文章目录
- 1. 认识红黑树
-
- 1.1 红黑树的规则
- 1.2 红黑树如何确保最长路径不超过最短路径的2倍呢?
- 1.3 红黑树的效率
- 2. 实现红黑树
-
- 2.1 红黑树的结构
- 2.2 红黑树的插入
-
- 2.2.1 第一种情况:插入节点的父节点和其uncle节点都为红色,且uncle节点存在
- 2.2.2 第2种情况:插入节点cur和其父节点为红,其uncle节点不存在或者为黑色
- 2.2.3 第3种情况:uncle节点不存在或者为黑色,且cur节点和parent节点为红
- 2.3 红黑树的查找
- 2.4 红黑树的验证
- 3. 代码

前面我们学过了控制二叉搜索树平衡的AVL树,今天我们就来学习控制二叉搜索树平衡的另一种—红黑树
1. 认识红黑树
- 红黑树(Red-Black Tree)是一种自平衡的二叉查找树(BST),通过特定的规则和旋转操作维持树的平衡,从而保证高效的查找、插入和删除操作。它的核心用途是在动态数据集中提供对数时间复杂度(
O(logN))的搜索、插入和删除性能,尤其适用于需要频繁修改且要求高效查询的场景
- 红黑树是⼀棵二叉搜索树,他的每个结点增加一个存储位来表示结点的颜色,可以是红色或者黑色。通过对任何一条从根到叶子的路径上各个结点的颜色进行约束,红黑树确保没有一条路径会比其他路径长出2倍,因而是接近平衡的
1.1 红黑树的规则
- 每个节点不是红色就是黑色
- 根节点是黑色的
- 如果一个节点是红色的,那么它的两个孩子节点必须是黑色的,也就是说任意一条路径不会有连续的红色节点
- 对于任意一条路径,从该节点到其所有NULL节点的简单路径上,均包含相同数量的黑色节点
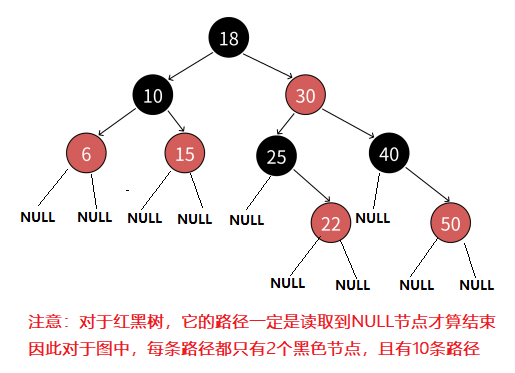
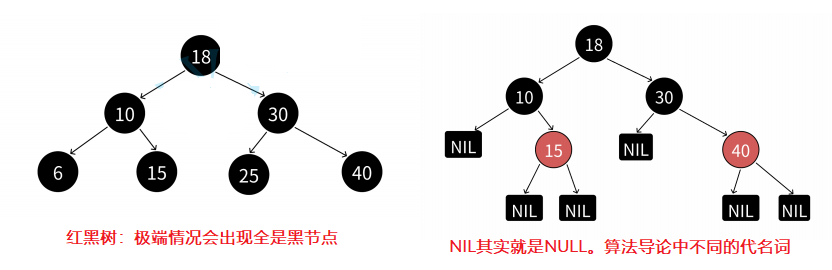
1.2 红黑树如何确保最长路径不超过最短路径的2倍呢?
- 由规则4可知,从根到NULL结点的每条路径都有相同数量的黑色结点,所以极端场景下,最短路径就就是全是黑色结点的路径,假设最短路径长度为bh(black height)
- 由规则2和规则3可知,任意一条路径不会有连续的红色结点,所以极端场景下,最长的路径就是一黑一红间隔组成,那么最长路径的长度为2*bh
- 综合红黑树的4点规则而言,理论上的全黑最短路径和一黑一红的最长路径并不是在每棵红黑树都存在的。假设任意一条从根到NULL结点路径的长度为x,那么bh <= x <= 2*bh
1.3 红黑树的效率
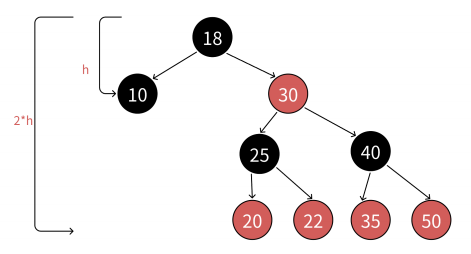
- 假设N是红黑树树中结点数量,h最短路径的长度,那么 , 由此推出
h ≈ logN,也就是意味着红黑树增删查改最坏也就是走最长路径 ,那么时间复杂度还是O(logN)
- 红黑树的表达相对AVL树要抽象⼀些,AVL树通过高度差直观的控制了平衡。红黑树通过4条规则的颜色约束,间接的实现了近似平衡,他们效率都是同⼀档次,但是相对而言,插入相同数量的节点,红黑树的旋转次数是更少的,因为他对平衡的控制没那么严格
2. 实现红黑树
2.1 红黑树的结构
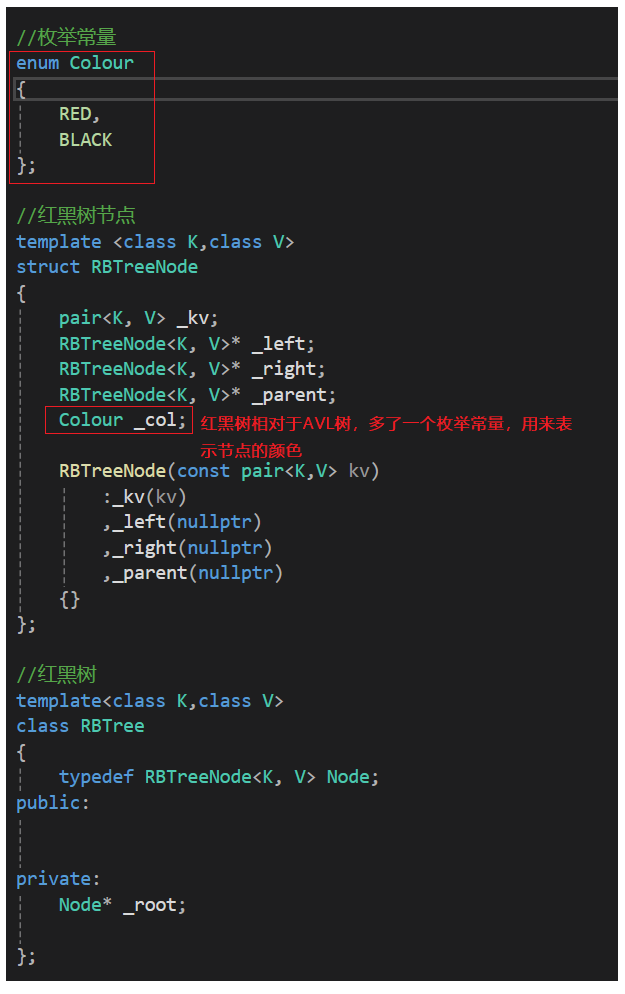
2.2 红黑树的插入
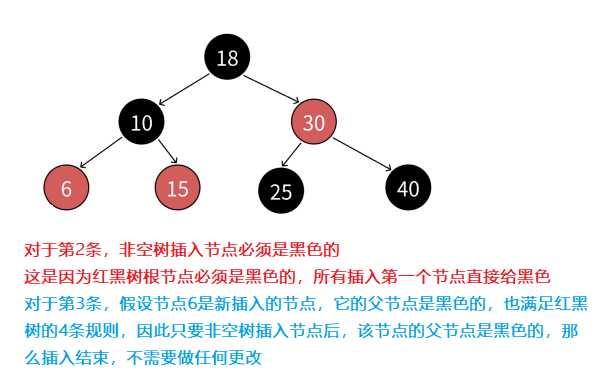
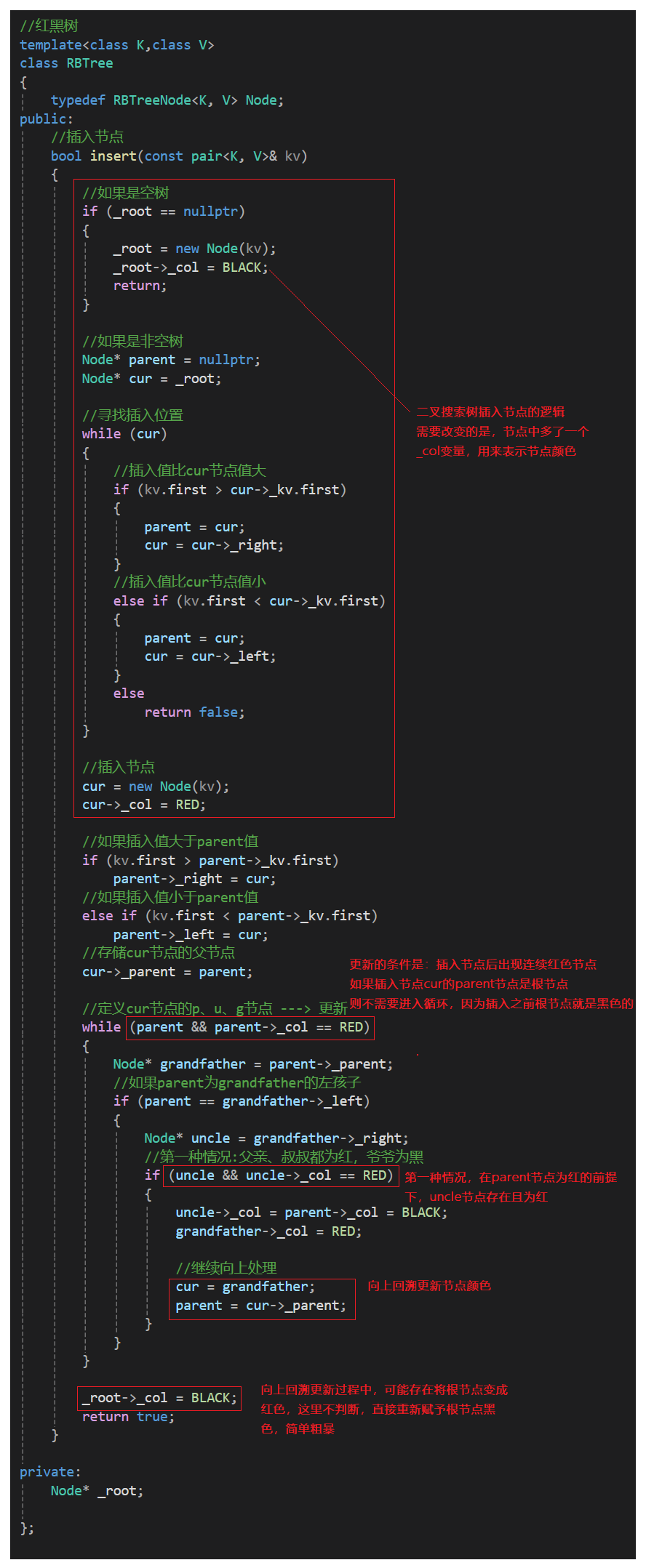
- 1. 红黑树插入一个值按照二叉搜索树的方式插入,插入后只需要观察是否满足红黑树的4条规则
- 2. 如果是空树插入,那么新插入的节点要给黑色。但如果是非空树插入,那么新插入的节点则必须是红色,因为如果是黑色,就破坏了红黑树任意路径黑色节点相同的规则
- 3.非空树插入红色节点后,如果它的父节点是黑色的,那么满足4条规则,插入结束
- 4.如果非空树插入红色节点后,其父节点是红色的,则违反了红黑树任意一条路径中不能出现连续红色节点的规则,得进一步分析
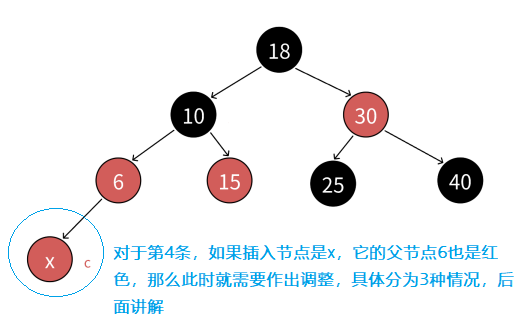
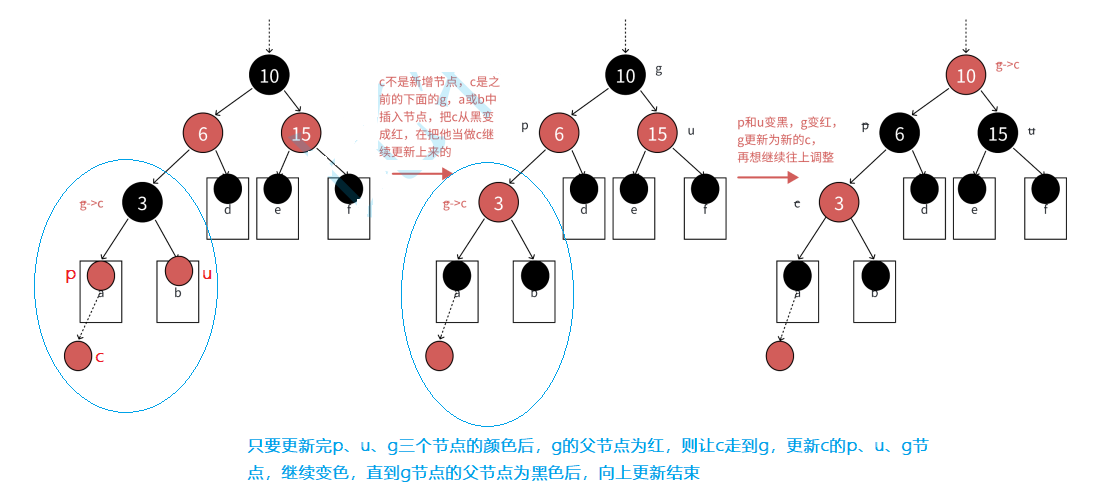
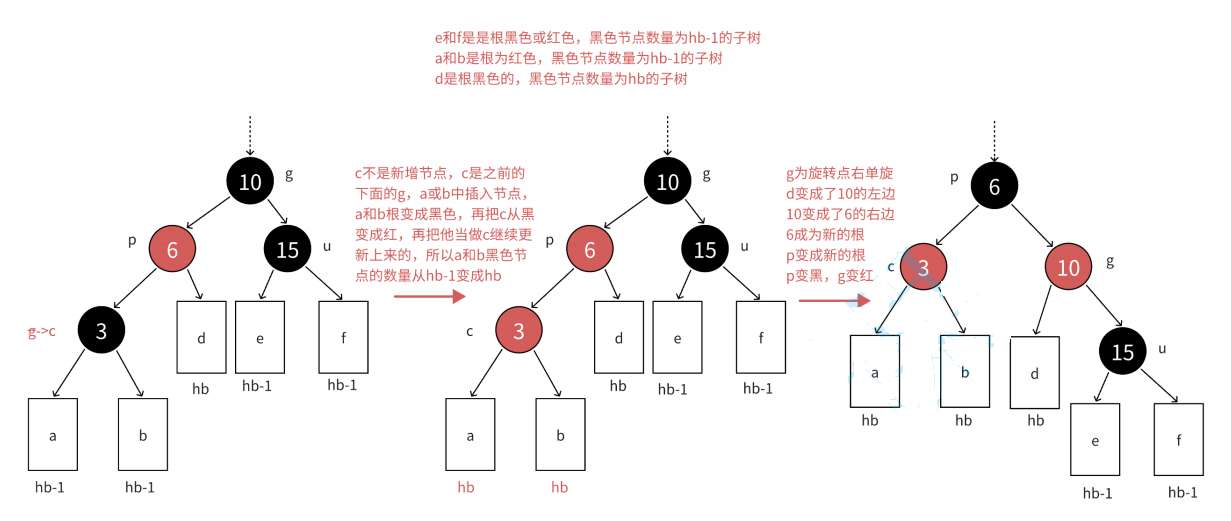
2.2.1 第一种情况:插入节点的父节点和其uncle节点都为红色,且uncle节点存在
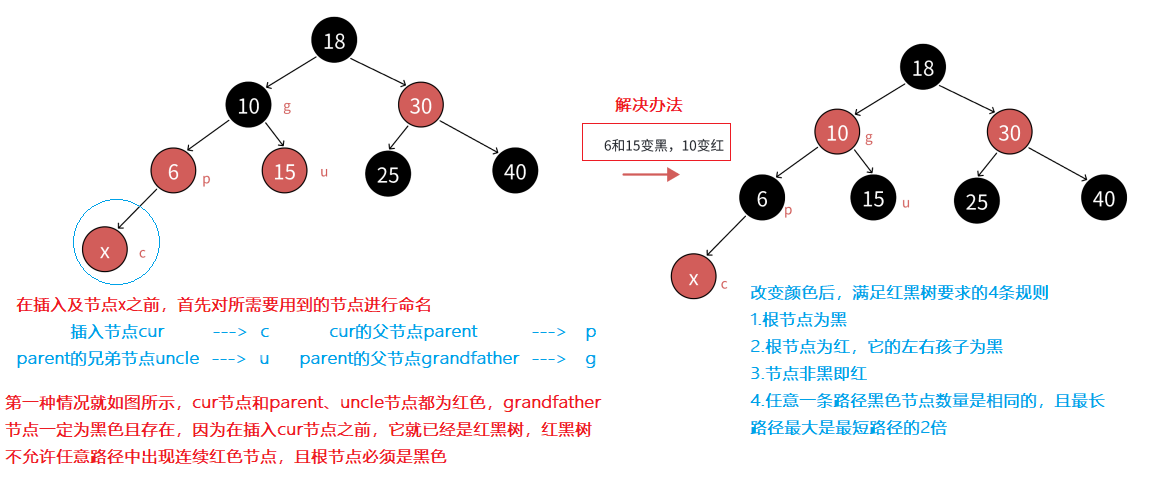
- 注意:上述图中只是最简单的一种,无非就是将cur的父节点parent和uncle节点变色(红→黑),再将grandfather节点变色(黑→红)
- 另外cur节点无论插在parent的左边还是右边,都满足上述的变色逻辑
- 当然上图中这颗树可能也只是棵子树,需要继续向上更新,那什么时候向上更新呢?
- 向上更新的条件:
g节点的父节点是红色时,p、u、g节点变色后需继续向上更新
- 为什么说g节点的父节点是红色就得继续更新呢?因为g节点变完色后是红色,红黑树不允许出现连续的红色节点
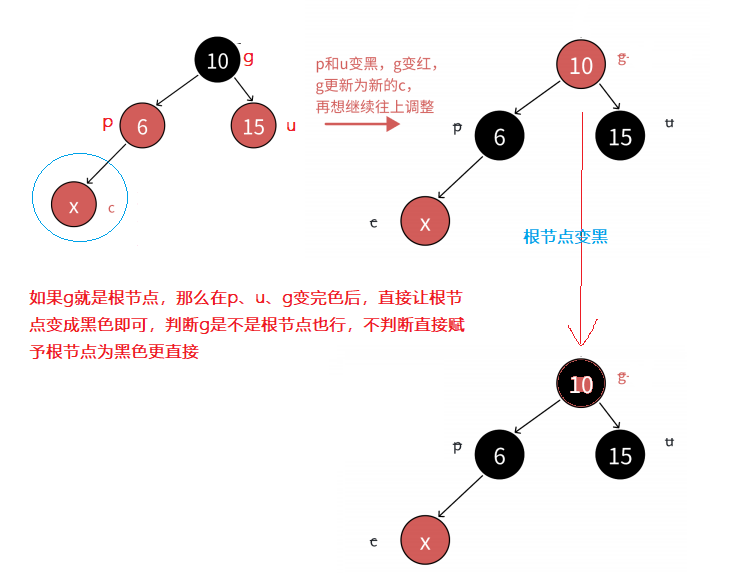
- 向上更新步骤:p、u、g节点变完色后,直接让cur等于g节点,然后p、u、g节点随着cur节点更新而更新,直到g节点的父节点为黑,插入结束
- 当然,如果grandfather就是根节点,那么p、u、g节点变完色后,直接让g节点重新变为黑色,插入结束
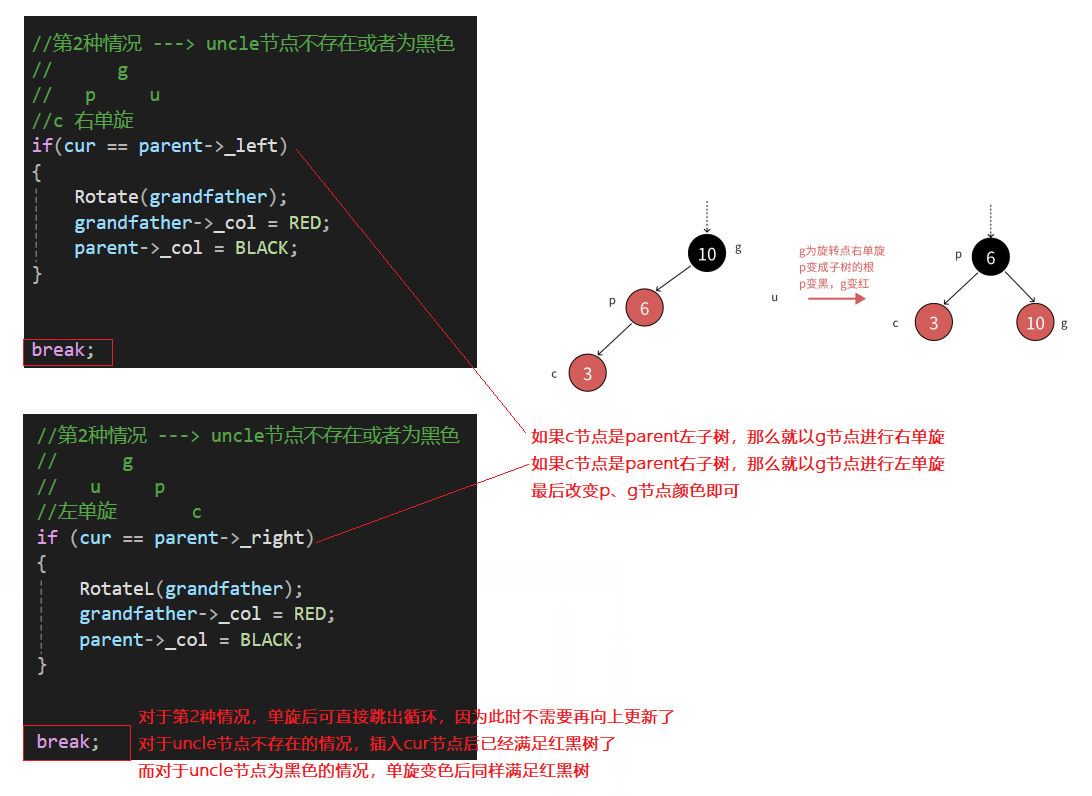
2.2.2 第2种情况:插入节点cur和其父节点为红,其uncle节点不存在或者为黑色
- 这种情况一般是:如果parent是grandfather左子树节点,cur节点也是p左孩子的情况;或者parent是grandfather右子树节点,cur节点也是p右孩子的情况
- 因此第2种情况就是:cur节点和parent节点是它们的父节点的左孩子/右孩子方向是保持一致的
- 对于uncle节点不存在的情况,则是直接以节点g为旋转点进行右单旋,然后分别让p节点变红,g节点变黑
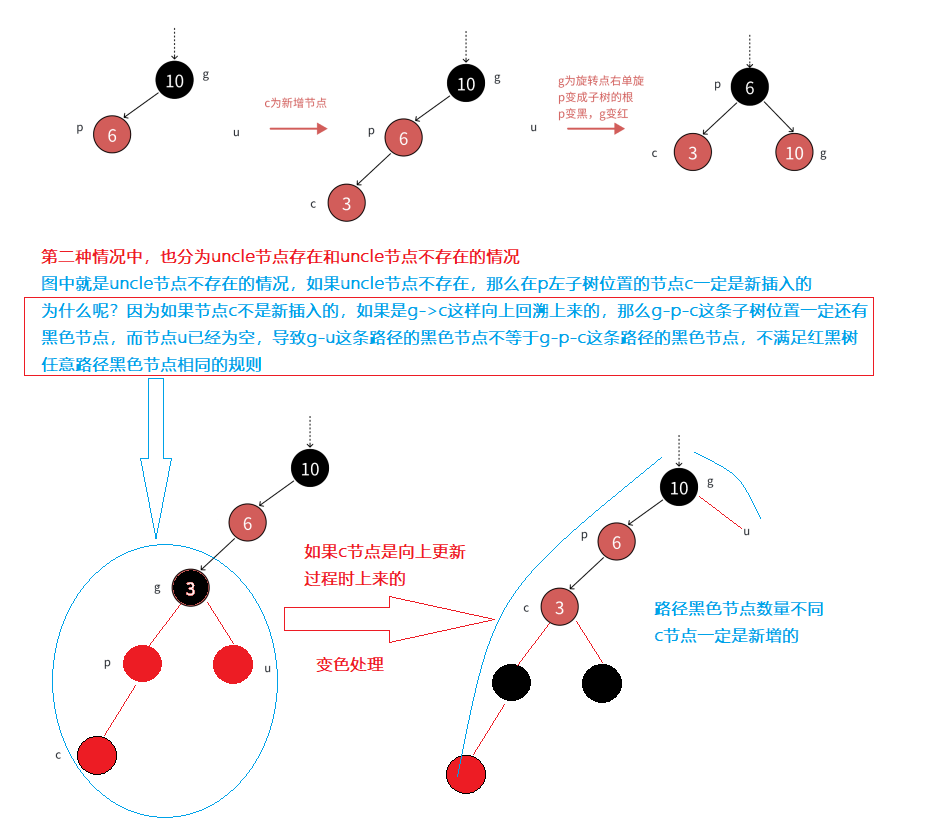
- 对于uncle节点存在且为黑色的情况,处理情况相同,同样是以g节点为旋转点进行右单旋,然后p节点为红,g节点为黑
2.2.3 第3种情况:uncle节点不存在或者为黑色,且cur节点和parent节点为红
- 这种情况一般是:如果parent是grandfather左子树节点,cur节点是p右孩子的情况;或者parent是grandfather右子树节点,cur节点是p左孩子的情况
- 因此第2种情况就是:cur节点和parent节点是它们的父节点的左孩子/右孩子方向不保持一致
- 第3种情况和第2种情况类似,只是单纯一次单旋满足不了红黑树的要求,需要双旋+变色


- 同样和第2种情况类似,情景1:uncle节点不存在
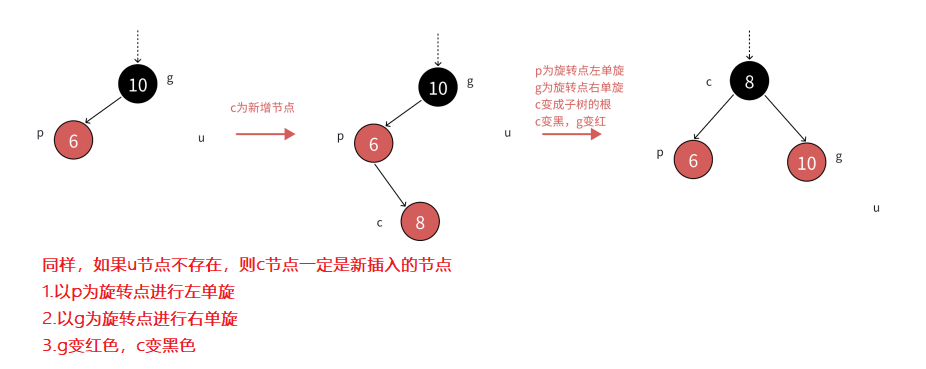
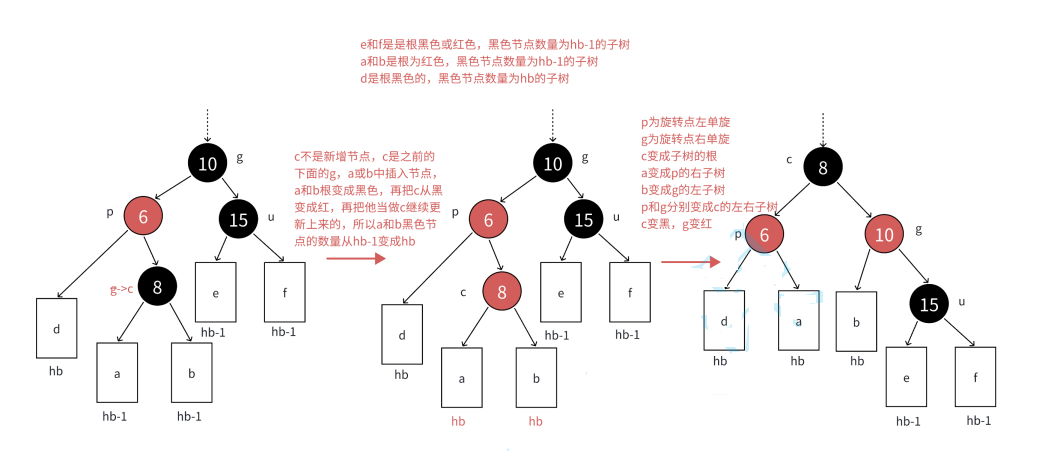
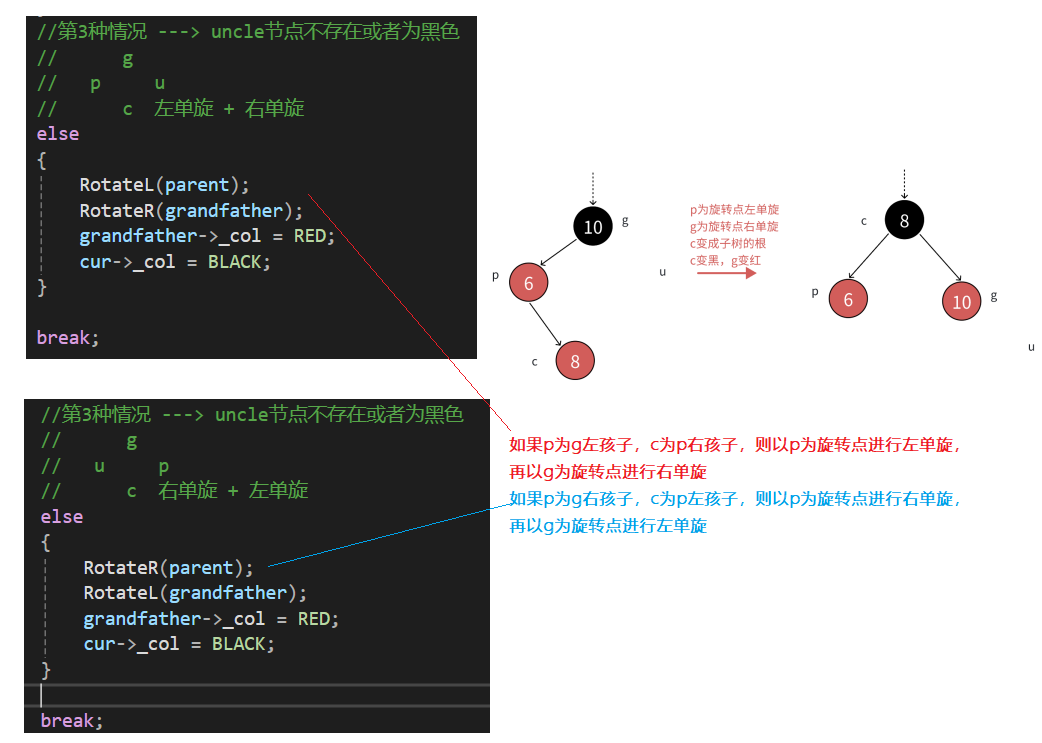
- 当然,对于左右单旋的代码在上一节AVL树有详细讲解,这里不过多赘述
2.3 红黑树的查找
- 红黑树的查找按照二叉搜索树的方式查找就行,效率
O(logN)
Node* Find(const K& key){Node* cur = _root;if (key > cur->_kv.first)cur = cur->_right;else if (key < cur->_kv.first)cur = cur->_left;elsereturn cur;return nullptr;}
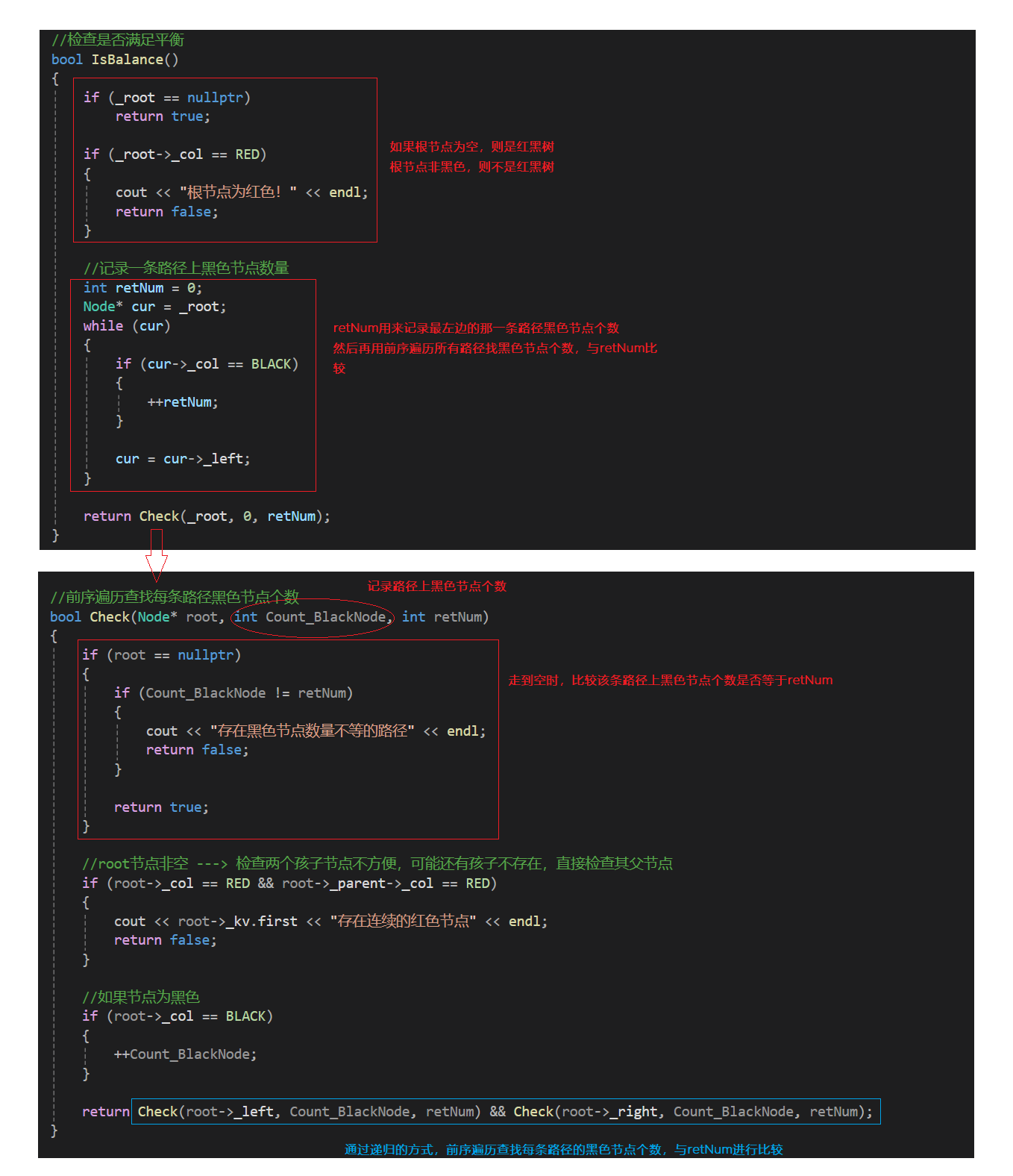
2.4 红黑树的验证
- 这里获取最长路径和最短路径,检查最长路径不超过最短路径的2倍是不可行的,因为就算满足这个条件,红黑树也可能颜色不满足规则,当前暂时没出问题,后续继续插入还是会出问题的。所以我们还是去检查4点规则,满足这4点规则,一定能保证最长路径不超过最短路径的2倍
- 1. 规则1枚举颜色类型,天然实现保证了颜色不是黑色就是红色
- 2. 规则2直接检查根即可
- 3. 规则3前序遍历检查,遇到红色结点查孩子不太方便,因为孩子有两个,且不一定存在,反过来检查父亲的颜色就方便多了
- 4. 规则4前序遍历,遍历过程中用形参记录跟到当前结点的blackNum(黑色结点数量),前序遍历遇到黑色结点就++blackNum,走到空就计算出了一条路径的黑色结点数量。再任意一条路径黑色结点数量作为参考值,依次比较即可
3. 代码
#pragma once#include using namespace std;enum Colour{RED,BLACK};template <class K,class V>struct RBTreeNode{pair<K, V> _kv;RBTreeNode<K, V>* _left;RBTreeNode<K, V>* _right;RBTreeNode<K, V>* _parent;Colour _col;RBTreeNode(const pair<K,V> kv):_kv(kv),_left(nullptr),_right(nullptr),_parent(nullptr),_col(RED){}};template<class K,class V>class RBTree{typedef RBTreeNode<K, V> Node;public:bool insert(const pair<K, V>& kv){if (_root == nullptr){_root = new Node(kv);_root->_col = BLACK;return true;}Node* parent = nullptr;Node* cur = _root;while (cur){if (kv.first > cur->_kv.first){parent = cur;cur = cur->_right;}else if (kv.first < cur->_kv.first){parent = cur;cur = cur->_left;}elsereturn false;}cur = new Node(kv);cur->_col = RED;if (kv.first > parent->_kv.first)parent->_right = cur;else if (kv.first < parent->_kv.first)parent->_left = cur;cur->_parent = parent;while (parent && parent->_col == RED){Node* grandfather = parent->_parent;if (parent == grandfather->_left){Node* uncle = grandfather->_right;if (uncle && uncle->_col == RED){uncle->_col = parent->_col = BLACK;grandfather->_col = RED;cur = grandfather;parent = cur->_parent;}else{if(cur == parent->_left){RotateR(grandfather);grandfather->_col = RED;parent->_col = BLACK;}else{RotateL(parent);RotateR(grandfather);grandfather->_col = RED;cur->_col = BLACK;}break;}}else{Node* uncle = grandfather->_left;if (uncle && uncle->_col == RED){uncle->_col = parent->_col = BLACK;grandfather->_col = RED;cur = grandfather;parent = cur->_parent;}else{if (cur == parent->_right){RotateL(grandfather);grandfather->_col = RED;parent->_col = BLACK;}else{RotateR(parent);RotateL(grandfather);grandfather->_col = RED;cur->_col = BLACK;}break;}}}_root->_col = BLACK;return true;}void RotateL(Node* parent){Node* subR = parent->_right;Node* subRL = subR->_left;parent->_right = subRL;subR->_left = parent;if (subRL)subRL->_parent = parent;Node* parent_Parent = parent->_parent;parent->_parent = subR;if (parent_Parent == nullptr){_root = subR;subR->_parent = nullptr;}else{if (parent_Parent->_left == parent)parent_Parent->_left = subR;elseparent_Parent->_right = subR;subR->_parent = parent_Parent;}}void RotateR(Node* parent){Node* subL = parent->_left;Node* subLR = subL->_right;parent->_left = subLR;subL->_right = parent;if (subLR)subLR->_parent = parent;Node* parent_Parent = parent->_parent;parent->_parent = subL;if (parent == _root){_root = subL;subL->_parent = nullptr;}else{if (parent_Parent->_left == parent)parent_Parent->_left = subL;elseparent_Parent->_right = subL;subL->_parent = parent_Parent;}}void Inorder(){_Inorder(_root);cout << endl;}void _Inorder(Node* root){if (root == nullptr)return;_Inorder(root->_left);cout << root->_kv.first << \"-\" << root->_kv.second << \" \";_Inorder(root->_right);}size_t Size(){return _Size(_root);}size_t _Size(Node* root){return root == nullptr ? 0 : _Size(root->_left) + _Size(root->_right) + 1;}Node* Find(const K& key){Node* cur = _root;while(cur){if (key > cur->_kv.first)cur = cur->_right;else if (key < cur->_kv.first)cur = cur->_left;elsereturn cur;}return nullptr;}bool Check(Node* root, int Count_BlackNode, int retNum){if (root == nullptr){if (Count_BlackNode != retNum){cout << \"存在黑色节点数量不等的路径\" << endl;return false;}return true;}if (root->_col == RED && root->_parent->_col == RED){cout << root->_kv.first << \"存在连续的红色节点\" << endl;return false;}if (root->_col == BLACK){++Count_BlackNode;}return Check(root->_left, Count_BlackNode, retNum) && Check(root->_right, Count_BlackNode, retNum);}bool IsBalance(){if (_root == nullptr)return true;if (_root->_col == RED){cout << \"根节点为红色!\" << endl;return false;}int retNum = 0;Node* cur = _root;while (cur){if (cur->_col == BLACK){++retNum;}cur = cur->_left;}return Check(_root, 0, retNum);}private:Node* _root = nullptr;};
#include\"RBTree.h\"#includevoid RBTreetest1(){RBTree<int, int> rb1;int a[] = { 4, 2, 6, 1, 3, 5, 15, 7, 16, 14 };for (auto& e : a){rb1.insert({ e,e });}rb1.Inorder();cout << \"Size:\" << rb1.Size() << endl;}void RBTreetest2(){const int N = 1000000;vector<int> v;v.reserve(N);srand(time(0));for (size_t i = 0; i < N; i++){v.push_back(i + rand());}size_t begin2 = clock();RBTree<int, int> t;for (size_t i = 0; i < v.size(); ++i){t.insert(make_pair(v[i], v[i]));}size_t end2 = clock();cout << \"Insert:\" << end2 - begin2 << endl;cout << \"Size:\" << t.Size() << endl;t.insert({ 20,20 });cout << t.Find(20) << endl;if (t.IsBalance())cout << \"该二叉树是红黑树!\" << endl;elsecout << \"该二叉树不是红黑树!\" << endl;}int main(){RBTreetest2();return 0;}

