第6篇: ElasticSearch写操作—原理及近实时性分析(完整版)
背景:目前国内有大量的公司都在使用 Elasticsearch,包括阿里、京东、滴滴、今日头条、小米、vivo等诸多知名公司。除了搜索功能之外,Elasticsearch还结合Kibana、Logstash、Elastic Stack还被广泛运用在大数据近实时分析领域,包括日志分析、指标监控等多个领域。
目录
1、 ElasticSearch单条及批量写操作(Java版)
1.1 单条新增index
1.2 批量新增bulk
2、ElasticSearch写操作原理
2.1 写原理流程图
2.2 写操作核心步骤
2.2.1 客户端->主节点
2.2.2 主分片->副本分片
2.2.3 主分片->内存缓冲区
2.2.4 主分片->TransLog
2.2.5 Segment->Commit Point
3、写近实时性分析
3.1 性能影响关键问题
1)单条插入性能较差
2)主副分片之间数据同步IO问题
3) 索引刷新时间
3.2 写性能问题解决方案
1)单条改为批量
2)引入多线性机制
3)索引刷新时间和副本个数调整
4)修改事务日志translog参数
1、 ElasticSearch单条及批量写操作(Java版)
为了更好地说明Elasticsearch写原理,我们先来看下客户端写操作代码及发起的请求信息。具体操作细节可参考前面的文章 Elasticsearch 7.X增删改查实战
1.1 单条新增index
/*** 添加文档-单条* @param dto* @param indexName* @return* @throws IOException*/public static Boolean addDocument(Object dto, String indexName) throws IOException { BaseDto baseDto = (BaseDto) dto; //创建请求 IndexRequest request = new IndexRequest(indexName); //规则 put request.id(baseDto.getId()); request.timeout(TimeValue.timeValueSeconds(1)); //将数据放入请求 Map jsonMap = JSON.parseObject(toJson(dto), Map.class); request.source(jsonMap); //客户端发送请求 IndexResponse response = restHighLevelClient.index(request, RequestOptions.DEFAULT); //响应状态 CREATED return response.status().getStatus() == RestStatus.CREATED.getStatus();}1.2 批量新增bulk
/*** 添加文档-批量** @param list* @param indexName* @return* @throws IOException*/public static Boolean batchAddDocument(List list, String indexName) throws IOException { //创建请求 BulkRequest bulkRequest = new BulkRequest(); for(Object dto: list) { BaseDto baseDto = (BaseDto) dto; IndexRequest indexRequest = new IndexRequest(indexName); //规则 put indexRequest.id(baseDto.getId()); indexRequest.timeout(TimeValue.timeValueSeconds(1)); //将数据放入请求参数 Map jsonMap = JSON.parseObject(toJson(dto), Map.class); indexRequest.source(jsonMap); //客户端发送请求 bulkRequest.add(indexRequest); } BulkResponse response = restHighLevelClient.bulk(bulkRequest, RequestOptions.DEFAULT); //批量新增 //响应状态 CREATED return response.status().getStatus() == RestStatus.CREATED.getStatus();}2、ElasticSearch写操作原理
如果对ES整体架构不太了解的朋友,可以先下前面的文章能有助于理解本篇内容。Elasticsearch架构及模块功能介绍
2.1 写原理流程图
写流程主要从应用层、协议层、发现层、数据处理层、核心架构层以及数据存储层这6层来梳理。
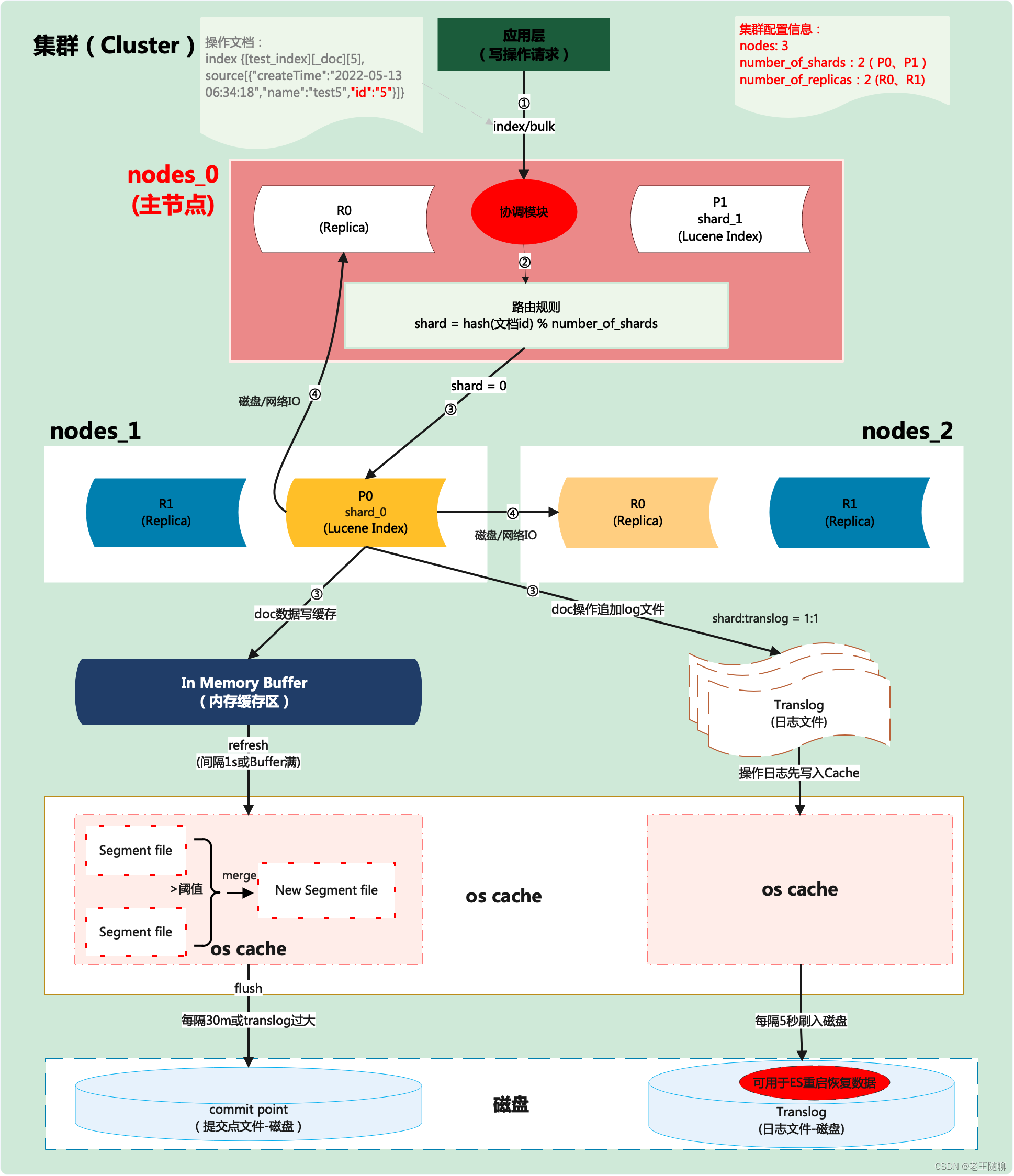
2.2 写操作核心步骤
2.2.1 客户端->主节点

1)应用端向主节点(node_0)发起写操作(index/bulk)请求,参数为文档内容数据。
2)主节点(node_0)通过自身的调度模块,对传入的文档ID进行hash处理后,再与主分片数进行取余数,余数范围为:0~number_of_shards-1。
3)主节点(node_0)计算得到的余数(分片号0)就是该条文档数据对应存储的主分片(shard_0)中。
4)等主分片shard_0存储文档成功数据后,会将主分片数据通过磁盘或者网络(IO)复制的其他副本分片中(R0)。
2.2.2 主分片->副本分片
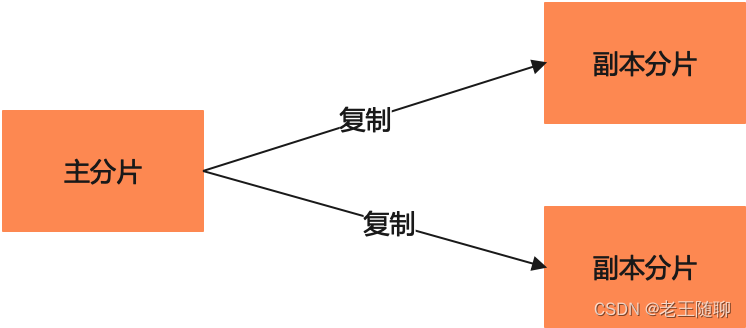
1)主分片存储文档成功后,才会将数据复制到对应各副本分片。
2)如果主分片存储失败,则会认为整个集群存储失败;如果是部分副分片失败,则会认为整体处理成功,通过后续补偿机制来恢复副本数据。
2.2.3 主分片->内存缓冲区

数据写入主分片后,写入内存缓存区的目的属于一种存储优性能化方式。通过引入使用 in-memory buffer 来暂存每个 doc 对应的 inverted index的数据,从而达到批量堆积的效果,进一步避免频繁的磁盘 I/O。当这些文档数据累积到一定量后,就可以从 in-memory buffer 刷到 disk 了。
2.2.4 主分片->TransLog

Elasticsearch通过临时写入写操作来保证数据安全。因为lucene索引过程中,数据会首先据缓存在内存中直到达到一个量(文档数或是占用空间大小)才会写入到磁盘。这就会带来一个风险,如果在写入磁盘前系统崩溃,那么这些缓存数据就会丢失。因此,Elasticsearch通过translog解决了这个问题,每次写操作都会写入一个临时文件translog中,这样如果系统需要恢复数据可以从translog中读取。另外,当ES出现宕机重启后,可通过translog磁盘文件进行数据恢复。
2.2.5 Segment->Commit Point

我们知道,Segment是Shard的最小存储组成部分,每个Shard由若干Segment和和对应的 commit point(提交点文件)构成。而用Commit Point来记录所有Segment的元数,保存着旧的Segment文件的信息。
3、写近实时性分析
3.1 性能影响关键问题
1)单条插入性能较差
毫无疑问,单条插入会受磁盘和网络IO的影响。如果在数据量大的情况下,会频繁发送请求,这对服务端而言,处理能力必然会受影响。
2)主副分片之间数据同步IO问题
如果我们设置了副本,数据会先写入主分片,然后主分片再同步到副本分片,那同步操作就会加重磁盘 IO,间接会影响写入操作的性能。
3) 索引刷新时间
默认情况下索引的refresh_interval为1秒,这意味着数据写1秒后就可以被搜索到,每次索引的refresh会产生一个新的Lucene段,这会导致频繁的segment merge行为,如果不需要这么高的搜索实时性,应该降低索引refresh周期。
3.2 写性能问题解决方案
1)单条改为批量
具体优势就不必多说,在这里重点需要说一下,在使用bulk时,需要根据服务性能做批次卡控,并非是无限制批次就是最优的,反而可能会影响性能。并非bulk每个批次值越大越好,而是根据写入数据量具体来定的,因为越大的bulk会导致内存压力过大。建议一个请求最好不要发送超过15MB的数据量。
2)引入多线性机制
我们知道,单线程发送bulk请求是无法最大化Elasticsearch集群写入的吞吐量的。如果要充分利用集群所有资源,就需使用多线程并发将数据bulk写入集群中。多线程并发写入同时可以减少每次底层磁盘fsync的次数和开销。
3)索引刷新时间和副本个数调整
索引刷新时间默认“index.refresh_interval”为“1s”, 即每秒都会强制生成1个新的segments文件,增大索引刷新时间,可以生成更大的segments文件,有效降低IO并减少segments merge的压力。
如果只是纯导入数据而非实时查询的业务场景,比如上传报表数据等,可以把refresh禁用(即设置index.refresh_interval为-1),并设置“index.number_of_replicas”为“0”,当然这样设置会有数据丢失风险。等到数据完成导入后,再把参数设置为合适的值。
{ "number_of_replicas": 0, "refresh_interval": "120s"}4)修改事务日志translog参数
默认设置下,translog 的持久化策略是每个请求都flush,这样能保证写操作可靠性,但是对性能会有很严重的影响,可以通过调整 translog 持久化策略、周期性和一定大小的时候 flush,能大大提升导入性能。
{"index": { "translog": { "flush_threshold_size": "1GB", "sync_interval": "120s", "durability": "async" } }}