数据结构(一)
文章目录
- 前言
- ❤️线性表
- ❤️散列
-
- 🤍哈希表
-
- ✍️哈希表说明
- ✍️哈希表的操作
- ✍️哈希表应用
- 🤍位图
-
- ✍️位图的说明
- ✍️位图的应用
前言
在大学的时候大家就学过数据结构和算法,当时学的时候感觉挺难的,到了工作的时候可能发现一直在做CURD操作,感觉数据结构和算法用处不大。其实你想错了,数据结构和算法是一个优秀代码的基础,尤其对于大数据量处理方面,CURD大家都会,写出来的代码的好坏往往是依赖于那些像数据结构和算法、设计模式、代码规范等基础,这也是互联网公司面试的一大重点。本文就简单的介绍一下常用的数据结构。
❤️线性表
🤍数组
数组是开发中最常见的数据结构了,它是一些相同数据类型的数据组成的有序集合,当然这个有序指的是存放顺序。
✍️数组的操作
🔊 数组的读取
数组在内存空间中是由一组连续的内存空间来存放,例如我们定义一个长度为5的int数组。

大家都知道数组有一个优点就是随机访问的速度快,看了数组的内存存放规则应该就清楚为啥了。只要知道数组的开始地址,因为数组中存放的数据类型一样,所以占用的空间一样,地址可以直接计算出来:
a[i]的地址 = 数组的开始地址+ 数组中变量类型占用的空间 * 下标i
刚开始学习数组的时候大家可能有个疑问为啥数组的下标是从0开始的,看了上面的公式大家应该知道为啥了吧。
🔊 数组的插入
数组中插入数据分为两种情况
1️⃣ 数组中的空间没有满
当数组中的空间没有放满的时候,如果尾部插入数据就直接从数据的尾部节点存放数据就可以了;如果想在数组的中间插入数据的时候,需要将数组的后半部分数据往后移动一位然后再将数据插入数组中。
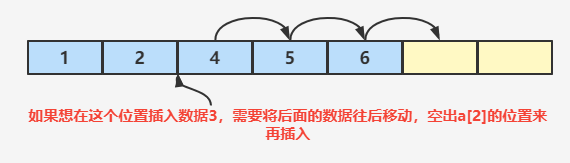
2️⃣ 数组已经存满了
如果数组中的空间已经满了,如果想要往数组里面插入数据就需要再找一个两倍于当前空间的连续空间来作为新的数组空间。
找到连续空间之后将原来的数据全部复制到新的空间中去,然后执行上面的空间没满的时候插入数据操作
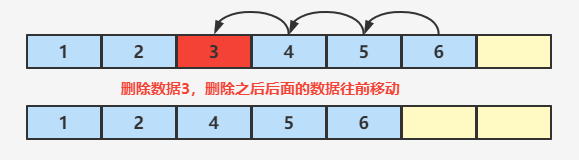
🔊 数组的删除
数组的删除挺简单的,因为不涉及到内存的开辟,直接删除想要删除的数据,然后后面的数据往前移动就行了。
✍️数组总结
根据上面的分析可以得到我们平常记的数组优缺点:
1. 根据数组读取操作的分析得到数组的优点,随机访问的速度比较快。
2. 根据插入和删除操作的分析得到数组的缺点,随机插入和删除的性能比较低,涉及到数据的迁移。
🤍链表
链表是由一系列数据节点通过指针指向组成的有序数据集合,当然这个有序也是指的存放顺序。
✍️链表说明
链表在内存空间中的存放可以是不连续的,它是通过节点中指针的指向来记录下一个元素的。
常见的链表有单向链表,双向链表和循环链表,下面用一个双向链表来分析下它的具体存放逻辑。
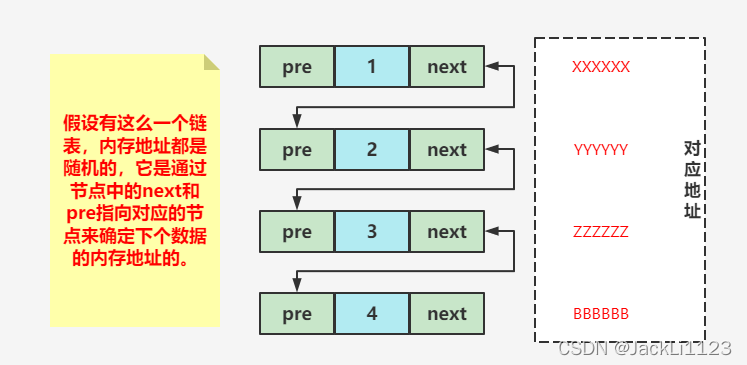
所以链表有一个好处,可以有效的利用零散的内存碎片空间。
✍️链表的操作
🔊 链表的查找
根据上面链表在内存空间的存放方式,因为其节点存放的空间地址是随机的,我们无法通过计算直接获取到某个节点的物理地址,所以我们必须从开始节点一个一个的遍历到需要的节点来读取。
🔊 链表的插入
1️⃣ 头尾插入
链表的头部插入和尾部插入比较简单,它是通过指针指向来连接数据的,头部插入和尾部插入就可以直接在头部结点的pre或尾部节点的next挂上对应的数据就行,不涉及到内存的扩充迁移操作。
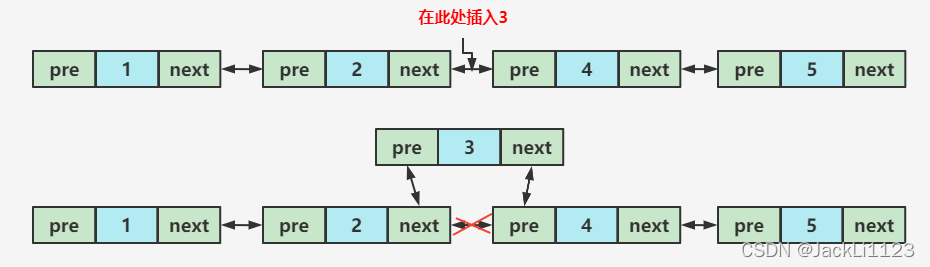
2️⃣ 中间插入
链表中间插入数据只需要在对应的节点断开指针连接,然后分别将上一节点和下一节点的引用与新的数据建立指向关系就行了,不涉及到内存的扩充迁移操作。
🔊 链表的删除
链表中头部节点和尾部节点的删除比较简单,直接把数据移除,然后将尾节点指向NULL就行了。
链表中间节点的删除只需要将中间节点的前后指向断开,然后重新建立剩下数据的节点指向就可以了。

✍️链表总结
根据上面的分析可以得到我们平常记的链表优缺点:
1. 链表的插入和删除操作不涉及到扩容和数据迁移,所以操作比较快。
2.链表使用的内存空间可以是随机不连续的,所以对碎片内存空间利用上要优于数组。
3.因为链表的内存空间不连续没有规律,所以随机查找需要从头遍历到下标位置,效率很低
🤍栈
栈是线性表里的一种逻辑数据结构,遵循着先入后出的原则。
逻辑数据结构的意思是这不是物理内存上的意义,而是一种逻辑表达方式。而数组和链表是实实在在的物理内存上面的操作,逻辑数据结构是在物理数据结构的基础上增加规则来实现的。可以理解为物理数据结构就是人,制定了一系列法律之后遵守法律就变成了逻辑数据结构。
✍️栈的说明
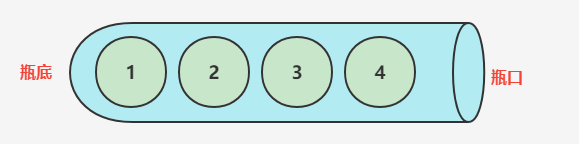
说到栈的逻辑大家通常想到的是一个圆柱体的桶里面放小球的原理,由于桶是单出口的,所以先放进去的最后拿出来。
✍️栈的操作
栈的操作只有入栈和出栈,没有啥随机操作,这是在逻辑规则上定死了的。而且操作上面比较简单,入栈就是在瓶口一个一个的往里面放东西,出栈就是从瓶口一个一个的往外面倒出来东西,没有啥半截中把数据拿出来或者换了的操作,除非把瓶子给摔碎了。
因为逻辑数据结构是由物理数据结构作为基础指定规则实现的,所以栈是否需要扩容位移是根据实现栈使用的物理数据结构的特性来决定的。
✍️栈的应用
栈的应用常见的有浏览器页面的前进后退缓存,我们点后退的时候只能退回到上一个页面;函数方法的调用,函数方法写的时候一层一层的嵌套调用都会先将一个临时变量入栈,当函数方法执行完成之后再对应的出栈,保证函数的执行不错乱。
🤍队列
队列也是一种逻辑上的线性数据结构,队列的规则是先入先出。
✍️队列的说明
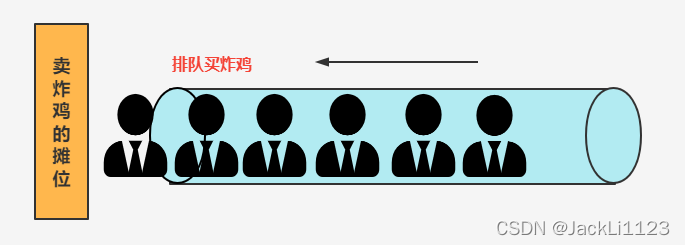
我们在说队列的时候常常用来打比方的就是排队,先排队的先得到执行,遵循着先入先入的规则。
✍️队列的操作
队列的操作分为入队和出队,操作也是比较简单的,入队就直接在队伍的尾部直接往里面继续放就行,出队就直接从队伍的头部一直往外出就行了,同样没有中间数据操作。
队列是否需要扩容位移同样是根据实现栈使用的物理数据结构的特性来决定的。
✍️队列的应用
队列数据结构在实际代码中的应用也是比较广泛的,例如常用的消息队列、资源池(资源池时通过线程池实现的,而线程池是使用队里存放的)等。
❤️散列
🤍哈希表
✍️哈希表说明
哈希表HashTable大家应该不陌生了,这是通过键值对来存放的,在Java集合中就有我们常用的HashTable。哈希表是通过一个唯一主键和实际数据的一一对应关系来表示一组数据的。
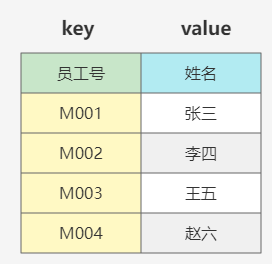
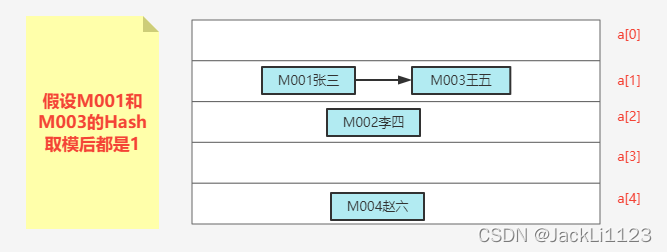
Hashtable的数据结构其本质是通过数组来实现的,使用Key的Hash值作为数组中的下标,对应下标位置存放这当前Key对应的数据。那么上面的数据实际在数组中的存放是这样的。

当然如果Hash值冲突了,两组或多组数据最后计算出来的下标一样的,那怎么办呢?一般是这样处理的,咱数组中的数据存放链表,链表的Node节点上面不仅记录了具体的值和指向,还记录了对应的key,如果hash冲突了就在链表上面一直加数据。因为数组中的数据类型是一样的,所以整个数组中存放的都是链表。
✍️哈希表的操作
哈希表最终采用的底层数据结构是数组和链表,所以实际操作还是和数组跟链表一样,只是说一下表层的逻辑操作。
🔊 哈希表的查找
哈希表的查找还是比较简单的,一般是通过Key来查找value。首先先获取Key对应的Hash运算转换为数组的下标,去对应的数组下标获取数据,对应下标位置的数据是链表,所以需要再遍历链表对比如果Key相等的数据返回。
🔊 哈希表的插入
哈希表的插入操作跟读取操作类似,先通过Key进行Hash计算转换为数组的下标,将值存放到对应的数据下标位置,下标位置是链表,如果出现了哈希碰撞,其实不管出现不出现哈希碰撞都是按照链表的存放规则来存放的。
在插入的数据越来越多的时候产生的Hash碰撞就越来越多,导致链表的长度越来越长,然后查询最终变成了遍历链表操作,查询效率就变差了。所以在哈希表中都有个扩容因子,数组中实际存放的数据的长度=数组的最大长度 * 扩容因子之后就进行数组的扩容。因为哈希表的用途主要在于查找数据,尽量保持较多的数据直接存放在数组上面,减少存放链表的长度的。
🔊 哈希表的删除
哈希表的删除就不用说了,同样先进行哈希表的查找找到对应的数据之后按照对应的存放结构规则进行删除。
✍️哈希表应用
哈希表的用途也有很多,常见的Java中的HashTable就不用说了吧,连名字都没有该就叫哈希表;常用的缓存数据库Redis中的字典;用来防止缓存穿透的布隆过滤器其实也算是使用的哈希表的思想来实现的。
🤍位图
位图对于大多数初级程序员来说接触的比较少,它是用二进制的方式来表达一组数据,姑且算是Hash的一种变种吧。
✍️位图的说明
位图使用二进制bit来标记表示一个元素,位图在散列里面的key就是元素本身。位图看起来可能比较绕,咱用一个图来表示一下。
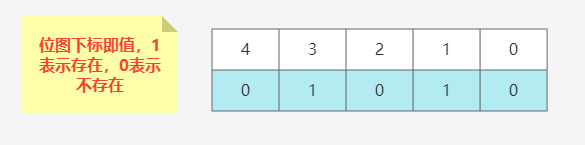
看上面的图,位图因为二进制只有0和1,如果表达一个数组由数组的最大值表示二进制的长度,对应位置为1表示数据存在,为0表示不存在。上面的图就是int类型的数组 [1,3]。
可以看到位图使用的是二进制,占用的空间小。但是位图如果最大值很长,而且很散列的数据,同样采用的Hash值来计算位图的下标,也会存在Hash冲突问题,所以一般使用的时候采用多个位图来构建一个算法,通过多个位图的多次不同下标计算校验是否存在。
✍️位图的应用
常见的位图的使用那就是用来防止缓存穿透的布隆过滤器,一般是这样实现的假设整了3组位图,三种算法来计算下标,每个数据的ID都会根据算法修改不同位图上面的标志位,传入ID后都先通过位图确定当前ID是否存在再进行查询。

