大厂面试真题:谈谈你对MySQL索引的理解
当面试官抛出一个问题的时候,面试者的内心其实是很想把自己知道的东西迫切的说给面试官听。做过4年的面试官,这里总结一下经验,回答任何一个问题的时候应该要遵循:明确题意-->深入浅出-->举例说明-->总结,这四个步骤很重要,可以让你沉着冷静,思路清晰,避免尴尬。特别是面试官抛出一个比较宽泛的问题,例如:谈谈你对MySQL索引的理解。这种问题其实对面试者是很有益的,越宽泛越有可能涉及到你熟悉的区域。
01 明确题意
明确题意的意思就是先明确一下面试官的题目,能避免自己理解有误而跑题,当面试官抛出这个问题的时候,先明确一下MySQL索引含义。可以这样说:面试官你好,索引是主要用来加快数据的访问,提高数据查询的效率。它的效率高主要是来源于它存储的数据结构B+树。
02 深入浅出
这个时候就会抛出另外一个问题,为什么使用B+树,接下来就可以从Hash、二叉树、BST树、AVL树、红黑树、多叉树等数据结构说,最后说到B-树和B+树的区别,最终选择B+树。这其中还有很多延伸的点可以说,如果面试官打断问一些问题,那就说明面试官是感兴趣的。接下来就详细说下这几个数据结构为什么不合适。
-
Hash:它的数据结构是数组 + 链表,优势是查询速度很快。缺点是需要设计出一个优良的hash算法用来解决hash冲突问题,它只能存储Key,查询之后需要回表查询,存储是无序的,排序效率低、按照范围效率低等缺点。可以再补充一点:memeory是支持Hash的。
-
二叉树、BST树、AVL树、红黑树,可以将这些树一起说,最终的原因就是因为树节点分为左右两个分支,树的深度会随着数据量的增大而增大,非平衡树还有可能退化成链表,平衡树最终避免不了树的深度问题。深度越高查询IO的次数就会越多。所以二叉树是不合适的,所以要选择多叉有序树,B-树。
-
B-树:先来了解一下B-树的数据结构。
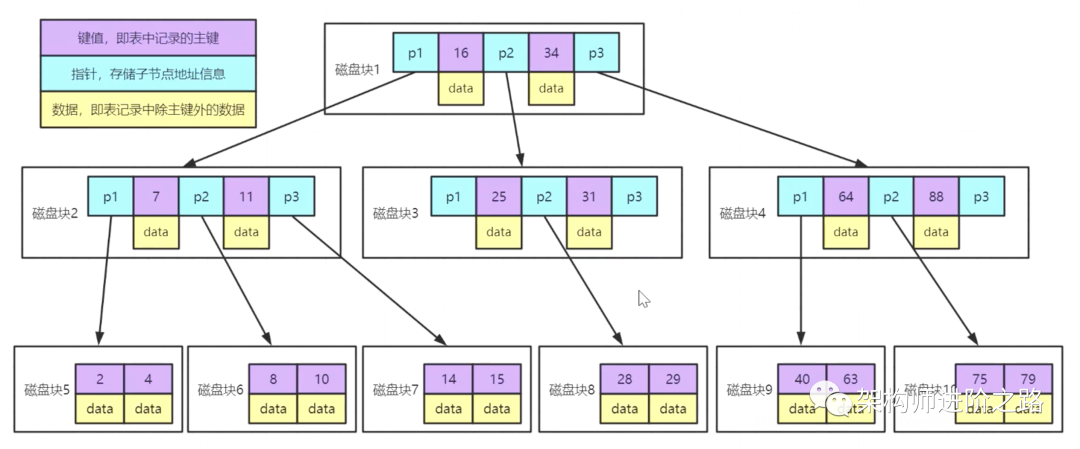
可以看到数据的查询效率会很高,例如:查询数据28的数据,磁盘块1的p2--->磁盘块3的p2--->磁盘块8。看上去没问题,但是光环在B+树上面,所以B-树肯定还有瑕疵,这个时候需要抛出一个知识点:磁盘预读,内存和磁盘之间的交互是按照页为单位进行读取的,MySQL的InnodDb默认是16KB读取一页数据,所以要尽可能的减少磁盘的读取次数,B-树的数据结构中有个点就是磁盘块中除了存储了主键,还存储了当前主键对应的数据,如果一行的数据量较大,那一页16kb的存储能够存储的数据量较小,假设数据 + 指针等信息加起来总和为1KB,则一页存储的数量只有16条数据。假设现在B-树的高度为3,那只能存储16 * 16 * 16 = 4096 条数据,当数据量很大的时候假设1000万条数据的时候,此时树的高度很高,读取磁盘IO的次数也会变得很多,所以需要一个较为极致的数据结构,让磁盘的IO的次数变得很少,所以这个问题是B-树的节点也存储了数据,如果将只存储指针而数据存在叶子节点呢。那接下来就开始聊B+树的特点。
-
B+树的特点:先看下B+树的数据结构
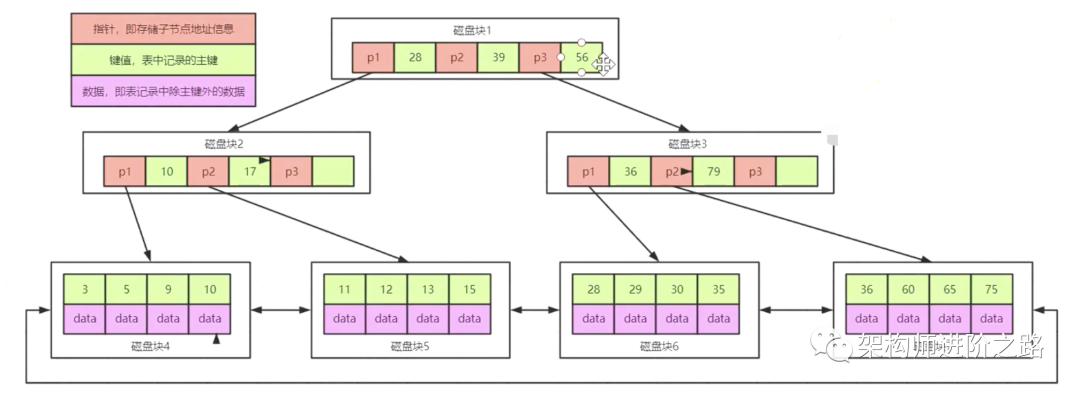
先说下B+树的特点是非叶子节点不存储数据,存储主键和指针,数据都存在叶子节点,也就是最后一层的节点存储了所有的全量数据,这样就能够将B-树中的指针数量变多,例如:此时B+树的高度为3能存储多少数据,假设指针等信息为32B,那么3层结构的第二层数据量为:16 * 1024 除 32 = 512 个指针左右,也就是指向了512块磁盘,第二次不存储数据,每块磁盘还是有512个指针,所以第二层的数据量为:512 * 512 约等于26万个指针左右,第三层的存储,指针 + 数据等信息假设还是1KB,那么每个磁盘只存储16条数据,那么第三层的数据为 26万个指针 * 16 = 400万条数据。从以上的分析可以得出结论:数据量存储的量其实和主键和数据量本身有关系,如果主键存储的是varchar那么三层结构的数据量不会太多,相反的话如果存储的是int类型并且一行记录的数据量很小,将会存储上千万或者上亿的数据量,所以这里为什么建议数据库的主键是自增长的原因就在于此处。当上千万条数据只有三层高度的时候,查询的效率是极高的。再说下B+树除了非叶子节点不存储数据外,叶子节点的数据结构还是一个双向链表,当进行区间查询的时候,这样又能够提高查询的效率。
这样说完估计5~10分过去了,如果面试官不打扰的话,如果打扰的话可能就更多了。此时可以这样说:针对于MySQL的索引我们平时在使用的时候我们要注意索引失效的问题。这就又引出了索引使用和优化的问题,然后就可以介绍一下索引的使用方式。
-
聚簇索引:数据会根据主键来生成聚簇索引,如果没有主键选择唯一键,如果没有唯一键则会使用隐式row_id作为聚簇索引的主键,聚簇索引存储了所有的数据。这里面又有个知识点隐式字段6字节的row_id,这个点又可以延伸出来事务的隔离级别中的MVCC,当然如果面试官打断提到的话,那就会更加兴奋,时间又在这里消耗了一点。MyISAM不支持聚簇索引只支持非聚簇索引。
-
非聚簇索引:存储索引的key值,没有存储具体数据行,这个key值对应聚簇索引的key值。
-
组合索引:多个字段合并生成一个索引,提高查询效率。
-
覆盖索引:在查询的时候不用回表查询,就可以得到所需要的数据。
介绍完索引的使用,再说下索引失效的情况
-
组合索引不遵循最左匹配原则
-
组合索引的前面索引列使用范围查询(,like),会导致后续的索引失效
-
不要在索引上做任何操作(计算,函数,类型转换)
-
is null和is not null无法使用索引
-
字符串不添加引号会导致索引失效
-
like语句中,以%开头的模糊查询
03 举例说明
然后再说一个实际工作中的一个例子,使用explain执行计划怎么优化sql语句让索引从失效到生效,最终提高了查询效率,也可以是一个很简单的例子,要基于业务说明实际的情况。
04 总结
最后来句总结:这就是我对索引的理解。主要的作用是提醒面试官说完了,看看面试官是否有问题要问,或者让面试官提问下一个问题,不要让面试官或者自己尴尬。