PostgreSQL的学习心得和知识总结(七十四)|深入理解PostgreSQL数据库最新版本14下的可递归公共表达式表CTE功能增强(SEARCH和CYCLE) 原理
目录结构
注:提前言明 本文借鉴了以下博主、书籍或网站的内容,其列表如下:
1、参考书籍:《PostgreSQL数据库内核分析》
2、参考书籍:《数据库事务处理的艺术:事务管理与并发控制》
3、PostgreSQL数据库仓库链接,点击前往
4、PostgreSQL数据库中文社区官方网站,点击前往
5、参考书籍:《PostgreSQL中文手册》
6、PostgreSQL: The World’s Most Advanced Open Source Relational Database,点击前往
7、PostgreSQL 14 版本发布,快来看看有哪些新特性!,点击前往
8、PostgreSQL 14版本发布说明,点击前往
9、PostgreSQL14 官方用户手册 CTE 章节,点击前往
10、参考书籍:《The Internals of PostgreSQL for database administrators and system developers》
11、PostgreSQL 14 release notes 官方发布说明,点击前往
1、本文内容全部来源于开源社区 GitHub和以上博主的贡献,本文也免费开源(可能会存在问题,评论区等待大佬们的指正)
2、本文目的:开源共享 抛砖引玉 一起学习
3、本文不提供任何资源 不存在任何交易 与任何组织和机构无关
4、大家可以根据需要自行 复制粘贴以及作为其他个人用途,但是不允许转载 不允许商用 (写作不易,还请见谅 💖)
5、本文内容基于PostgreSQL14.2源码开发而成
PostgreSQL下的可递归公共表达式表CTE功能增强
- 文章快速说明索引
- 版本阅读源码解析

文章快速说明索引
学习目标:
做数据库内核开发久了就会有一种 少年得志,年少轻狂 的错觉,然鹅细细一品觉得自己其实不算特别优秀 远远没有达到自己想要的。也许光鲜的表面掩盖了空洞的内在,每每想到于此,皆有夜半临渊如履薄冰之感。为了睡上几个踏实觉,即日起 暂缓其他基于PostgreSQL数据库的兼容功能开发,近段时间 将着重于学习分享Postgres的基础知识和实践内幕。
注1:2021-09-30,PostgreSQL全球开发组宣布:功能最为强大的开源数据库 PostgreSQL 14版本正式发布!
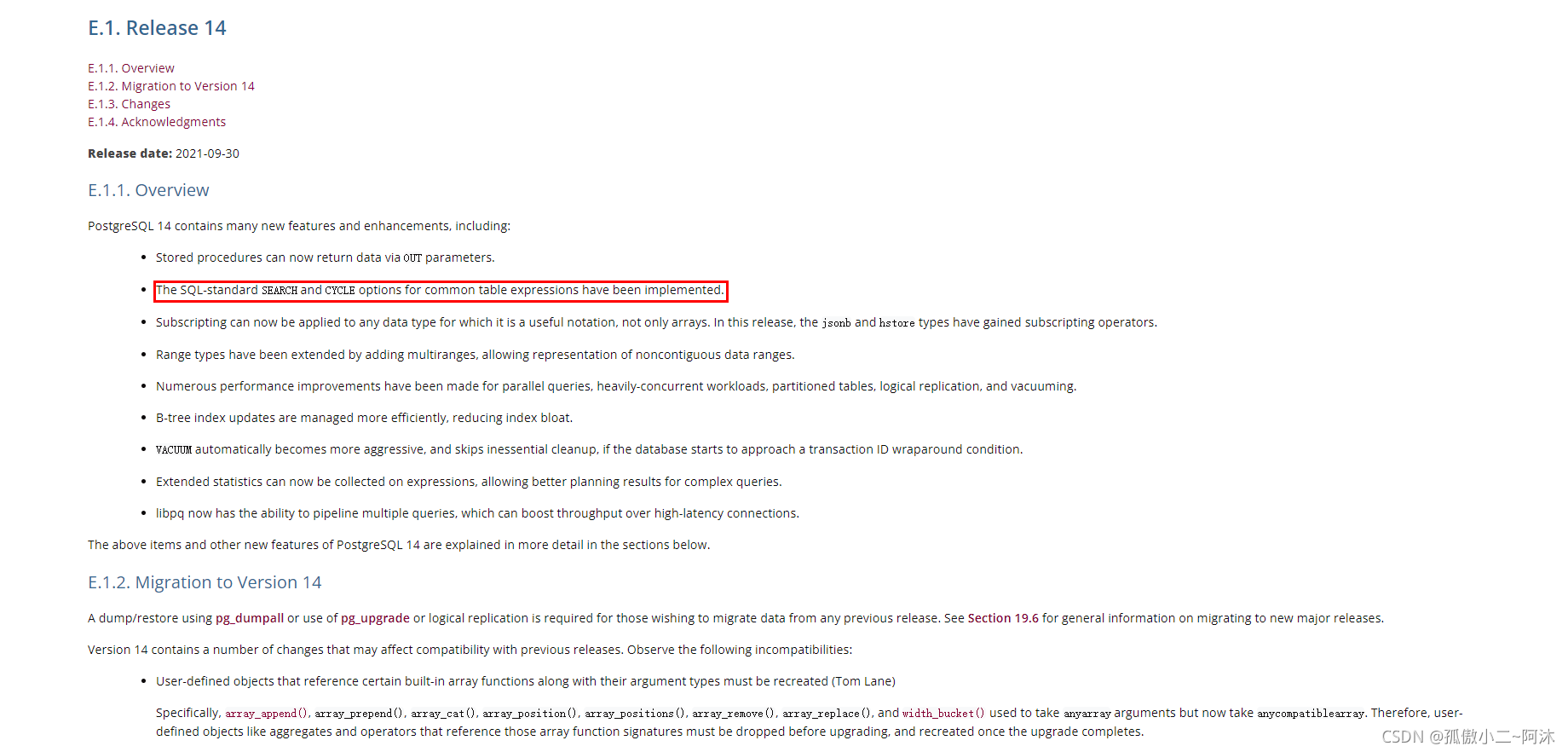
注2:自PostgreSQL14.0发布之后,官方和数据库爱好者们纷纷发过介绍新版本功能特性的文章。然而,看过之后 觉得都比较空洞和泛泛而谈。数据库大版本的发布肯定包含了大量的功能和修正,不是一篇文档就能全部说清楚的!对于想了解某一功能而言,确实不太够。在众多功能说明中,吸引到在下的一个功能就是:扩充了 WITH RECURSIVE 的功能(已实现用于公共表表达式的 SQL 标准 SEARCH 和 CYCLE 选项),如下:
学习内容:(详见目录)
1、PostgreSQL数据库下的可递归公共表达式表CTE功能增强 (SEARCH 和 CYCLE)
学习时间:
2021年10月26日 14:51:05
学习产出:
1、PostgreSQL数据库基础知识回顾 1个
2、CSDN 技术博客 1篇
3、PostgreSQL数据库内核深入学习
版本阅读源码解析
接下来,我们要做的事情就是来看一下,此次SEARCH and CYCLE clauses的功能源码提交!我们这里的做法:从源码(开发人员)的角度理解此次的功能开发!
注1:这里使用的源码为:Stamp 14.2!
注2:因为篇幅的限制,With新特性的 开发的需求和背景 等基础知识上一篇已经分享完成 PostgreSQL的学习心得和知识总结(七十三)|深入理解PostgreSQL数据库最新版本14下的可递归公共表达式表CTE功能增强(SEARCH和CYCLE) 基础,点击前往,关于功能的实现及原理部分,我放到本篇里面进行详解!
二、功能的实现及原理
在开始之前先看一个例子:
postgres=# insert into player values(1,0,'zhangsan','1000000','f');INSERT 0 1postgres=# postgres=# insert into player values(2,1,'lisi','50500','m');INSERT 0 1postgres=# postgres=# insert into player values(4,1,'houzi','65000','m');INSERT 0 1postgres=# postgres=# insert into player values(3,1,'wangwu','60000','m');INSERT 0 1postgres=# postgres=# insert into player values(7,4,'gouba','23000','m');INSERT 0 1postgres=# postgres=# insert into player values(8,4,'dujiu','21000','f');INSERT 0 1postgres=# postgres=# insert into player values(5,2,'maliu','30000','f');INSERT 0 1postgres=# postgres=# insert into player values(6,2,'liuqi','25000','m');INSERT 0 1postgres=# table player ; keyid | parent_keyid | name | salary | sex -------+--------------+----------+---------+----- 1 | 0 | zhangsan | 1000000 | f 2 | 1 | lisi | 50500 | m 4 | 1 | houzi | 65000 | m 3 | 1 | wangwu | 60000 | m 7 | 4 | gouba | 23000 | m 8 | 4 | dujiu | 21000 | f 5 | 2 | maliu | 30000 | f 6 | 2 | liuqi | 25000 | m(8 rows)postgres=#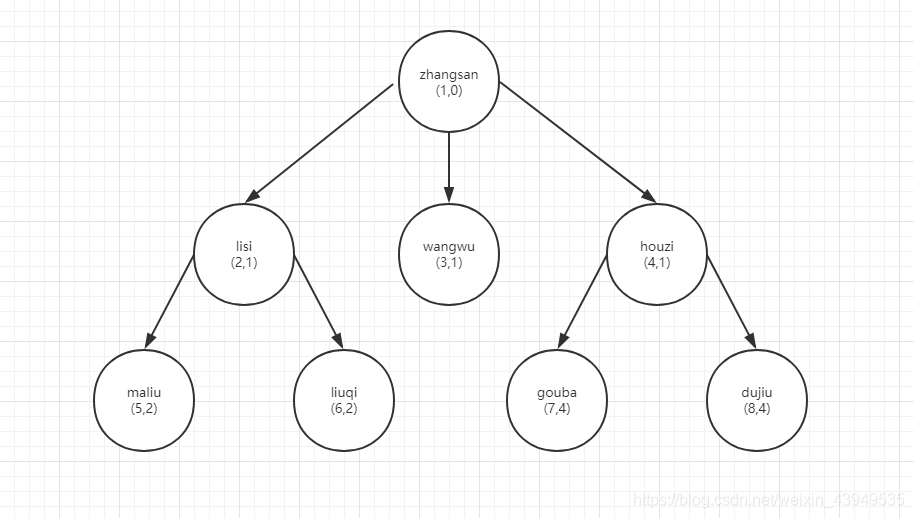
注1:以上表 insert 的时候,我故意把插入顺序打乱 后面有用
注2:以上数据来自于本人之前的博客:Oracle的学习心得和知识总结(五)|Oracle数据库 Connect By 技术详解,点击前往
示例一
## pg14新特性:深度postgres=# with recursive search_graph(keyid,parent_keyid,name,salary,sex) as (postgres(# select keyid,parent_keyid,name,salary,sex from player p where keyid = 1postgres(# union allpostgres(# select p.* from player p, search_graph sg where p.parent_keyid = sg.keyidpostgres(# ) search depth first by keyid,parent_keyid set seq select * from search_graph ; keyid | parent_keyid | name | salary | sex | seq -------+--------------+----------+---------+-----+--------------------------- 1 | 0 | zhangsan | 1000000 | f | {"(1,0)"} 2 | 1 | lisi | 50500 | m | {"(1,0)","(2,1)"} 4 | 1 | houzi | 65000 | m | {"(1,0)","(4,1)"} 3 | 1 | wangwu | 60000 | m | {"(1,0)","(3,1)"} 7 | 4 | gouba | 23000 | m | {"(1,0)","(4,1)","(7,4)"} 8 | 4 | dujiu | 21000 | f | {"(1,0)","(4,1)","(8,4)"} 5 | 2 | maliu | 30000 | f | {"(1,0)","(2,1)","(5,2)"} 6 | 2 | liuqi | 25000 | m | {"(1,0)","(2,1)","(6,2)"}(8 rows)postgres=# with recursive search_graph(keyid,parent_keyid,name,salary,sex) as (postgres(# select keyid,parent_keyid,name,salary,sex from player p where keyid = 1postgres(# union allpostgres(# select p.* from player p, search_graph sg where p.parent_keyid = sg.keyidpostgres(# ) search depth first by keyid,parent_keyid set seq select * from search_graph order by seq; keyid | parent_keyid | name | salary | sex | seq -------+--------------+----------+---------+-----+--------------------------- 1 | 0 | zhangsan | 1000000 | f | {"(1,0)"} 2 | 1 | lisi | 50500 | m | {"(1,0)","(2,1)"} 5 | 2 | maliu | 30000 | f | {"(1,0)","(2,1)","(5,2)"} 6 | 2 | liuqi | 25000 | m | {"(1,0)","(2,1)","(6,2)"} 3 | 1 | wangwu | 60000 | m | {"(1,0)","(3,1)"} 4 | 1 | houzi | 65000 | m | {"(1,0)","(4,1)"} 7 | 4 | gouba | 23000 | m | {"(1,0)","(4,1)","(7,4)"} 8 | 4 | dujiu | 21000 | f | {"(1,0)","(4,1)","(8,4)"}(8 rows)postgres=#另一个实现上述功能的SQL示例:
postgres=# with recursive search_graph(keyid,parent_keyid,name,salary,sex,seq) as (postgres(# select keyid,parent_keyid,name,salary,sex,array[row(keyid,parent_keyid)] from player p where keyid = 1postgres(# union allpostgres(# select p.*,seq || array[row(p.keyid,p.parent_keyid)] from player p, search_graph sg where p.parent_keyid = sg.keyidpostgres(# ) select * from search_graph order by seq; keyid | parent_keyid | name | salary | sex | seq -------+--------------+----------+---------+-----+--------------------------- 1 | 0 | zhangsan | 1000000 | f | {"(1,0)"} 2 | 1 | lisi | 50500 | m | {"(1,0)","(2,1)"} 5 | 2 | maliu | 30000 | f | {"(1,0)","(2,1)","(5,2)"} 6 | 2 | liuqi | 25000 | m | {"(1,0)","(2,1)","(6,2)"} 3 | 1 | wangwu | 60000 | m | {"(1,0)","(3,1)"} 4 | 1 | houzi | 65000 | m | {"(1,0)","(4,1)"} 7 | 4 | gouba | 23000 | m | {"(1,0)","(4,1)","(7,4)"} 8 | 4 | dujiu | 21000 | f | {"(1,0)","(4,1)","(8,4)"}(8 rows)postgres=#看一下这里的顺序,再联想一下Oracle数据库的层次查询!
解释一下:
- 深度优先遍历 若是不对seq列排序,顺序上等于插入顺序
- 深度优先遍历 若是对seq列排序,顺序上就是先序遍历
- search depth 实质上就是下面SQL的 简便形式(再想想pg14 新特性所说的 rewrite)
示例二
## pg14新特性:广度postgres=# table player ; keyid | parent_keyid | name | salary | sex -------+--------------+----------+---------+----- 1 | 0 | zhangsan | 1000000 | f 2 | 1 | lisi | 50500 | m 4 | 1 | houzi | 65000 | m 3 | 1 | wangwu | 60000 | m 7 | 4 | gouba | 23000 | m 8 | 4 | dujiu | 21000 | f 5 | 2 | maliu | 30000 | f 6 | 2 | liuqi | 25000 | m(8 rows)postgres=# with recursive search_graph(keyid,parent_keyid,name,salary,sex) as (select keyid,parent_keyid,name,salary,sex from player p where keyid = 1union allselect p.* from player p, search_graph sg where p.parent_keyid = sg.keyid) search breadth first by keyid,parent_keyid set seq select * from search_graph ; keyid | parent_keyid | name | salary | sex | seq -------+--------------+----------+---------+-----+--------- 1 | 0 | zhangsan | 1000000 | f | (0,1,0) 2 | 1 | lisi | 50500 | m | (1,2,1) 4 | 1 | houzi | 65000 | m | (1,4,1) 3 | 1 | wangwu | 60000 | m | (1,3,1) 7 | 4 | gouba | 23000 | m | (2,7,4) 8 | 4 | dujiu | 21000 | f | (2,8,4) 5 | 2 | maliu | 30000 | f | (2,5,2) 6 | 2 | liuqi | 25000 | m | (2,6,2)(8 rows)postgres=# with recursive search_graph(keyid,parent_keyid,name,salary,sex) as (select keyid,parent_keyid,name,salary,sex from player p where keyid = 1union allselect p.* from player p, search_graph sg where p.parent_keyid = sg.keyid) search breadth first by keyid,parent_keyid set seq select * from search_graph order by seq; keyid | parent_keyid | name | salary | sex | seq -------+--------------+----------+---------+-----+--------- 1 | 0 | zhangsan | 1000000 | f | (0,1,0) 2 | 1 | lisi | 50500 | m | (1,2,1) 3 | 1 | wangwu | 60000 | m | (1,3,1) 4 | 1 | houzi | 65000 | m | (1,4,1) 5 | 2 | maliu | 30000 | f | (2,5,2) 6 | 2 | liuqi | 25000 | m | (2,6,2) 7 | 4 | gouba | 23000 | m | (2,7,4) 8 | 4 | dujiu | 21000 | f | (2,8,4)(8 rows)postgres=# 解释一下:
- 这里明白了 插入时乱序的用意了吧
- 广度优先遍历 若是不对seq列排序,顺序上等于插入顺序
- 广度优先遍历 若是对seq列排序,顺序上就是层序遍历
- search breadth 实质上 也是一个rewrite的形式 但是这个SQL很难写,后面我会详细介绍其底层的实现原理
示例三
postgres=# insert into player values(4,8,'xunhuan','22222','m');INSERT 0 1postgres=# table player ; keyid | parent_keyid | name | salary | sex -------+--------------+----------+---------+----- 1 | 0 | zhangsan | 1000000 | f 2 | 1 | lisi | 50500 | m 4 | 1 | houzi | 65000 | m 3 | 1 | wangwu | 60000 | m 7 | 4 | gouba | 23000 | m 8 | 4 | dujiu | 21000 | f 5 | 2 | maliu | 30000 | f 6 | 2 | liuqi | 25000 | m 4 | 8 | xunhuan | 22222 | m(9 rows)postgres=#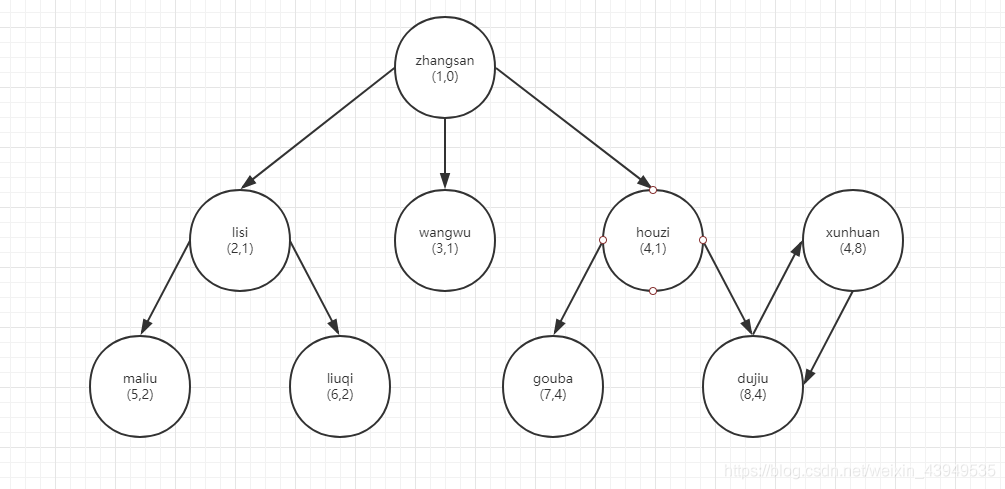
## pg14新特性:cyclepostgres=# with recursive search_graph(keyid,parent_keyid,name,salary,sex) as (select keyid,parent_keyid,name,salary,sex from player p where keyid = 1union allselect p.* from player p, search_graph sg where p.parent_keyid = sg.keyid) cycle keyid,parent_keyid set is_cycle to 'Y' default 'N' using seq select * from search_graph order by seq; keyid | parent_keyid | name | salary | sex | is_cycle | seq -------+--------------+----------+---------+-----+----------+------------------------------------------- 1 | 0 | zhangsan | 1000000 | f | N | {"(1,0)"} 2 | 1 | lisi | 50500 | m | N | {"(1,0)","(2,1)"} 5 | 2 | maliu | 30000 | f | N | {"(1,0)","(2,1)","(5,2)"} 6 | 2 | liuqi | 25000 | m | N | {"(1,0)","(2,1)","(6,2)"} 3 | 1 | wangwu | 60000 | m | N | {"(1,0)","(3,1)"} 4 | 1 | houzi | 65000 | m | N | {"(1,0)","(4,1)"} 7 | 4 | gouba | 23000 | m | N | {"(1,0)","(4,1)","(7,4)"} 8 | 4 | dujiu | 21000 | f | N | {"(1,0)","(4,1)","(8,4)"} 4 | 8 | xunhuan | 22222 | m | N | {"(1,0)","(4,1)","(8,4)","(4,8)"} 7 | 4 | gouba | 23000 | m | N | {"(1,0)","(4,1)","(8,4)","(4,8)","(7,4)"} 8 | 4 | dujiu | 21000 | f | Y | {"(1,0)","(4,1)","(8,4)","(4,8)","(8,4)"}(11 rows)postgres=#另一个实现上述功能的SQL示例:
postgres=# with recursive search_graph(keyid,parent_keyid,name,salary,sex,is_cycle,seq) as (select keyid,parent_keyid,name,salary,sex,'N' as is_cycle,array[row(keyid,parent_keyid)] from player p where keyid = 1union allselect p.*,case when row(p.keyid, p.parent_keyid) = any (array[seq]) then 'Y' else 'N' end,seq || array[row(p.keyid,p.parent_keyid)] from player p, search_graph sg where p.parent_keyid = sg.keyid and is_cycle = 'N') select * from search_graph order by seq; keyid | parent_keyid | name | salary | sex | is_cycle | seq -------+--------------+----------+---------+-----+----------+------------------------------------------- 1 | 0 | zhangsan | 1000000 | f | N | {"(1,0)"} 2 | 1 | lisi | 50500 | m | N | {"(1,0)","(2,1)"} 5 | 2 | maliu | 30000 | f | N | {"(1,0)","(2,1)","(5,2)"} 6 | 2 | liuqi | 25000 | m | N | {"(1,0)","(2,1)","(6,2)"} 3 | 1 | wangwu | 60000 | m | N | {"(1,0)","(3,1)"} 4 | 1 | houzi | 65000 | m | N | {"(1,0)","(4,1)"} 7 | 4 | gouba | 23000 | m | N | {"(1,0)","(4,1)","(7,4)"} 8 | 4 | dujiu | 21000 | f | N | {"(1,0)","(4,1)","(8,4)"} 4 | 8 | xunhuan | 22222 | m | N | {"(1,0)","(4,1)","(8,4)","(4,8)"} 7 | 4 | gouba | 23000 | m | N | {"(1,0)","(4,1)","(8,4)","(4,8)","(7,4)"} 8 | 4 | dujiu | 21000 | f | Y | {"(1,0)","(4,1)","(8,4)","(4,8)","(8,4)"}(11 rows)postgres=#注:在后面查询重写模块,我会详细介绍上面这3个对应的实现原理!
虽然关于递归查询的逻辑(函数ExecRecursiveUnion)我已经调试过很多遍 也给大家手写了很多遍,但是这个是递归的核心精华 真的很重要 大家可以去看本人之前的博客:
- PostgreSQL的学习心得和知识总结(六十四)|关于PostgreSQL数据库 图式搜索(graph search)及递归查询 的场景说明,点击前往
- PostgreSQL的学习心得和知识总结(七十一)|深入理解PostgreSQL数据库的可递归公共表达式表CTE的基础功能和基本原理,点击前往
- PostgreSQL的学习心得和知识总结(七十三)|深入理解PostgreSQL数据库最新版本14下的可递归公共表达式表CTE功能增强(SEARCH和CYCLE) 基础,点击前往
我们这里再调试一下,分析一下上面这11行是怎么查询出来的:
- 首先递归基查询出来的 keyid = 1,其 is_cycle 都是假。它会在
working_table里面记录 - 接下来进入递归部分:首先会得到 keyid = 2 的这一行,并记录在
intermediate_table里面 - 下一次递归 会得到 keyid = 4 parent_keyid = 1 的这一行,并记录在
intermediate_table里面 - 下一次递归 会得到 keyid = 3 的这一行,并记录在
intermediate_table里面 - 下一次递归 与
working_table相关的行没有了,此时会用intermediate_table来覆盖working_table并重建临时表 - 此时工作表里面有 keyid = 2,3,4 这三个:此时能在这个的基础上得到 keyid = 7 的这一行,并记录在
intermediate_table里面 - 下一次递归 会得到 keyid = 8 的这一行,并记录在
intermediate_table里面 - 下一次递归 会得到 keyid = 5 的这一行,并记录在
intermediate_table里面 - 下一次递归 会得到 keyid = 6 的这一行,并记录在
intermediate_table里面 - 下一次递归 与
working_table相关的行没有了,此时会用intermediate_table来覆盖working_table并重建临时表 - 此时工作表里面有 keyid = 7,8,5,6 这四个:此时能在这个的基础上得到 keyid = 4 parent_keyid = 8 的这一行,并记录在
intermediate_table里面 - 下一次递归 与
working_table相关的行没有了,此时会用intermediate_table来覆盖working_table并重建临时表 - 此时工作表里面有 keyid = 4 parent_keyid = 8 这一个:此时能在这个的基础上得到 keyid = 7 的这一行,并记录在
intermediate_table里面 - 下一次递归 会得到 keyid = 8 的这一行,并记录在
intermediate_table里面 - 下一次递归 与
working_table相关的行没有了,此时会用intermediate_table来覆盖working_table并重建临时表 - 此时工作表里面有 keyid = 7,8 这两个:但是因为工作表里面还可以 有:keyid = 8 parent_keyid = 4 -> keyid = 4 parent_keyid = 8 但是此时的 is_cycle 为真,所以递归部分不再能遍历出 keyid = 4 parent_keyid = 8
- 此时工作表里面有 keyid = 7 这一个:但是 7 没有指向,所以递归部分结束
OK 这是我最后一次手写这个过程了,即使下次等到 层次查询 做出来 我也不写了(白白的死脑细胞 划不来)!
这里小结一下:
1、现在再理解一下commit信息:
These clauses can be rewritten into queries using existing syntax, and that is what this patch does in the rewriter.
2、现在给大家透露一点:这也就是本人基于PostgreSQL数据库开发Oracle数据库层次查询功能的核心原理
This adds the SQL standard feature that adds the SEARCH and CYCLE clauses to recursive queries to be able to do produce breadth- or depth-first search orders and detect cycles. These clauses can be rewritten into queries using existing syntax, and that is what this patch does in the rewriter.OK,下面来看一下这一版代码!语法相关的,上一篇已经写的很清楚了,这里不再赘述!
第一步:语义分析阶段
调试的SQL如下:
postgres=# with recursive search_graph(keyid,parent_keyid,name,salary,sex) as (select keyid,parent_keyid,name,salary,sex from player p where keyid = 1union allselect p.* from player p, search_graph sg where p.parent_keyid = sg.keyid) cycle keyid,parent_keyid set is_cycle to 'Y' default 'N' using seq select * from search_graph order by seq; keyid | parent_keyid | name | salary | sex | is_cycle | seq -------+--------------+----------+---------+-----+----------+------------------------------------------- 1 | 0 | zhangsan | 1000000 | f | N | {"(1,0)"} 2 | 1 | lisi | 50500 | m | N | {"(1,0)","(2,1)"} 5 | 2 | maliu | 30000 | f | N | {"(1,0)","(2,1)","(5,2)"} 6 | 2 | liuqi | 25000 | m | N | {"(1,0)","(2,1)","(6,2)"} 3 | 1 | wangwu | 60000 | m | N | {"(1,0)","(3,1)"} 4 | 1 | houzi | 65000 | m | N | {"(1,0)","(4,1)"} 7 | 4 | gouba | 23000 | m | N | {"(1,0)","(4,1)","(7,4)"} 8 | 4 | dujiu | 21000 | f | N | {"(1,0)","(4,1)","(8,4)"} 4 | 8 | xunhuan | 22222 | m | N | {"(1,0)","(4,1)","(8,4)","(4,8)"} 7 | 4 | gouba | 23000 | m | N | {"(1,0)","(4,1)","(8,4)","(4,8)","(7,4)"} 8 | 4 | dujiu | 21000 | f | Y | {"(1,0)","(4,1)","(8,4)","(4,8)","(8,4)"}(11 rows)postgres=#因为每个WITH子句中的辅助语句可以是一个SELECT INSERT UPDATE 或 DELETE;并且WITH子句本身附加到的初级语句可以是一个SELECT INSERT UPDATE 或 DELETE。
因此,我们学习的重点就在:
// src/backend/parser/parse_cte.c/* * transformWithClause - * Transform the list of WITH clause "common table expressions" into * Query nodes. * * The result is the list of transformed CTEs to be put into the output * Query. (This is in fact the same as the ending value of p_ctenamespace, * but it seems cleaner to not expose that in the function's API.) * * 结果是要放入输出查询的转换后的 CTE 列表 * (这实际上与 p_ctenamespace 的结束值相同,但在函数的 API 中不公开它似乎更清晰) */List *transformWithClause(ParseState *pstate, WithClause *withClause);其步骤如下:
- 遍历ctes:对于任一类型的 WITH,列表中不得有重复的 CTE 名称。此外,暂时将每个 CTE 标记为非递归,并将其引用计数初始化为零,并在需要时设置
pstate->p_hasModifyingCTE - 对于 WITH RECURSIVE,我们根据需要重新排列列表元素以消除前向引用。 首先,构建一个工作数组并设置
tree walkers所需的数据结构
2.1查找所有依赖项并将 CteItem 排序为安全处理顺序。 此外,标记包含自引用的 CTE
2.2在检查递归查询的格式是否正确之后;设置ctenamespace进行解析分析。 根据规范,所有 WITH 项对所有其他项都是可见的,因此在解析分析之前将它们全部填入。 我们以安全的处理顺序构建列表,以便规划器可以按顺序处理查询
2.3按照拓扑排序确定的顺序进行解析分析
- 对于非递归的WITH,只需按顺序分析每个 CTE,然后将其添加到
ctenamespace。 这对应于规范对每个 WITH 名称范围的定义。 然而,为了让错误报告能够意识到错误引用的可能性,我们在p_future_ctes中维护了一个尚未可见的 CTE 的列表
于是可以看出最重要的函数就是:analyzeCTE(pstate, cte);,如下:
// src/backend/parser/parse_cte.c/* * Perform the actual parse analysis transformation of one CTE. All * CTEs it depends on have already been loaded into pstate->p_ctenamespace, * and have been marked with the correct output column names/types. * * 执行一个 CTE 的实际解析分析转换 * 它所依赖的所有 CTE 都已经加载到 pstate->p_ctenamespace 中,并且已经用正确的输出列名称/类型进行了标记 */static voidanalyzeCTE(ParseState *pstate, CommonTableExpr *cte);该函数执行过程:
- 先行使用
parse_sub_analyze来处理 语法解析阶段的PreparableStmt模块,如下:
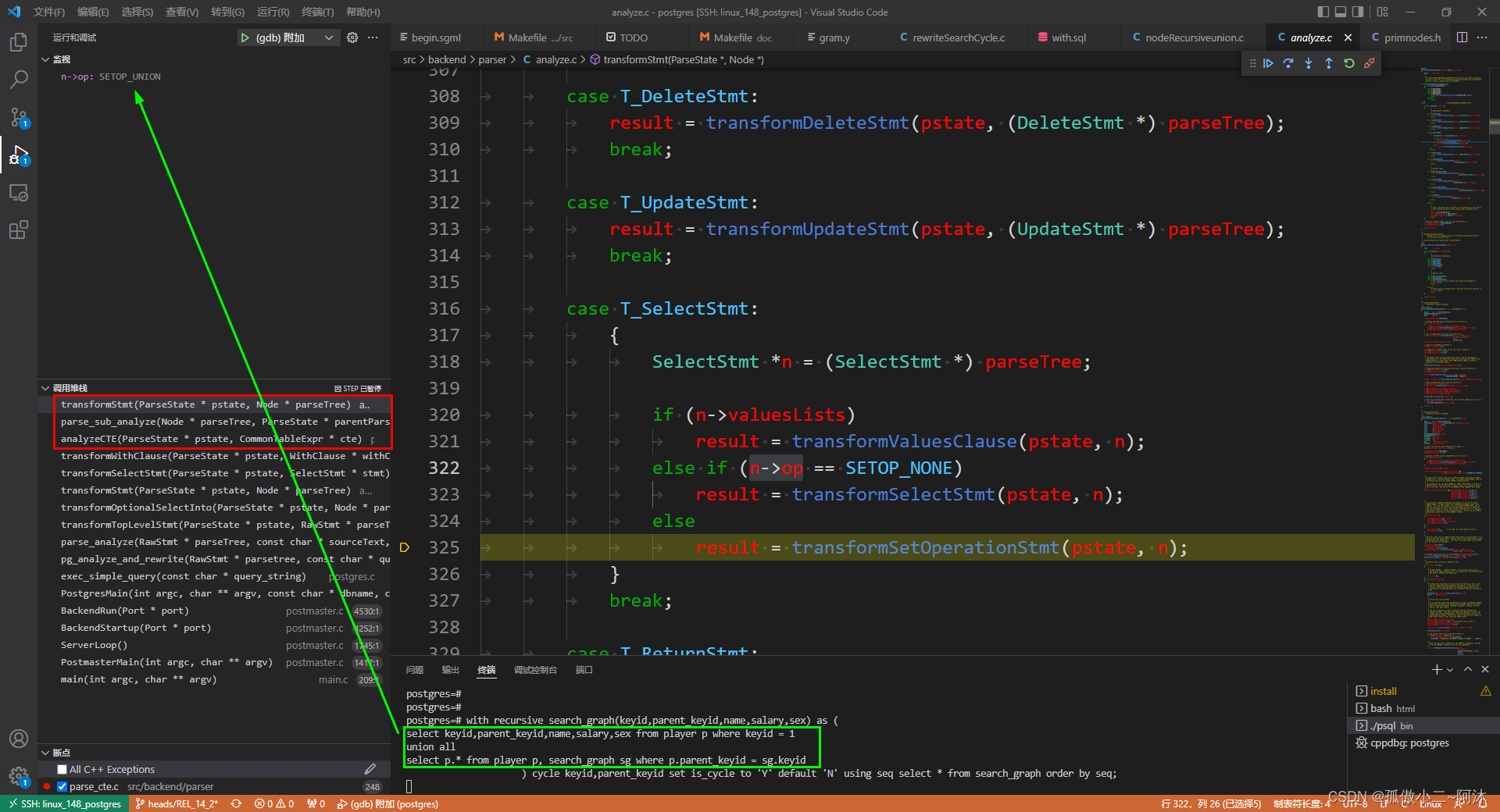
最终query = parse_sub_analyze(cte->ctequery, pstate, cte, false, true);的结果(就是上图中的绿色框框里面),如下图所示:

如上图所示:一个非常非常非常清晰的Query结构出现在我们面前,关于制作工具请参见本人博客:PostgreSQL的学习心得和知识总结(七十二)|深入理解PostgreSQL数据库开源节点树打印工具pgNodeGraph的作用原理及继续维护pgNodeGraph的声明,点击前往
注1:这里就使用我的仓库即可,否则制作出来的图片连接线无颜色区分!
注2:上图看着非常复杂,但实际上 逐块分析递归回溯 是非常清晰明了!
这里解释一下上面那张图(Query结构 这里的由函数transformSetOperationStmt解析生成):
// src/backend/parser/analyze.c/* * transformSetOperationStmt - * transforms a set-operations tree * * A set-operation tree is just a SELECT, but with UNION/INTERSECT/EXCEPT * structure to it. We must transform each leaf SELECT and build up a top- * level Query that contains the leaf SELECTs as subqueries in its rangetable. * The tree of set operations is converted into the setOperations field of * the top-level Query. * * 集合操作树只是一个 SELECT,但具有 UNION/INTERSECT/EXCEPT 结构 * 我们必须转换每个叶子 SELECT,而且构建一个顶级查询。该查询包含叶子 SELECT 作为其范围表中的子查询 * * 集合操作树被转换为顶级 Query 的 setOperations 字段。 */static Query *transformSetOperationStmt(ParseState *pstate, SelectStmt *stmt);-
上图中
query->setOperations:op是1 代表SETOP_UNION;all 是true,表示 UNION ALL;左右就代表 union all 两边的select,就是上面rtable:rte1和rte2;colTypes:OID list of output column type OIDs -
query->targetList略 -
下面主要来看这两个RTE 由函数
transformSetOperationTree生成:在该函数中递归调用自身,递归处理左右子树
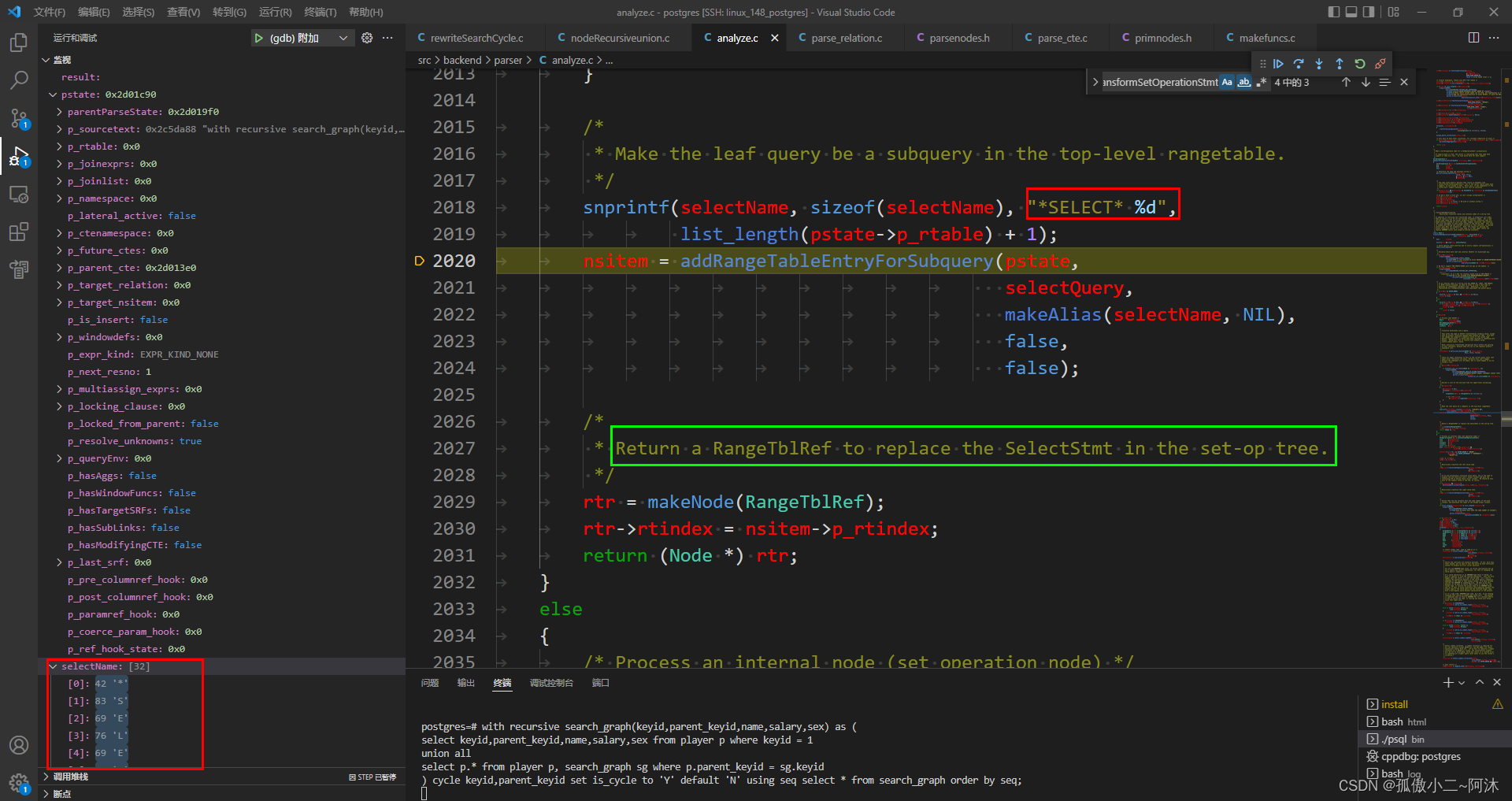

如上,*SELECT* 1的就是左子树 (递归基部分);*SELECT* 2的就是右子树(递归部分)。这里也没有办法详述 图示已经非常清楚了! -
继续回到函数
analyzeCTE中,此次新增了关于cte->search_clause || cte->cycle_clause的诸多报错场景 有兴趣的可以去看上一篇文档 这里不再多说 -
接下来 回到
transformWithClause函数中,在之后解析结束回到transformSelectStmt函数中 OK,我们这里直接看一下parse_analyze查询分析之后的query结构,如下所示:

还好现在的图片线条都是有颜色的,不然打死我 我都不想分析这个图!对这个工具感兴趣的小伙伴们可以去看一下博客:PostgreSQL的学习心得和知识总结(七十二)|深入理解PostgreSQL数据库开源节点树打印工具pgNodeGraph的作用原理及继续维护pgNodeGraph的声明
OK,下面来解释一下:
- 虽然都是Query结构,第一张是第二张图的
query->cteList中CTE表达式的ctequery部分(就是图2最上面的 黑色线条指向的部分) - 而SQL语句里面的
opt_cycle_clause部分 则是第二张图的query->cteList中CTE表达式的cycle_clause部分(短蓝色线段部分)。可以看出:cycle_mark_column名字is_cycle其类型为25 text;cycle_mark_value设置的是'Y';cycle_mark_default设置的是'N这里提示一下:去看一下constvalue的值 89,78就明白了;cycle_path_column的名字seq。因为这里没有写search语句,search_clause为空 - 接下来看:
select * from search_graph order by seq rtable自然就是search_graph,其列的个数为7 分析一下:
| - | - | - | - | - | - | - |
|---|---|---|---|---|---|---|
| 23 | 23 | 1043 | 23 | 1043 | 25 | 2287 |
| keyid | parent_keyid | name | salary | sex | is_cycle | seq |
| int4 | int4 | varchar | int4 | varchar | text | _record |
- 如上 cycle_clause 这里额外拼加
cycle_mark_columncycle_path_column列到递归查询中,大家去看一下上面 示例3 的SQL改写
同理可得,search_clause语句 额外拼接的就是search_seq_column,大家去看一下上面的 示例1 的SQL改写!
第二步:查询重写阶段
接下来我们调试的SQL如下:
postgres=# with recursive search_graph(keyid,parent_keyid,name,salary,sex) as (select keyid,parent_keyid,name,salary,sex from player p where keyid = 1union allselect p.* from player p, search_graph sg where p.parent_keyid = sg.keyid) search depth first by keyid,parent_keyid set seq cycle keyid,parent_keyid set is_cycle to 'Y' default 'N' using path select * from search_graph; keyid | parent_keyid | name | salary | sex | seq | is_cycle | path -------+--------------+----------+---------+-----+-------------------------------------------+----------+------------------------------------------- 1 | 0 | zhangsan | 1000000 | f | {"(1,0)"} | N | {"(1,0)"} 2 | 1 | lisi | 50500 | m | {"(1,0)","(2,1)"} | N | {"(1,0)","(2,1)"} 4 | 1 | houzi | 65000 | m | {"(1,0)","(4,1)"} | N | {"(1,0)","(4,1)"} 3 | 1 | wangwu | 60000 | m | {"(1,0)","(3,1)"} | N | {"(1,0)","(3,1)"} 7 | 4 | gouba | 23000 | m | {"(1,0)","(4,1)","(7,4)"} | N | {"(1,0)","(4,1)","(7,4)"} 8 | 4 | dujiu | 21000 | f | {"(1,0)","(4,1)","(8,4)"} | N | {"(1,0)","(4,1)","(8,4)"} 5 | 2 | maliu | 30000 | f | {"(1,0)","(2,1)","(5,2)"} | N | {"(1,0)","(2,1)","(5,2)"} 6 | 2 | liuqi | 25000 | m | {"(1,0)","(2,1)","(6,2)"} | N | {"(1,0)","(2,1)","(6,2)"} 4 | 8 | xunhuan | 22222 | m | {"(1,0)","(4,1)","(8,4)","(4,8)"} | N | {"(1,0)","(4,1)","(8,4)","(4,8)"} 7 | 4 | gouba | 23000 | m | {"(1,0)","(4,1)","(8,4)","(4,8)","(7,4)"} | N | {"(1,0)","(4,1)","(8,4)","(4,8)","(7,4)"} 8 | 4 | dujiu | 21000 | f | {"(1,0)","(4,1)","(8,4)","(4,8)","(8,4)"} | Y | {"(1,0)","(4,1)","(8,4)","(4,8)","(8,4)"}(11 rows)postgres=#// src/backend/tcop/postgres.c/* * Given a raw parsetree (gram.y output), and optionally information about * types of parameter symbols ($n), perform parse analysis and rule rewriting. * * A list of Query nodes is returned, since either the analyzer or the * rewriter might expand one query to several. * * NOTE: for reasons mentioned above, this must be separate from raw parsing. */List *pg_analyze_and_rewrite(RawStmt *parsetree, const char *query_string, Oid *paramTypes, int numParams, QueryEnvironment *queryEnv){.../* * (2) Rewrite the queries, as necessary */querytree_list = pg_rewrite_query(query);...}OK,这里就不再展示 语义分析 阶段之后的query图了,下面来看一下具体的rewriter过程:
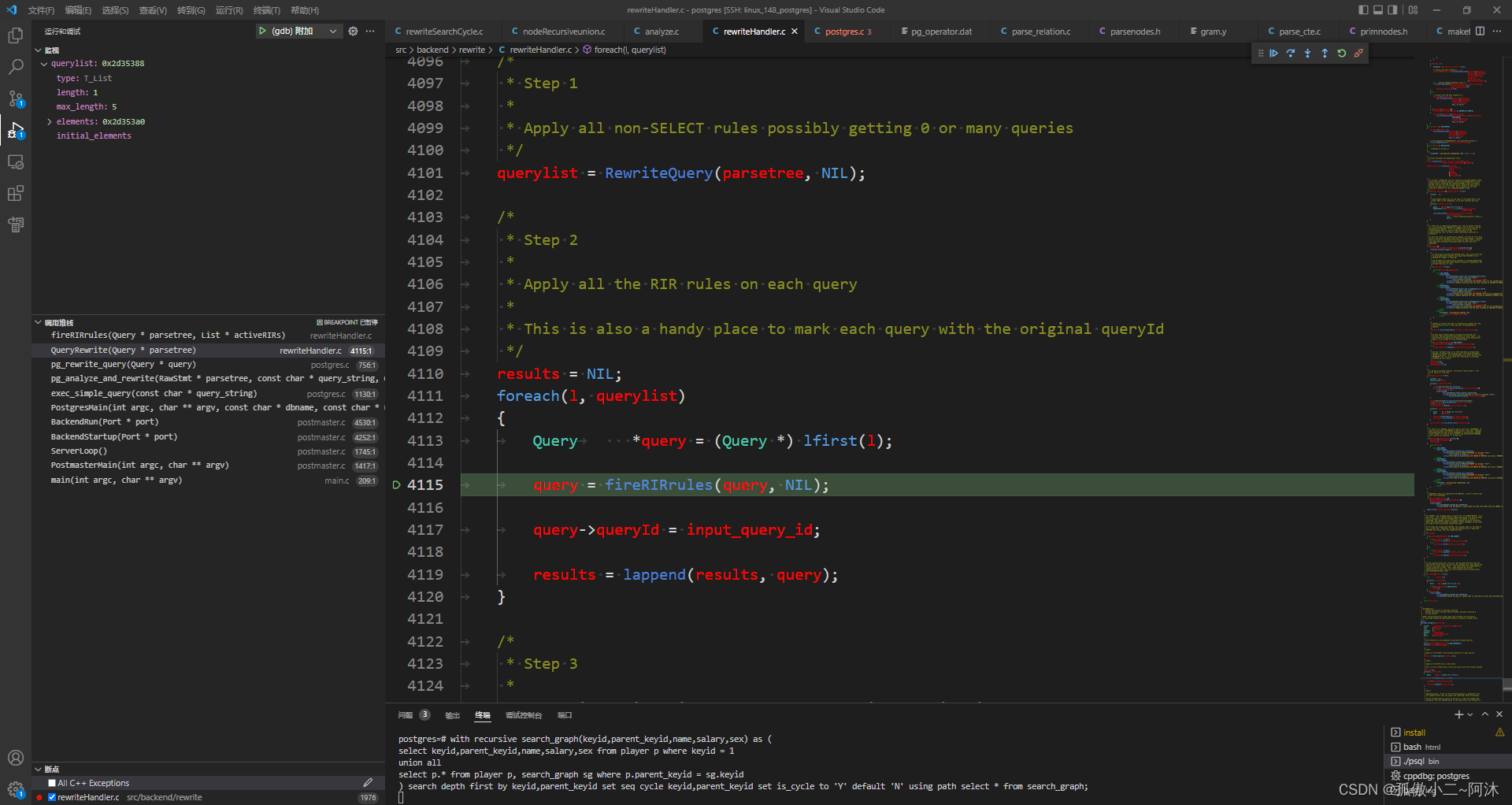
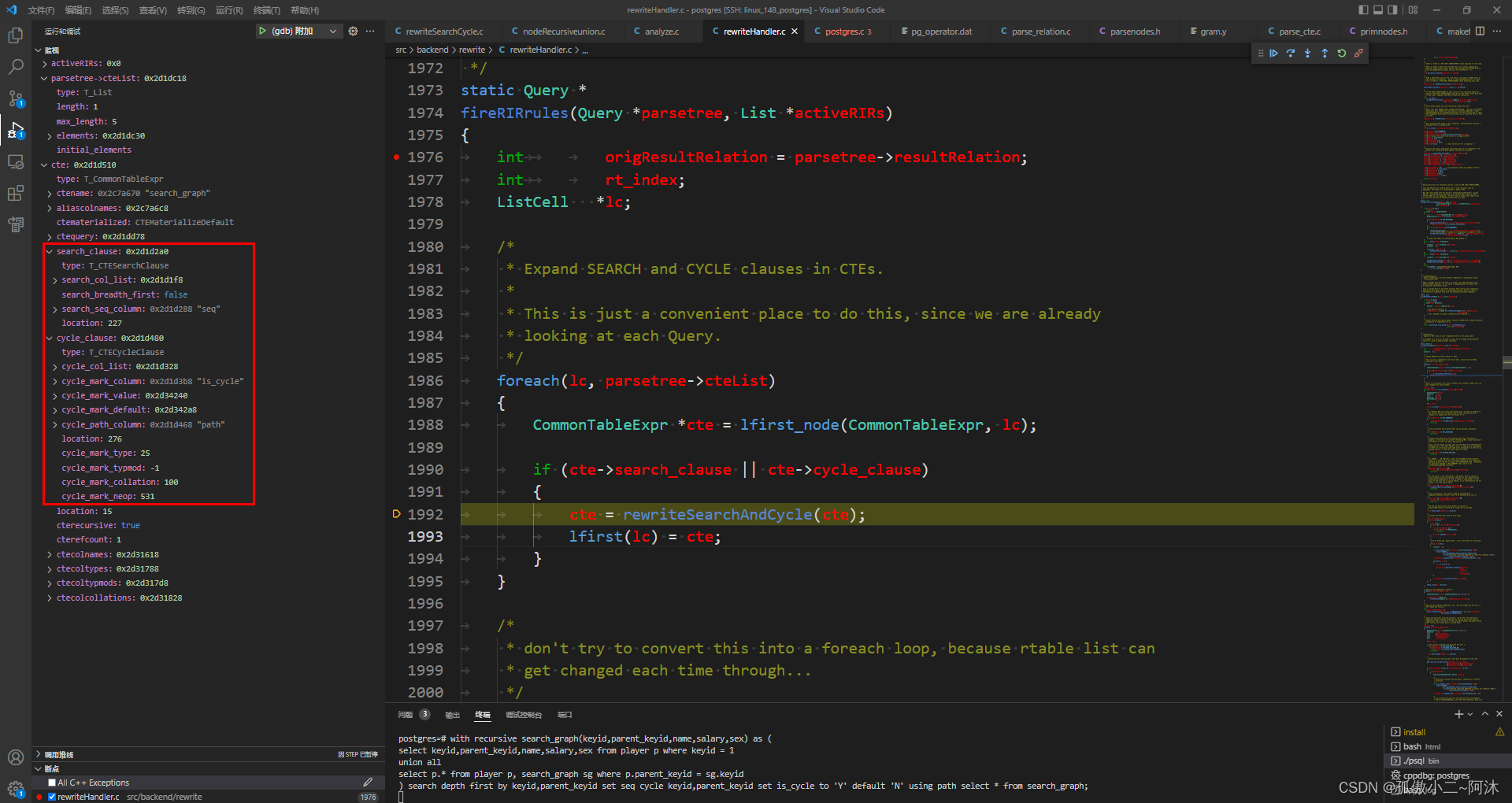
OK,下面就来看一下这里的重写函数rewriteSearchAndCycle,如下:
// src/backend/rewrite/rewriteSearchCycle.cCommonTableExpr *rewriteSearchAndCycle(CommonTableExpr *cte);首先来看一下重写之前的一些信息:

其实这个就是Query1图所展示的内容,下面开始重写!
- 这里设置了 search depth 即:深度 选择的类型是
RECORDARRAYOID广度选择的是RECORDOID。原因如下:
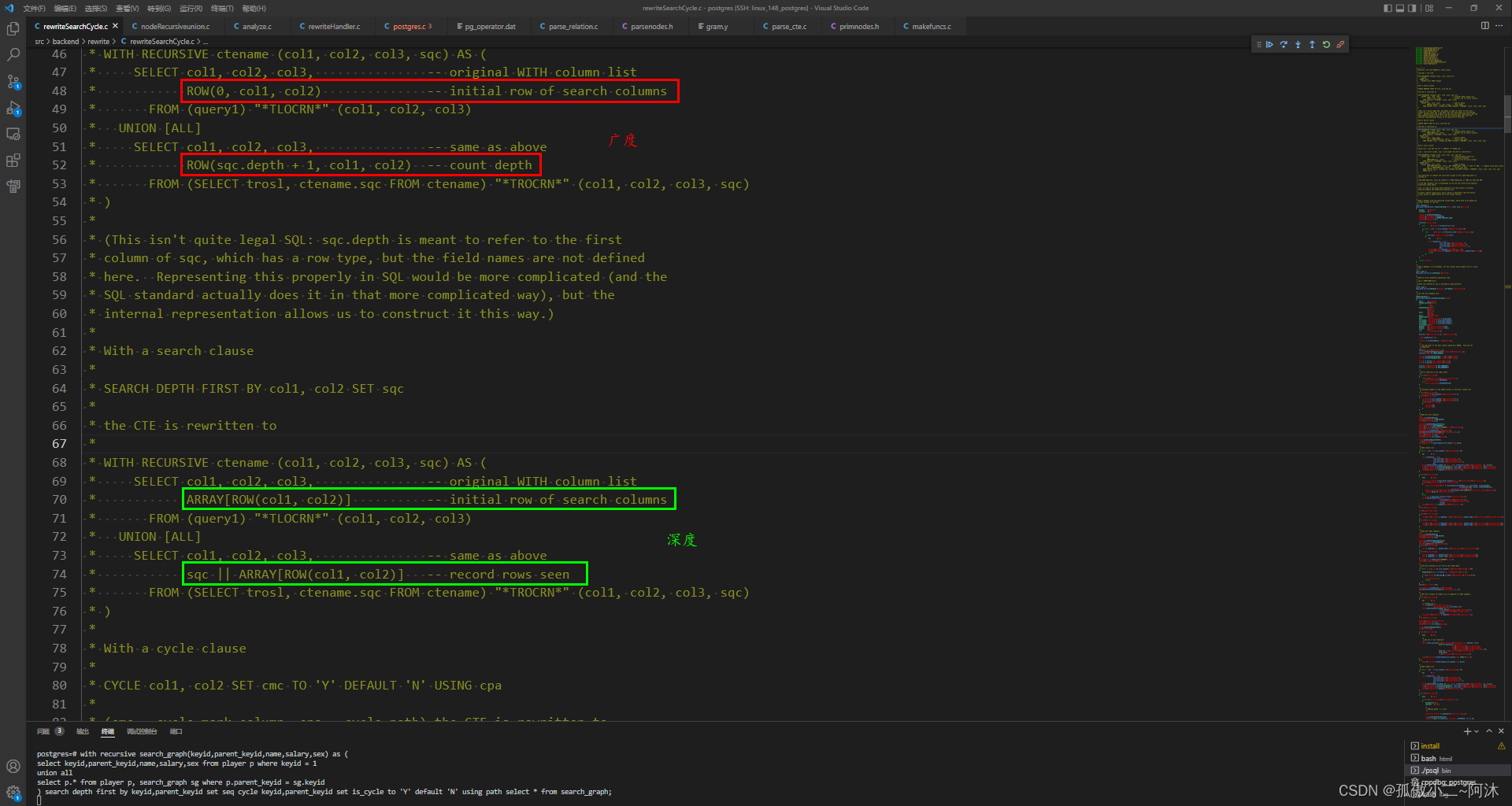
- Attribute numbers of the added columns in the CTE’s column list. 这里
cte->ctecolnames已经是5,所以search的拼接列seq列号为6;cycle的两个拼接列cmc = cycle mark column, cpa = cycle path分别为7,8 - Make new left subquery(左子树)
- Make target list 这里详细解释一下
1、将
cte->ctecolnames的5列加入到 targetlist里面
2、这里search_clause不为空,cte->search_clause->search_col_list是2 指的是:depth first by keyid,parent_keyid
然后调用函数make_path_rowexpr将这两列做成RowExpr结构的rowexpr->args即:row(keyid, parent_id)
3、对于广度:下面改写RowExpr结构的rowexpr->args为row(0, keyid, parent_id)。做法:在search_col_rowexpr->args的前面拼接一个 0
4、对于深度:下面改写为ArrayExpr结构体的 即:array[row(keyid, parent_id)]
5、注:这里建议大家再回到上面看一下 示例1 示例2!
6、makeTargetEntry函数把这个seq列生成,之后加入targetlist
OK,search的这一列已经加到targetList里面了,下面来看cycle的两个列:
1、
cycle_mark_column就是这里的 is_cycle列 ,然后调用makeTargetEntry来制作它 这里需要注意,用的是默认值cycle_mark_default,之后加到targetList里面
2、cte->cycle_clause->cycle_col_list是2 指的是:cycle keyid,parent_keyid
然后调用函数make_path_initial_array将这两列做成ArrayExpr结构体的 即:array[row(keyid, parent_id)](和上面深度一样)之后加到targetList里面,列名 path
左子树子查询制作完成:rte1->subquery = newq1;,从此 递归基 里面的targetList里面就是8个了!之后,把这1+2 = 3列 拼接到 rte1->eref->colnames
- Make new right subquery 上面是递归基部分的重写,那下面就是 递归部分的重写
此时就是在重写下面这个:
select p.* from player p, search_graph sg where p.parent_keyid = sg.keyid// 开始的时候 targetlist也是5rte2->subquery->rtable里面就是2,指:p、sg。于是Find the reference to our CTE in the range table的结果就是:cte_rtindex = 2- Add extra columns to target list of subquery of right subquery 这里详细解释一下
1、search_clause子句:首先做出
search_seq_type类型的一个var;然后makeTargetEntry函数制作出var的空列 列名seq;放到targetlist
2、cycle_clause子句:依次制作成cycle_mark_columncycle_path_column列(内部都是一个简单的var空列);放到targetlist
- 针对于
cycle_clause,要制作条件:Add cmc cmv condition
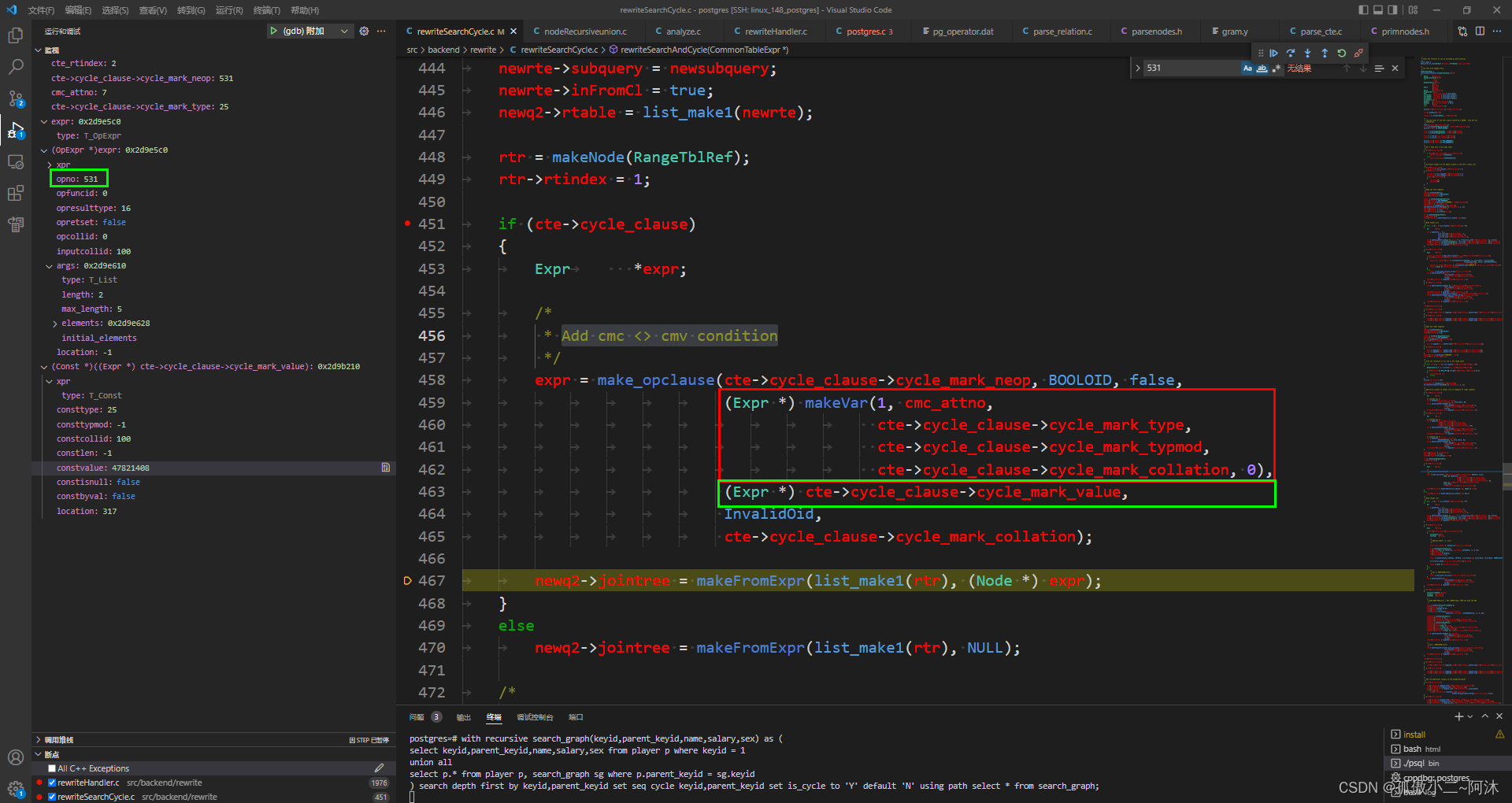
是不是不知道在干嘛?看一下 示例3下面 我改下的那个SQL:
is_cycle = 'N'这里做的就是:
is_cycle <> 'Y'// cte->cycle_clause->cycle_mark_neop = 531 就是text类型的 // (Expr *) cte->cycle_clause->cycle_mark_value 就是 'Y'- Make target list 这里需要更详细的解释一下
1、将
cte->ctecolnames的5列加入到 targetlist里面
2、这里search_clause不为空:
3、对于广度:下面改写RowExpr结构的rowexpr->args为row(seq.depth + 1, keyid, parent_id),之后加入targetlist下面详细解释
4、对于深度:下面改写为ArrayExpr结构体的 即:seq || array[row(keyid, parent_id)]然后makeTargetEntry函数把这个seq列生成,之后加入targetlist下面详细解释
5、注:这里建议大家再回到上面看一下 递归基部分的!
广度 我们在最开始的时候也说了,广度的SQL不好改写,原因是真的写不出来:
// 递归基:row(0, keyid, parent_id)// 递归部分row(seq.depth + 1, keyid, parent_id)这里的seq.depth + 1难以使用SQL进行模拟,但是我们可以通过其他的方式 这里介绍一下:
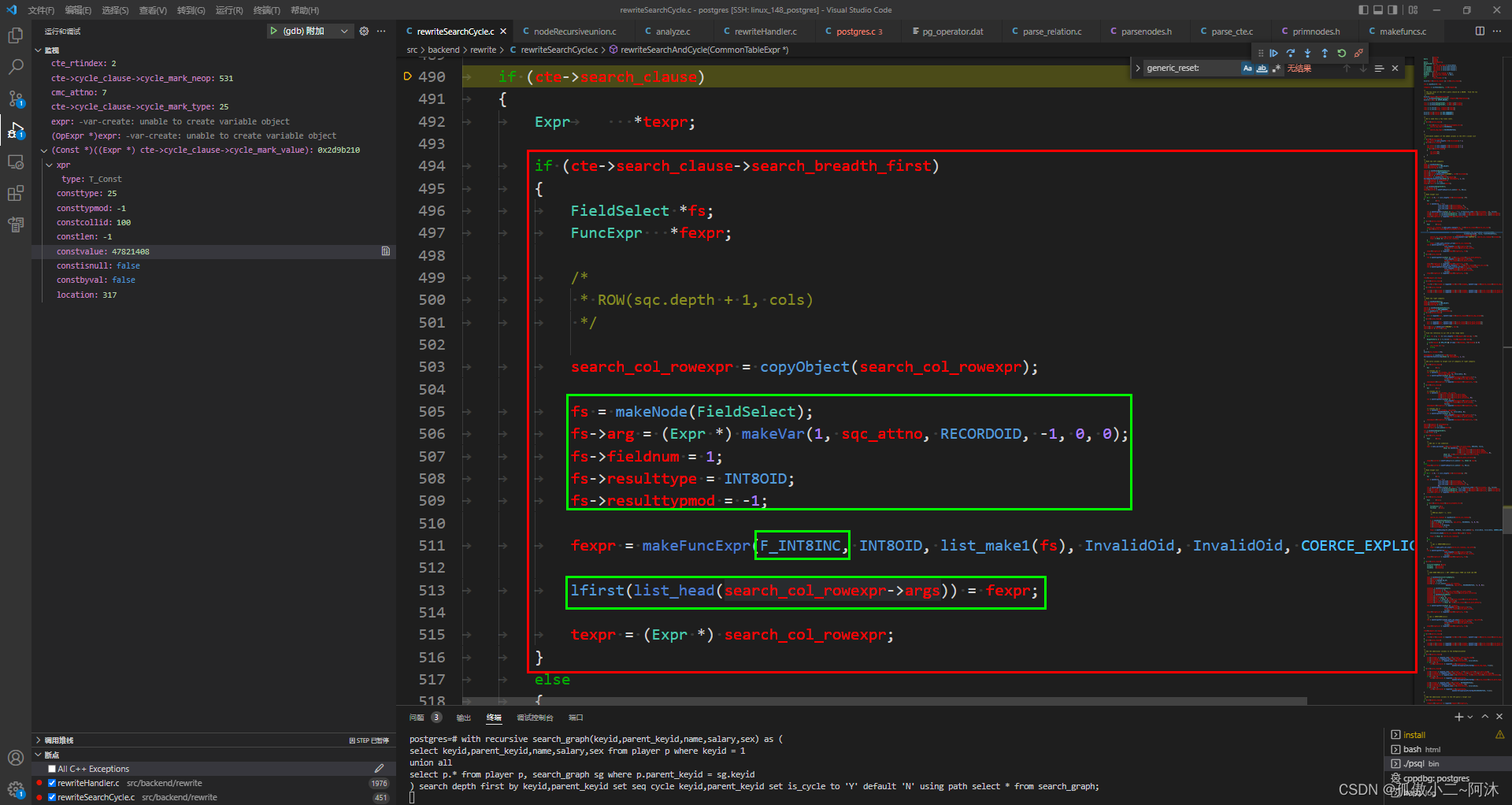
介绍一下:
// src/include/nodes/primnodes.h/* ---------------- * FieldSelect * * FieldSelect represents the operation of extracting one field from a tuple * value. At runtime, the input expression is expected to yield a rowtype * Datum. The specified field number is extracted and returned as a Datum. * ---------------- * FieldSelect 表示从元组值中提取一个字段的操作 * 在运行时,输入表达式预计会产生一个行类型 Datum * 指定的字段编号被提取并作为基准返回 */typedef struct FieldSelect{Exprxpr;Expr *arg;/* input expression */AttrNumberfieldnum;/* attribute number of field to extract */Oidresulttype;/* type of the field (result type of this * node) */int32resulttypmod;/* output typmod (usually -1) */Oidresultcollid;/* OID of collation of the field */} FieldSelect;绿色框1:将得到列seq (列号sqc_attno = 6)的fs->fieldnum = 1的值 作为下面的函数传参
绿色框2:fexpr是一个调用F_INT8INC 即:int8inc。这可是一个自增函数
绿色框3:lfirst(list_head(search_col_rowexpr->args)) = fexpr; 这是在覆盖ROW第一个arg
想必看到这里,大家应该明白了 广度下递归部分,row(seq.depth + 1, keyid, parent_id)的实现了吧!
深度 相比之下,深度就可以使用SQL模拟出来。下面来看一下代码:
else{/* * sqc || ARRAY[ROW(cols)] */texpr = make_path_cat_expr(search_col_rowexpr, sqc_attno);}OK,下面针对广度/深度,调用makeTargetEntry函数生成 seq 列,并放到targetlist
对于cte->cycle_clause,简单多了,如下:
/* * CASE WHEN ROW(cols) = ANY (ARRAY[cpa]) THEN cmv ELSE cmd END */和/* * cpa || ARRAY[ROW(cols)] */这里不再浪费时间,大家去看一下 示例3 !
右子树子查询制作完成:rte2->subquery = newq2;,从此 递归部分 里面的targetList里面就是8个了!
- 把这1+2 = 3列 拼接到 rte2->eref->colnames
- Add the additional columns to the SetOperationStmt
- Add the additional columns to the CTE query’s target list
- Add the additional columns to the CTE’s output columns
OK,下面来看一下经过重写之后的 cte ,如下:
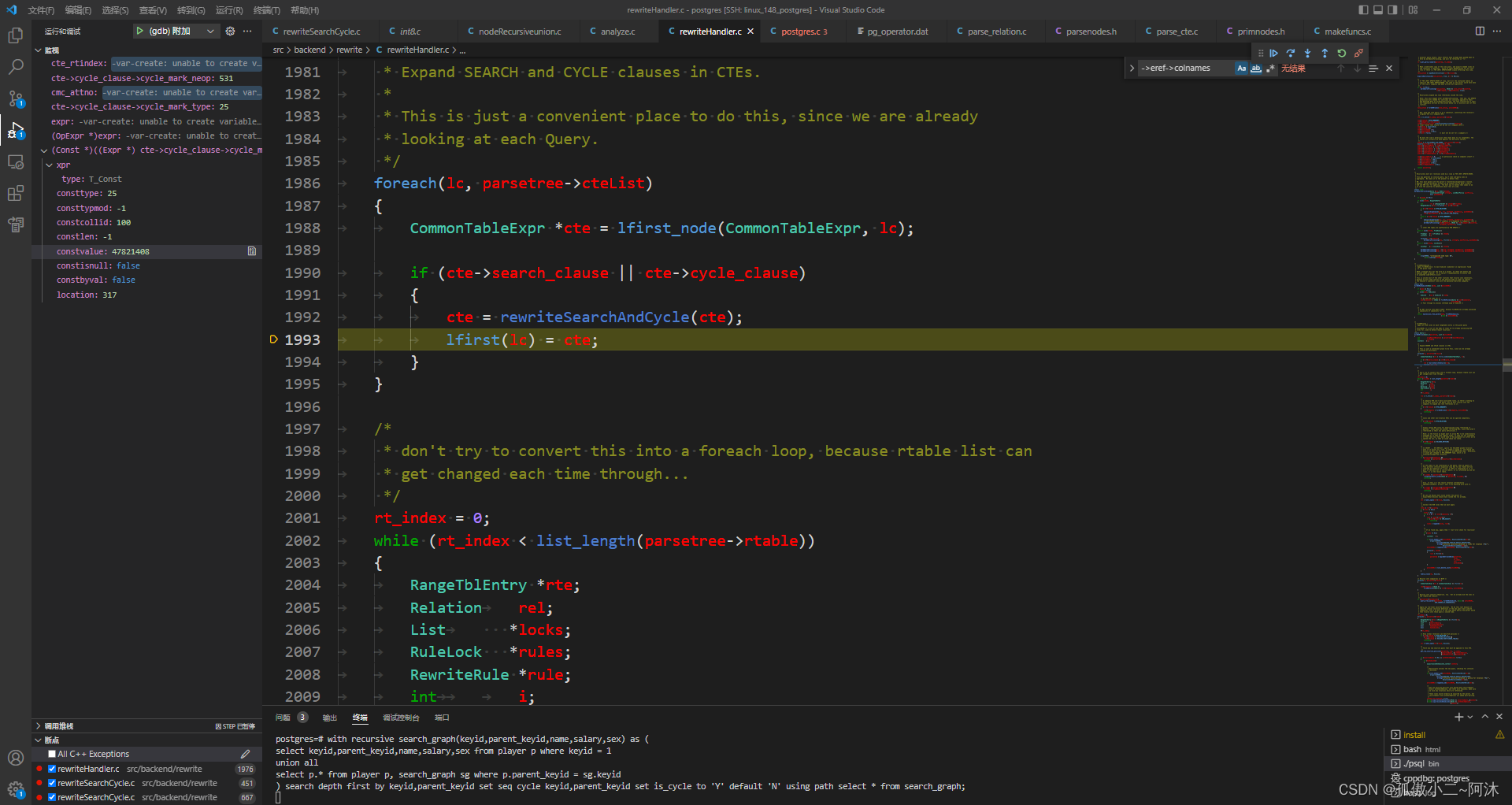

OK,下面来看一下重写的结果:
重写前:

重写后:

再后面,就是函数ExecRecursiveUnion的事情了!
OK,这里以及函数ExecRecursiveUnion就不再解释了 上面已经说的很清楚了(实在是太累了)。截止到现在,PostgreSQL数据库最新版本14下的可递归公共表达式表CTE功能增强源码(SEARCH和CYCLE) 已经全部解读完成。后面就是基于PostgreSQL14开发 Oracle数据库层次查询功能,路漫漫其修远兮 吾将上下而求索!

