B,B+,B*,2-3树的介绍与图的创建
多叉树的介绍与图的创建
多叉树:从为什么,是什么,有什么用展开阐述,并有配图讲解
图:从图的定义以及相关方法的建立与分析展开,并由配图讲解
若有不足之处,欢迎指出
博主空间
https://blog.csdn.net/JOElib?spm=1010.2135.3001.5343广度优先算法
目录
多叉树🐼
为什么要有多叉树?🐻
多叉树的定义🐻
相关术语🐻
2-3树🐨
特点🦁
图例(创建过程)🦁
B-tree(B树)🐨
搜索原理🦁
特征🦁
搜索图解(思路,并非准确B-tree)🦁
B+树🐨
搜索原理🦁
特征🦁
图例🦁
B*树🐨
特征🦁
图例 🦁
图🐼
为什么要有图这种数据结构?🐻
图的定义🐻
相关概念🐻
图的表示方式🐻
图示🦁
图的创建🐼
结论🐼
多叉树🐼
为什么要有多叉树?🐻
- 如果我们在数据库或者从外存中存取数据,当我们采用二叉树这种数据结构时,面对海量的数据,我们默认会读取一个"页"的数据,由于一个节点的数据项有限,就会造成海量的IO操作,从而使程序效率变低
- 因为子节点数量最大为二,若海量节点被创建,会导致树的层数大大增加,树高过大,操作效率大大降低
多叉树的定义🐻
- 一个节点可以有更多的数项和更多的子节点,我们称这种节点构造成为的树为多叉树
相关术语🐻
- 页:一个节点中所有的数项
- 数项:一个节点中的一类数据
- 度(N):一个节点的子节点数
- 阶:一个节点的最大节点数
2-3树🐨
特点🦁
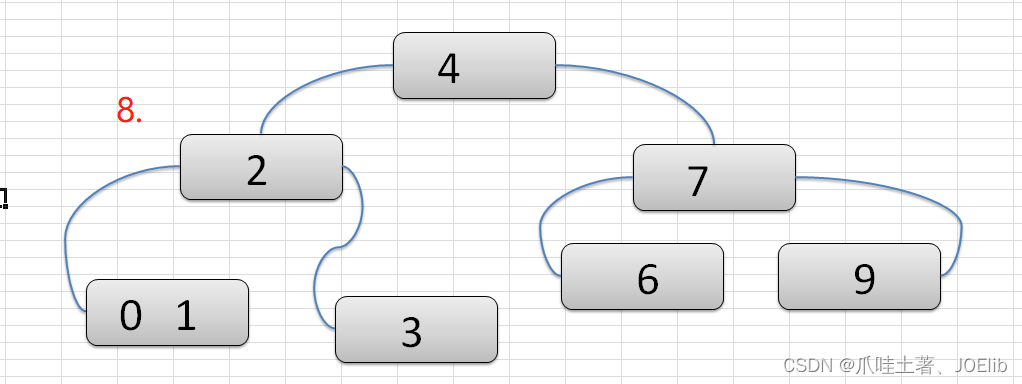
- 2-3树只由二节点和三节点组成
- 所有的叶子节点都在同一层上(只要是B树类的都满足)
- 二节点:
- 只有两个子节点的节点被称为二节点,二节点要么没有子节点,要么有两个子节点,不能出现其他情况
- 一般只有一个数项
- 三节点:
- 只有三个子节点的节点被称为三节点,三节点要么没有子节点,要么有三个子节点,不能出现其他情况
- 一般有两个数项
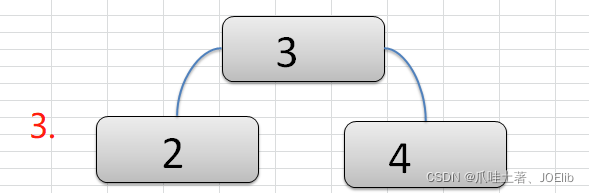
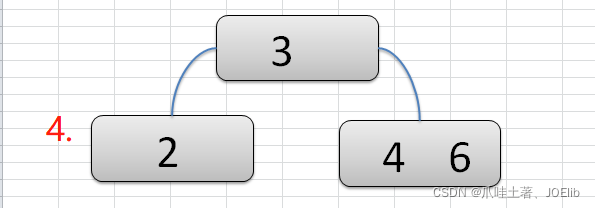
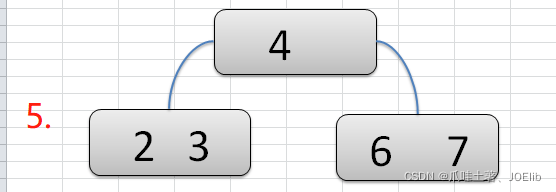
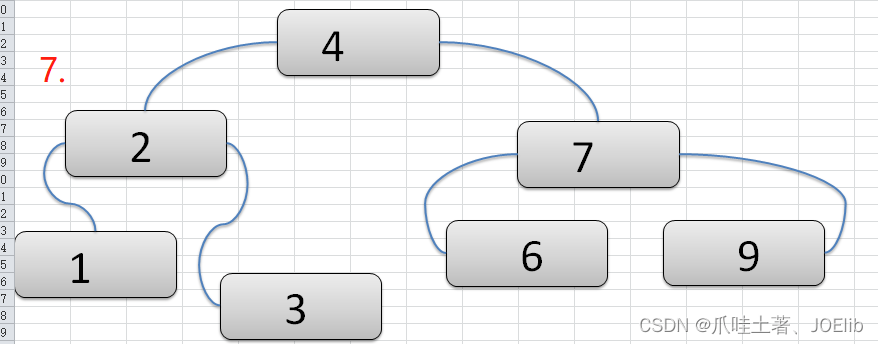
- 注意:在构建2-3树的时候,我们需要保证每一步完成后,该树仍然是一个2-3树
图例(创建过程)🦁




 B-tree(B树)🐨
B-tree(B树)🐨
搜索原理🦁
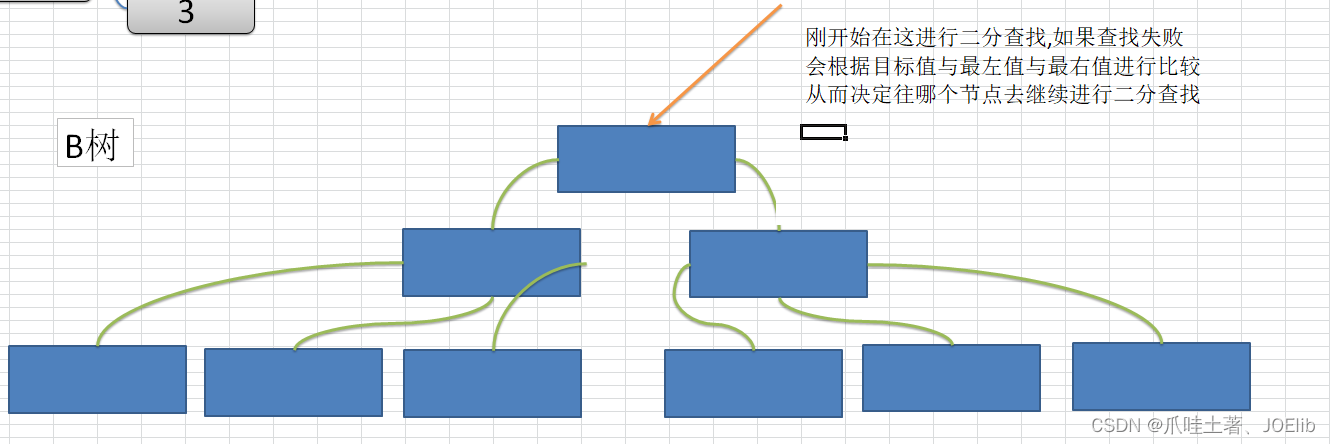
- 从根节点开始,对节点内的关键字进行一次二分查找,如果命中关键字,搜索结束,否则进入查询关键字所属范围的子节点,重复以上操作直至命中关键字
- 关键字不存在的情况:
- 带查找的节点为空,关键字不存在
- 若子节点查找不到,关键字不存在
特征🦁
- 关键字分布在整棵树中,即叶子节点和非叶子节点都可以存放关键字,即存放数据
- 所以,可能在叶子节点命中关键字,也可能在非叶子节点命中关键字
- 在B-tree内的二分查找等效于全集内的二分查找,效率高(多个节点的数据合成一个去查找)
搜索图解(思路,并非准确B-tree)🦁
 B+树🐨
B+树🐨
搜索原理🦁
- 搜索原理与B-tree(B树一致)
- 特别的是:B+树的关键字只能存储在叶子节点中,所以,只能在叶子节点中去命中关键字,在非叶子节点中不可能命中到关键字
特征🦁
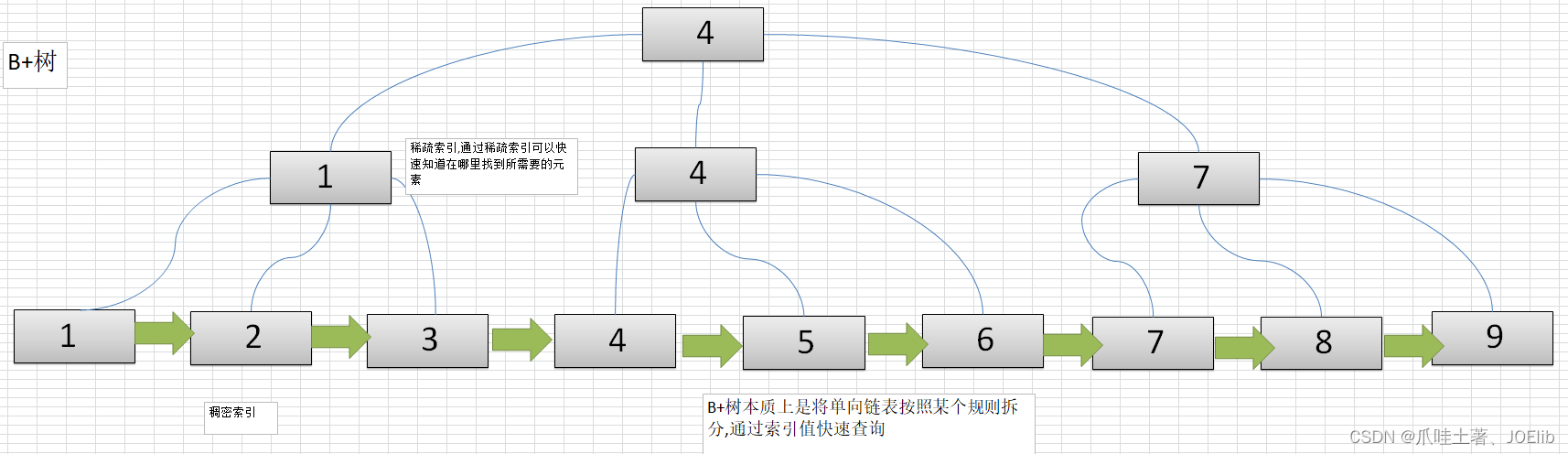
- 所有的关键字存储在叶子节点中(即数据只能存储在叶子节点中[稠密索引]),且链表中的关键字 是有序的
- 非叶子节点相当于叶子节点的索引[稀疏索引],叶子节点相当于存储关键字的数据层
- 适合用于文件索引系统
图例🦁

B*树🐨
特征🦁
- B*树是B+树的变体,在B+树的非叶子节点和非根节点再增加兄弟节点的引用
- B*树规定了非叶子节点的关键字至少为N*2/3,而B+树为N*1/2,可以看出B*树的最低利用率比 B+树的最低利用率高,所以B*树的新节点更少,空间利用率更高
图例 🦁

图🐼
为什么要有图这种数据结构?🐻
- 线性表如单向链表等,只有一个直接前驱节点和一个直接后继节点(一对一)
- 非线性表如树等,只有一个直接前驱节点(一对多)
- 以上两种数据结构都不可以满足多对多的关系,所以有了图这种数据结构
图的定义🐻
- 图是一种数据结构,其中一个节点可以有零个或者是多个相邻的节点(邻接节点)
相关概念🐻
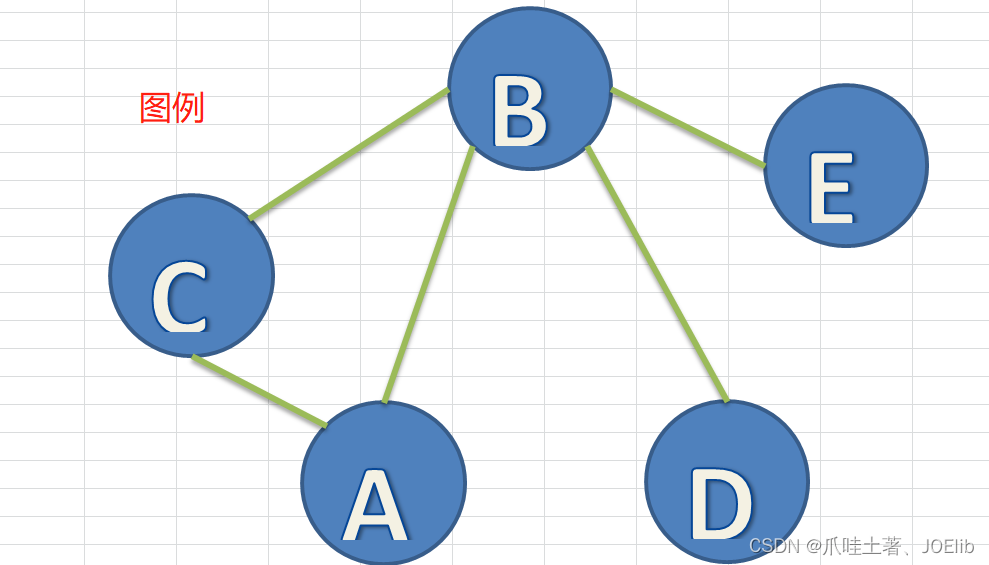
- 顶点:顶点与节点是等效的
- 边:节点和节点之间的连线
- 路径:从某个节点到另一个节点
- 无向图:边没有方向
- 有向图:边有方向
- 带权图: 边带权
图的表示方式🐻
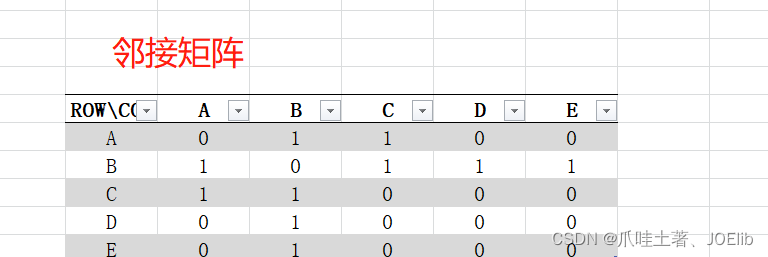
- 邻接矩阵(二维数组实现)
- 邻接矩阵中的ROW与COL分别表示0~n的节点,即0表示下表为0节点,1表示下标为1的节点
- 在邻接矩阵中,1表示两个节点中有边,0表示两个节点间没有边
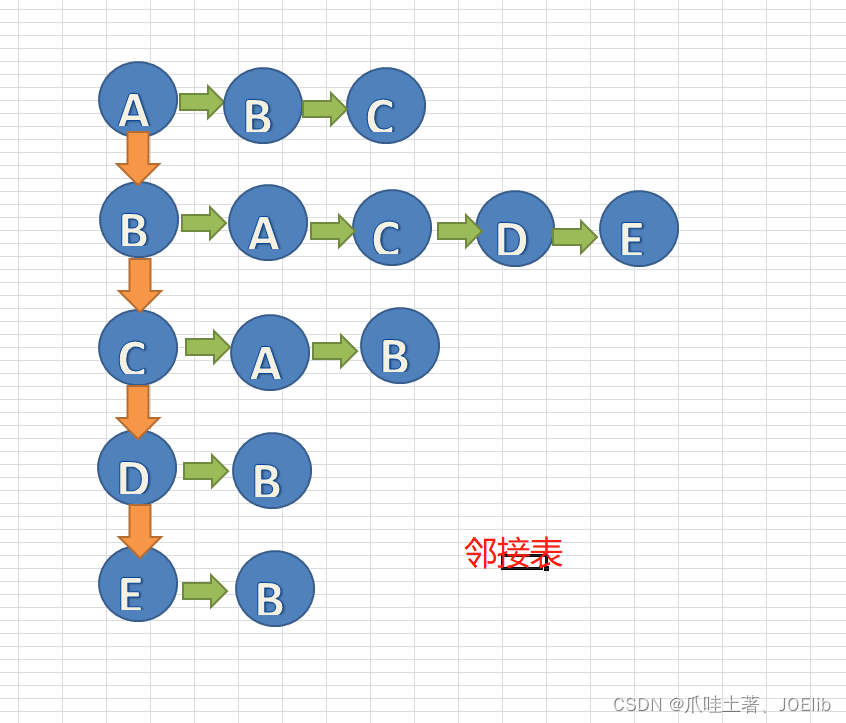
- 邻接表(数组+链表的形式实现)
- 邻接矩阵每增加一个元素,就会导致空间占用多出N,本质上很多空间被赋值为0,是冗余的,可能造成巨大的空间浪费
- 邻接表只关心有边的情况,不关心没有边的情况,因此,没有空间浪费的现象
图示🦁
图的创建🐼
public class Graph { /** * 表示邻接矩阵 */ public int[][] edges; /** * 表示用该集合存放顶点数据 */ public ArrayList vertexList; /** * 表示边的数目 */ public int numOfEdges; /** * 表示顶点是否被访问的状态的数组 */ boolean[] isVisited; /** * 表示顶点个数 */ private int num; /** * 初始化图以及邻接矩阵 * @param num 图的最大顶点个数 */ public Graph(int num) { this.num = num; edges = new int[num][num]; vertexList = new ArrayList(num); isVisited = new boolean[num]; } /** * 添加顶点的方法 * @param vertex 顶点的数据 */ public void addVertex(String vertex) { vertexList.add(vertex); } /** * 通过字符数组一键添加顶点,每一个字符串都是一个顶点 * @param str 字符串 */ public void addVertexByStrings(String[] str) { vertexList.addAll(Arrays.asList(str)); } /** * 为顶点加边 * @param v1 第一个顶点对应的下标 * @param v2 第二个顶点对应的下标 * @param value 两个顶点之间的权,若为1则表示为两个顶点加边 */ public void addEdge(int v1,int v2,int value) { edges[v1][v2] = value; edges[v2][v1] = value; numOfEdges++; } /** * 获取图中边的数目 * @return 边的数目 */ public int getNumOfEdges() { return numOfEdges; } /** * 获取顶点的数据 * @param index 被获取数据的顶点下标 * @return 返回的数据 */ public String getItem(int index) { return vertexList.get(index); } /** * 获取两个顶点之间的权 * @param v1 第一个顶点的下标 * @param v2 第二个顶点的下标 * @return 两个顶点之间的权,若为1,则为有边,0为无边 */ public int getEdgeBetV(int v1,int v2) { return edges[v1][v2]; } /** * 输出邻接矩阵的方法 */ public void showEdges() { for (var edges : this.edges) { System.out.println(Arrays.toString(edges)); } }}结论🐼
B,B+,B*,2-3树都是较为困难的数据结构,常常在笔试中也不做要求,如果大家想了解更加深入的话,可以和博主交流哦,我来总结以下几点:
1.图的创建
2.多叉树中各种树的特征和图的特征
🚇下一站:AVL树