Elasticsearch 相关软件安装
Elasticsearch 相关软件安装
Elasticsearch官方下载地址:Download Elasticsearch Free | Get Started Now | Elastic | Elastic
1、Windows 安装 Elasticsearch

1.1、JDK环境
至少1.8.0_73以上版本,验证:java -version
PS C:\Users\lenovo> java -versionjava version "11.0.12" 2021-07-20 LTSJava(TM) SE Runtime Environment 18.9 (build 11.0.12+8-LTS-237)Java HotSpot(TM) 64-Bit Server VM 18.9 (build 11.0.12+8-LTS-237, mixed mode)1.2、下载和解压缩Elasticsearch安装包,查看目录结构。
- bin:脚本目录,包括(启动、停止等可执行脚本)
- config:置文件目录
- data:索引目录,存放索引文件的地方
- logs:日志目录
- modules:模块目录,包括了es的功能模块
- plugins:插件目录,es支持插件机制

1.3、配置文件
位置:ES的配置文件的地址根据安装形式的不同而不同
- 使用zip、tar安装﹐配置文件的地址在安装目录的config下
- 使用RPM安装,配置文件在/etc/elasticsearch下
- 使用MSI安装,配置文件的地址在安装目录的config下,并且会自动将config目录地址写入环境变量ES_PATH_CONF。
1.3.1、elasticsearch.yml
配置格式是YAML,可以采用如下两种方式:
-
方式1:层次方式
path: data: /var/lib/elasticsearch logs: /var/log/elasticsearch -
方式2:属性方式
path.data: /var/lib/elasticsearchpath.logs: /var/log/elasticsearch
elasticsearch.yml常用的配置项如下
cluster.name: 配置elasticsearch的集群名称,默认是elasticsearch。建议修改成一个有意义的名称。node.name:节点名,通常一台物理服务器就是一个节点,es会默认随机指定一个名字,建议指定一个有意义的名称,方便管理一个或多个节点组成一个cluster集群,集群是一个逻辑的概念,节点是物理概念,后边章节会详细介绍。path.conf: 设置配置文件的存储路径,tar或zip包安装默认在es根目录下的config文件夹,rpm安装默认在/etc/ elasticsearchpath.data:设置索引数据的存储路径,默认是es根目录下的data文件夹,可以设置多个存储路径,用逗号隔开。path.logs:设置日志文件的存储路径,默认是es根目录下的logs文件夹path.plugins: 设置插件的存放路径,默认是es根目录下的plugins文件夹bootstrap.memory_lock: true设置为true可以锁住ES使用的内存,避免内存与swap分区交换数据。network.host: 设置绑定主机的ip地址,设置为0.0.0.0表示绑定任何ip,允许外网访问,生产环境建议设置为具体的ip。http.port: 9200设置对外服务的http端口,默认为9200。transport.tcp.port: 9300 集群结点之间通信端口node.master: 指定该节点是否有资格被选举成为master结点,默认是true,如果原来的master宕机会重新选举新的master。node.data: 指定该节点是否存储索引数据,默认为true。discovery.zen.ping.unicast.hosts: ["host1:port", "host2:port", "..."]设置集群中master节点的初始列表。discovery.zen.ping.timeout: 3s设置ES自动发现节点连接超时的时间,默认为3秒,如果网络延迟高可设置大些。discovery.zen.minimum_master_nodes:主结点数量的最少值 ,此值的公式为:(master_eligible_nodes / 2) + 1 ,比如:有3个符合要求的主结点,那么这里要设置为2。node.max_local_storage_nodes: 单机允许的最大存储结点数,通常单机启动一个结点建议设置为1,开发环境如果单机启动多个节点可设置大于1。1.3.2、jvm.options
设置最小及最大的JVM堆内存大小
在 jvm.options 中设置 -Xms和-Xmx
- -Xms:启动时占用内存 -Xmx:运行时占用内存
- 两个值设置为相等
- -Xmx 设置为不超过物理内存的一半。
1.3.3、log4j2.properties
日志文件设置,ES使用log4j,注意日志级别的配置。
4.1.2、启动 Elasticsearch
启动Elasticsearch:bin\elasticsearch.bat,es的特点就是开箱即,无需配置,启动即可。
注意:es7 windows版本不支持机器学习,所以 elasticsearch.yml 中添加如下几个参数:
node.name: node-1 cluster.initial_master_nodes: ["node-1"] xpack.ml.enabled: false http.cors.enabled: truehttp.cors.allow-origin: /.*/检查ES是否启动成功:浏览器访问http://localhost:9200

{ "name": "node-1", "cluster_name": "elasticsearch", "cluster_uuid": "HqAKQ_0tQOOm8b6qU-2Qug", "version": { "number": "7.3.0", "build_flavor": "default", "build_type": "zip", "build_hash": "de777fa", "build_date": "2019-07-24T18:30:11.767338Z", "build_snapshot": false, "lucene_version": "8.1.0", "minimum_wire_compatibility_version": "6.8.0", "minimum_index_compatibility_version": "6.0.0-beta1" }, "tagline": "You Know, for Search"}解释:
name: node名称,取自机器的hostname
cluster_name: 集群名称(默认的集群名称就是elasticsearch)
version.number: 7.3.0,es版本号
version.lucene_version:封装的lucene版本号
浏览器访问 http://localhost:9200/_cluster/health 查询集群状态

{ "cluster_name":"elasticsearch", "status":"green", "timed_out":false, "number_of_nodes":1, "number_of_data_nodes":1, "active_primary_shards":1, "active_shards":1, "relocating_shards":0, "initializing_shards":0, "unassigned_shards":0, "delayed_unassigned_shards":0, "number_of_pending_tasks":0, "number_of_in_flight_fetch":0, "task_max_waiting_in_queue_millis":0, "active_shards_percent_as_number":100.0}4.2、Windows 安装 Kibana
Kibana 官网下载地址:Download Kibana Free | Get Started Now | Elastic | Elastic
-
kibana是es数据的前端展现,数据分析时,可以方便地看到数据。作为开发人员,可以方便访问es
-
下载,解压 kibana。
-
启动Kibana:bin\kibana.bat
-
浏览器访问 http://localhost:5601 进入Dev Tools界面。像 plsql 一样支持代码提示。


- 发送get请求,查看集群状态GET _cluster/health。相当于浏览器访问 http://localhost:9200/_cluster/health。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-PBj5BZ5r-1649472521737)(D:\Typora\Typora\Typora\typora-user-images\image-20211019031856646.png)]
添加配置在 config\kibana.yml
i18n.locale: "zh-CN"
首页 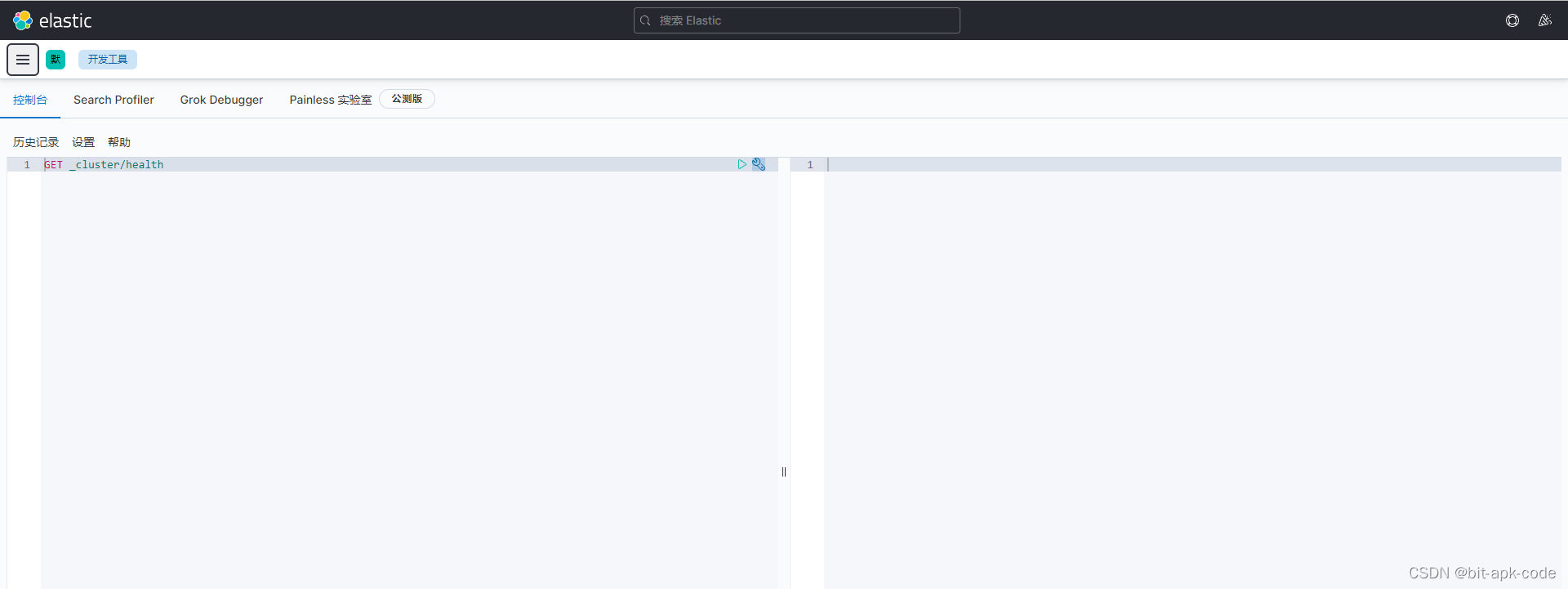 Dev Tools界面
5、Elasticsearch 快速入门
5.1、文档(document)的数据格式
- 应用系统的数据结构都是面向对象的,具有复杂的数据结构
- 对象存储到数据库,需要将关联的复杂对象属性插到另一张表,查询时再拼接起来
- elasticsearch 面向文档,文档中存储的数据结构,与对象一致。所以一个对象可以直接存成一个文档
- elasticsearch 的 document 用 json 数据格式来表达。
例如:班级和学生关系
public class Student { private String id; private String name; private String classInfoId; }private class ClassInfo { private String id; private String className; ...... }数据库中要设计所谓的一对多,多对一的两张表,外键等。查询出来时,还要关联,mybatis写映射文件,很繁琐。
而在 elasticsearch 中,一个学生存成文档如下:
{ "id":"1", "name": "张三", "last_name": "zhang", "classInfo": { "id": "1", "className": "三年二班", }}
