Unity引擎中制作UI动画-Animation Clip_unity ui动画
Unity中的动画主要是三种来源:
-
在Unity引擎中制作动画Animation Clip:适用于UI动画
-
从外部工具(如3ds Max、Maya等)导入动画:适用于模型场景动画
-
使用代码制作的动画:使用于简单的动画
-
Timeline系统:适合同时对场景中多个物体制作复杂动画,还能包含音频,自定义的动画内容。
Animation Clip:动画系统基于一种名为Animation Clip(动画剪辑)的资源,这些资源以文件的形式存在工程中。这些文件内的数据记录了物体如何随着时间移动、旋转、缩放,物体上的属性如何随着时间变化。每一个Clip文件是一段动画。
Animator:Animation Clip只是一段动画数据,你可以把它类比成视频文件,而Animator组件是一个播放器,用来控制动画的播放、多个动画片段之间的切换等。
1.打开动画窗口
Animator 程序控制播放、切换
Animation
按个人的习惯调整好窗口位置
2.新建动画
动画片段可编辑物体及其所有的子物体,在想控制的物体创建动画,取名并放在对应的文件夹下
取名:界面动画名:一般根据界面名+动画名
动画控制器默认为节点名,推荐使用界面
( 动画控制的节点,结构命名改变会丢失引用)
3.录制动画
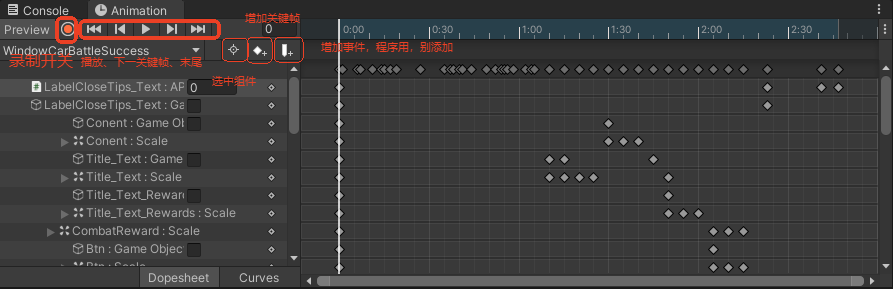 点击录制
点击录制
选中时间
默认情况下,动画的帧速率是60
添加关键帧
1.录制时选中物体,修改相应的值
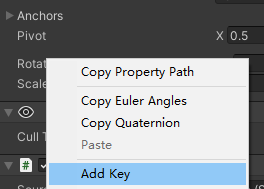
2.也可以右键点击对应的属性,在弹出菜单中点击Add Key即可添加关键帧,不在录制也可以
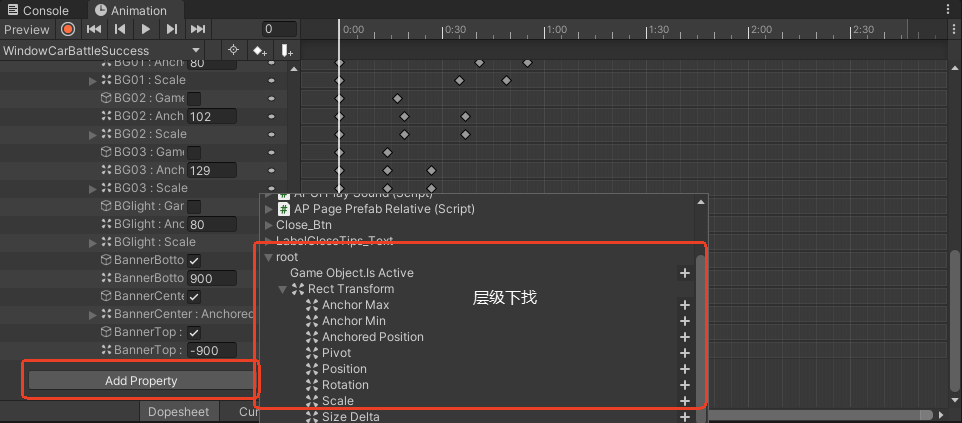
3.动画窗口中的\"Add Property\"按钮,在展开的层级中,找到子对象及其动画属性
使用于子物体也有动画
4.复制粘贴关键帧
在子对象的动画剪辑中创建所需的关键帧,选择这些关键帧并复制(Ctrl+C)
切换到父对象的动画剪辑,在动画窗口的时间轴上定位到想要粘贴的位置
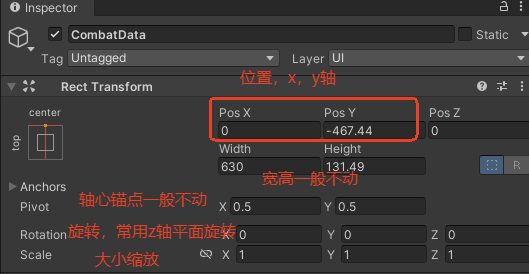
UI常见修改
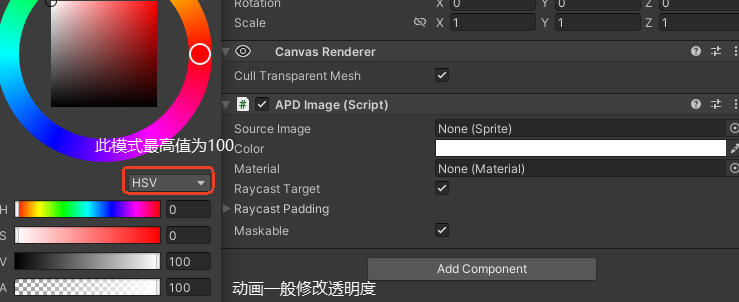
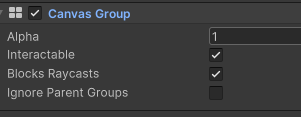
透明度修改只影响对应的图片、字体,想控制所有子物体的透明度,需添加组件
Canvas Group ,1为不透明
4.编辑动画
曲线编辑动画
选中对应的属性,点击Curves切换为曲线模式,进一步调节关键帧之间的数值是如何过渡的
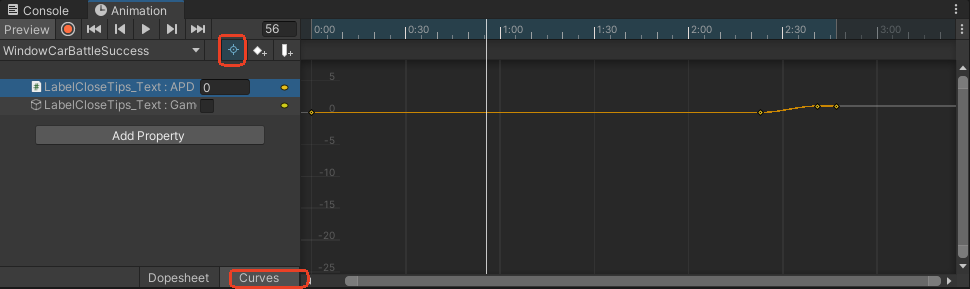
编辑关键帧
编辑关键帧时,可以多选(在Curve编辑中同理):
按住Shift或Ctrl,再点击关键帧可以选中多个关键帧。通过框选多选关键帧
按住Shift或Ctrl的同时框选,可以添加或移除框选住的关键帧
进行位移-调整出现时间,拉伸-调整快慢

如果你想让后方的关键帧也跟着移动,可以按住R键,同时拖拽这些关键帧。这种编辑方式叫做Ripple Edit(在音视频编辑软件中很常见)。缩放同理。
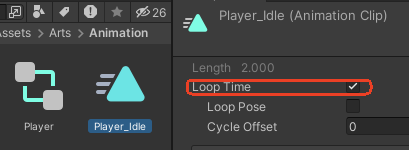
循环动画
选中Animation Clip文件,勾选是否循环Loop
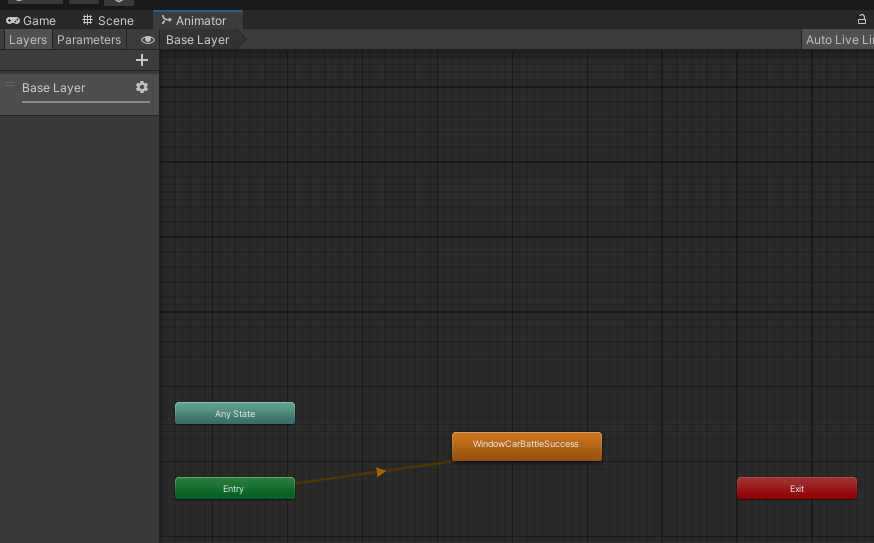
5.动画控制器
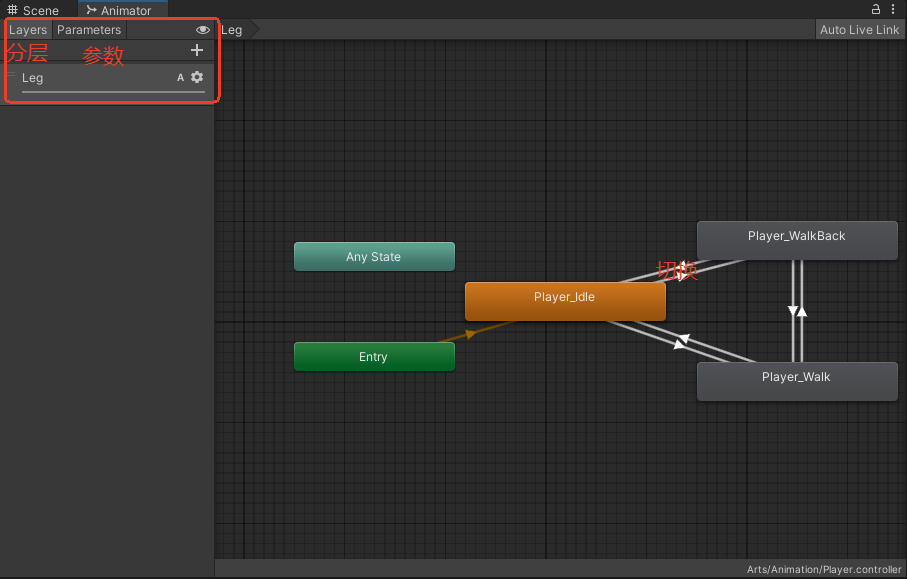
长方块即状态、状态一般为空或动画、动画可从资源中拖拽加入。
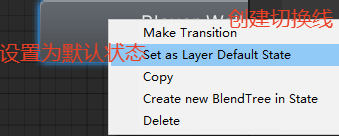
黄色为默认状态,即首先播放的动画
带箭头的线即动画的切换,通过条件切换状态
Layers分层
用于融合动画,比如将腿部的动画和上半身的动画分开,UI动画一般不需要
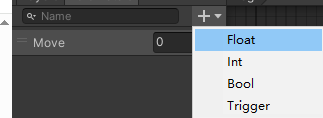
Parameter参数
用于切换动画所需要的限制,分别为浮点数(小数)、整型(整数)、布尔值(0或1,即是或不是)、触发器(触发一次后返回原来的动画)
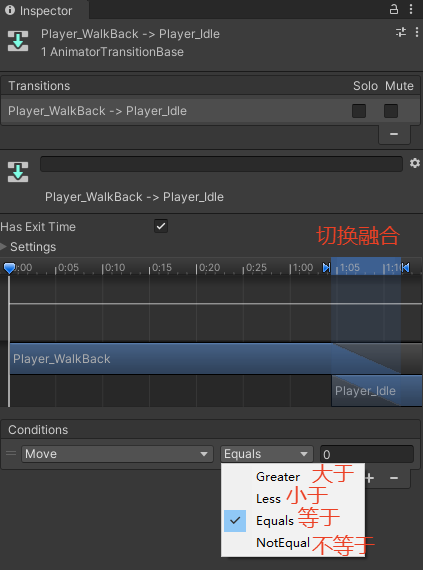
游戏运行中,可以根据参数的变化切换状态(动画)
切换融合是根据上个动画的末尾帧和下个动画的首帧进行计算融合,UI动画一般不需要

