客快物流大数据项目(六十七):客户主题

文章目录
客户主题
一、背景介绍
二、指标明细
三、表关联关系
1、事实表
2、维度表
3、关联关系
四、客户数据拉宽开发
1、拉宽后的字段
2、SQL语句
3、Spark实现
五、客户数据指标开发
1、计算的字段
2、Spark实现
客户主题
一、背景介绍
客户主题主要是通过分析用户的下单情况构建用户画像
二、指标明细
|
指标列表 |
|
总客户数 |
|
今日新增客户数 |
|
留存率(超过180天未下单表示已流失,否则表示留存) |
|
活跃用户数(近10天内有发件的客户表示活跃用户) |
|
月度新老用户数(应该是月度新用户!) |
|
沉睡用户数(3个月~6个月之间的用户表示已沉睡) |
|
流失用户数(9个月未下单表示已流失) |
|
客单数 |
|
客单价 |
|
平均客单数 |
|
普通用户数 |
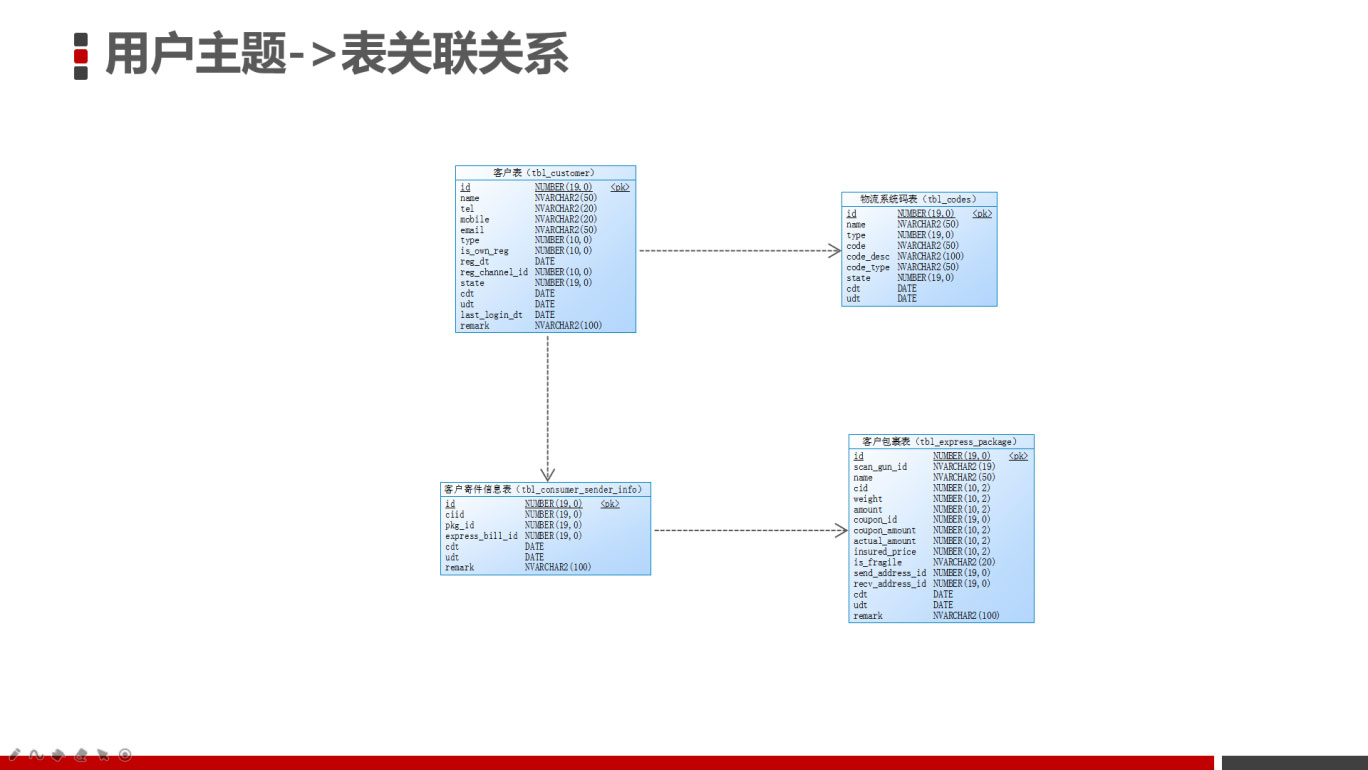
三、表关联关系
1、事实表
|
表名 |
描述 |
|
tbl_customer |
用户表 |
2、维度表
|
表名 |
描述 |
|
tbl_codes |
物流系统码表 |
|
tbl_consumer_sender_info |
客户寄件信息表 |
|
tbl_express_package |
快递包裹表 |
3、关联关系
用户表与维度表的关联关系如下:
四、客户数据拉宽开发
1、拉宽后的字段
|
表 |
字段名 |
别名 |
字段描述 |
|
tbl_customer |
id |
id |
客户ID |
|
tbl_customer |
name |
name |
客户姓名 |
|
tbl_customer |
tel |
tel |
客户电话 |
|
tbl_customer |
mobile |
mobile |
客户手机 |
|
tbl_customer |
|
|
客户邮箱 |
|
tbl_customer |
type |
type |
客户类型ID |
|
tbl_codes |
codeDesc |
type_name |
客户类型名称 |
|
tbl_customer |
isownreg |
is_own_reg |
是否自行注册 |
|
tbl_customer |
regdt |
regdt |
注册时间 |
|
tbl_customer |
regchannelid |
reg_channel_id |
注册渠道ID |
|
tbl_customer |
state |
state |
客户状态ID |
|
tbl_customer |
cdt |
cdt |
创建时间 |
|
tbl_customer |
udt |
udt |
修改时间 |
|
tbl_customer |
lastlogindt |
last_login_dt |
最后登录时间 |
|
tbl_customer |
remark |
remark |
备注 |
|
tbl_consumer_sender_info |
cdt |
first_cdt |
首次下单时间 |
|
tbl_consumer_sender_info |
cdt |
last_cdt |
尾次下单时间 |
|
tbl_express_package |
billCount |
billCount |
下单总数 |
|
tbl_express_package |
totalAmount |
totalAmount |
累计下单金额 |
|
tbl_customer |
yyyyMMdd(cdt) |
day |
创建时间 年月日格式 |
2、SQL语句
SELECT TC."id" ,TC."name" ,TC."tel",TC."mobile",TC."email",TC."type",TC."is_own_reg",TC."reg_dt",TC."reg_channel_id",TC."state",TC."cdt",TC."udt",TC."last_login_dt",TC."remark",customercodes."code_desc",sender_info.first_cdt AS first_sender_cdt ,sender_info.last_cdt AS last_sender_cdt, sender_info.billCount AS billCount, sender_info.totalAmount AS totalAmountFROM "tbl_customer" tc LEFT JOIN (SELECT "ciid", min(sender_info."id") first_id, max(sender_info."id") last_id, min(sender_info."cdt") first_cdt, max(sender_info."cdt") last_cdt,COUNT(sender_info."id" ) billCount,sum(express_package."actual_amount") totalAmountFROM "tbl_consumer_sender_info" sender_infoLEFT JOIN "tbl_express_package" express_packageON SENDER_INFO."pkg_id" =express_package."id"GROUP BY sender_info."ciid") sender_infoONtc."id" = sender_info."ciid"LEFT JOIN "tbl_codes" customercodes ON customercodes."type" =16 AND tc."type" =customercodes."code"
3、Spark实现
实现步骤:
- 在dwd目录下创建 CustomerDWD 单例对象,继承自OfflineApp特质
- 初始化环境的参数,创建SparkSession对象
- 获取客户表(tbl_customer)数据,并缓存数据
- 判断是否是首次运行,如果是首次运行的话,则全量装载数据(含历史数据)
- 获取客户寄件信息表(tbl_consumer_sender_info)数据,并缓存数据
- 获取客户包裹表(tbl_express_package)数据,并缓存数据
- 获取物流字典码表(tbl_codes)数据,并缓存数据
- 根据以下方式拉宽仓库车辆明细数据
- 根据客户id,在客户表中获取客户数据
- 根据包裹id,在包裹表中获取包裹数据
- 根据客户类型id,在物流字典码表中获取客户类型名称数据
- 创建客户明细宽表(若存在则不创建)
- 将客户明细宽表数据写入到kudu数据表中
- 删除缓存数据
3.1、初始化环境变量
初始化客户明细拉宽作业的环境变量
package cn.it.logistics.offline.dwdimport cn.it.logistics.common.{CodeTypeMapping, Configuration, OfflineTableDefine, SparkUtils}import cn.it.logistics.offline.OfflineAppimport org.apache.spark.SparkConfimport org.apache.spark.sql.{DataFrame, SparkSession}import org.apache.spark.storage.StorageLevelimport org.apache.spark.sql.functions._import org.apache.spark.sql.types.IntegerType/** * 客户主题数据的拉宽操作 */object CustomerDWD extends OfflineApp { //定义应用的名称 val appName = this.getClass.getSimpleName def main(args: Array[String]): Unit = { /** * 实现步骤: * 1)初始化sparkConf对象 * 2)创建sparkSession对象 * 3)加载kudu中的事实表和维度表的数据(将加载后的数据进行缓存) * 4)定义维度表与事实表的关联 * 5)将拉宽后的数据再次写回到kudu数据库中(DWD明细层) * 5.1:创建车辆明细宽表的schema表结构 * 5.2:创建车辆宽表(判断宽表是否存在,如果不存在则创建) * 5.3:将数据写入到kudu中 * 6)将缓存的数据删除掉 * 7)停止任务 */ //1)初始化sparkConf对象 val sparkConf: SparkConf = SparkUtils.autoSettingEnv( SparkUtils.sparkConf(appName) ) //2)创建sparkSession对象 val sparkSession: SparkSession = SparkUtils.getSparkSession(sparkConf) sparkSession.sparkContext.setLogLevel(Configuration.LOG_OFF) //数据处理 execute(sparkSession) } /** * 数据处理 * * @param sparkSession */ override def execute(sparkSession: SparkSession): Unit = { sparkSession.stop() }}
3.2、加载客户相关的表并缓存
- 加载客户表的时候,需要指定日期条件,因为客户主题最终需要Azkaban定时调度执行,每天执行一次增量数据,因此需要指定日期。
- 判断是否是首次运行,如果是首次运行的话,则全量装载数据(含历史数据)
//导入隐士转换import sparkSession.implicits._val customerSenderInfoDF: DataFrame = getKuduSource(sparkSession, TableMapping.consumerSenderInfo, Configuration.isFirstRunnable).persist(StorageLevel.DISK_ONLY_2)val customerDF = getKuduSource(sparkSession, TableMapping.customer, true).persist(StorageLevel.DISK_ONLY_2)val expressPageageDF = getKuduSource(sparkSession, TableMapping.expressPackage, true).persist(StorageLevel.DISK_ONLY_2)val codesDF: DataFrame = getKuduSource(sparkSession, TableMapping.codes, true).persist(StorageLevel.DISK_ONLY_2)val customerTypeDF = codesDF.where($"type" === CodeTypeMapping.CustomType)3.3、定义表的关联关系
- 为了在DWS层任务中方便的获取每日增量客户表数据(根据日期),因此在DataFrame基础上动态增加列(day),指定日期格式为yyyyMMdd
代码如下:
//TODO 4)定义维度表与事实表的关联关系val left_outer = "left_outer"/** * 获取每个用户的首尾单发货信息及发货件数和总金额 */val customerSenderDetailInfoDF: DataFrame = customerSenderInfoDF.join(expressPageageDF, expressPageageDF("id") === customerSenderInfoDF("pkgId"), left_outer) .groupBy(customerSenderInfoDF("ciid")) .agg(min(customerSenderInfoDF("id")).alias("first_id"), max(customerSenderInfoDF("id")).alias("last_id"), min(expressPageageDF("cdt")).alias("first_cdt"), max(expressPageageDF("cdt")).alias("last_cdt"), count(customerSenderInfoDF("id")).alias("totalCount"), sum(expressPageageDF("actualAmount")).alias("totalAmount") )val customerDetailDF: DataFrame = customerDF .join(customerSenderDetailInfoDF, customerDF("id") === customerSenderInfoDF("ciid"), left_outer) .join(customerTypeDF, customerDF("type") === customerTypeDF("code").cast(IntegerType), left_outer) .sort(customerDF("cdt").asc) .select( customerDF("id"), customerDF("name"), customerDF("tel"), customerDF("mobile"), customerDF("type").cast(IntegerType), customerTypeDF("codeDesc").as("type_name"), customerDF("isownreg").as("is_own_reg"), customerDF("regdt").as("regdt"), customerDF("regchannelid").as("reg_channel_id"), customerDF("state"), customerDF("cdt"), customerDF("udt"), customerDF("lastlogindt").as("last_login_dt"), customerDF("remark"), customerSenderDetailInfoDF("first_id").as("first_sender_id"), //首次寄件id customerSenderDetailInfoDF("last_id").as("last_sender_id"), //尾次寄件id customerSenderDetailInfoDF("first_cdt").as("first_sender_cdt"), //首次寄件时间 customerSenderDetailInfoDF("last_cdt").as("last_sender_cdt"), //尾次寄件时间 customerSenderDetailInfoDF("totalCount"), //寄件总次数 customerSenderDetailInfoDF("totalAmount") //总金额 )
3.4、创建客户明细宽表并将客户明细数据写入到kudu数据表中
客户明细宽表数据需要保存到kudu中,因此在第一次执行客户明细拉宽操作时,客户明细宽表是不存在的,因此需要实现自动判断宽表是否存在,如果不存在则创建
实现步骤:
- 在CustomerDWD 单例对象中调用save方法
实实现过程:
- 在CustomerDWD 单例对象Main方法中调用save方法
save(customerDetailDF, OfflineTableDefine.customerDetail)3.5、删除缓存数据
为了释放资源,客户明细宽表数据计算完成以后,需要将缓存的源表数据删除。
//移除缓存customerDetailDF.unpersistcodesDF.unpersistexpressPackageDF.unpersistcustomerSenderDF.unpersistcustomerDF.unpersist3.6、完整代码
package cn.it.logistics.offline.dwdimport cn.it.logistics.common.{CodeTypeMapping, Configuration, OfflineTableDefine, SparkUtils, TableMapping}import cn.it.logistics.offline.OfflineAppimport org.apache.spark.SparkConfimport org.apache.spark.sql.{DataFrame, SparkSession}import org.apache.spark.storage.StorageLevelimport org.apache.spark.sql.functions._import org.apache.spark.sql.types.IntegerType/** * 客户主题数据的拉宽操作 */object CustomerDWD extends OfflineApp { //定义应用的名称 val appName = this.getClass.getSimpleName def main(args: Array[String]): Unit = { /** * 实现步骤: * 1)初始化sparkConf对象 * 2)创建sparkSession对象 * 3)加载kudu中的事实表和维度表的数据(将加载后的数据进行缓存) * 4)定义维度表与事实表的关联 * 5)将拉宽后的数据再次写回到kudu数据库中(DWD明细层) * 5.1:创建车辆明细宽表的schema表结构 * 5.2:创建车辆宽表(判断宽表是否存在,如果不存在则创建) * 5.3:将数据写入到kudu中 * 6)将缓存的数据删除掉 * 7)停止任务 */ //1)初始化sparkConf对象 val sparkConf: SparkConf = SparkUtils.autoSettingEnv( SparkUtils.sparkConf(appName) ) //2)创建sparkSession对象 val sparkSession: SparkSession = SparkUtils.getSparkSession(sparkConf) sparkSession.sparkContext.setLogLevel(Configuration.LOG_OFF) //数据处理 execute(sparkSession) } /** * 数据处理 * * @param sparkSession */ override def execute(sparkSession: SparkSession): Unit = { //导入隐士转换 import sparkSession.implicits._ val customerSenderInfoDF: DataFrame = getKuduSource(sparkSession, TableMapping.consumerSenderInfo, Configuration.isFirstRunnable).persist(StorageLevel.DISK_ONLY_2) val customerDF = getKuduSource(sparkSession, TableMapping.customer, true).persist(StorageLevel.DISK_ONLY_2) val expressPageageDF = getKuduSource(sparkSession, TableMapping.expressPackage, true).persist(StorageLevel.DISK_ONLY_2) val codesDF: DataFrame = getKuduSource(sparkSession, TableMapping.codes, true).persist(StorageLevel.DISK_ONLY_2) val customerTypeDF = codesDF.where($"type" === CodeTypeMapping.CustomType) //TODO 4)定义维度表与事实表的关联关系 val left_outer = "left_outer" /** * 获取每个用户的首尾单发货信息及发货件数和总金额 */ val customerSenderDetailInfoDF: DataFrame = customerSenderInfoDF.join(expressPageageDF, expressPageageDF("id") === customerSenderInfoDF("pkgId"), left_outer) .groupBy(customerSenderInfoDF("ciid")) .agg(min(customerSenderInfoDF("id")).alias("first_id"), max(customerSenderInfoDF("id")).alias("last_id"), min(expressPageageDF("cdt")).alias("first_cdt"), max(expressPageageDF("cdt")).alias("last_cdt"), count(customerSenderInfoDF("id")).alias("totalCount"), sum(expressPageageDF("actualAmount")).alias("totalAmount") ) val customerDetailDF: DataFrame = customerDF .join(customerSenderDetailInfoDF, customerDF("id") === customerSenderInfoDF("ciid"), left_outer) .join(customerTypeDF, customerDF("type") === customerTypeDF("code").cast(IntegerType), left_outer) .sort(customerDF("cdt").asc) .select( customerDF("id"), customerDF("name"), customerDF("tel"), customerDF("mobile"), customerDF("type").cast(IntegerType), customerTypeDF("codeDesc").as("type_name"), customerDF("isownreg").as("is_own_reg"), customerDF("regdt").as("regdt"), customerDF("regchannelid").as("reg_channel_id"), customerDF("state"), customerDF("cdt"), customerDF("udt"), customerDF("lastlogindt").as("last_login_dt"), customerDF("remark"), customerSenderDetailInfoDF("first_id").as("first_sender_id"), //首次寄件id customerSenderDetailInfoDF("last_id").as("last_sender_id"), //尾次寄件id customerSenderDetailInfoDF("first_cdt").as("first_sender_cdt"), //首次寄件时间 customerSenderDetailInfoDF("last_cdt").as("last_sender_cdt"), //尾次寄件时间 customerSenderDetailInfoDF("totalCount"), //寄件总次数 customerSenderDetailInfoDF("totalAmount") //总金额 ) save(customerDetailDF, OfflineTableDefine.customerDetail) // 5.4:将缓存的数据删除掉 customerDF.unpersist() customerSenderInfoDF.unpersist() expressPageageDF.unpersist() customerTypeDF.unpersist() sparkSession.stop() }}五、客户数据指标开发
1、计算的字段
|
字段名 |
字段描述 |
|
id |
主键id(数据产生时间) |
|
customerTotalCount |
总客户数 |
|
addtionTotalCount |
今日新增客户数(注册时间为今天) |
|
lostCustomerTotalCount |
留存数(超过180天未下单表示已流失,否则表示留存) |
|
lostRate |
留存率 |
|
activeCount |
活跃用户数(近10天内有发件的客户表示活跃用户) |
|
monthOfNewCustomerCount |
月度新老用户数(应该是月度新用户!) |
|
sleepCustomerCount |
沉睡用户数(3个月~6个月之间的用户表示已沉睡) |
|
loseCustomerCount |
流失用户数(9个月未下单表示已流失) |
|
customerBillCount |
客单数 |
|
customerAvgAmount |
客单价 |
|
avgCustomerBillCount |
平均客单数 |
2、Spark实现
实现步骤:
- 在dws目录下创建 ConsumerDWS 单例对象,继承自OfflineApp特质
- 初始化环境的参数,创建SparkSession对象
- 根据指定的日期获取拉宽后的用户宽表(tbl_customer_detail)增量数据,并缓存数据
- 判断是否是首次运行,如果是首次运行的话,则全量装载数据(含历史数据)
- 指标计算
- 总客户数
- 今日新增客户数(注册时间为今天)
- 留存数(超过180天未下单表示已流失,否则表示留存)
- 留存率
- 活跃用户数(近10天内有发件的客户表示活跃用户)
- 月度新老用户数(应该是月度新用户!)
- 沉睡用户数(3个月~6个月之间的用户表示已沉睡)
- 流失用户数(9个月未下单表示已流失)
- 客单数
- 客单价
- 平均客单数
- 普通用户数
- 获取当前时间yyyyMMddHH
- 构建要持久化的指标数据(需要判断计算的指标是否有值,若没有需要赋值默认值)
- 通过StructType构建指定Schema
- 创建客户指标数据表(若存在则不创建)
- 持久化指标数据到kudu表
2.1、初始化环境变量
package cn.it.logistics.offline.dwsimport cn.it.logistics.common.{Configuration, DateHelper, OfflineTableDefine, SparkUtils}import cn.it.logistics.offline.OfflineAppimport org.apache.spark.SparkConfimport org.apache.spark.rdd.RDDimport org.apache.spark.sql.{DataFrame, Row, SparkSession}import org.apache.spark.sql.types.{DoubleType, LongType, Metadata, StringType, StructField, StructType}import org.apache.spark.sql.functions._import scala.collection.mutable.ArrayBuffer/** * 客户主题指标计算 */object CustomerDWS extends OfflineApp { //定义应用程序的名称 val appName = this.getClass.getSimpleName def main(args: Array[String]): Unit = { /** * 实现步骤: * 1)创建SparkConf对象 * 2)创建SparkSession对象 * 3)读取客户明细宽表的数据 * 4)对客户明细宽表的数据进行指标的计算 * 5)将计算好的指标数据写入到kudu数据库中 * 5.1:定义指标结果表的schema信息 * 5.2:组织需要写入到kudu表的数据 * 5.3:判断指标结果表是否存在,如果不存在则创建 * 5.4:将数据写入到kudu表中 * 6)删除缓存数据 * 7)停止任务,退出sparksession */ //TODO 1)创建SparkConf对象 val sparkConf: SparkConf = SparkUtils.autoSettingEnv( SparkUtils.sparkConf(appName) ) //TODO 2)创建SparkSession对象 val sparkSession: SparkSession = SparkUtils.getSparkSession(sparkConf) sparkSession.sparkContext.setLogLevel(Configuration.LOG_OFF) //处理数据 execute(sparkSession) } /** * 数据处理 * * @param sparkSession */ override def execute(sparkSession: SparkSession): Unit = {sparkSession.stop() }}2.2、加载客户宽表增量数据并缓存
加载客户宽表的时候,需要指定日期条件,因为客户主题最终需要Azkaban定时调度执行,每天执行一次增量数据,因此需要指定日期。
//TODO 3)读取客户明细宽表的数据(用户主题的数据不需要按照天进行增量更新,而是每天全量运行)val customerDetailDF = getKuduSource(sparkSession, OfflineTableDefine.customerDetail, Configuration.isFirstRunnable)2.3、指标计算
//定义数据集合val rows: ArrayBuffer[Row] = ArrayBuffer[Row]()//TODO 4)对客户明细宽表的数据进行指标的计算val customerTotalCount: Row = customerDetailDF.agg(count($"id").alias("total_count")).first()//今日新增客户数val addTotalCount: Long = customerDetailDF.where(date_format($"regDt", "yyyy-MM-dd").equalTo(DateHelper.getyesterday("yyyy-MM-dd"))).agg(count($"id")).first().getLong(0)//留存率(超过180天未下单表示已经流失,否则表示留存)//留存用户数//val lostCustomerTotalCount: Long = customerDetailDF.join(customerSenderInfoDF.where("cdt >= date_sub(now(), 180)"), customerDetailDF("id") === customerSenderInfoDF("ciid")).count()val lostCustomerTotalCount: Long = customerDetailDF.where("last_sender_cdt >= date_sub(now(), 180)").count()println(lostCustomerTotalCount)//留存率,超过180天未下单的用户数/所有的用户数val lostRate: Double = (lostCustomerTotalCount / (if (customerTotalCount.isNullAt(0)) 1D else customerTotalCount.getLong(0))).asInstanceOf[Number].doubleValue()println(lostRate)// 活跃用户数(近10天内有发件的客户表示活跃用户)val activeCount = customerDetailDF.where("last_sender_cdt>=date_sub(now(), 10)").count// 月度新老用户数(应该是月度新用户!)val monthOfNewCustomerCount = customerDetailDF.where($"regDt".between(trunc($"regDt", "MM"), date_format(current_date(), "yyyy-MM-dd"))).count// 沉睡用户数(3个月~6个月之间的用户表示已沉睡)val sleepCustomerCount = customerDetailDF.where("last_sender_cdt>=date_sub(now(), 180) and last_sender_cdt=date_sub(now(), 270)").countprintln(loseCustomerCount)// 客单数val customerSendInfoDF = customerDetailDF.where("first_sender_id is not null")val customerBillCountAndAmount: Row = customerSendInfoDF.agg(sum("totalCount").alias("totalCount"), sum("totalAmount").alias("totalAmount")).first()// 客单价val customerAvgAmount = customerBillCountAndAmount.get(1).toString.toDouble / customerBillCountAndAmount.get(0).toString.toDouble //总金额/总件数println(customerAvgAmount)// 平均客单数val avgCustomerBillCount = customerSendInfoDF.count / customerDetailDF.count// 获取昨天时间yyyyMMddval cdt = DateHelper.getyesterday("yyyyMMdd")// 构建要持久化的指标数据val rowInfo = Row( cdt, if (customerTotalCount.isNullAt(0)) 0L else customerTotalCount.get(0).asInstanceOf[Number].longValue(), addTotalCount, lostCustomerTotalCount, lostRate, activeCount, monthOfNewCustomerCount, sleepCustomerCount, loseCustomerCount, if (customerBillCountAndAmount.isNullAt(0)) 0L else customerBillCountAndAmount.get(0).asInstanceOf[Number].longValue(), customerAvgAmount, avgCustomerBillCount)rows.append(rowInfo)
2.4、通过StructType构建指定Schema
import sparkSession.implicits._val schema = StructType(Array( StructField("id", StringType, true, Metadata.empty), StructField("customerTotalCount", LongType, true, Metadata.empty), StructField("addtionTotalCount", LongType, true, Metadata.empty), StructField("lostCustomerTotalCount", LongType, true, Metadata.empty), StructField("lostRate", DoubleType, true, Metadata.empty), StructField("activeCount", LongType, true, Metadata.empty), StructField("monthOfNewCustomerCount", LongType, true, Metadata.empty), StructField("sleepCustomerCount", LongType, true, Metadata.empty), StructField("loseCustomerCount", LongType, true, Metadata.empty), StructField("customerBillCount", LongType, true, Metadata.empty), StructField("customerAvgAmount", DoubleType, true, Metadata.empty), StructField("avgCustomerBillCount", LongType, true, Metadata.empty)))
2.5、持久化指标数据到kudu表
// 5.2:组织要写入到kudu表的数据val data: RDD[Row] = sparkSession.sparkContext.makeRDD(rows)val quotaDF: DataFrame = sparkSession.createDataFrame(data, schema)save(quotaDF, OfflineTableDefine.customerSummery)2.6、完整代码
package cn.it.logistics.offline.dwsimport cn.it.logistics.common.{Configure, DateHelper, OfflineTableDefine, SparkUtils}import cn.it.logistics.offline.OfflineAppimport cn.it.logistics.offline.dws.ExpressBillDWS.{appName, execute}import org.apache.spark.SparkConfimport org.apache.spark.rdd.RDDimport org.apache.spark.sql.{DataFrame, Row, SparkSession}import org.apache.spark.sql.functions._import org.apache.spark.sql.types.{DoubleType, LongType, Metadata, StringType, StructField, StructType}import scala.collection.mutable.ArrayBuffer/** * 客户主题开发 * 读取客户明细宽表的数据,然后进行指标开发,将结果存储到kudu表中(DWS层) */object ConsumerDWS extends OfflineApp{ //定义应用的名称 val appName: String = this.getClass.getSimpleName /** * 入口函数 * @param args */ def main(args: Array[String]): Unit = { /** * 实现步骤: * 1)创建sparkConf对象 * 2)创建SparkSession对象 * 3)读取客户宽表数据(判断是全量装载还是增量装载),将加载的数据进行缓存 * 4)对客户明细表的数据进行指标计算 * 5)将计算好的数写入到kudu表中 * 5.1)定义写入kudu表的schema结构信息 * 5.2)将组织好的指标结果集合转换成RDD对象 * 5.3)创建表,写入数据 * 6)删除缓存,释放资源 * 7)停止作业,退出sparkSession */ //TODO 1)创建sparkConf对象 val sparkConf: SparkConf = SparkUtils.autoSettingEnv( SparkUtils.sparkConf(appName), SparkUtils.parameterParser(args) ) //TODO 2)创建SparkSession对象 val sparkSession: SparkSession = SparkUtils.getSparkSession(sparkConf) sparkSession.sparkContext.setLogLevel(Configure.LOG_OFF) //执行数据处理的逻辑 execute(sparkSession) } /** * 数据处理 * * @param sparkSession */ override def execute(sparkSession: SparkSession): Unit = { //TODO 3)读取客户明细宽表的数据(用户主题的数据不需要按照天进行增量更新,而是每天全量运行) val customerDetailDF: DataFrame = getKuduSource(sparkSession, OfflineTableDefine.customerDetail, true) import sparkSession.implicits._ val schema = StructType(Array( StructField("id", StringType, true, Metadata.empty), StructField("customerTotalCount", LongType, true, Metadata.empty), StructField("addtionTotalCount", LongType, true, Metadata.empty), StructField("lostCustomerTotalCount", LongType, true, Metadata.empty), StructField("lostRate", DoubleType, true, Metadata.empty), StructField("activeCount", LongType, true, Metadata.empty), StructField("monthOfNewCustomerCount", LongType, true, Metadata.empty), StructField("sleepCustomerCount", LongType, true, Metadata.empty), StructField("loseCustomerCount", LongType, true, Metadata.empty), StructField("customerBillCount", LongType, true, Metadata.empty), StructField("customerAvgAmount", DoubleType, true, Metadata.empty), StructField("avgCustomerBillCount", LongType, true, Metadata.empty), StructField("normalCustomerCount", LongType, true, Metadata.empty) )) //定义数据集合 val rows: ArrayBuffer[Row] = ArrayBuffer[Row]() //TODO 4)对客户明细宽表的数据进行指标的计算 val customerTotalCount: Row = customerDetailDF.agg(count($"id").alias("total_count")).first() //今日新增客户数 val addTotalCount: Long = customerDetailDF.where(date_format($"regDt", "yyyy-MM-dd").equalTo(DateHelper.getyestday("yyyy-MM-dd"))).agg(count($"id")).first().getLong(0) //留存率(超过180天未下单表示已经流失,否则表示留存) //留存用户数 //val lostCustomerTotalCount: Long = customerDetailDF.join(customerSenderInfoDF.where("cdt >= date_sub(now(), 180)"), customerDetailDF("id") === customerSenderInfoDF("ciid")).count() val lostCustomerTotalCount: Long = customerDetailDF.where("last_sender_cdt >= date_sub(now(), 180)").count() println(lostCustomerTotalCount) //留存率,超过180天未下单的用户数/所有的用户数 val lostRate: Double = (lostCustomerTotalCount / (if (customerTotalCount.isNullAt(0)) 1D else customerTotalCount.getLong(0))).asInstanceOf[Number].doubleValue() println(lostRate) // 活跃用户数(近10天内有发件的客户表示活跃用户) val activeCount = customerDetailDF.where("last_sender_cdt>=date_sub(now(), 10)").count // 月度新老用户数(应该是月度新用户!) val monthOfNewCustomerCount = customerDetailDF.where($"regDt".between(trunc($"regDt", "MM"), date_format(current_date(), "yyyy-MM-dd"))).count // 沉睡用户数(3个月~6个月之间的用户表示已沉睡) val sleepCustomerCount = customerDetailDF.where("last_sender_cdt>=date_sub(now(), 180) and last_sender_cdt=date_sub(now(), 270)").count println(loseCustomerCount) // 客单数 val customerSendInfoDF = customerDetailDF.where("first_sender_id is not null") val customerBillCountAndAmount: Row = customerSendInfoDF.agg(sum("totalCount").alias("totalCount"), sum("totalAmount").alias("totalAmount")).first() // 客单价 val customerAvgAmount = customerBillCountAndAmount.get(1).toString.toDouble / customerBillCountAndAmount.get(0).toString.toDouble //总金额/总件数 println(customerAvgAmount) // 平均客单数 val avgCustomerBillCount = customerSendInfoDF.count / customerDetailDF.count // 普通用户数 val normalCustomerRow: Row = customerDetailDF.where("type=1").agg(count($"id").alias("total_count")).first() println(normalCustomerRow) val normalCustomerCount: Long = if (normalCustomerRow.isNullAt(0)) 0L else normalCustomerRow.get(0).asInstanceOf[Number].longValue() // 获取昨天时间yyyyMMdd val cdt = DateHelper.getyestday("yyyyMMdd") // 构建要持久化的指标数据 val rowInfo = Row( cdt, if (customerTotalCount.isNullAt(0)) 0L else customerTotalCount.get(0).asInstanceOf[Number].longValue(), addTotalCount, lostCustomerTotalCount, lostRate, activeCount, monthOfNewCustomerCount, sleepCustomerCount, loseCustomerCount, if (customerBillCountAndAmount.isNullAt(0)) 0L else customerBillCountAndAmount.get(0).asInstanceOf[Number].longValue(), customerAvgAmount, avgCustomerBillCount, normalCustomerCount ) rows.append(rowInfo) // 5.2:组织要写入到kudu表的数据 val data: RDD[Row] = sparkSession.sparkContext.makeRDD(rows) val quotaDF: DataFrame = sparkSession.createDataFrame(data, schema) save(quotaDF, OfflineTableDefine.customerSummery) //删除缓存,释放资源 customerDetailDF.unpersist() sparkSession.stop() }}- 📢博客主页:https://lansonli.blog.csdn.net
- 📢欢迎点赞 👍 收藏 ⭐留言 📝 如有错误敬请指正!
- 📢本文由 Lansonli 原创,首发于 CSDN博客🙉
- 📢停下休息的时候不要忘了别人还在奔跑,希望大家抓紧时间学习,全力奔赴更美好的生活✨