文本相似度之有监督相似度计算
注:无监督文本相似见:链接直达
有监督相似度计算,是在具有标注预料的条件下进行的,即根据标注数据进行深度学习建模,通过模型的端到端学习,直接求解出短文本的相似度值。目前,分为三种框架结构:(1)暹罗”架构;(2)“交互聚合”架构;(3)“预训练”架构。
1、“暹罗”架构:在该框架结构中,将两个短文本分别输入到相同的深度学习编码器中(如CNN或RNN),使得两个句子映射到相同的空间中,然后将得到得两个句子向量进行距离得度量,最终获取短文本的相似度值。代表模型是孪生网络【1】,如图1所示。
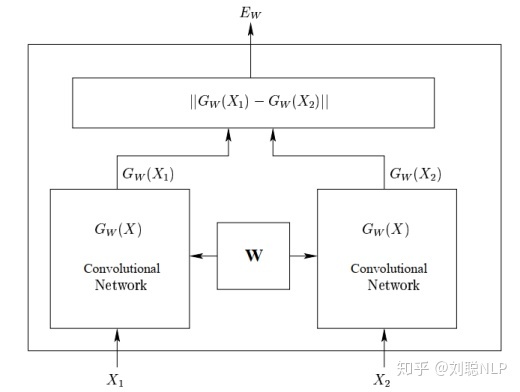
孪生网路模型结构图
其优点是共享参数使模型更小,更容易训练。虽然其短文本的句向量通过模型得出,具有一定的语义信息;但缺点也不容忽视,在映射过程中两个文本之间没有明确的交互作用,会丢失很多相互影响的信息。
参考论文:https://aclanthology.org/W16-1617.pdf
2、“交互聚合”架构:该框架结构是针对于第一种框架结构的缺点而提出的,它的框架前部分与第一种框架相同,也是将两个文本分别输入到相同的深度学习编码器中得到两个句子向量,但之后不是直接将两个句子向量进行距离的度量,而是通过一种或多种注意力机制将两个句子向量进行信息的交互,最终将其聚合成一个向量,并通过值映射(全连接到一个节点)获取短文本的相似度值。代表模型有:ESIM【2】、BiMPM【3】、DIIN【4】和Cafe【5】等。如图2所示,
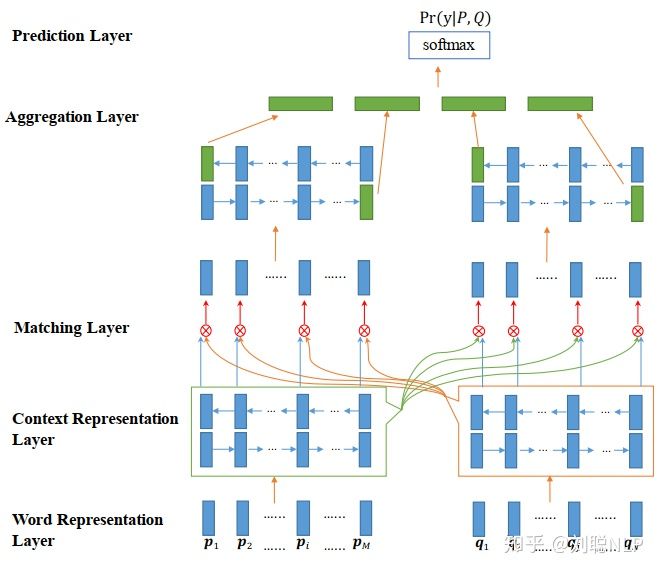
BiMPM模型结构图
这种框架捕获了两句话之间更多的交互特性,因此它相较于第一种框架获得了显著的改进。
3、“预训练”架构:该框架结构来自近期较火的pre-trained模型(代表模型有:ELmo【6】,GPT【7】和BERT【8】等)。它主要采用两阶段模式,第一阶段使用很大的通用语料库训练一个语言模型,第二阶段使用预训练的语言模型做相似度计算任务,即将两个文本到预训练模型中,得到信息交互后的向量,并通过值映射(全连接到一个节点)获取短文本的相似度值。如图3所示,
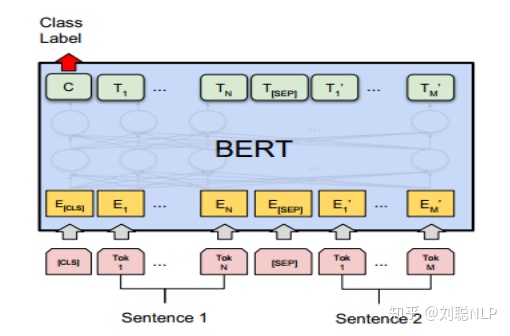
BERT模型结构图
这种框架通常具有很大的参数量,并且由于使用了很大通用语料库,使其普适性更好,可以获取两个短文本之间更隐蔽的交互特征,因此它相较于第二种框架也获取了一些改进。
虽然,监督学习方法比非监督学习方法求得的短文本相似度更加准确;但是,监督学习模型网络对计算要求较高。例如,如果我们想要从标准问库中找到一个与用户问题最相似的标准问,每一次一个新的用户问题来到时,我们都要与所有标准问题进行新的编码计算。如果标准问库很庞大时,需要大量的时间;而在事实问答场景中,用户很难去等待这么久。这也就是为什么监督学习模型效果虽好,但是现实问答机器人中依然采用无监督的方法的原因吧?
有监督+无监督相似度计算
鉴于无监督学习和有监督学习的优缺点,我们可以将其结合到一起,提高无监督学习的准确率并且降低有监督学习的时间成本。
那么如何去实现呢?
(1)无监督学习的弊端在于文本的句向量生成,通过词向量人为地加权求和并不能得到很好的句向量,并且得到的句向量也不包含上下文的语义信息。
我们可以使用监督学习的方法,去获取一个短文本的句向量。如上文所所,我们可以通过孪生网络获取到短文本的句向量,虽然没有两个文本句向量直接的相互信息,但是包含了各自文本的上下文语义信息。
(2)有监督学习的时间复杂度太高,为了避免每一次来一个新的文本,都将所有文本都计算一遍。我们舍弃文本之间的交互作用,直接使用生成好的句向量。
我们可以在问答系统或问答机器人启动阶段,先将标准问库中所有的标注问的句向量计算完成并存储;当一个用户问题过来时,我们只需要求解用户问题的句向量,然后与存储在库中的标准问句向量进行距离度量,最终就可以获得最相似的标准问了。节约了很大一部分时间成本。
(3)有监督学习可以获取优于无监督学习的句向量,那么如何可以提高句向量的质量呢?在2018年前,人们都是使用CNN或LSTM对其短文本进行编码,为获取更好的句子向量,但是效果一般,相较于无监督学习提高的程度也有限。同时又需要标注预料,其实在工业界使用价值并不明显。在2018年,BERT横空出世后,句向量的获取又被提高到了一个新的高度。借助于庞大的预训练语料库和模型参数,BERT模型称霸各大榜单的榜首,我们可以将BERT模型代替原来孪生网络中的CNN或LSTM结构,获取具有更多语义信息的句向量,将监督模型在工业界使用变成了可能。代表模型:Sentence-bert【9】。
由于BERT模型太过于庞大,我们还可以使用蒸馏模型的方法(有机会可以再次分享),将其进行蒸馏,来降低时间成本。