MySQL索引-知识点总结
MySQL索引-知识点总结
-
- 1.什么是索引
- 2.索引的使用
- 3.索引底层的数据结构
·> MySQL 作为一个数据存储的工具,最基本的就是 MySQL 的基础使用,我们首先要会使用这个工具,会写 SQL 语句,懂得 MySQL 存储数据和 SQL 语句操作数据的机制。
·> 那么第二点,我们就要考虑如何让能够把 MySQL 用好,这就是我本文想要整理的关于 MySQL 索引的使用,索引是能够提高 MySQL 性能的,它能够让我们把 MySQL 用得更快,用的更好。索引也是面试中容易考察到的点。
·> 第三个,我们会用 MySQL 了,并且能把它用的更好了的前提下,怎么样能够让 MySQL 稳定的运行,这就是 MySQL 事务要解决的问题,后面我还会整理出一篇关于 MySQL 事务的总结。
1.什么是索引
-
当表的数据量比较大时,查询操作会比较耗时。建立索引是加快查询速度的有效手段。
-
数据库索引是一种特殊的文件,它包含的是数据表里所有记录的引用指针(理解为数据存放的一个地址,或者一个对象)。
-
类似于图书目录后面的索引,能够快速定位到需要查找的内容。用户可以根据应用环境的需要在基本表上建立一个或多个索引,以提供多种存取路径,加快查找速度。
本文讲的是基于 MySQL5.5 之后默认的数据库引擎 InnoDB
MyISAM与InnoDB 的区别: link.
2.索引的使用
-
为什么要使用索引
数据库中数据存储在磁盘,磁盘的顺序查询速度是很慢的,所有的顺序查找指的是读取磁盘中的数据⼀ 条⼀条的进⾏查找。
索引就是为了避免顺序查询,提供查询速度的。 -
索引的优势
实际的一个功能性数据库中,它所存放的数据信息是十分的多的,数据量很大,会占用更多的存储空间,而一般来说这些数据是被存储在磁盘中的,而不会是存储在内存里。但是索引不一样,它所存储的只是每一个数据信息对应的存储空间的地址,如果我们使用索引存放了地址,查询时将索引加载到内存中,查询数据时就可以快速的从内存里去扫描索引,找到数据信息存放的内存地址,就可以精准快速的拿到想要的数据了。 -
索引 VS 书的目录
从宏观上来讲,我们可以认为索引就是书的目录。
但从微观上来讲,索引不等于书的目录。因为一本书的目录只有一个,而一张表可以有多个索引,而每个索引都相当于一个目录。 -
索引分类
索引的分类有以下⼏种:
主键索引(聚簇索引):⼀种特殊的唯⼀索引,不允许有空值,⼀般是在建表的时候同时创建主键 索引(通过 primary key)。
非主键索引(⼆级索引/非聚簇索引):除主键索引之外的其他索引。
唯⼀索引:不能重复的索引。 普通索引:可以重复也可以为 NULL 的索引。
联合索引:使⽤多个字段联合组成的索引。
注意:创建主键约束(PRIMARY KEY)、唯⼀约束(UNIQUE)、外键约束(FOREIGN KEY)时, 会⾃动创建对应列的索引。
- 查看索引
show index from 表名;- .创建索引
假设,我们有⼀个主键列为 ID 的表,表中有字段 k,并且在 k 上有索引。这个表的建表语句是:
create table T( id int primary key, k int not null, name varchar(16), index (k) ) engine=InnoDB;- 创建普通索引
create index 索引名 on 表名(字段名[,字段名2...]);- 创建唯一索引
create unique index 索引名 on 表名(字段名); 1- 添加主键索引
alter table table_name add primary key (column);- 删除索引
drop index 索引名 on 表名;-
索引 VS 约束
① 创建索引的时候会自动创建约束,并且在创建约束的时候也会自动创建索引
② 索引和约束的不同是业务定义,约束是用来规范数据的正确性,而索引是用来提升数据库的程序性能的
③ 大多数情况可以理解为:索引和约束是共生关系(反例:非空约束) -
创建索引注意事项
① 在创建索引的时候会创建对应的约束,而删除索引的时候也会删除对应的约束
② 唯一索引在创建时,要确保原先的数据符合唯一约束,这样才能成功的创建唯一约束,否则会创建失败
- 注意事项
- 创建索引要考虑的因素
① 数据量是否足够大
② 创建索引的列是否经常使用到查询条件
原因:因为索引的产生是为了提高表的查询效率,索引的底层使用的是 B+ 树,在表的频繁添加和删除的时候,都是要对索引进行维护的,要重新整理树的结构。
-
不适合创建索引的场景
① 读比较低频,而添加和删除比较高频的表业务,不适合使用索引。
② MySQL 服务器本身安装的电脑上磁盘空间或内存空间不足的情况下,就不要创建。 -
如果对已经存在的很多数据的表新增索引的时候,不要在生产环境上执行(找一个没有用户使用的时间段进行索引创建)因为索引创建会锁表,其他的业务场景就只能排队等待了。
3.索引底层的数据结构
InnDB MySQL 索引实现原理:经历了三个阶段
1.二叉树 2. B-树 3.B+树
- 二叉树阶段
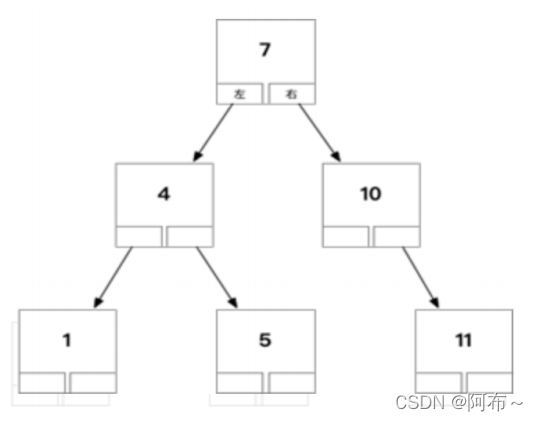
缺点:数据⼤之后树很⾼,维护和查询的性能不好。
-
B-tree 阶段
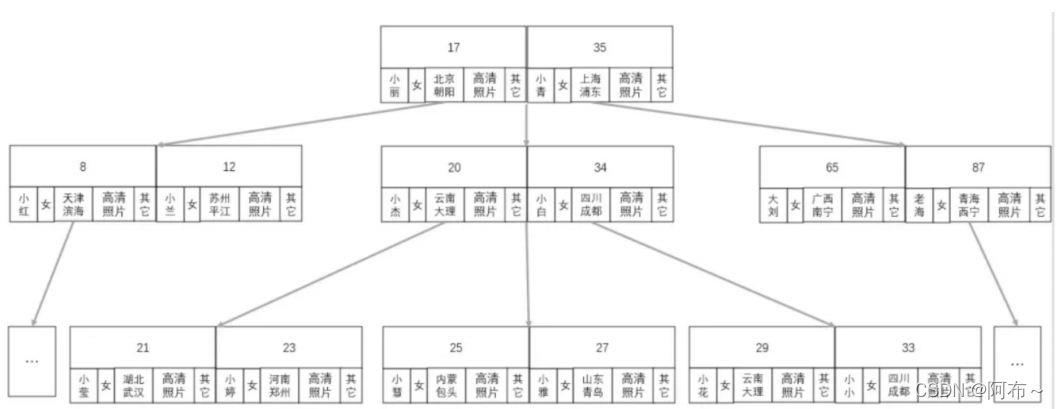
所有节点都保存了数据,加载需要很⻓的时间。也就相当于把一张表树化了,一个索引就会占用很大的空间。 -
B+ tree 阶段
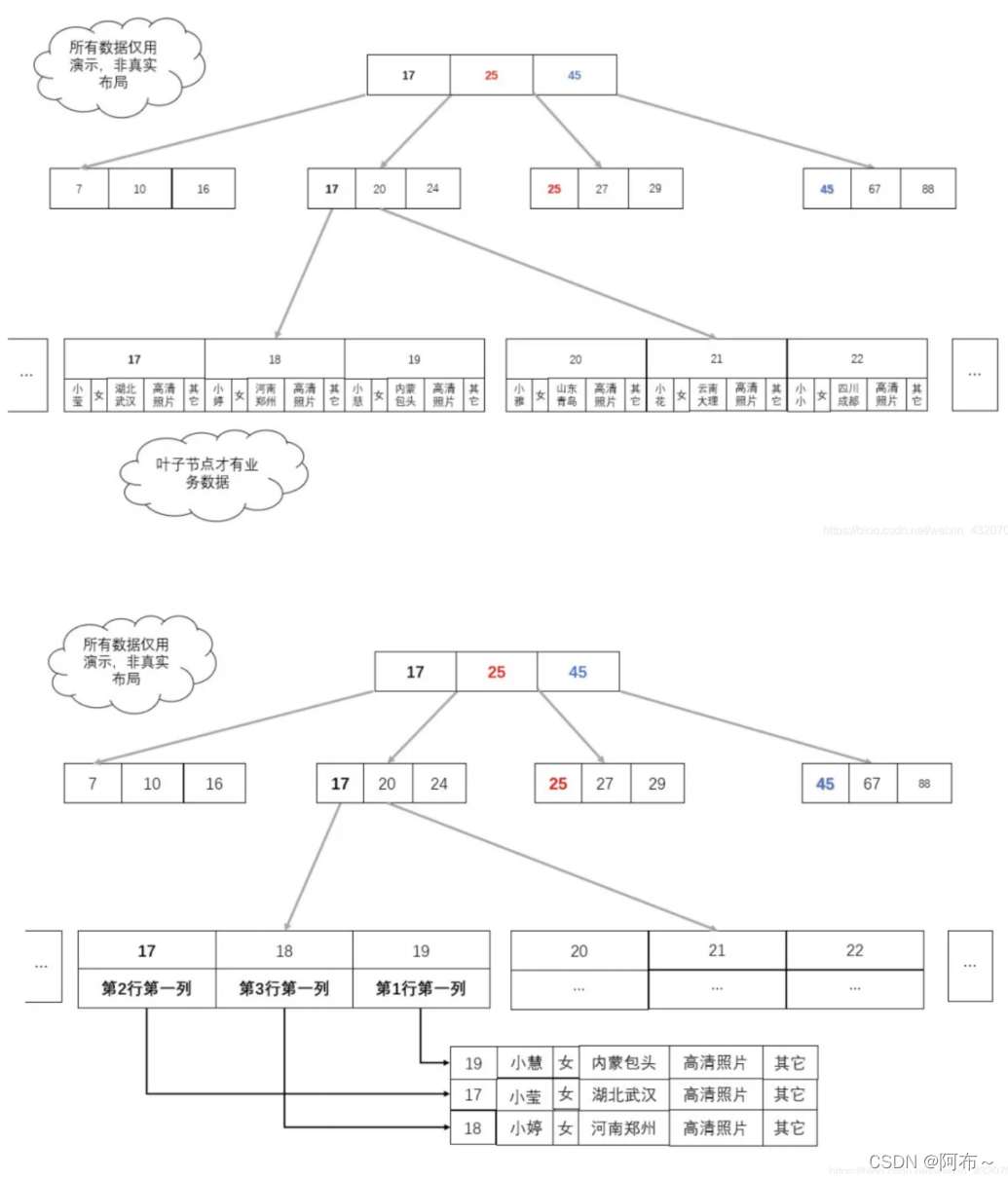
只有叶⼦节点才存储数据,且数据和索引是分离的,所谓的存储的数据,其实是指向数据的地址,数据 量变的⾮常⼩。
更多详情: link.
- 回表查询
面试问题:聚簇索引 和 ⾮聚簇索引 的区别
① 执⾏效率:聚簇索引查询速度更快,因为聚簇索引存储的是数据,⽽⾮聚簇索引存储的是主键 ID, 需要进⾏回表查询。
② 数量上:聚簇索引⼀个表只能有⼀个,⽽⾮聚簇索引可以有多个。
是的,对于非聚簇索引,在使用索引时,都要进行回表查询
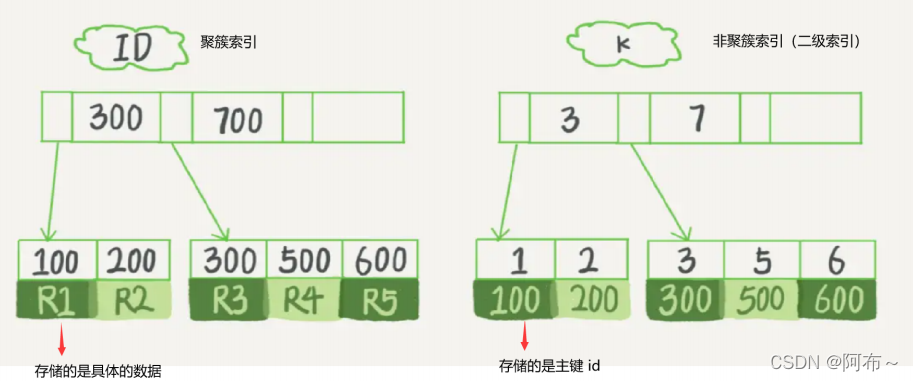
对于二级索引,他的 B+tree 的叶子节点存储的并不是数据信息地址,而是主键索引对应的 id 值!在使用二级索引时,要通过查询到的主键索引 id 去聚簇索引的 B+tree 中再去查询,才能找到数据信息的地址。

