 |
短整型 |
|
int |
4 |
4 |
整形 |
|
long int |
4 |
8 |
长整型 |
|
long long int |
8 |
8 |
更长的整形 |
|
float |
4 |
4 |
单精度浮点数 |
|
double |
8 |
8 |
双精度浮点数 |
注:C语言规定:sizeof(long) >= sizeof(int)
布尔类型_Bool。专门用来表示真or假的这样一种变量,c99中引入了布尔类型。头文件,早期我们用1表示真,0表示假。本质上它就是对C语言中的int类型进行了重命名而已。但是目前应用的不太广泛。
关于bool类型的示例代码:


1.1 类型的基本归类
整型家族:
char
unsigned char
signed char
short
unsigned short [int]
signed short [int]
int
unsigned int
signed int
long
unsigned long [int]
signed long [int]
1.有人可能会疑惑,为什么char也归类到整形里面?这是是因为:每一个字符变量里面存的是字符,而字符的ASCII码值其实是这个字符对应的一个数字,ASCII码值是整数,所以我们通常把字符归类到整形家族。
2.注:char != signed char
解释:char到底是signed char还是unsigned char是取决于编译器的实现。常见的编译器下:char就是signed char。
3.整型是有符号位的,分为有符号数和无符号数。有符号数既可存正数也可存负数。
示例代码:

本质上来讲无符号数不能用%d打印,应该用%u来打印

为什么会用无符号打印有符号数会变成这么大的数字 ,这里留个坑,后面会填!![]()
浮点数家族:
- float
- double
float精度较低一些,double精度较高。
构造类型(自定义类型):
> 数组类型
> 结构体类型 struct
> 枚举类型 enum
> 联合类型 union
又有人可能不太理解,为什么数组类型是自定义类型。举个例子:int a[10]去掉数组名int [10]就是这个数组的类型,这个数组如果我们写成另外一种形式int a[5],同样的去掉数组名,int [5]就是这个数组的类型。这两个数组的类型是完全不同的,只要我的数组元素个数发生变化,或者元素类型发生变化,这两个数组的类型就彻底不一样了,既然我们稍作改动它的类型就发生变化,就说明数组是自定义类型。后面几个类型以后再讲。
指针类型:
- int* pi;
- char* pc;
- float* pf;
- void* pv;
注:void* 是无具体类型的指针。
空类型:
void 表示空类型(无类型)。
通常应用于函数的返回类型、函数的参数、指针类型。
二、整形在内存中的存储
我们知道一个变量的创建是要在内存中开辟空间的。空间的大小是根据不同的类型而决定的那接下来我们谈谈数据在所开辟内存中到底是如何存储的?
比如:
int a = 20;
int b = -10;
我们知道为 a 分配四个字节的空间。那么它是如何存储?下来我们一起了解下面的概念。
2.1 原码、反码、补码
计算机中的整数有三种表示方法,即原码、反码和补码。而内存中存储的是二进制的补码。三种表示方法均有符号位和数值位两部分,符号位都是用0表示“正”,用1表示“负”,而数值位负整数的三种表示方法各不相同。
原码:直接将二进制按照正负数的形式翻译成二进制就可以。
反码:原码的符号位不变,其他位依次按位取反就可以得到了。
补码:反码的二进制序列+1就得到补码。
注:正数的原、反、补码都相同。
对于整形来说:数据存放内存中其实存放的是补码。为什么呢?
在计算机系统中,数值一律用补码来表示和存储。原因在于:使用补码,可以将符号位和数值域统
一处理;同时,加法和减法也可以统一处理(CPU中只有加法器)。
例如:我们让计算机计算1+(-1),下图就是计算机的大致运算处理过程。

除此之外,还有一个原因就是:补码与原码相互转换,其运算过程是相同的,不需要额外的硬件电路。
解释:负数的补码是由它的原码取反加一得到的,所以负数的补码减一取反即可得到原码。但是当你把负数的补码取反加一也可以得到原码!!!看下图:

内存中我们看到的地址是用16进制表示的, 二进制转换成16进制,4个二进制位可以转换成16进制位。
我们看下图几个实例:

通过调试出内存窗口可以看到它在内存中地址的具体存放顺序:



我们可以看到对于a和b分别存储的是补码。但是我们发现顺序有点不对劲。那为什么内存中它要倒着存放呢?内存中存储的补码不是直接就放进去了,而是有一定的顺序,这就是我们马上要讲到的大小端的问题。
2.2 大小端介绍
什么是大端小端:
大端(存储)模式,是指数据的低位保存在内存的高地址中,而数据的高位,保存在内存的低地址中;
小端(存储)模式,是指数据的低位保存在内存的低地址中,而数据的高位,,保存在内存的高地址中。
如果还不太明白,请看下图:


为什么有大端和小端:
为什么会有大小端模式之分呢?这是因为在计算机系统中,我们是以字节为单位的,每个地址单元都对应着一个字节,一个字节为8bit。但是在C语言中除了8bit的char之外,还有16bit的short型,32bit 的long型(要看具体的编译器)。另外,对于位数大于8位的处理器,例如16位或者32位的处理器,由于寄存器宽度大于一个字节,那么必然存在着一个如何将多个字节安排的问题。因此就导致了大端存储模式和小端存储模式。
例如:一个 16bit 的 short 型 x ,在内存中的地址为 0x0010 , x 的值为 0x1122 ,那么 0x11 为高字节, 0x22 为低字节。对于大端模式,就将 0x11 放在低地址中,即 0x0010 中,0x22 放在高地址中,即 0x0011 中。小端模式,刚好相反。我们常用的 X86 结构是小端模式,而 KEIL C51 则为大端模式。很多的ARM,DSP都为小端模式。有些ARM处理器还可以由硬件来选择是大端模式还是小端模式。
即学即练,百度2015年系统工程师笔试题:
请简述大端字节序和小端字节序的概念,设计一个小程序来判断当前机器的字节序。(10分)
答:简述:
大端字节序存储:当一个数据的低字节的数据存放在高地址处,高字节序的内容放在了低地址处,这种存储方式就是大端字节序存储。
小端字节序存储:当一个数据的低字节序的数据存放在低地址处,高字节序存的内容放在高地址处,这种存储方式就是小端字节序存储
程序实现分析:

char* p = (char*)&a;
使p是一个char*类型的指针,这样解引用时才会访问一个字节。但是&a是int*类型,所以得把&a进行强制类型转换为char*类型,虽然类型转换了但是里面的值没有变。*p其实访问的是a的第一个字节,如果*p等于1的话,我们就知道它是小端存储,反之则是大端存储。

char ch = (char)a;
这样写是行不通的。a是一个整型,不管是大端存储还是小端存储,它总是把a的四个字节里面的最低字节的内容截断来赋给ch!
我们最好可以用一个函数把判断大小端的程序进行封装。
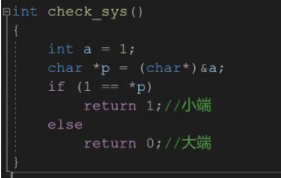
上面这种写法较复杂,对代码进行简化,直接返回*p。
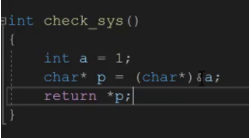
直接返回*p也是可以的,但是还可以进一步简化代码!p等于被强制类型转换成char*后的&a,再返回*p,那还不如直接返回(char*)&a再将其解引用即可!
示例代码:
#include int check_sys(){int a = 1;return (*(char*)&a);}int main(){int ret = check_sys();if (ret == 1){printf("小端\n");}else{printf("大端\n");}return 0;}
总结
本篇我们学习了:数据类型详细介绍、整形在内存中的存储:原码、反码、补码、大小端字节序介绍及判断等知识。为了避免文章冗余,我决定将此篇分为两篇文章来进行讲解。下一篇我会将余下内容一一呈现,敬请期待!!!谢谢大家支持。
名言警句:知人者智,自知者明。胜人者有力,自胜者强。


