HashMap树化的条件和扩容机制令人疑惑,语焉不详,正好好久没写了,补上一篇
从我学习Java的时候,学到HashMap,我记过的答案是HashMap在Jdk1.8的时候底层实现改为数组+链表+红黑树,当链表长度为8时转为红黑树,红黑树长度减少到6时又转为链表,这样的话在csdn中能找到很多,但他们都没有说清楚。
原因是我最近看到有些文章说数组容量达到64才会触发树化,这就和我固有的认识(错误的)产生了冲突,然后我就开始未知探索之路
以下是我的结论(查看大佬的解析+b站视频双管齐下)
HashMap链表转红黑树的条件:容量大于等于64且链表长度为8才会进行树化,否则只会进行扩容
HashMap数组的扩容机制:键值对个数(size)超过(如果容量是16(默认值),负载因子是0.75(默认值)的话,阈值就是12,要第13个才会扩容)阈值(依次类推,容量32时阈值为24)触发扩容,还有就是当一条链表长度达到8且数组容量小于64也会进行扩容
1.HashMap的put()方法,put()方法里是调用putVal()方法
HashMap<Integer, String> map = new HashMap<>(); //第一次HashMap在第一次调用put()时才会初始化 map.put(1, "小明"); /* //HashMap的属性,table数组,每个索引位置称为桶 transient Node[] table; ----------------------------------以下是put()方法的代码实现(为了便于查看我把所有注释加了个制表符) //hash:新键值对的hash值,key是键(就是加入的1),value是值(就是小明) final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) { //tab数组:临时的HashMap底层存储数组, //p节点:就是用来存放头节点的 //n是tab.length就是桶的数量 //i是索引位置(也就是桶,桶:我的理解就是还数组索引位置及hash冲突之后的链表) Node[] tab; Node p; int n, i; //对hashMap进行判空(HashMap底层存储数组,是HashMap类的属性) //!!##我有个大大的疑问,第二次put()时,tab不为空不会进入这个if,那n(数组长度)不就是未初始化的状态吗 //!!##这个疑惑已解决(我放在最下面的代码段) if ((tab = table) == null || (n = tab.length) == 0) //如果为空则调用resize(),初始化 n = (tab = resize()).length; //i = (n - 1) & hash "n-1"是数组长度-1,然后和hash(hash值)相与,得到传入节点的桶位置 //x mod 2^n = x & (2^n - 1) 这是 HashMap 在速度上的优化,因为 & 比 % 具有更高的效率。 //i就是table数组(hashMap底层的那个数组)的索引,桶的位置 //对桶位置的判空(是否有头节点) if ((p = tab[i = (n - 1) & hash]) == null) //无头节点则直接把新节点存在桶位置 tab[i] = newNode(hash, key, value, null); else {//有头节点 //泛型类型的变量k是头节点的key Node e; K k; //再解释一个p是头节点 //当新加入的节点的hash值和key对象的地址相同(即同一对象) //或者 两个key的值相等时(地址不同比较对象,这就是作为Key的类要重写hashcode方法和equals方法) //其实就是做替换value的操作(在下一个的if中操作的) if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k)))) e = p;//相等就把头节点的地址(是地址)赋值给临时节点变量e,并进入下一个if #if (e != null) {}# else if (p instanceof TreeNode)//是否是红黑树的实例 //把Node类型的p强转为TreeNode(红黑树类型),然后调用红黑树的putTreeVal()方法 e = ((TreeNode)p).putTreeVal(this, tab, hash, key, value); else {//只是单纯的链表 for (int binCount = 0; ; ++binCount) {//死循环,写源码的人特别喜欢用for(;;)来写死循环 //##能理解要遍历链表但不明白每次循环调用next节点是如何操作的 if ((e = p.next) == null) { //加到最后一个节点后面 p.next = newNode(hash, key, value, null); //加入节点后要判断链表长度是否为8,如果是则调用树化方法(但不一定会树化) //binCount从0开始自增 //当binCount >=7时 if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st//树化!!!(但不是马上树化,)treeifyBin(tab, hash);//##下个代码段我把treeifyBin()方法中有利于本文理解的代码贴出来//会进行这么一个判断,MIN_TREEIFY_CAPACITY:最小树化容量为64//if (tab == null || (n = tab.length) threshold) resize(); afterNodeInsertion(evict); return null; }*/2.HashMap的树化代码
final void treeifyBin(Node<K,V>[] tab, int hash) { int n, index; Node<K,V> e; //看这,某条链表长度为8时进入这个方法, //tab肯定不为null,当tab长度小于MIN_TREEIFY_CAPACITY时 //#我对MIN_TREEIFY_CAPACITY的理解(最小树化容量值为64,capacity是容量的意思(在HashMap中 //同样用到这个单词的只有table数组的容量,默认为16), //我看有些博客说什么链表长度为8时和64个节点就树化应该是错误的理解)# if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY) //所以只有数组容量大于等于64时,链表长度到8时才会树化,把链表转红黑树,其他情况都是扩容 resize(); //下面的代码以后再看了😂 else if ((e = tab[index = (n - 1) & hash]) != null) { TreeNode<K,V> hd = null, tl = null; do { TreeNode<K,V> p = replacementTreeNode(e, null); if (tl == null) hd = p; else { p.prev = tl; tl.next = p; } tl = p; } while ((e = e.next) != null); if ((tab[index] = hd) != null) hd.treeify(tab); } }3.HaspMap的扩容机制
在IDEA中使用debug调试可以很清晰看到HashMap的扩容机制(有些人可能只能看到普通数组而看不到HashMap中的数组,我之前也是,那是因为IEDA中对集合的数据视图进行了设置)
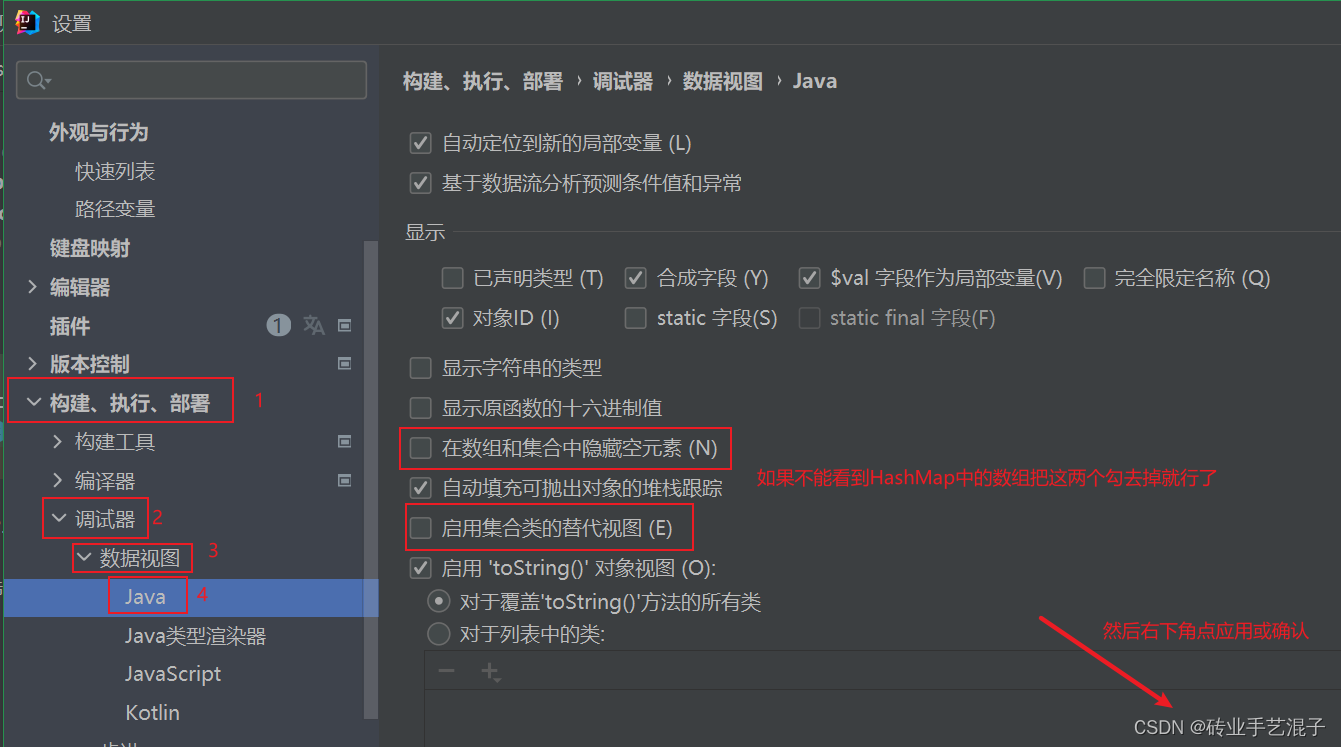
写一个简单的例子,然后debug
HashMap<String, Integer> map = new HashMap<>(); for (int i = 0; i < 13; i++) { map.put("小明"+i, i); }debug截图
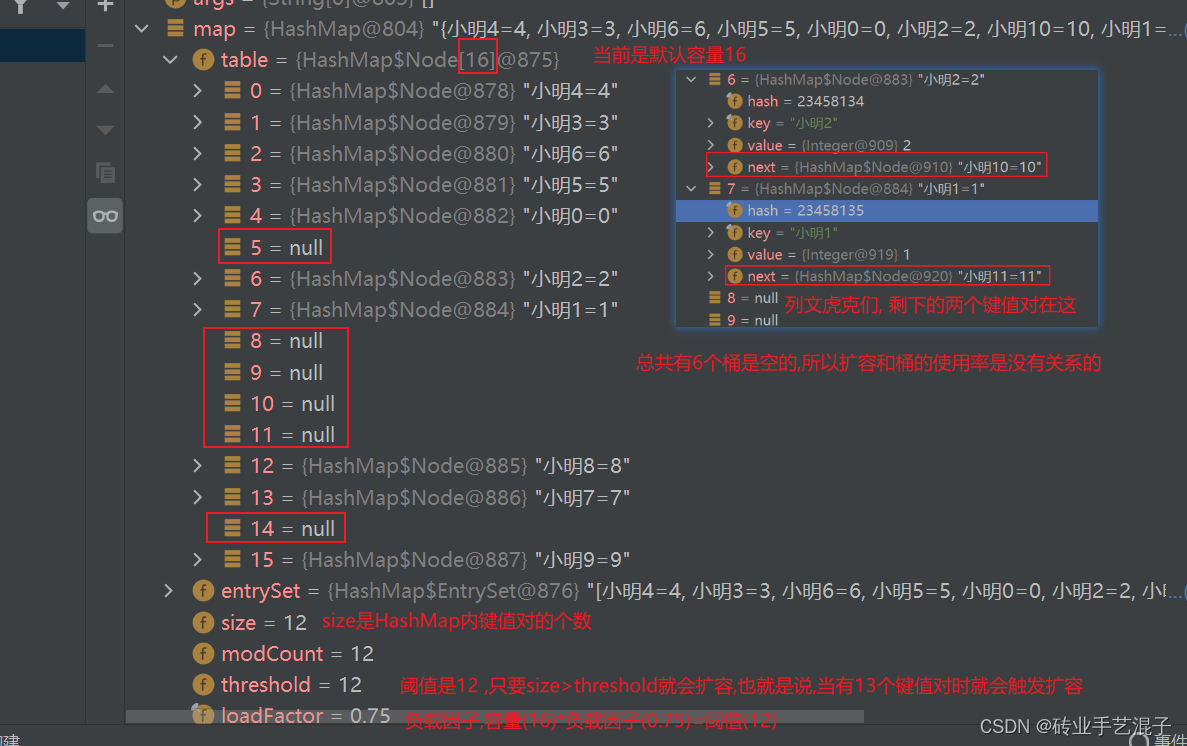
当键值对个数也就是map.size()==13时触发扩容
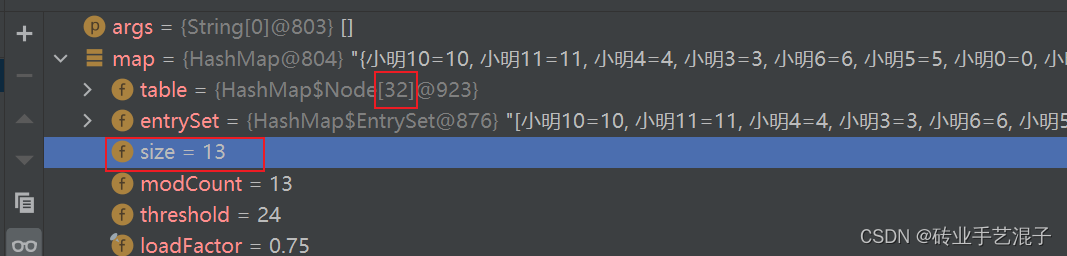
4.第二次put()时n的值
如果对HashMap第二次put()方法没疑惑别浪费时间,路过
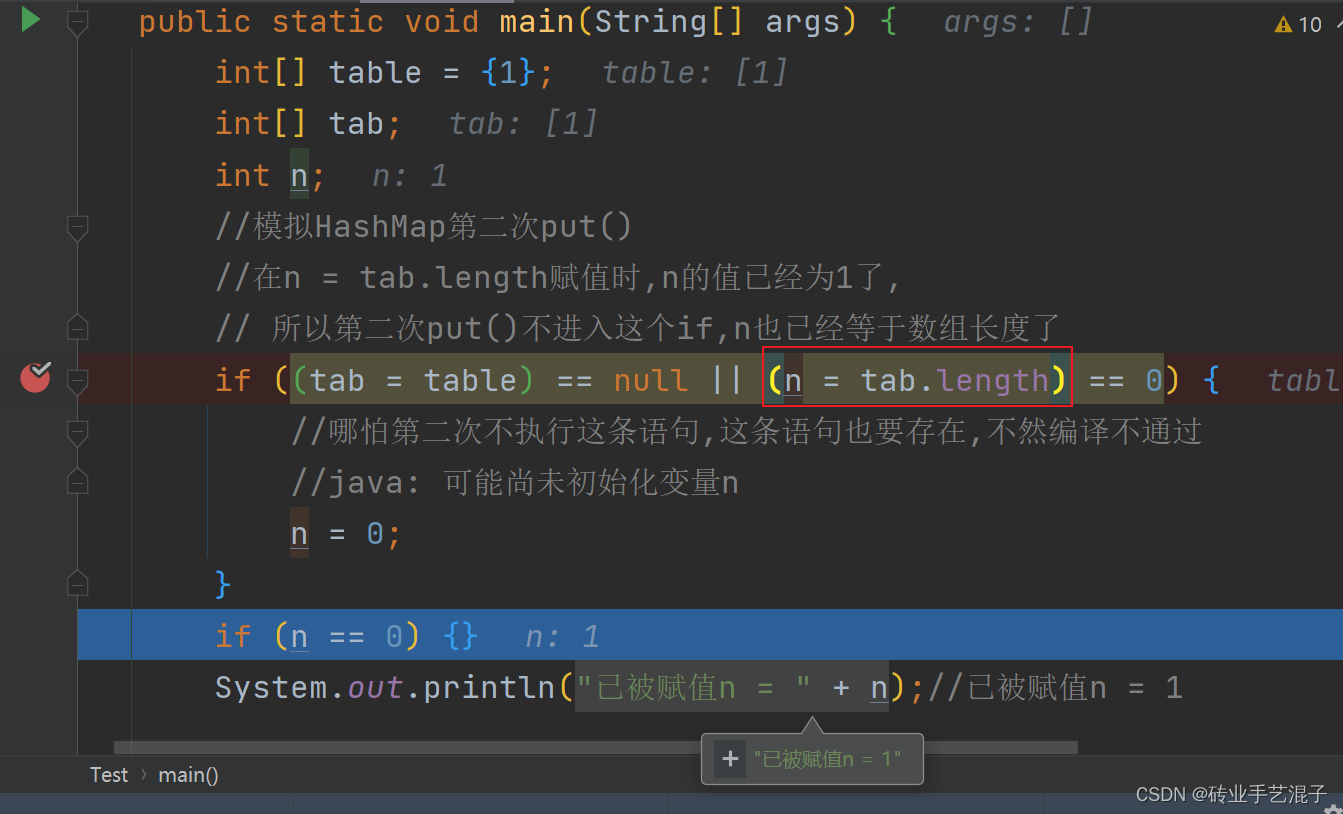
模拟第二次put方法时,n在何时赋值?
public static void main(String[] args) { int[] table = {1}; int[] tab; int n; //模拟HashMap第二次put() //首先,进入if的条件判断,tab显然不为空为false,然后在n = tab.length赋值时,n的值已经为1了,不管能不能进{}代码块,n已被赋值 // 所以第二次put()不进入这个if,n也已经等于数组长度了 if ((tab = table) == null || (n = tab.length) == 0) { //哪怕第二次不执行这条语句,这条语句也要存在,不然编译不通过 //java: 可能尚未初始化变量n n = 0; } if (n == 0) {} System.out.println("已被赋值n = " + n);//已被赋值n = 1 }5.最后
小记:
HashMap转红黑树:容量大于等于64且链表长度为8才会进行树化,否则只会进行扩容
HashMap的扩容机制:键值对个数(size)超过(如果容量是16,负载因子是0.75的话,阈值就是12,要第13个才会扩容)阈值触发扩容,还有就是当一条链表长度达到8且数组容量小于64也会进行扩容
最近感悟,HashMap在网上的解析非常多但是参差不齐,好多自己都没debug过,所以遇到不懂的还是得信源码和debug,一定要结合源码,一定要有自己的思考
参考这两个大佬的,看了韩顺平的b站视频才终于懂了debug,开心!!!
参考了[程序员囧辉]史上最详细的 JDK 1.8 HashMap 源码解析
【韩顺平讲Java】Java集合专题

