Kafka入门学习
一、简介:
1.1 概述
Apache Kafka 是一款开源的消息引擎系统。也可以叫做消息队列,消息中间件。是一个分布式、分区的、多副本的、多订阅者,基于zookeeper协调的分布式日志系统(也可以当做MQ系统),常见可以用于web/nginx日志、访问日志,消息服务等等
维基百科定义:消息引擎系统是一组规范。企业利用这组规范在不同系统之间传递语义准确的消息,实现松耦合的异步式数据传递。
个人理解:系统 A 发送消息给消息引擎系统,系统 B 从消息引擎系统中读取 A 发送的消息。
消息引擎:
- 消息引擎传输的对象是消息;
- 如何传输消息属于消息引擎设计机制的一部分。
1.2 特性
- 持久性,可靠性。以时间复杂度为O(1)的方式提供消息持久化能力,即使对TB级以上数据也能保证常数时间的访问性能。
- 高吞吐率,低延迟。即使在非常普通的硬件上也能做到单机支持每秒数百万条消息的传输。
- 可扩展性:支持在线水平扩展
- 支持Kafka Server间的消息分区,及分布式消费,同时保证每个partition内的消息顺序传输。
- 同时支持离线数据处理和实时数据处理。
消息引擎是用于在不同系统之间传输消息的。Kafka使用的是纯二进制的字节序列。当然消息还是结构化的,只是在使用之前都要将其转换成二进制的字节序列。
1.3 消息传递模式
点对点模型:也叫消息队列模型。系统 A发送的消息只能被系统 B 接收,其他任何系统都不能读取 A 发送的消息。
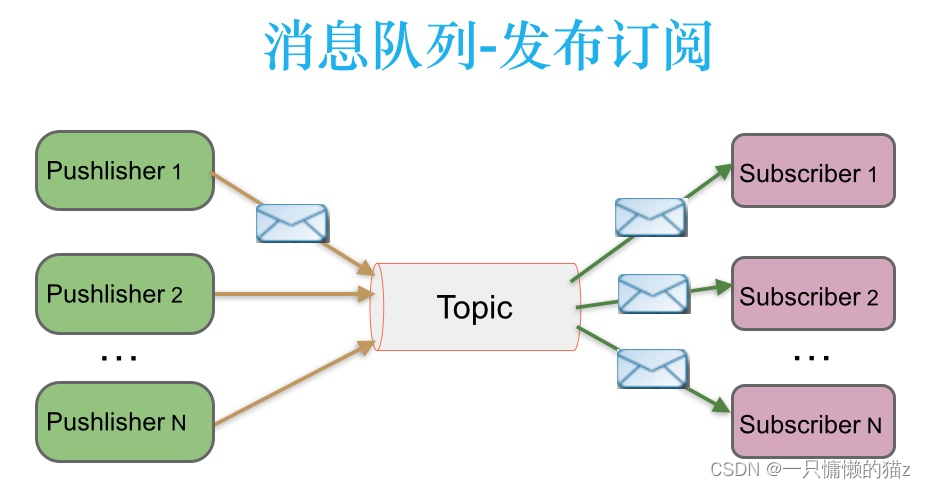
发布 / 订阅模型:与上面不同的是,它有一个主题(Topic)的概念,你可以理解成逻辑语义相近的消息容器。该模型也有发送方和接收方,只不过提法不同。消息的生产者也称为发布者(Publisher),消息的消费者称为订阅者(Subscriber)。在发布-订阅消息系统中,消息被持久化到一个topic中。与点对点消息系统不同的是,消费者可以订阅一个或多个topic,消费者可以消费该topic中所有的数据,同一条数据可以被多个消费者消费,数据被消费后不会立马删除。该模式的示例图如下:
1.4 Kafka 的优点
- 解耦,削峰
发送方和接收方的松耦合,这也在一定程度上简化了应用的开发,减少了系统间不必要的交互。
所谓的“削峰”就是指缓冲上下游瞬时突发流量,使其更平滑。特别是对于那种发送能力很强的上游系统,如果没有消息引擎的保护,“脆弱”的下游系统可能会直接被压垮导致全链路服务“雪崩”。但是,一旦有了消息引擎,它能够有效地对抗上游的流量冲击,给下游子服务留出了充足的时间去消费它们。 - 保证顺序
在大多使用场景下,数据处理的顺序都很重要。大部分消息队列本来就是排序的,并且能保证数据会按照特定的顺序来处理。Kafka保证一个Partition内的消息的有序性。 - 异步通信
消息队列提供了异步处理机制,允许用户把一个消息放入队列,但并不立即处理它。想向队列中放入多少消息就放多少,然后在需要的时候再去处理它们。
二、核心概念:
- Producer(生产者)
- Consumer(消费者)
- Consumer Group (消费者组)
- Broker(服务器节点)
- Topic (主题)
- Partition(分区)
- Leader Replica(领导者副本)
- Follower Replica (追随者副本)
2.1 Producer
向主题发布消息的客户端应用程序称为生产者(Producer),生产者程序通常持续不断地向一个或多个主题发送消息
2.2 Consumer
订阅这些主题消息的客户端应用程序就被称为消费者(Consumer)。和生产者类似,消费者也能够同时订阅多个主题的消息。我们把生产者和消费者统称为客户端(Client)。你可以同时运行多个生产者和消费者实例,这些实例会不断地向 Kafka 集群中的多个主题生产和消费消息。
2.3 Consumer Group
指的是多个消费者实例共同组成一个组来消费一组主题。这组主题中的每个分区都只会被组内的一个消费者实例消费,其他消费者实
例不能消费它。为什么要引入消费者组呢?主要是为了提升消费者端的吞吐量。多个消费者实例同时消费,加速整个消费端的吞吐量(TPS)
2.4 Broker
Kafka 的服务器端由被称为 Broker(服务器节点) 的服务进程构成,即一个 Kafka 集群由多个 Broker 组成,Broker 负责接收和处理客户端发送过来的请求,以及对消息进行持久化。常见的做法是将不同的 Broker 分别运行在不同的机器上,这样如果集群中某一台机器宕机,其他机器上的 Broker 也依然能够对外提供服务。保证 Kafka 的高可用。
2.5 Topic
每条发布到Kafka集群的消息都有一个主题,这个主题被称为Topic。在实际使用中多用来区分具体的业务。(物理上不同Topic的消息分开存储,逻辑上一个Topic的消息虽然保存于一个或多个broker上但用户只需指定消息的Topic即可生产或消费数据而不必关心数据存于何处)
2.6 Partition
副本机制可以保证数据的持久化或消息不丢失,但没有解决伸缩性的问题。如果一个副本积累了太多的数据,Broker机器无法容纳。那如果我们把数据分成几份,这样是不是就解决了这个问题。Kafka的分区就是这样设计的。Kafka 中的分区机制指的是将每个主题划分成多个分区(Partition),每个分区是一组有序的消息日志。生产者生产的每条消息只会被发送到一个分区中
2.7 Leader Replica
副本分为领导者副本和追随者副本,各自有不同的角色划分。副本是
在分区层级下的,即每个分区可配置多个副本实现高可用。领导者副本有且仅有一个,Leader Replica是当前负责数据的读写的partition。
2.8 Follower Replica
Follower只是被动跟随Leader,不与外界交互。所有写请求都通过Leader路由,数据变更会广播给所有Follower,Follower与Leader保持数据同步。如果Leader失效,则从Follower中选举出一个新的Leader。当Follower与Leader挂掉、卡住或者同步太慢,leader会把这个follower从“in sync replicas”(ISR)列表中删除,重新创建一个Follower。
2.9 Rebalance
重平衡:Rebalance。消费者组内某个消费者实例挂掉后,其他消费者实例自动重新分配订阅主题分区的过程。Rebalance 是 Kafka 消费者端实现高可用的重要手段。
2.10 Offset
消息位移:Offset。表示分区中每条消息的位置信息,是一个单调递增且不变的值。
三、总结
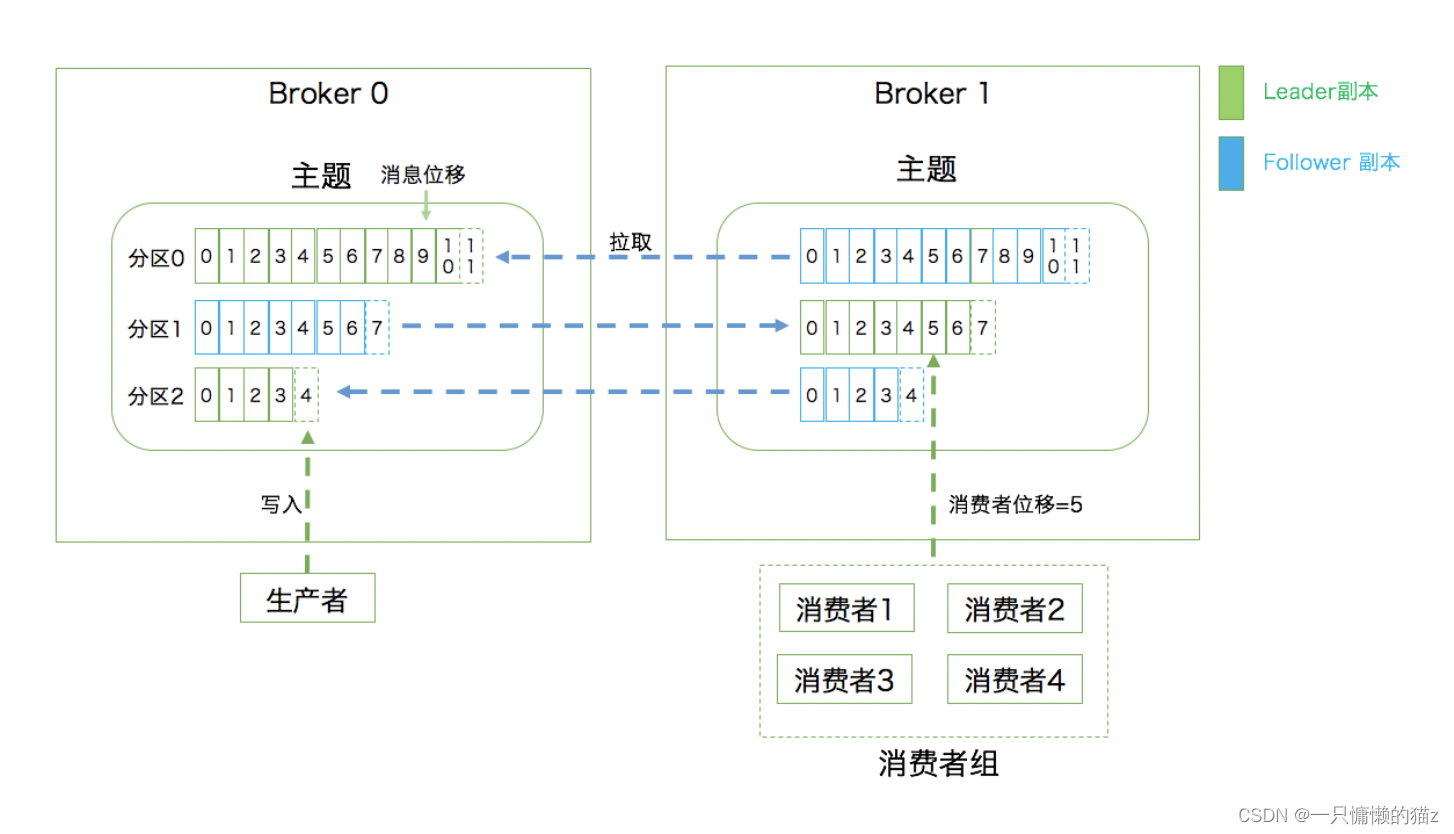
上面提到的副本如何与分区联系在一起呢?
实际上,副本是在分区这个层级定义的。每个分区下可以配置若干个副本,其中只能有 1 个领导者副本和 N-1 个追随者副本。生产者向分区写入消息,每条消息在分区中的位置信息由一个叫位移(Offset)的数据来表征。分区位移总是从 0 开始,假设一个生产者向一个空分区写入了 10 条消息,那么这 10 条消息的位移依次是 0、1、2、…、9。
至此我们能够完整地串联起 Kafka 的三层消息架构:
- 第一层是主题层,每个主题可以配置 M 个分区,而每个分区又可以配置 N 个副本。
- 第二层是分区层,每个分区的 N 个副本中只能有一个充当领导者角色,对外提供服务;其他 N-1 个副本是追随者副本,只是提供数据冗余之用。
- 第三层是消息层,分区中包含若干条消息,每条消息的位移从 0 开始,依次递增。
最后,客户端程序只能与分区的领导者副本进行交互。
重点:用一张图来展示上面提到的这些概念