使用sharding-jdbc实现水平分库分表和读写分离
使用 Sharding-Jdbc 实现 读写分离和水平分表
服务器准备
- 我们克隆四台虚拟机 【 可参考克隆虚拟机】。ip地址分别为:
- 192.168.17.123
- 192.168.17.124
- 192.168.17.125
- 192.168.17.126
- 在四台机器上分别按照好mysql。【可以现在一台服务器上按照好,然后克隆三个】。
克隆之后需要修改mysql服务的UUID。否则后面搭建主从复制时会出现问题。
# find / -name 'auto.cnf'# vim /data/mysql/auto.cnf[auto]server-uuid=804f2ebe-3a1c-11e8-ab46-000c29133368 # 按照这个16进制格式,修改server-uuid,重启mysql即可uuid可以使用SQL来生成。select uuid();
搭建主从复制
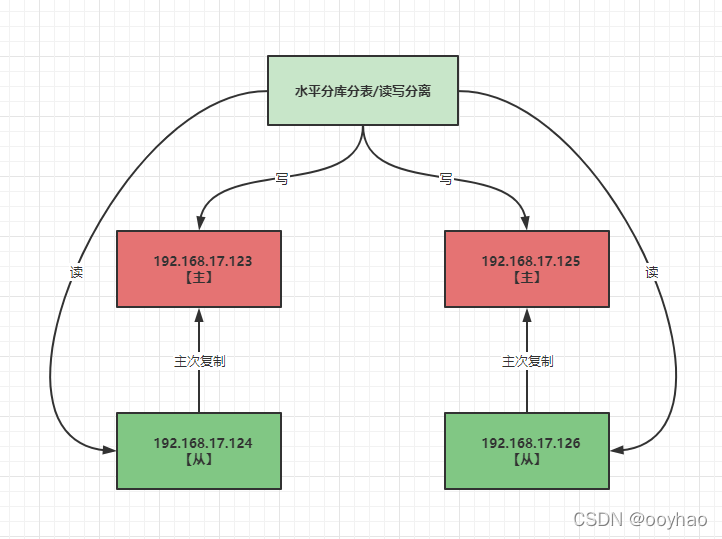
搭建方式参考 主从复制
主机配置
要求主从所有配置项都配置在 /etc/mysql.cnf的【mysqld】节点下。且都是小写字母。
# ========================== [必须] ===============================#[必须] 主服务器唯一IDserver-id=1#[必须]启用二进制日志,指明路径。比如:自己本地的路径/log/mysqlbinlog-bin=ooyhao-bin# ========================== [可选] ===============================#[可选] 0(默认)表示读写(主机),1表示只读(从机)read-only=0#[可选]设置日志文件保留的时长,单位是秒binlog_expire_logs_seconds=6000#[可选]控制单个二进制日志大小。此参数的最大和默认值都是1GBmax_binlog_size=200M#[可选]设置不要复制的数据库binlog-ignore-db=test#[可选]设置需要复制的数据库,默认全部记录。比如:binlog-do-db=atguigu_master_slavebinlog-do-db=需要复制的主数据库名字#[可选]设置binlog格式binlog-format=STATEMENT重启后台mysql服务,使配置生效。systemctl restart mysqld
搭建方式参考 主从复制
主机配置
要求主从所有配置项都配置在 /etc/mysql.cnf的【mysqld】节点下。且都是小写字母。
# ========================== [必须] ===============================#[必须] 主服务器唯一IDserver-id=1#[必须]启用二进制日志,指明路径。比如:自己本地的路径/log/mysqlbinlog-bin=ooyhao-bin# ========================== [可选] ===============================#[可选] 0(默认)表示读写(主机),1表示只读(从机)read-only=0#[可选]设置日志文件保留的时长,单位是秒binlog_expire_logs_seconds=6000#[可选]控制单个二进制日志大小。此参数的最大和默认值都是1GBmax_binlog_size=200M#[可选]设置不要复制的数据库binlog-ignore-db=test#[可选]设置需要复制的数据库,默认全部记录。比如:binlog-do-db=atguigu_master_slavebinlog-do-db=需要复制的主数据库名字#[可选]设置binlog格式binlog-format=STATEMENT重启后台mysql服务,使配置生效。systemctl restart mysqld
从机配置
#[必须]从服务器唯一IDserver-id=2#[可选]启用中继日志relay-log=mysql-relay重启后台mysql服务,使配置生效。systemctl restart mysqld
主机:建立账户并授权
#在主机MySQL里执行授权主从复制的命令#5.5,5.7GRANT REPLICATION SLAVE ON *.* TO 'db_sync'@'从机器数据库IP' IDENTIFIED BY 'abc123'; # MySQL8CREATE USER 'db_sync'@'%' IDENTIFIED BY '123456'; GRANT REPLICATION SLAVE ON *.* TO 'db_sync'@'%'; #此语句必须执行。否则见下面。ALTER USER 'db_sync'@'%' IDENTIFIED WITH mysql_native_password BY '123456';flush privileges;查询master状态
mysql> show master status;+-------------------+----------+----------------------+------------------+-------------------+| File| Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set |+-------------------+----------+----------------------+------------------+-------------------+| ooyhao-bin.000001 | 1136 | atguigu_master_slave | | |+-------------------+----------+----------------------+------------------+-------------------+1 row in set (0.00 sec)记录下File和Position的值
注意:执行完此步骤后不要再操作主服务器MySQL,防止主服务器状态值变化。
从机:配置需要复制的主机
解释
CHANGE MASTER TO MASTER_HOST=‘主机的IP地址’,MASTER_USER=‘主机用户名’,MASTER_PASSWORD=‘主机用户名的密码’,MASTER_LOG_FILE=‘mysql-bin.具体数字’,MASTER_LOG_POS=具体值;
示例
CHANGE MASTER TO MASTER_HOST=‘192.168.17.123’,MASTER_USER=‘db_sync’,MASTER_PASSWORD=‘123456’,MASTER_LOG_FILE=‘ooyhao-bin.000001’,MASTER_LOG_POS=1136;
mysql> CHANGE MASTER TO MASTER_HOST='192.168.17.123',MASTER_USER='slave1',MASTER_PASSWORD='123456',MASTER_LOG_FILE='ooyhao-bin.000001',MASTER_LOG_POS=1136; Query OK, 0 rows affected, 8 warnings (0.01 sec)启动slave
mysql> START SLAVE;Query OK, 0 rows affected, 1 warning (0.00 sec)在从节点上执行SHOW SLAVE STATUS. 如果出现 Slave_IO_Running: Yes和 Slave_SQL_Running: Yes。表示启动成功。
项目搭建
需求说明
按照user_id 奇偶进行分库。按照order_id奇偶计算分表。
创建springboot项目
使用 springboot 启动器 创建springboot项目
导入依赖
<dependencies> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter</artifactId> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-test</artifactId> <scope>test</scope> </dependency> <dependency> <groupId>org.apache.shardingsphere</groupId> <artifactId>sharding-jdbc-spring-boot-starter</artifactId> <version>4.0.0-RC1</version> </dependency> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> </dependency> <dependency> <groupId>com.alibaba</groupId> <artifactId>druid-spring-boot-starter</artifactId> <version>1.1.23</version> </dependency> <dependency> <groupId>com.baomidou</groupId> <artifactId>mybatis-plus-boot-starter</artifactId> <version>3.3.0</version> </dependency> <dependency> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId> </dependency> </dependencies>创建数据库和表
在两个主库中创建数据库和表,从库会自动同步;
create database order_db; use order_db; create table tb_order_0(order_id bigint(20) primary key not null,sku_name varchar(128) not null,user_id bigint(20) ); create table tb_order_1(order_id bigint(20) primary key not null,sku_name varchar(128) not null,user_id bigint(20) );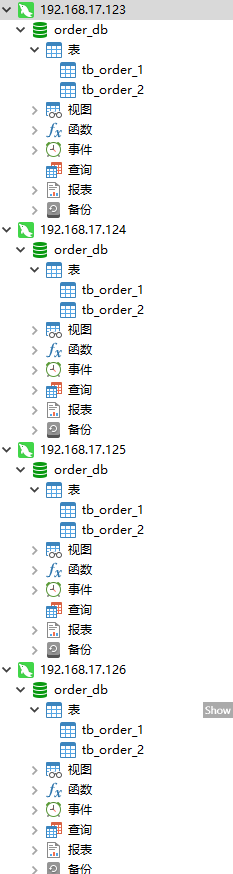
配置主从复制和读写分离
在【application.properties】中配置
# 允许beanDefinition覆盖 [一个实体类对应两张表,覆盖]spring.main.allow-bean-definition-overriding=true# ======================================= 数据源配置 ======================================# 配置数据源的名称 主库为m1,m2 从库为 s1,s2spring.shardingsphere.datasource.names=m0,m1,s0,s1# 配置数据源具体内容 包含连接池、驱动、地址、用户名和密码# 配置第 1 个主库数据源spring.shardingsphere.datasource.m0.type=com.alibaba.druid.pool.DruidDataSourcespring.shardingsphere.datasource.m0.driver-class-name=com.mysql.cj.jdbc.Driverspring.shardingsphere.datasource.m0.url=jdbc:mysql://192.168.17.123:3306/order_db?serverTimezone=GMT%2B8spring.shardingsphere.datasource.m0.username=rootspring.shardingsphere.datasource.m0.password=root# 配置第 2 个主库数据源spring.shardingsphere.datasource.s0.type=com.alibaba.druid.pool.DruidDataSourcespring.shardingsphere.datasource.s0.driver-class-name=com.mysql.cj.jdbc.Driverspring.shardingsphere.datasource.s0.url=jdbc:mysql://192.168.17.124:3306/order_db?serverTimezone=GMT%2B8spring.shardingsphere.datasource.s0.username=rootspring.shardingsphere.datasource.s0.password=root# 配置第 1 个从库数据源spring.shardingsphere.datasource.m1.type=com.alibaba.druid.pool.DruidDataSourcespring.shardingsphere.datasource.m1.driver-class-name=com.mysql.cj.jdbc.Driverspring.shardingsphere.datasource.m1.url=jdbc:mysql://192.168.17.125:3306/order_db?serverTimezone=GMT%2B8spring.shardingsphere.datasource.m1.username=rootspring.shardingsphere.datasource.m1.password=root# 配置第 2 个从库数据源spring.shardingsphere.datasource.s1.type=com.alibaba.druid.pool.DruidDataSourcespring.shardingsphere.datasource.s1.driver-class-name=com.mysql.cj.jdbc.Driverspring.shardingsphere.datasource.s1.url=jdbc:mysql://192.168.17.126:3306/order_db?serverTimezone=GMT%2B8spring.shardingsphere.datasource.s1.username=rootspring.shardingsphere.datasource.s1.password=root# ====================================== 配置读写分离 ======================================# 配置主从服务 ds0为 user_dbspring.shardingsphere.sharding.master-slave-rules.ds0.master-data-source-name=m0spring.shardingsphere.sharding.master-slave-rules.ds0.slave-data-source-names=s0spring.shardingsphere.sharding.master-slave-rules.ds1.master-data-source-name=m1spring.shardingsphere.sharding.master-slave-rules.ds1.slave-data-source-names=s1# ====================================== 分库分表策略 ======================================# 按照 user_id 奇偶进行分库。按照order_id奇偶计算分表。# 分表策略# 表达式 `ds_$->{0..1}`枚举的数据源为读写分离配置的逻辑数据源名称# 指定数据库分片规则,指定数据库表的分片规则spring.shardingsphere.sharding.tables.order.actual-data-nodes=ds$->{0..1}.tb_order_$->{0..1}spring.shardingsphere.sharding.tables.order.key-generator.column=order_id# 分布式序列算法配置spring.shardingsphere.sharding.tables.order.key-generator.type=SNOWFLAKE# ===================================== 分库策略 ==============================================# 指定表的分库策略 [分库字段为 user_id] user_id 为偶数则放到m0库,为奇数则放到m1库spring.shardingsphere.sharding.tables.order.database-strategy.inline.sharding-column=user_idspring.shardingsphere.sharding.tables.order.database-strategy.inline.algorithm-expression=ds$->{user_id % 2}# 默认的分库策略#spring.shardingsphere.sharding.default-database-strategy.inline.sharding-column=user_id#spring.shardingsphere.sharding.default-database-strategy.inline.algorithm-expression=ds$->{user_id % 2}# ===================================== 分表策略 ==============================================# 表达式 `ds_$->{user_id % 2}` 枚举的数据源为读写分离配置的逻辑数据源名称spring.shardingsphere.sharding.tables.order.table-strategy.inline.sharding-column=order_idspring.shardingsphere.sharding.tables.order.table-strategy.inline.algorithm-expression=tb_order_$->{order_id % 2}# 打开sql输出日志spring.shardingsphere.props.sql.show=trueMapper和Entity
@Datapublic class Order { private Long orderId; private String skuName; private Long userId;}@Mapperpublic interface OrderMapper extends BaseMapper<Order> {}测试
@SpringBootTestclass ShardingJdbcReadWriteApplicationTests { @Autowired private OrderMapper orderMapper; @Test void addOrder() { for (long i = 0; i < 1000; i++) { Order order = new Order(); order.setUserId((long) new Random().nextInt(20)); order.setSkuName("sku-i-"+i); orderMapper.insert(order); } }}结果:192.168.17.124是192.168.17.123的从节点,192.168.17.126是192.168.17.125的从节点。
192.168.17.123
mysql> select count(*) from tb_order_0;+----------+| count(*) |+----------+| 256 |+----------+1 row in set (0.11 sec)mysql> select count(*) from tb_order_1;+----------+| count(*) |+----------+| 258 |+----------+1 row in set (0.06 sec)192.168.17.124
mysql> select count(*) from tb_order_0;+----------+| count(*) |+----------+| 256 |+----------+1 row in set (0.08 sec)mysql> select count(*) from tb_order_1;+----------+| count(*) |+----------+| 258 |+----------+1 row in set (0.06 sec)192.168.17.125
mysql> select count(*) from tb_order_0;+----------+| count(*) |+----------+| 244 |+----------+1 row in set (0.06 sec)mysql> select count(*) from tb_order_1;+----------+| count(*) |+----------+| 242 |+----------+1 row in set (0.08 sec)192.168.17.126
mysql> select count(*) from tb_order_0;+----------+| count(*) |+----------+| 244 |+----------+1 row in set (0.09 sec)mysql> select count(*) from tb_order_1;+----------+| count(*) |+----------+| 242 |+----------+1 row in set (0.08 sec)
