第九章:scrapy、gerapy与定时爬虫-[基于Vue、Django、supermap iserver和gerapy的生态旅游web系统开发实例]
本章介绍将scrapy打包成BS端爬虫
- 简介:
Gerapy是一款由国人利用Django框架(Python)开发的分布式爬虫管理框架,支持中文,特点是UI精美、代码编辑、持续优化的特点。共分为主机管理、项目管理、任务管理模块。
Gerapy 可以帮助我们:
1.更方便地控制爬虫运行
2.更统一地实现主机管理
3.更实时地查看爬取结果
4.更简单地实现项目部署
5.更直观地查看爬虫状态
6.在线修改爬虫代码
7.定时任务实现自动化爬虫
8.分布式爬虫
- 各管理模块功能
主机管理:分布式,一个电脑代表一个主机
项目管理:一个项目代表一个爬虫,每个项目通过“打包部署”均可搭载在不同的主机(电脑)上,-------用于进行在线代码编辑的地方
任务管理:设置定时任务,实现自动化爬虫
- 操作步骤
3.1 环境部署(默认已安装scrapy)
Scrapyd下载
Gerapy下载(均可通过pip命令下载)
Scrapyd安装部署:Scrapyd的安装与部署_u010476994的博客-CSDN博客_scrapyd安装
Gerapy安装部署
Gerapy安装与配置使用_Cage小哥哥的博客-CSDN博客
3.2 操作步骤
1.在web项目上并列创建文件夹,在此命名为gerapy
进入gerapy文件,创建scrapyd文件夹(用于存放scrapyd内置数据库),进入文件夹中,在scrapyd文件夹中cmd命令“scrapyd”,让scrapyd保持运行,在gerapy文件夹中cmd命令“gerapy init”,项目结构如下:

2. 将写好的爬虫项目复制到project文件夹,然后cmd命令“gerapy migrate”,gerapy createsuperuser(创建用户),
输入Username:
Email:可以不用直接回车
Password
3.cmd命令“gerapy runserver”,启动gerapy(进入页面一直加载的话可以退出账号,在登陆一遍,gerapy框架存在一些bug)
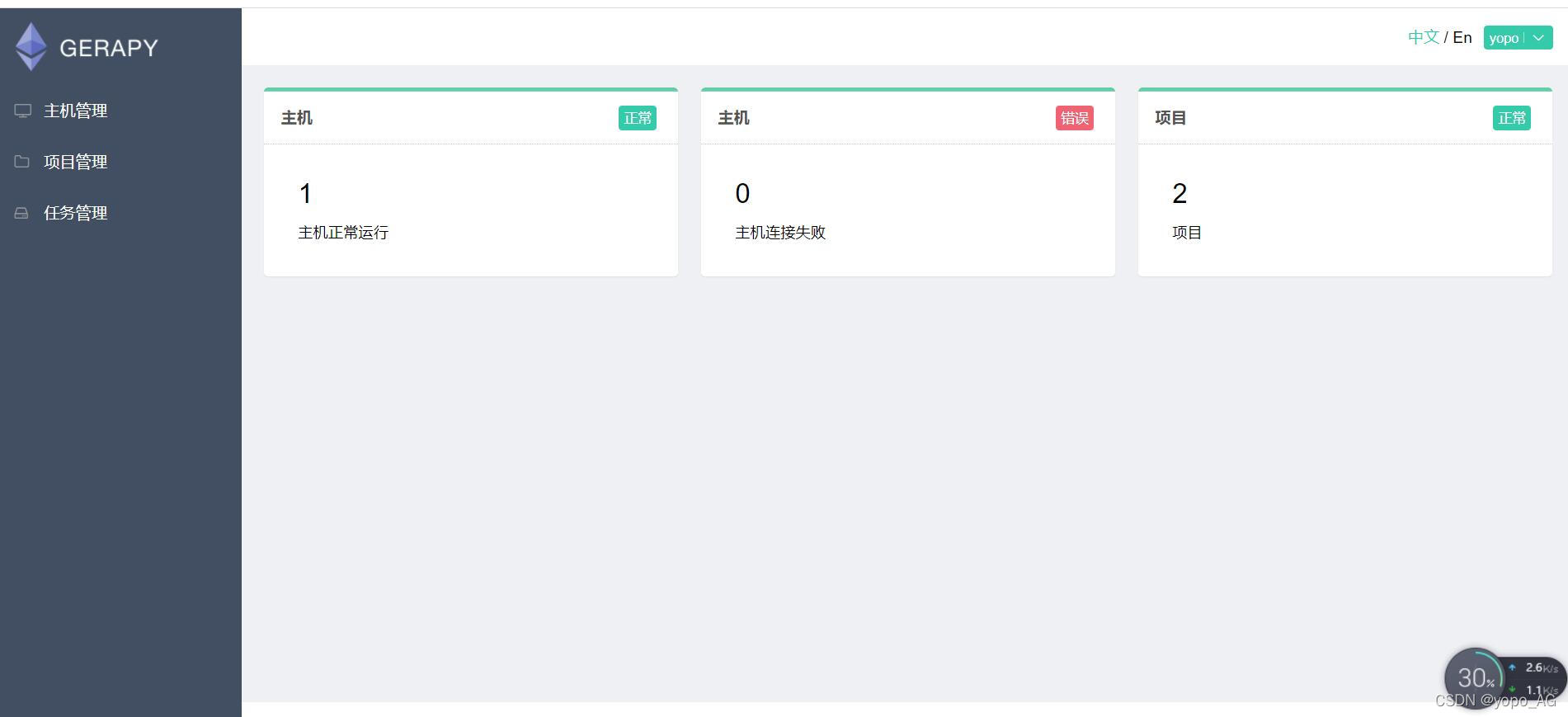
- gerapy主机管理、项目管理、任务管理操作可参考
Scrapy入门到放弃07:scrapyd、gerapy,界面化启停爬虫_CatchLight的博客-CSDN博客_gerapy scrapyd
- 定时任务遇到的问题
在任务管理创建定时任务后,点击“状态”显示加载失败。
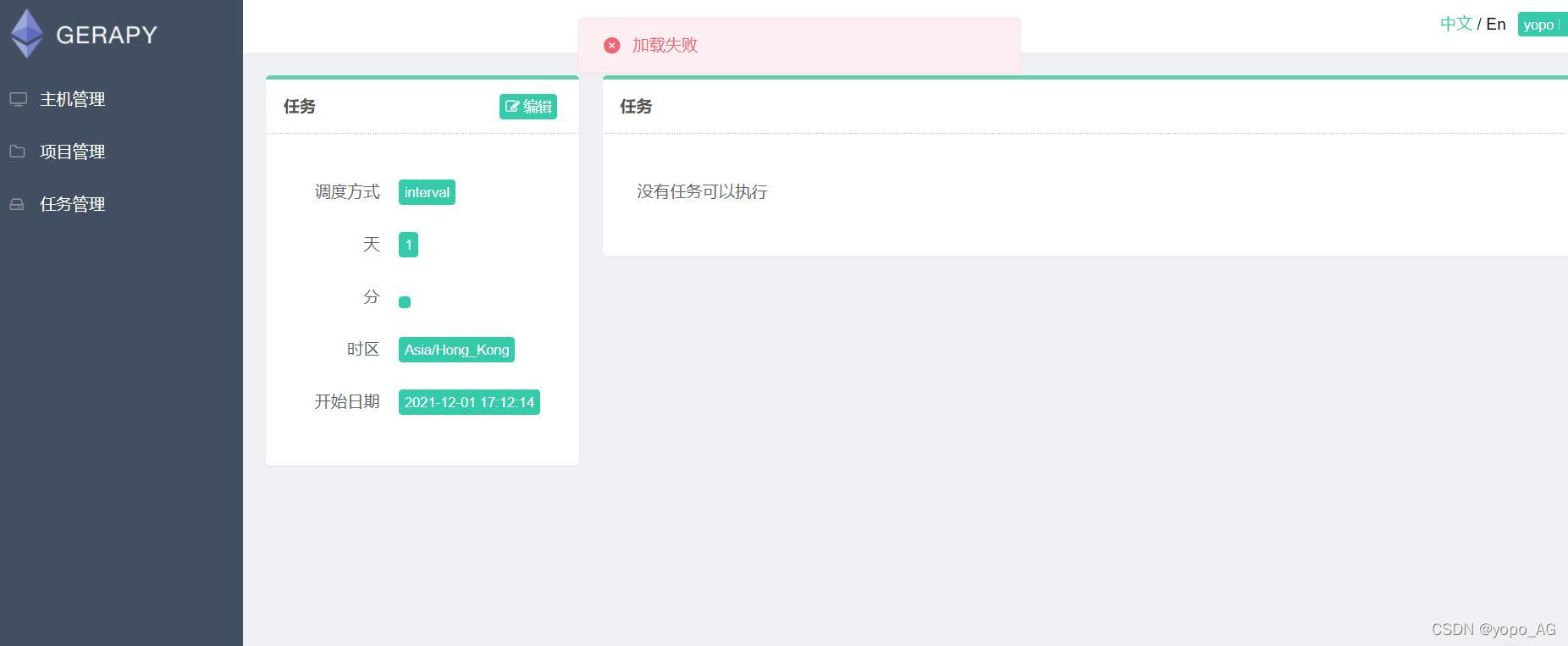
解决:可以不用理会这个错误,每次设置完和修改定时任务后,需要将scrapyd和gerap重新启动才会开始执行,后面挂载就行,可以实现定时自动爬虫,亲测有效。
- 关于在线编辑功能的思考
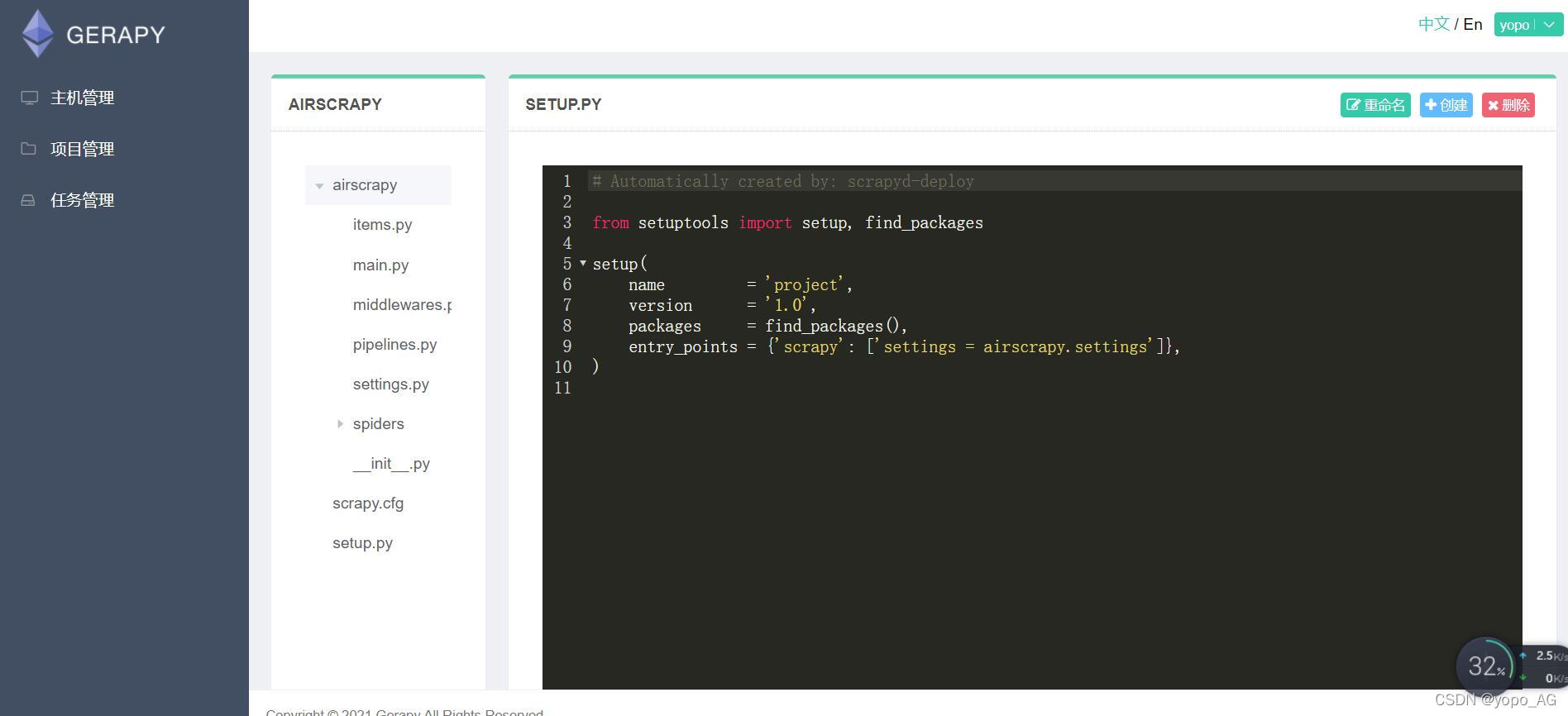
在项目管理点击“编辑”,可以查看爬虫项目结构和代码,可以在上面进行爬取对象与存储对象的修改,方便爬虫项目维护,后台管理人员可根据需求实时更新,避免二次打包。
上一章-第八章:百度API地图及热力图-[基于Vue、Django、supermap iserver和gerapy的生态旅游web系统开发实例]
下一章-第十章:nginx部署上线-[基于Vue、Django、supermap iserver和gerapy的生态旅游web系统开发实例]