【Java---数据结构】排序算法
目录
一、排序
🍓概念
🍓稳定性
二、直接插入排序
⏳排序思路
💦动态图
🍓性能分析
三、希尔排序
⏳排序原理
💦动态图
🍓性能分析
四、选择排序
⏳排序思路
💦动态图
🍓性能分析
五、堆排序
💦动态图
🍓性能分析
六、冒泡排序
⏳排序原理
💦动态图
🍓性能分析
七、快速排序
⏳排序原理
💦挖坑法动态图(一趟排序)
💦Hoare 法动态图(一趟排序)
⭐快速排序优化
🍓性能分析
八、归并排序
🎄合并两个有序数组
⏳解题思路
🎄归并排序
⏳排序原理
💦动态图
⏳归并排序递归思路
⏳归并排序非递归思路
🍓性能分析
一、排序
🍓概念
- 排序就是使一串记录,按照其中的某个或某些关键字的大小,递增或递减的排列起来的操作。
- 平时如果提到排序,通常指的是排升序(非降序)。
- 通常意义上的排序,都是指的原地排序(in place sort)。
🍓稳定性
两个相等的数据,如果经过排序后,排序算法能保证其相对位置不发生变化,则称该算法是具备稳定性的排序算法。
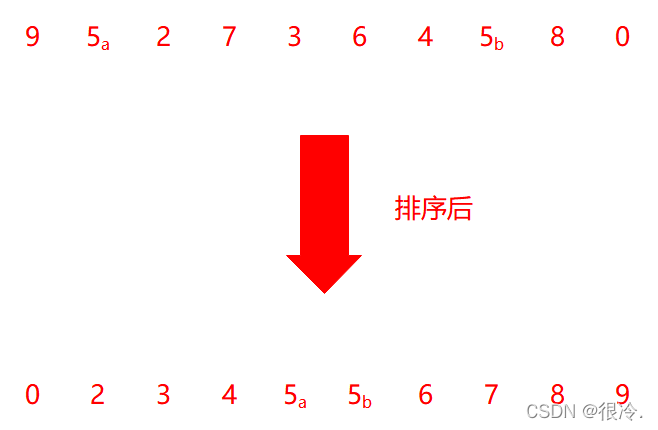
- 判断一个排序是不是稳定排序:如果一个排序算法中是进行“跳跃式”的元素交换(或插入)进行排序,则该排序很可能(不是一定,本质还是要看相同元素值的相对位置是否改变)是不稳定的。
- 对于一种稳定的排序算法,可以实现为不稳定的排序,但是对于一个不稳定的排序算法,是无法实现成稳定的排序。
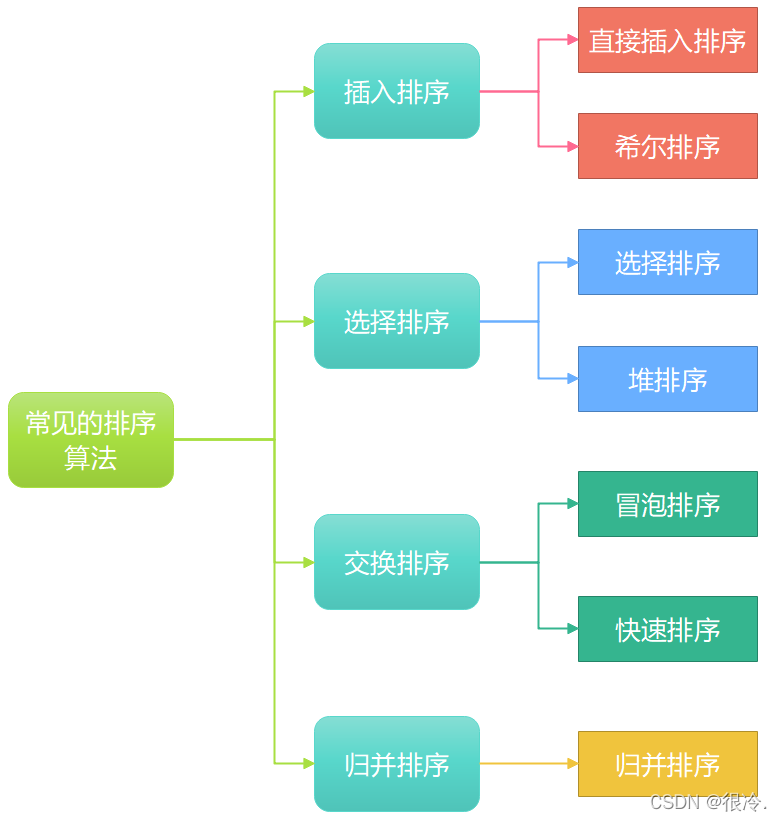
⭐常见的排序算法总览
二、直接插入排序
⏳排序思路
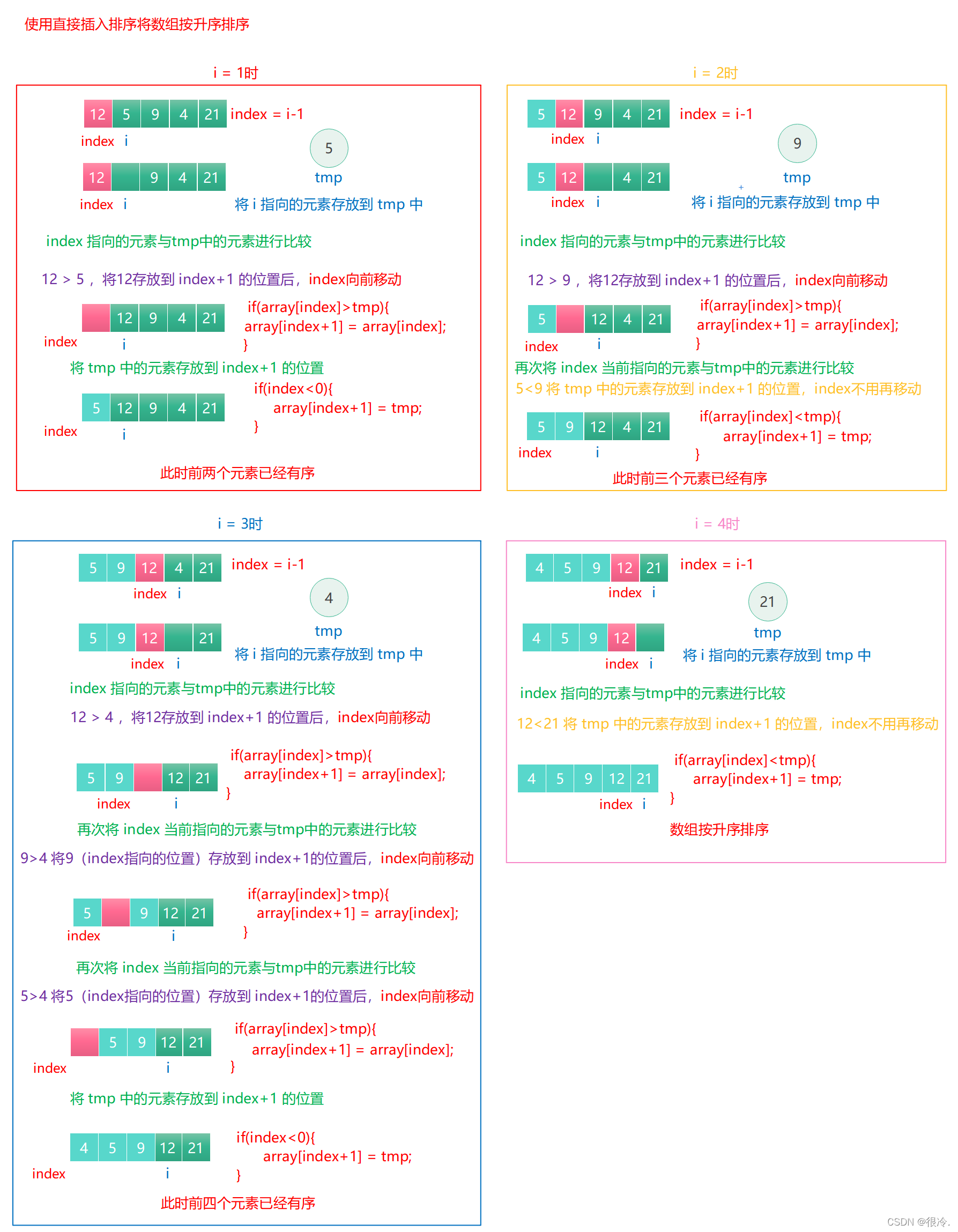
- 排序数组中的数据。将第一个元素使用 index 标记,从第二个元素开始使用变量 i 遍历剩下的数据。index = i-1;
- 将变量 i 指向的元素存放到临时变量 tmp 中,如果 index 标记的元素比 tmp 中存放的元素大,那么就将 index 标记的元素存放到 index+1 的位置处,然后将 index 向前移动(index--)。
- 将tmp中的元素存放到移动后,index+1的位置。
- 如果index <0 或 index当前指向的元素比 tmp 中的元素小,那么直接将tmp中的元素存放到 index+1的位置,index不用再移动。
- 将所有元素完成插入后,数组按升序排列,如果要降序,则插入的时候要把大的元素移动到数组前面,思路是一样的。
💦动态图
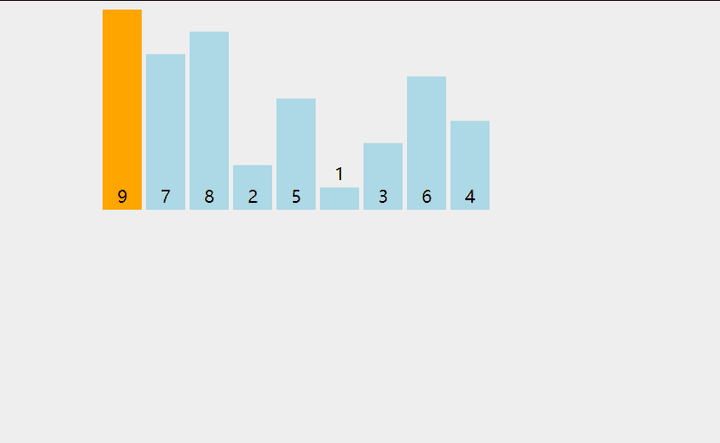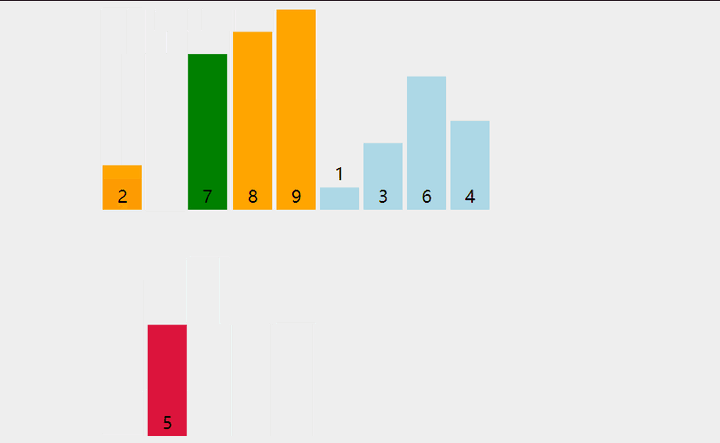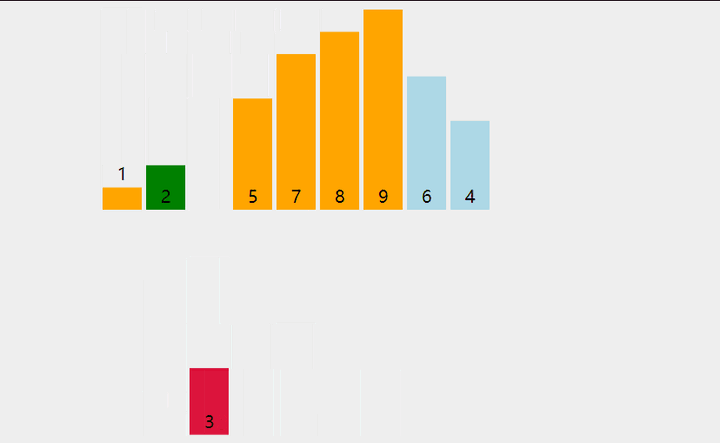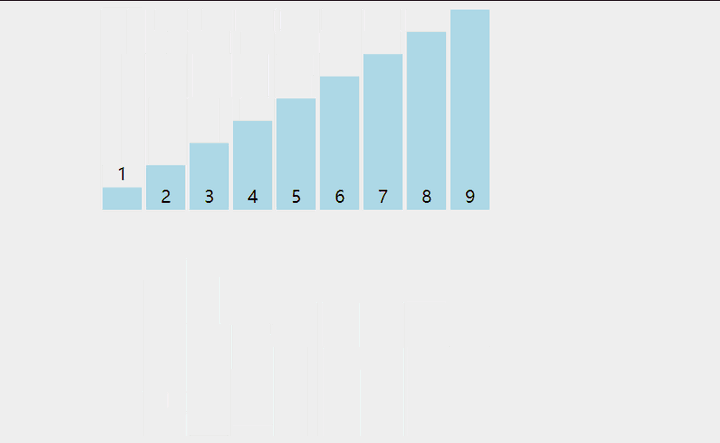
🛫排序过程(升序)
🌊代码实现
/ * 时间复杂度:O(N^2) * 最好的情况是O(N):对于直接插入排序来说,最好的情况是数据有序 * 对于直接插入排序来说,数据越有序,排序速度越快。 * 空间复杂度:O(1) * 稳定性:稳定的 * @param array */public static void insertSort(int[] array){ for (int i = 1; i 0 ; index--) { if(array[index]>tmp){ array[index+1] = array[index]; }else{ break; } } array[index+1] = tmp; }}🍓性能分析

🍎直接插入排序有一个特点:数据越接近有序,排序速度越快,时间效率越高。
三、希尔排序
⭐希尔排序法又称缩小增量法。
⏳排序原理
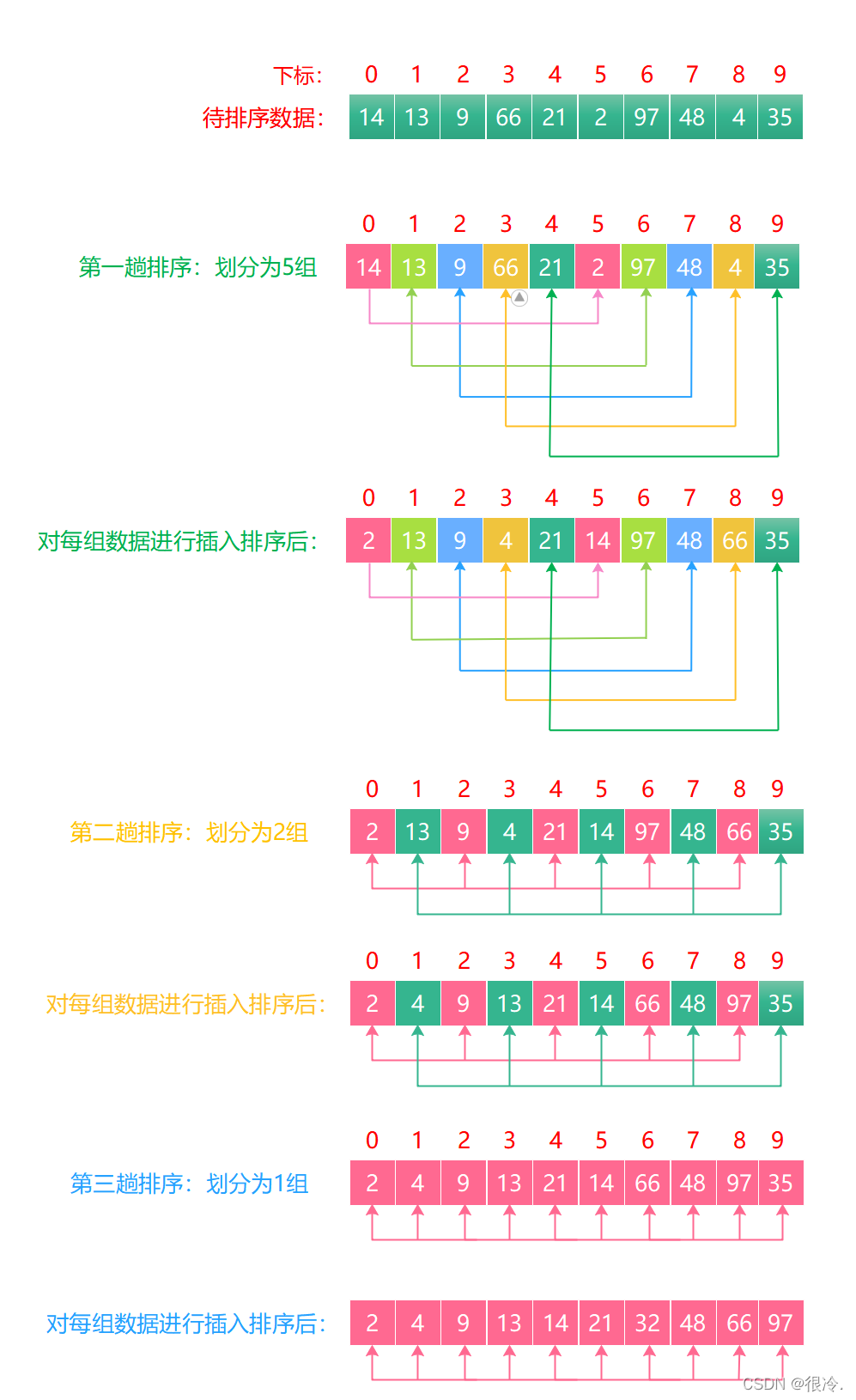
希尔排序法的基本思想是:
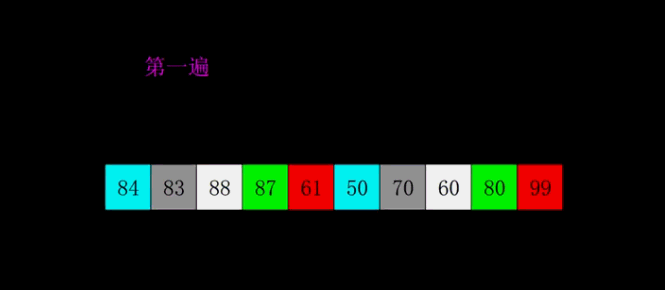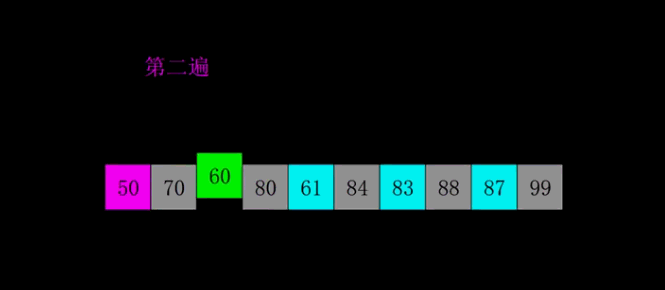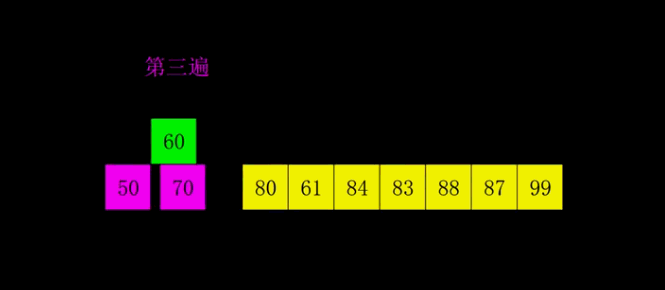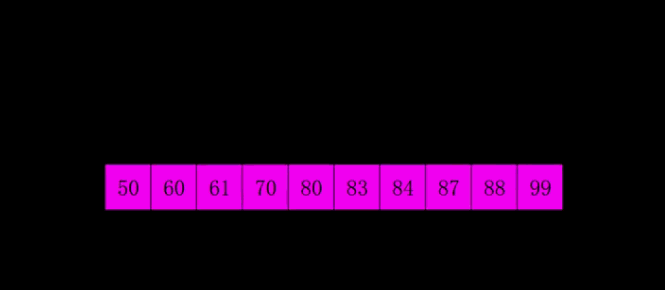
- 先选定一个整数 n,把待排序文件中所有记录分成 n 个组,所有距离为 n 的数据分在同一个组内,并对每一组内的数据进行排序。然后重复上述分组和排序的工作。当到达 n =1时,所有数据将在同一个组内进行最后一次排序。
- 希尔排序是对直接插入排序的优化。
- 当 n > 1时都是预排序,目的是让数组更接近于有序。当 n == 1时,数组已经接近有序的了,这样就会很快。这样整体而言,可以达到优化的效果。
💦动态图
🛫排序过程
🌊代码实现
/ * 直接插入排序 * @param array 待排序序列 * @param gap 分的组数 */public static void shell(int[] array,int gap){ for (int i = 1; i =0 ; j-=gap) { if(array[j]>tmp){ array[j+gap] = array[j]; }else{ break; } } array[j+gap] = tmp; }}public static void shellSort(int[] array){ int gap = array.length; while(gap>1){ shell(array,gap); gap /= 2; } shell(array,1); //对最后一组进行排序}🍓性能分析

🍎希尔排序是直接插入排序的一种优化。
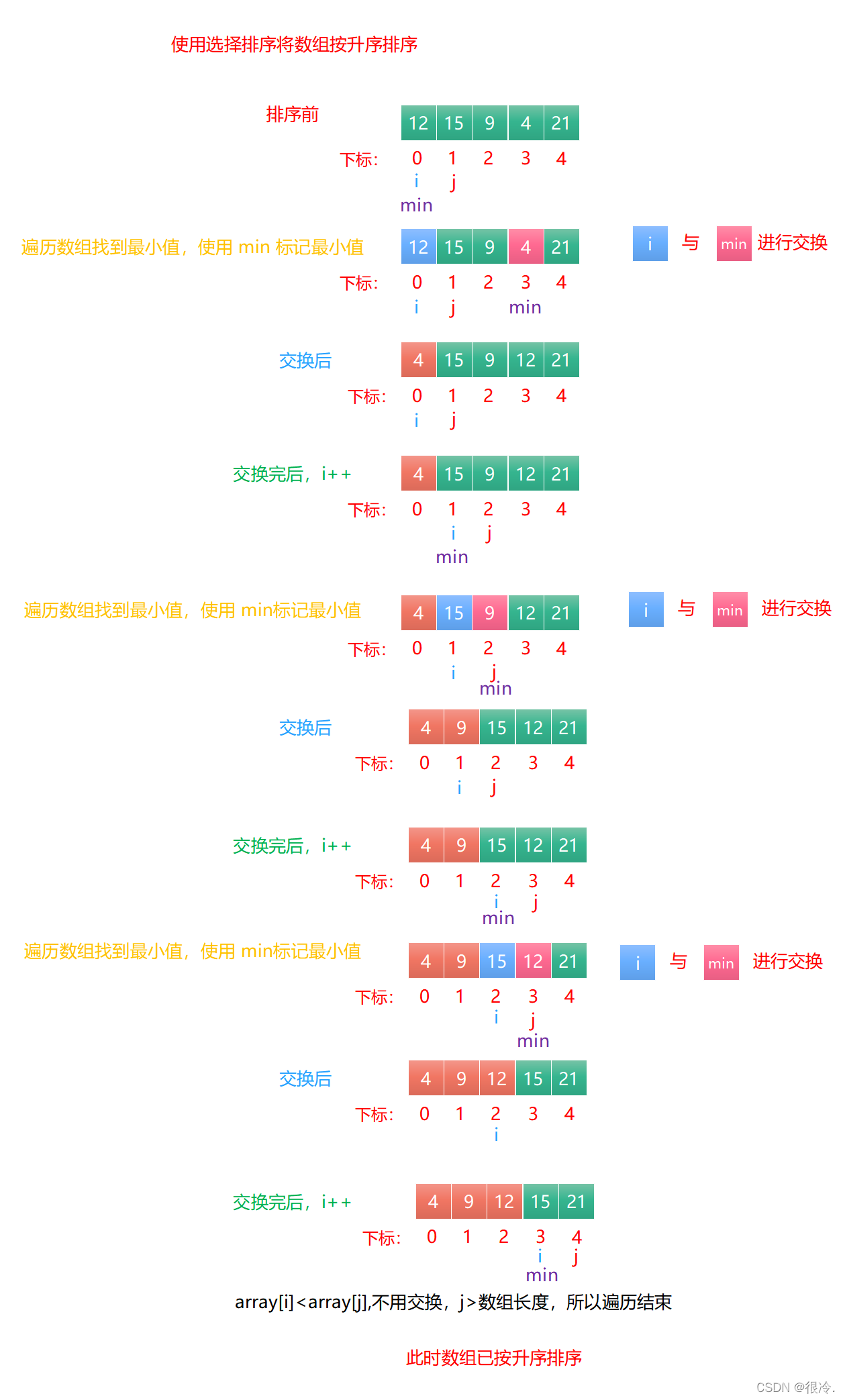
四、选择排序
⏳排序思路
- 排序数组中的数据。使用变量 i 从0下标开始遍历数组,使用变量 j 从 i+1 下标处遍历数组。
- i 下标的值与 j 下标的值进行比较,如果 i 下标的值大于 j 下标的值,则进行交换。
- 优化:找到数组中的最小值,使用 minIndex 标记最小值的下标,然后将最小值与 i 当前指向的元素交换。(升序)
- 如果是降序,遍历数组时找到数组中最大值,然后与 i 当前指向的元素交换。
- 每一次从无序区间选出最大(或最小)的一个元素,存放在无序区间的最后(或最前),直到全部待排序的数据元素排完。
💦动态图
🛫排序过程
🌊代码实现
/ * 选择排序 * 时间复杂度:O(N^2) * 空间复杂度:O(1) * 稳定性:不稳定 * @param array 待排序序列 */public static void selectSort(int[] array){ for(int i=0;i<array.length;i++){ int minIndex = i; for(int j=i+1;j<array.length;j++){ //找到最小值的下标 if(array[j]<array[minIndex]){ minIndex = j; } } int tmp = array[i]; array[i] = array[minIndex]; array[minIndex] = tmp; }}🍓性能分析

五、堆排序
⭐排序原理:升序需要创建大根堆,降序需要创建小根堆。
💦动态图
- 堆排序在优先级队列(堆)中已经介绍过了,如果想了解的朋友可以阅读前面的文章,这里就不再写具体思路与排序过程。
🚀文章导航:【Java---数据结构】优先级队列 PriorityQueue(堆)
🌊代码实现
/ * 时间复杂度:O(N*log N) * 空间复杂度:O(1) * 稳定性:不稳定 * @param array */public static void heapSort(int[] array){ //建堆,时间复杂度:O(N) createHeap(array); int end = array.length-1; //交换、调整。时间复杂度O(N*log N) while (end>0){ swap(array,0,end); shiftDown(array,0,end); end--; }}public static void swap(int[] array,int index1,int index2){ int tmp = array[index1]; array[index1] = array[index2]; array[index2] = tmp;}//向下调整public static void shiftDown(int[] array,int parent,int len){ int child = 2*parent+1; //左孩子下标 while (child<len){ if(child+1<len && array[child]array[parent]){ swap(array,child,parent); parent = child; child = 2*parent+1; }else{ break; } }}//创建大根堆public static void createHeap(int[] array){ for (int parent = (array.length-1-1)/2; parent >=0; parent--) { shiftDown(array,parent,array.length); }}🍓性能分析

六、冒泡排序
⏳排序原理
- 从第二个元素开始,将该元素与前一个元素进行比较,如果前一个元素比较大,则交换。直到将最大的元素放到最后,这一过程称为一趟冒泡排序。
- 每进行一趟冒泡排序,就会缩小一次右侧区间,因为每进行一趟冒泡排序就有一个元素有序。
💦动态图
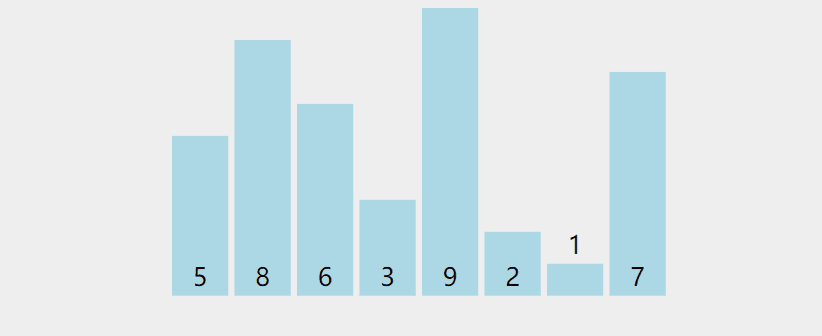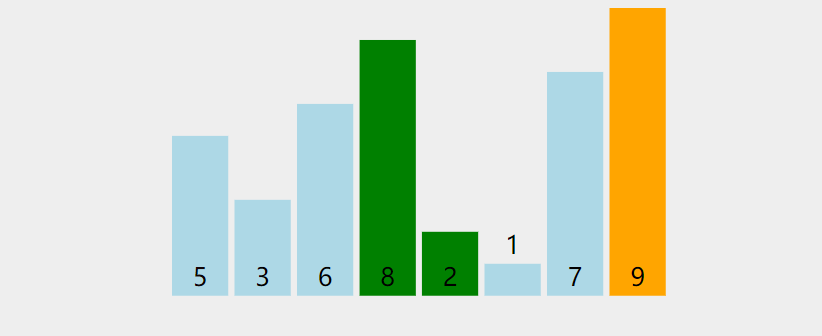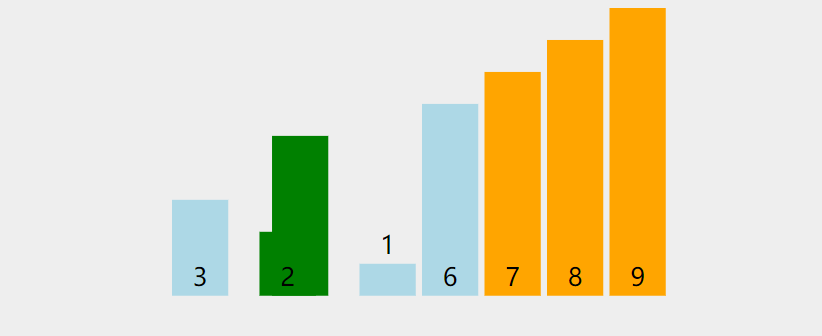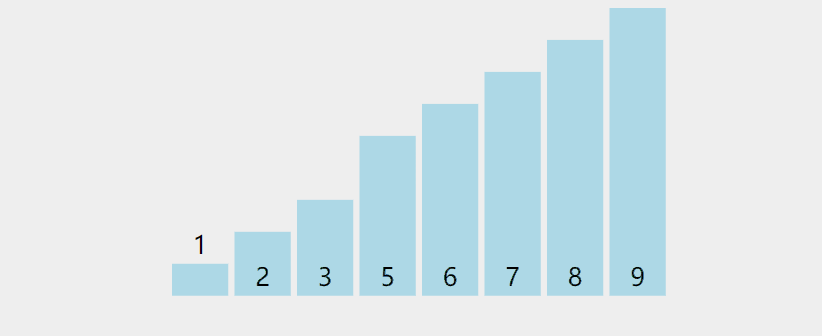
🛫排序过程

🌊代码实现
📔优化前
//元素交换public static void swap(int[] array,int index1,int index2){ int tmp = array[index1]; array[index1] = array[index2]; array[index2] = tmp;}/ * 冒泡排序 * @param array 待排序序列 */public static void bubbleSort(int[] array){ //冒泡排序的趟数 for (int i=0;i<array.length-1;i++){ //每一趟比较的次数 for (int j = 0; j array[j+1]){ swap(array,j,j+1); } } }}
- 如果数组中的元素已经有序了,就不需要再往下遍历比较了。冒泡排序可以进行优化。
- 当一趟排序完成后并没有发生元素交换,就说明数组已经有序了,就不用再继续排序了,所以在交换过程中加添加一个“标记”,可以根据这个标记来确定是否需要继续进行冒泡排序。
📔优化后
//元素交换public static void swap(int[] array,int index1,int index2){ int tmp = array[index1]; array[index1] = array[index2]; array[index2] = tmp;}public static void bubbleSort(int[] array){ //冒泡排序的趟数 boolean flag = false; //标记 for (int i=0;i<array.length-1;i++){ //每一趟比较的次数 for (int j = 0; j array[j+1]){ swap(array,j,j+1); flag = true; //如果进行了交换,就将flag置为true } } if(flag==false){ //如果flag 为false,说明上一趟排序的过程中没有元素交换,数组已经有序 break; } }}🍓性能分析

七、快速排序
⏳排序原理
- 从待排序区间选择一个数,作为基准值(pivot);
- Partition: 遍历整个待排序区间,将比基准值小的(可以包含相等的)放到基准值的左边,将比基准值大的(可以包含相等的)放到基准值的右边;
- 采用分治思想,对左右两个小区间按照同样的方式处理,直到小区间的长度 == 1,代表已经有序,或者小区间的长度 == 0,代表没有数据。
⭐对于基准值位置调整常见方法有:
- 挖坑法
- Hoare 法
- 前后遍历法
从本质上来说挖坑法与Hoare 法是一样的,只不过前者是填坑,后者是交换。
💦挖坑法动态图(一趟排序)
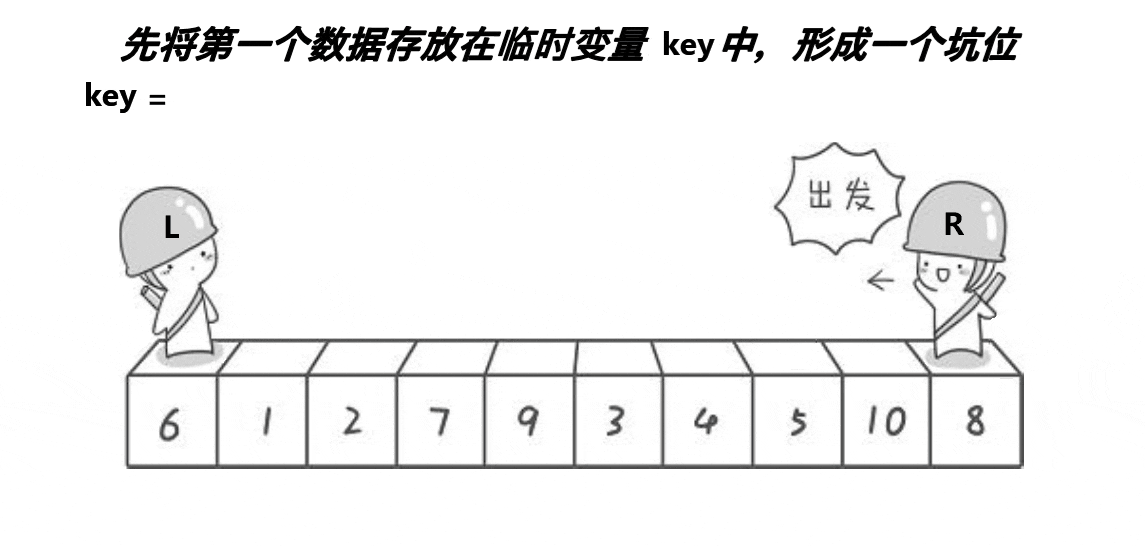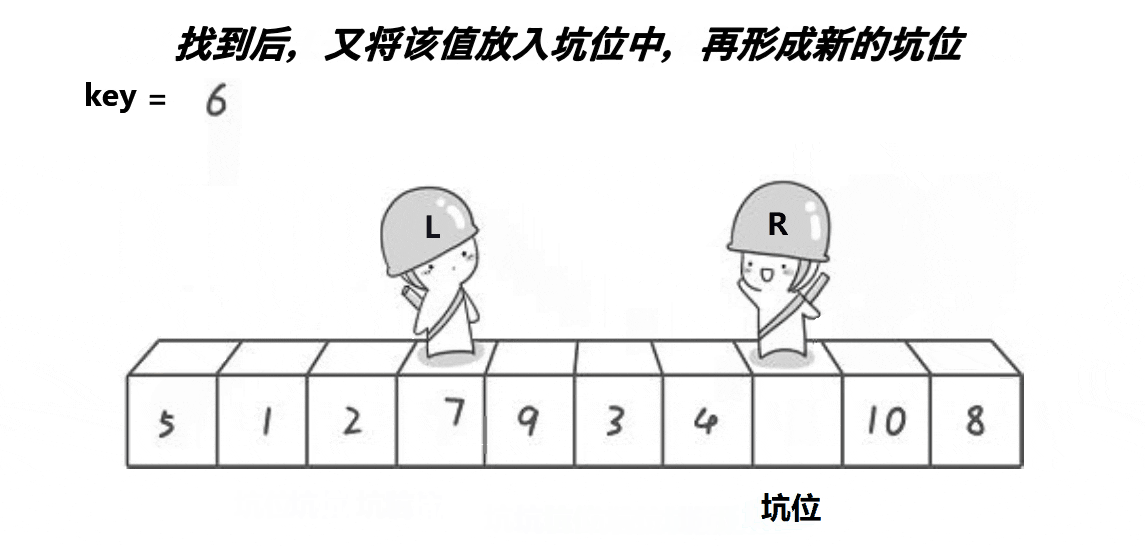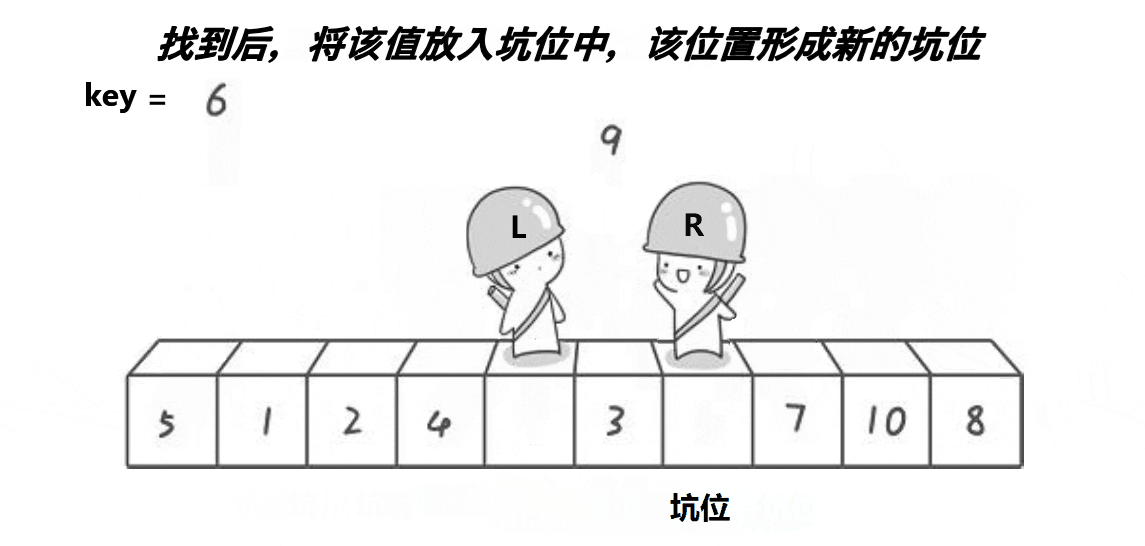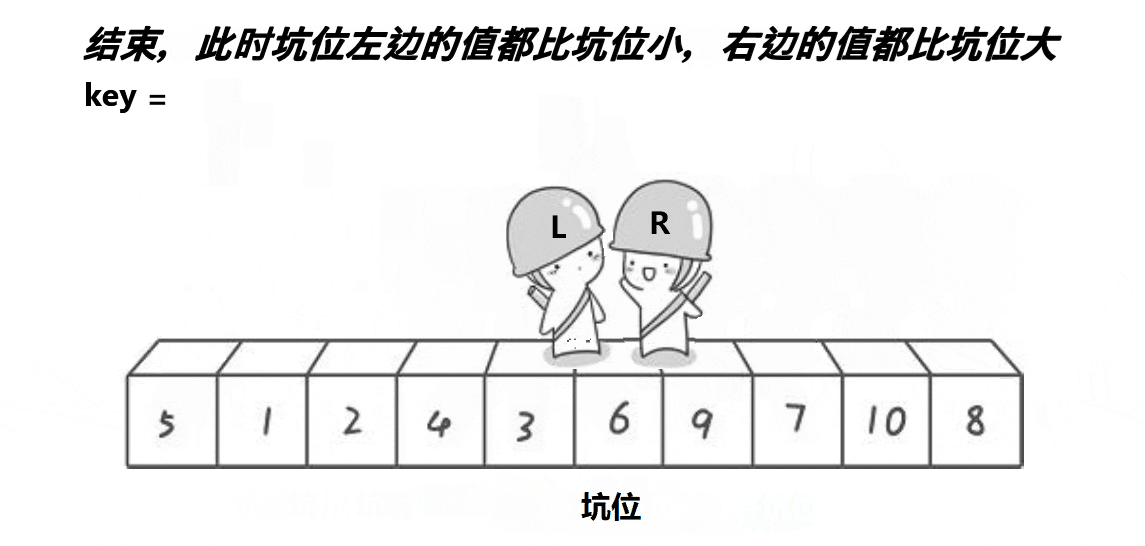
🛫排序过程(挖坑法)
快速排序的核心是对基准值位置的调整。
选择数组边上(左边或右边)的元素作为基准值,这里以数组左边的元素为基准值。
- 确定基准值的位置:start(初始标记数组的0下标)找比基准值小的元素,end(初始标记数组最后一个元素的下标)找比基准值大的元素。
- 以数组第一个元素为基准值,初始以基准值处为坑,将基准值放入 tmp 中,将数组最后位置的元素与tmp中的值进行比较。
- 如果end指向的值比 tmp 中的值大,end就向前移动(end--),直到找到比 tmp 中的值小的元素,将 end 指向的值放到挖的坑中(end 处就是新挖的坑)。
- 然后 start 向后移动(start++)直到找到比 tmp 中的值大的元素,将 start 指向的值放到坑中(start 处就是新挖的坑)。
- 左边的坑填比基准值小的元素,右边的坑填比基准值大的元素。
- 分别对基准值左右序列进行上述相同的操作:取左边界元素为基准值,通过挖坑法确定基准值排序位置。直到左右序列只有一个元素或没有元素为止。此时数组已经有序了。
🌊代码实现
//元素交换public static void swap(int[] array,int index1,int index2){ int tmp = array[index1]; array[index1] = array[index2]; array[index2] = tmp;}/ * 快速排序 * 时间复杂度: * 最好【基准每次都可以均匀分割待排序序列】O(n*log n) * 最坏【数据有序或者逆序】O(n^2) * 空间复杂度: * 最好:O(log n) * 最坏【单分支的树】:O(n) * 稳定性:不稳定 * @param array 待排序序列 */public static void quickSort(int[] array){ quick(array,0,array.length-1);}/ * 通过基准值,排序基准左右两边的序列 * @param array 待排序序列 * @param left 数组首元素的下标(0) * @param right 数组最后一个元素的下标 (len-1) */public static void quick(int[] array,int left,int right){ if(left>=right){ return; } int pivot = partition(array,left,right); //找基准 quick(array,left,pivot-1); //排序小于基准值的区间 quick(array,pivot+1,right); //排序大于基准值的区间}/ * 挖坑法找基准值的位置 * @param array 待排序序列 * @param start 数组首元素的下标(0) * @param end 数组最后一个元素的下标 (len-1) * @return 返回基准值的下标 */public static int partition(int[] array,int start,int end){ int tmp = array[start]; //将基准值存放到tmp中,start (0)下标处为“坑” while (start<end){ //从最后一个元素开始与基准值进行比较,遇到比基准值大的元素 end 就向前移动 while (start=tmp){ end--; } //end 指向的值小于tmp的值,将end指向的元素存放到“坑”中(end下标处为“新挖的坑”) array[start] = array[end]; //从首元素开始与基准值进行比较,遇到比基准值小的元素 start 就向后移动 while (start<end && array[start]<=tmp){ start++; } //start 指向的值大于tmp的值,将start指向的元素存放到“坑”中(start下标处为“新挖的坑”) array[end] = array[start]; } //上面的循环结束表示 start 与 end 相遇,将基准值存放到相遇的下标处 array[start] = tmp; return start; //相遇下标即为基准值的下标,返回 start 或 end 都可以}💦Hoare 法动态图(一趟排序)
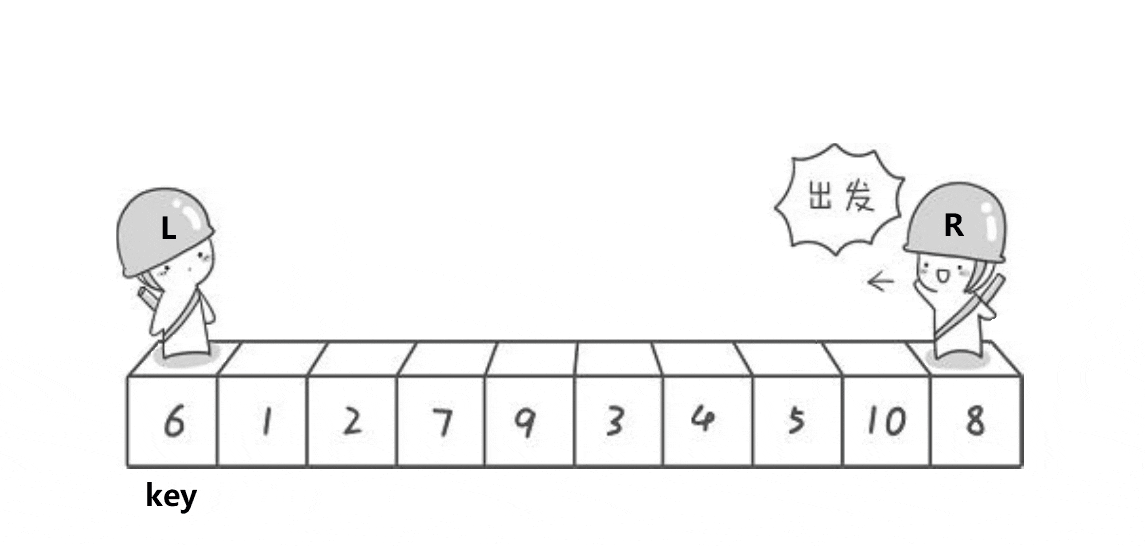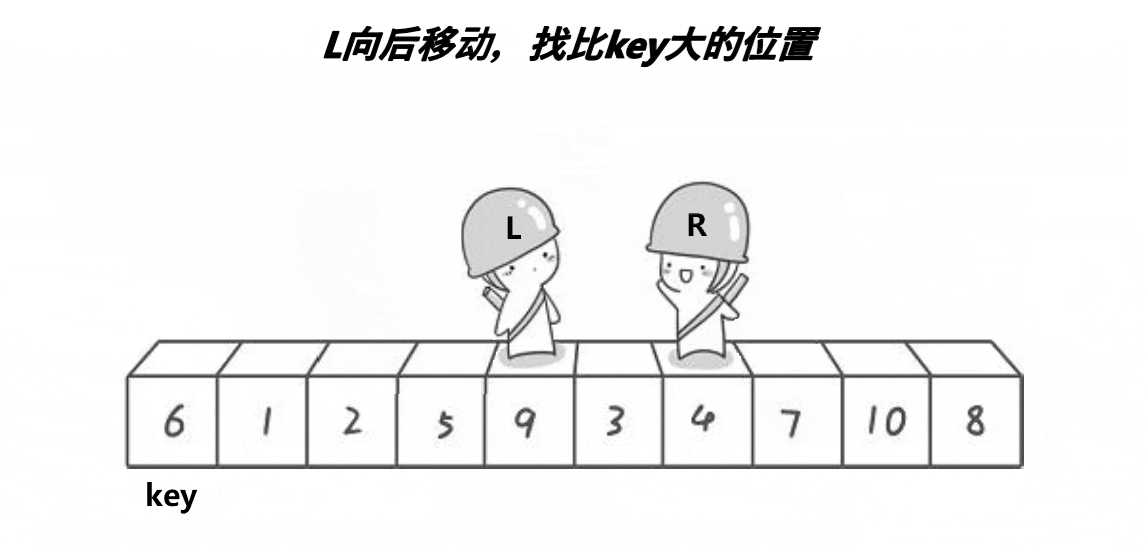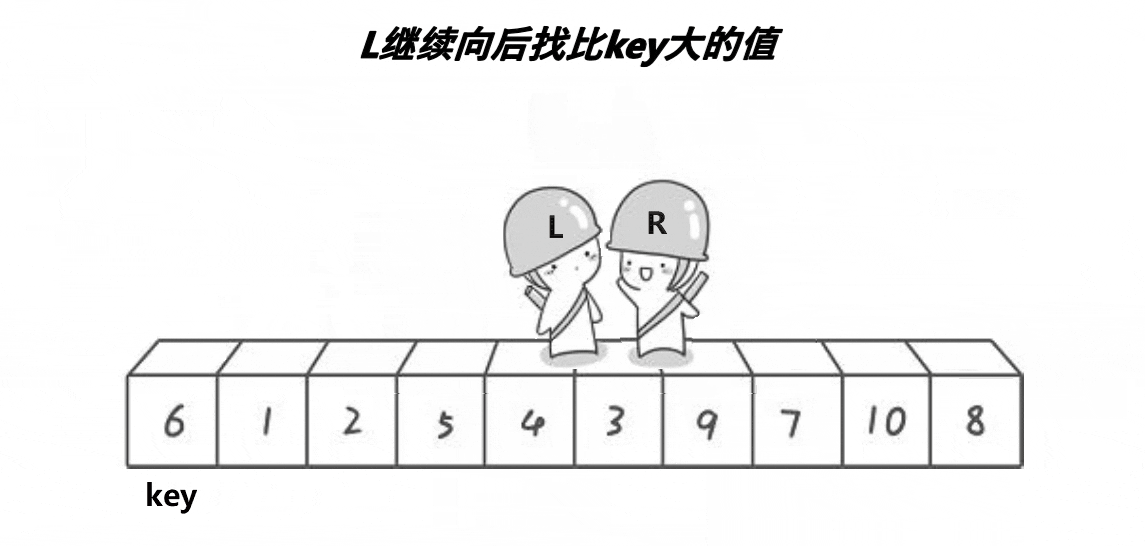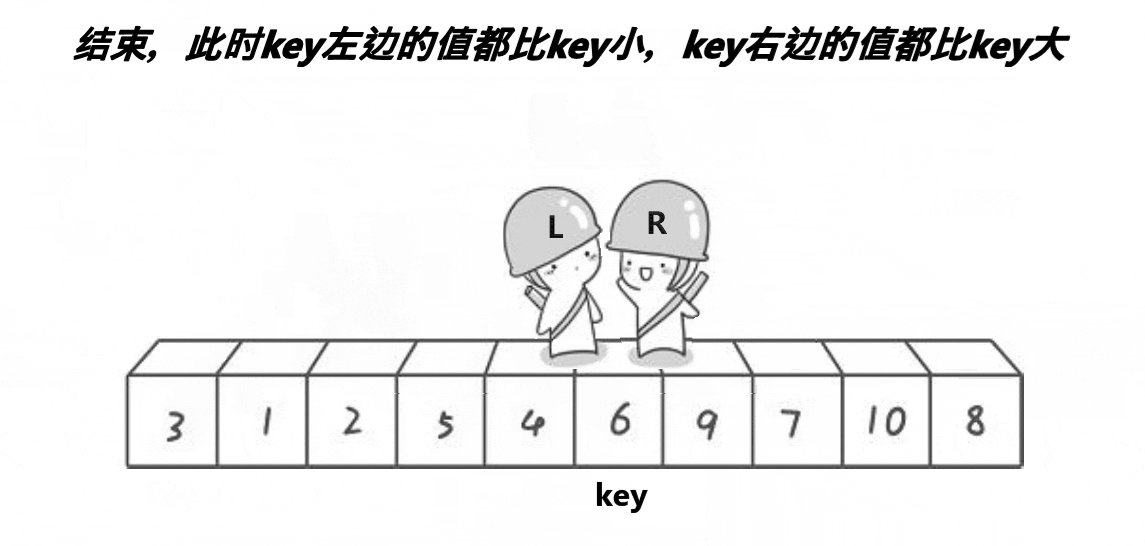
🛫排序过程(Hoare法)
- 选择数组边上(左边或右边)的元素作为基准值,这里以数组左边的元素为基准值。
- start从0下标开始向后遍历,如果遇到比基准值大的元素就停止遍历,end从数组最后一个元素的下标开始向前遍历,如果遇到比基准值小的元素就停止遍历。
- 然后交换 start 与 end 指向的元素,star t继续往后走,end 继续往前走,当 start 遇到比基准值大的元素,end 遇到比基准值小的元素就进行交换。
- 直到 start 与 end 相遇就停止遍历,将相遇位置(比基准值小的元素)与基准值原位置交换,此时基准值位置确定,左边元素小,右边元素大。
- 分别对基准值左右序列进行上述相同的操作:取左边界元素为基准值,通过Hoare法确定基准值排序位置。直到左右序列只有一个元素或没有元素为止。
💥注意:先 end 遍历找比基准值小的元素,再 start 遍历找比基准值大的元素,这样最后相遇时的元素一定是比基准值小的元素。
🌊代码实现
//元素交换public static void swap(int[] array,int index1,int index2){ int tmp = array[index1]; array[index1] = array[index2]; array[index2] = tmp;}/ * 快速排序 * @param array 待排序序列 */public static void quickSort(int[] array){ quick(array,0,array.length-1);}/ * 通过基准值,排序基准左右两边的序列 * @param array 待排序序列 * @param left 数组首元素的下标(0) * @param right 数组最后一个元素的下标 (len-1) */public static void quick(int[] array,int left,int right){ if(left>=right){ return; } int pivot = partition(array,left,right); //找基准 quick(array,left,pivot-1); //排序小于基准值的区间 quick(array,pivot+1,right); //排序大于基准值的区间}/ * Hoare 法找基准的位置 * @param array 待排序序列 * @param left 数组首元素的下标(0) * @param right 数组最后一个元素的下标 (len-1) * @return 返回基准值的下标 */public static int partition(int[] array,int left,int right){ int partindex = array[left]; //将数组首元素设置为基准值,与后面的元素进行比较,寻找基准的位置 int start = left; int end = right; while (start<end){ //从后向前遍历数组,如果遇到比基准值大的元素,end 就向前移动。(找比基准值小的元素) while (start=partindex){ end--; } //从前向后遍历数组,如果遇到比基准值小的元素,start 就向后移动。(找比基准中大的元素) while (start<end){ while (start<end && array[start]<=partindex){ start++; } } //交换两个元素,将比基准值大的元素放到数组的右区间,比基准值小的元素放到数组的区间 swap(array,start,end); } //上面的循环结束表示 start 与 end 相遇,将相遇位置的元素与基准值交换 swap(array,left,start); return start; //返回存放基准值的下标}⭐快速排序优化
🍎找基准值优化
常见找基准值的方法有以下几种:
- 取边界值法,即取目标序列最左边元素或最右边元素。
- 随机值法,随机选取目标序列中的一个元素作为基准值。
- 几数取中法,经常使用的是 三数取中法(三个数,取中间大小的值)。
前面实现快速排序找基准值使用的是取边界值法,使用这种方法当遇到有序或逆序的序列时,时间复杂度为O(N^2) ,空间复杂度为 O(N) 。
由于是递归,当待排序序列有序或逆序时,元素个数达到一定数量就会造成栈溢出,为了解决这个问题,可以使用随机取值法或三数取中法。
🍎随机取值法找基准值
- 使用该方法完全是看“人品”。
- 如果每次选取的基准值都是序列的最大值或最小值,时间复杂度仍为 O(N^2) ,空间复杂度仍为 O(N),所以这个方法并不是很好。
🍎三数取中法(推荐使用)
- 此方法可以对找基准进行很好的优化
- 在数组的左右边界值、中间位置的值,三个值中选择一个中间值作为基准值。
获取三个数中,中间大小的值的下标:
- 数组为:array,左边界下标:left ,右边界下标:right,中间位置的下标:mid。
- 先判断左右边界值的大小。
左边界大:array[left] > array[right]
- 情况1:中间位置的元素 > 左边界的元素
array[mid] > array[left]排列顺序:mid left right返回:left
- 情况2: 中间位置的元素 < 右边界的元素
array[mid] < array[right]排列顺序:left right mid返回:right
- 其他情况
排列顺序:left mid right返回:mid右边界大:array[left] <= array[right]
- 情况1:中间位置的元素 < 左边界的元素
array[mid] < array[left]排列顺序:mid left right返回:left
- 情况2:中间位置的元素 > 右边界的元素
array[mid] > array[right]排列顺序:left right mid 返回:right
- 其他情况
排列顺序:left mid right返回:mid
🌊代码实现
//元素交换public static void swap(int[] array,int index1,int index2){ int tmp = array[index1]; array[index1] = array[index2]; array[index2] = tmp;}/ *使用三数取中法对找基准进行优化 * 找三个数中,中间大小的值的下标 * @param array 待排序序列 * @param left 数组左边界 * @param right 数组右边界 * @return 然后三个数中,中间大小值的下标 */public static int findmidValInde(int[] array,int left,int right){ int mid = left + ((right-left)>>>1); //int mid = (left+right)/2; if(array[left]>array[right]){ if(array[mid] > array[left]){ swap(array,left,left); }else if(array[mid] < array[right]){ swap(array,right,left); }else { swap(array,mid,left); } }else{ if(array[mid] array[right]){ swap(array,right,left); }else { swap(array,mid,left); } }}🌊完整代码
/ * 快速排序 * @param array 待排序序列 */public static void quickSort(int[] array){ quick(array,0,array.length-1);}/ * 通过基准值,排序基准左右两边的序列 * @param array 待排序序列 * @param left 数组首元素的下标(0) * @param right 数组最后一个元素的下标 (len-1) */public static void quick(int[] array,int left,int right){ if(left>=right){ return; } int pivot = findmidValInde(array,left,right); //找基准 quick(array,left,pivot-1); //排序小于基准值的区间 quick(array,pivot+1,right); //排序大于基准值的区间}/ *挖坑法找基准:使用三数取中法进行优化 * 找三个数中,中间大小的值的下标 * @param array 待排序序列 * @param left 数组左边界 * @param right 数组右边界 * @return 然后三个数中,中间大小值的下标 */public static int findmidValInde(int[] array,int left,int right){ int mid = left + ((right-left)>>>1); //int mid = (left+right)/2; if(array[left]>array[right]){ if(array[mid] > array[left]){ swap(array,left,left); }else if(array[mid] < array[right]){ swap(array,right,left); }else { swap(array,mid,left); } }else{ if(array[mid] array[right]){ swap(array,right,left); }else { swap(array,mid,left); } } int tmp = array[left]; while (left<right){ //从最后一个元素开始与基准值进行比较,遇到比基准值大的元素 right 就向前移动 while (left=tmp){ right--; } //right 指向的值小于tmp的值,将end指向的元素存放到“坑”中(right下标处为“新挖的坑”) array[left] = array[right]; //从首元素开始与基准值进行比较,遇到比基准值小的元素 left 就向后移动 while (left<right && array[left]<=tmp){ left++; } //left 指向的值大于tmp的值,将left指向的元素存放到“坑”中(left下标处为“新挖的坑”) array[right] = array[left]; } //上面的循环结束表示 left 与 right 相遇,将基准值存放到相遇的下标处 array[left] = tmp; return right; //相遇下标即为基准值的下标,返回 left 或 right 都可以}⭐使用非递归的方法实现快速排序
- 非递归实现快速排序需要借助栈来实现。
- 先在待排序序列中找一次基准,将左边界的下标、基准左边的下标、基准右边的下标,右边界的下标依次入栈。
- 下标入栈时要判断基准值左右序列是否有两个以上的元素。如果有,将序列的左右边界下标入栈。
- 当栈不为空时弹出栈顶的两个元素,先出栈的元素放到右边(right = stack.pop();),后出栈的元素放到左边(left = stack.pop();)。元素出栈后重新找基准值的位置,并再次入栈。
- 重复执行上面的操作,直到栈为空时结束。
🌊代码实现
//元素交换public static void swap(int[] array,int index1,int index2){ int tmp = array[index1]; array[index1] = array[index2]; array[index2] = tmp;}/ * 挖坑法找基准:使用三数取中法进行优化 * 找三个数中,中间大小的值的下标 * @param array 待排序序列 * @param left 数组左边界 * @param right 数组右边界 * @return 然后三个数中,中间大小值的下标 */public static int findmidValInde(int[] array,int left,int right){ int mid = left + ((right-left)>>>1); //int mid = (left+right)/2; if(array[left]>array[right]){ if(array[mid] > array[left]){ swap(array,left,left); }else if(array[mid] < array[right]){ swap(array,right,left); }else { swap(array,mid,left); } }else{ if(array[mid] array[right]){ swap(array,right,left); }else { swap(array,mid,left); } } int tmp = array[left]; while (left<right){ //从最后一个元素开始与基准值进行比较,遇到比基准值大的元素 right 就向前移动 while (left=tmp){ right--; } //right 指向的值小于tmp的值,将end指向的元素存放到“坑”中(right下标处为“新挖的坑”) array[left] = array[right]; //从首元素开始与基准值进行比较,遇到比基准值小的元素 left 就向后移动 while (left<right && array[left]<=tmp){ left++; } //left 指向的值大于tmp的值,将left指向的元素存放到“坑”中(left下标处为“新挖的坑”) array[right] = array[left]; } //上面的循环结束表示 left 与 right 相遇,将基准值存放到相遇的下标处 array[left] = tmp; return right; //相遇下标即为基准值的下标,返回 left 或 right 都可以}/ * 非递归实现快速排序 * @param array 待排序序列 */public static void quickSort(int[] array){ Stack stack = new Stack(); int left = 0; int right = array.length-1; //找基准 int pivot = findmidValInde(array,left,right); if(left+1pivot){ //基准右边至少有两个元素 stack.push(pivot+1); stack.push(right); } while (!stack.isEmpty()){ right = stack.pop(); left = stack.pop(); pivot = findmidValInde(array,left,right); if(left+1pivot){ stack.push(pivot+1); stack.push(right); } }}🍓性能分析
📔优化前

📔 优化后

八、归并排序
🎄合并两个有序数组
- 在了解归并排序前,先做一个道题:将两个有序数组合并成一个有序的数组。
⏳解题思路
- 有两个有序的数组,第一个数组
array1的长度为len1,第二个数组array2的长度为len2,创建一个大小为len1+len2的新数组存放合并后的数据。- 比较两数组的元素按从小到大的顺序将数据拷贝到新的数组中。
- 如果其中有一个数组遍历完,就将另一个未遍历完的数组中的元素拷贝到新数组中。
🌊代码实现
//合并两个有序数组public static int[] mergeArray(int[] array1,int[] array2){ int s1 = 0; int s2 = 0; int index = 0; int e1 = array1.length-1; int e2 = array2.length-1; int[] newArray = new int[array1.length+array2.length]; while (s1<=e1 && s2array2[s2]){ newArray[index++] = array2[s2++];}else { newArray[index++] = array1[s1++];} } while (s1<=e1){newArray[index++] = array1[s1++]; } while (s2<=e2){newArray[index++] = array2[s2++]; } return newArray;}🎄归并排序
⏳排序原理
- 归并排序(MERGE-SORT)是建立在归并操作上的一种有效的排序算法,该算法是采用分治法(Divide andConquer)的一个非常典型的应用。
- 将已有序的子序列合并,得到完全有序的序列;即先使每个子序列有序,再使子序列段间有序。
- 若将两个有序表合并成一个有序表,称为二路归并。
💦动态图
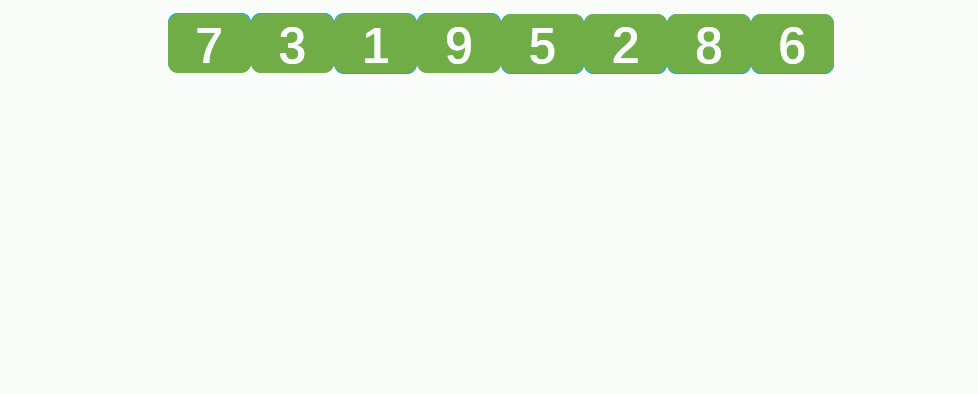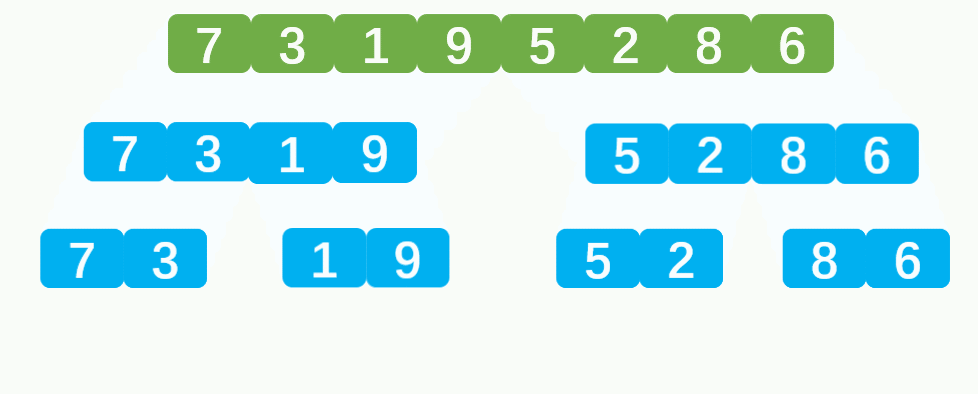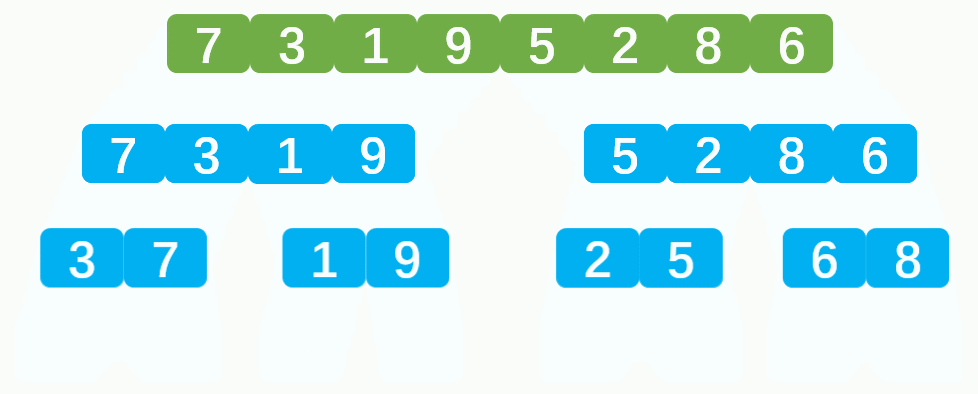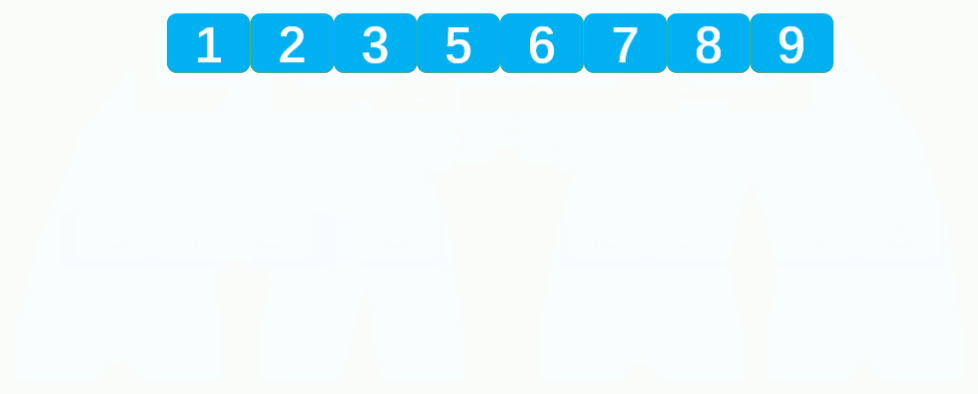
⏳归并排序递归思路
- 归并排序核心思想是合并有序数组。
- 首先将数组分解成一个一个的元素,并进行分组,每组一个元素。此时每组的元素全部是有序(因为只有一个元素)。
- 然后两两一组进行有序合并,合并后的数组也是有序数组,最后将合并的数组继续与其他合并的数组合并,直到完全合并为止。
- 分组后两两一组进行合并,第一组序列左边界为
left,右边界为mid, 第二组序列的左边界为 mid+1,右边界为right,则合并后新数组的长度为right-left+1。- 对于数组的分解再合并,最常见的思路就是递归。
🌊代码实现
/ * 归并排序 * 时间复杂度:O(N*logN) * 空间复杂度:O(N) * 稳定性:稳定 *如果 array[s1]>=array[s2] 不取等号,就是不稳定的 * @param array */public static void mergeSort(int[] array){ mergeSortInternal(array,0,array.length-1);}public static void mergeSortInternal(int[] array,int left,int right){ if(left>=right){ return; } int mid = left+((right-left)>>>1); //分解左边 mergeSortInternal(array,left,mid); //分解右边 mergeSortInternal(array,mid+1,right); //合并 merge(array,left,mid,right);}public static void merge(int[] array,int left,int mid,int right){ int s1 = left; int s2 = mid+1; int e1 = mid; int e2 = right; int index = 0; int[] newArray = new int[right-left+1]; while (s1<=e1 && s2=array[s2]){ newArray[index++] = array[s2++]; }else { newArray[index++] = array[s1++]; } } while (s1<=e1){ newArray[index++] = array[s1++]; } while (s2<=e2){ newArray[index++] = array[s2++]; } for (int i = 0; i < index; i++) { array[i+left] = newArray[i]; }}⏳归并排序非递归思路
- 将数组进行分组排序,需要确定每一组的左边界,中间下标,右边界。确定好下标后就可以对每一组进行合并。
- 每组的左边界为 left,每一组的组数为 nums,则 mid = left + nums -1,right = mid + nums。
- 定义变量 i 对数组进行遍历。因为每遍历完一组数据,就要重新遍历下一组,所以 left = i,按照上面的公式就可以计算出每组中 mid 与 right 的值。
- 每组组数为 nums(初始为1组),合并后,除了最后一组的元素个数不能保证为 2*nums,其他组的元素个数均为2*nums,所以完成一组合并后(一趟合并),num = 2*num。
- 因为每次合并两组数据,每遍历完一次就完成一组数据的合并,所以 i 的增量为 2*nums。
- 对每一组进行合并时都需要保证调整后的 mid 与 right 不能越界。如果越界,则需要调整为指向待排序序列的最后一个元素。
- 每次合并数组前,需要保证每组元素个数 nums 小于待排序序列长度,如果满足此条件就继续合并,不满足则表示已完成排序。
🌊代码实现
/ *合并有序序列 * @param array 待合并的序列 * @param left 每组序列的左边界 * @param mid 每组序列的中间下标 * @param right 每组序列的右边界 */public static void merge(int[] array,int left,int mid,int right){ int s1 = left; int s2 = mid+1; int e1 = mid; int e2 = right; int index = 0; int[] newArray = new int[right-left+1]; while (s1<=e1 && s2=array[s2]){ newArray[index++] = array[s2++]; }else { newArray[index++] = array[s1++]; } } while (s1<=e1){ newArray[index++] = array[s1++]; } while (s2<=e2){ newArray[index++] = array[s2++]; } for (int i = 0; i < index; i++) { array[i+left] = newArray[i]; }}/ * 非递归实现归并排序 * @param array 待排序序列 */public static void mergeSort(int[] array){ int nums = 1;//每组数据的个数 while (nums<=array.length){ //数组没都需要遍历,确定归并的区间 for(int i=0;i=array.length){ mid = array.length-1; } int right = mid+nums; //防止越界 if(right>=array.length){ right = array.length-1; } //下标确定后,进行合并 merge(array,left,mid,right); } nums*=2; }}🍓性能分析


