史上最全 Git 图文教程(非常详细)零基础入门到精通,收藏这一篇就够了
戳上方蓝字“Java知音”关注我
Git安装
安装
1.先去官网下载这个软件, 准备安装到本电脑中
https://git-scm.com/
2.根据自己电脑系统下载此软件到本机
Windows 系统直接下载
.exe文件即可,macOS 系统使用Homebrew命令行安装,终端输入git --version确认安装

3.默认选择默认安装路径即可,如若想更改路径,务必使用英文路径
4.对于 Windows 系统,查看安装是否成功: 在任意文件夹右键,查看是否有Git Base Here 选项,有就成功了

介绍
Git 的三个区域:
-
工作区: 处理工作的区域
-
暂存区: 临时存放的区域
-
本地git仓库: 最终的存放区域
在文件夹的体现如下:
-
工作区: 在你电脑里看到的目录
-
暂存区: 在.git文件夹内的index中 (二进制记录)
-
版本库: 指的整个.git文件夹 (也认为是本地仓库)
在代码中的体现如下:

Git使用
官方文档:教程链接[1]
菜鸟教程:教程链接[2]
Git配置
安装完 Git 之后,要做的第一件事就是设置你的用户名和邮件地址。因为每一个 Git 提交都会使用这些信息
命令格式如下:中文自己看情况换
-
git config: 固定命令,设置git相关配置
-
–global: 全局配置;一次配置,整机在使用git时都生效
git config --global user.name 你的用户名 git config --global user.email 你的邮箱地址 运行命令效果如下:

配置后,可以运行如下命令查看是否成功
git config --list #如果信息太多,可以输入 q 退出 运行命令效果如下:

出现以上内容即为注册成功。如果后续想要修改,只需要重新执行一下命令即可
文件右侧标记
一般使用 VSCode 打开一个包含git仓库的文件夹时,会有这些标记

右侧没有标记的时候为未修改 或 此文件/文件夹,被git忽略不跟踪变化
-
M:已修改(Modified) - 文件已被修改但还没有被添加到暂存区
-
A:已添加(Added) - 文件已经被添加到暂存区,但还没有被提交
-
D:已删除(Deleted) - 文件已经被删除,并且已经被标记为删除,但还没有提交
-
R:已重命名(Renamed) - 文件已经被重命名,这也算作是一种修改,需要被添加到暂存区
-
C:已复制(Copied) - 文件已经被复制,这也算作是一种修改,需要被添加到暂存区
-
U:已更新但未融合(Updated but Unmerged) - 这表示一个文件已经被更新了,但在合并时发生了冲突,需要手动解决冲突后再标记为已解决
Git基础命令
初始化空的Git仓库
新建一个文件夹或现有的文件夹并不是 git 仓库,因为文件夹内不包含 .git 文件夹,没有被 git 管理
可以在新文件夹或现有文件夹,运行如下命令得到 .git 文件夹,初始化成功则可让 git 开始准备管理
# 初始化 git 仓库, 产物: .git 文件夹 (所在文件夹\"内\"被管理) git init 例如,在新文件夹中输入git init命令用于初始化空的git版本库

初始化空的 git 仓库成功后,在项目文件夹中,开启显示隐藏文件,即可查看 .git 文件夹
-
对于 Windows 系统,在查看里面勾选隐藏的项目选项
-
对于 macOS 系统,使用快捷键
Command + Shift + .切换隐藏文件显示
记录更新到Git仓库
每当完成了一个阶段的目标,想要记录下它时,就将它提交到仓库
核心操作:工作区开发—>将修改后的文件添加到暂存区—>将暂存区的文件记录到版本库
把工作区变化放到暂存区中,执行如下命令
# 将 index.html 添加到暂存区 git add index.html # 将css目录下一切添加到暂存区 git add css 如下命令,可以一次性把所有变化文件放入暂存区
# .的意思是当前目录下所有变化都暂存 git add . 把暂存区内容,提交到版本库,命令如下(此处文字说明可以不加引号)
git commit -m \'提交的内容说明\' 过程图示:
以上命令相当于存档了一次,在版本库中产生一次提交记录并生成版本号
本次存档,不耽误我们在工作区 (项目文件夹) 下继续编写项目
Git日志及状态查看
查看所有提交的日志记录,命令如下
git log 运行命令效果如下:

当我们的日志越来越多,可能想要简化查看,可以输入如下命令
–oneline:在一行显示简略信息
git log --oneline 运行命令效果如下:

如果改的代码过多,忘记改过哪些了,可以运行如下命令来查看 git 仓库变化,只能看未提交的所有变更的文件状态
git status 运行命令效果如下:

暂存并再次提交,产生一次版本记录
git add . git commit -m \'新建登录页面_和样式\' 过程图示:

Git版本回退
时光机,回到过去~
回退命令语法如下
git reset --hard 版本号 查看版本号(每次的版本号随机生成)
git log --oneline 
尝试回退到 477321b 这次记录上
git reset --hard 477321b 观察工作区,回退成功

如果想要在回到最近一次提交的记录,但发现git log看不到未来的记录了,问题不大。输入git reflog命令,可以查看 git 所有的操作记录,包括你的reset记录
git reflog 运行命令效果如下:

拓展命令:
-
git bash(终端)清屏:clear
-
git bash(终端)另起一页:Ctrl + L
Git忽略文件
有的时候,我们某些文件或文件夹不想让 git 进行跟踪管理。这时候可以在 .git 文件夹同级目录下新增.gitignore的忽略文件并写入忽略规则(此处的文件名就是 .gitignore ,不是后缀)
项目文件夹结构如下:

# .gitignore内容: password.txt 其余用法: # 忽略文件夹 css # 忽略文件夹下的某个文件 css/index.js # 忽略文件夹下某类文件 css/*.js 根目录新建 password.txt,查看 git 追踪到了哪些变化
git status 运行命令效果如下:

发现只新增了.gitignore ,符合规则的都被忽略掉了
.gitignore文件在项目中可以根据脚手架自动生成,无需自己编写,当然如果你非要写,以下是Vue官方自动生成的.gitignore文件代码,可供复制使用
# Logs logs *.log npm-debug.log* yarn-debug.log* yarn-error.log* pnpm-debug.log* lerna-debug.log* node_modules dist dist-ssr *.local # Editor directories and files .vscode/* !.vscode/extensions.json .idea .DS_Store *.suo *.ntvs* *.njsproj *.sln *.sw? Git分支
分支本质
分支其实就是一个叫HEAD的指针标记,每次代码提交,此HEAD指针都会往后移动一次,保证指向的 (并且工作区里的) 都是最后一次提交
例如:当我们输入命令:git reset --hard a3bcab2,HEAD指针会移动,而且HEAD移动后,会影响工作区里的代码
创建分支
- 创建分支命令如下
# 创建分支 git branch 分支名 该命令创建分支后不会自动切换分支,我们可以运行命令查看现在这个 .git 版本库里所有分支
- 查看当前版本库所有分支命令如下
# 查看当前版本库所有分支,绿色带*代表现在所处的分支 git branch 运行命令效果如下:

- 手动切换到分支上
# 切换分支命令 git checkout 分支名 运行命令效果如下:

第一次创建并切换到 reg 分支,你会发现 master 分支上的所有代码 (和当前节点所有提交记录) 都被复制了过来 了,我们只需要在这个基础上接着往后开发就行
过程图示:
分支下开发流程
我们现在就可以在当前 reg 分支下来编写注册页面的逻辑代码,例如新建reg.html文件,并随便写点内容。随后暂存并提交一次,这次提交的记录会出现在这里,如图

以后在当前 reg 分支下开发,就会在 reg 范围内,每次提交产生一次版本记录,不会影响到别的分支
分支合并
我们可以把分支里写好的代码,合并到主分支或其他分支上,步骤如下:
首先,切换到你要合并到的目标分支上(以master主分支为例)
# 切换分支 git checkout master 切换分支后,HEAD指针位置如下:

合并命令语法
# 把目标分支名下的所有记录, 合并到当前分支下 git merge 目标分支名 这里我们执行命令git merge reg,执行后效果如图:

可见,reg 代码提交记录已经复制到了 master (主分支) 中
分支删除
假如注册功能开发完毕,代码已经合并到 master 分支上,我们已经不需要 reg 分支
命令如下
git branch -d 分支名 如果分支的修改没有被合并到其他分支上,Git 会提示一个类似以下的错误信息:
error: The branch \'branch_name\' is not fully merged. If you are sure you want to delete it, run \'git branch -D branch_name\'. 在这种情况下,Git 建议你确认是否要删除这个分支。如果你确定要删除该分支并且不在乎丢失该分支的修改,你可以使用git branch -D 命令来强制删除该分支。但请注意,这样会丢失掉分支上的未合并修改
分支合并时的冲突问题
在两个分支修改了同一个文件并提交过,在合并的时候,就会产生冲突
这里模拟一次简单的冲突:
- 在 master 分支下,修改
login.html的某行代码,并完成一次暂存提交

- 切换到 reg 分支下,也修改
login.html的对应行代码,并完成一次暂存提交

- 再切换回到 master 分支下,用合并命令,把 reg 分支下代码和变化合并过来,不出意外就会出现冲突了

发生冲突后,VSCode界面

此时我们要进行抉择:
采用当前更改、采用传入更改、全部保留
选择保留方式后,需要再次暂存提交一次

此时结束冲突状态,变回正常状态
打印冲突合并后的日志记录

总结:当我们合并遇到冲突了,应手动解决,然后暂存,提交一次即可
Git分支流程图详解(拓展)
HEAD头指针,它指向当前所在的分支或者某个具体的提交记录。每次提交会产生新的记录master和HEAD会后移

以当前节点为基准创建新的分支 (包含之前的所有提交记录),git branch reg 就会在当前的提交记录上创建一个新的指针,名称为reg

git checkout reg切换的是HEAD指针指向 (切换分支)

注册页面新建后,git add .添加到暂存区,git commit -m 产生了一次提交记录

注册页面的样式新建后暂存提交,产生了一次提交记录

合并分支,例如把 A 合并到 B上
-
git checkout B,切换到目标分支 B -
git merge A,把 A 分支记录合并到所在 B 分支下
先切换到主分支git checkout master

合并reg分支git merge reg

在reg分支下,修改了index.html文件,并暂存提交,产生了记录

切换到master分支,并修改index.html文件(同一个文件),暂存提交,产生了记录

在master分支中,想要把reg合并过来。由于修改了同一个文件,会报错,需要解决冲突

手动解决冲突后,会产生一个新的提交记录

删除reg分支,全部过程结束

Git远程仓库
介绍
远程仓库是指托管在因特网或其他网络上的 Git 仓库,可以存储我们版本库的所有记录和存档记录
远程仓库在团队协作中发挥着重要的作用。它不仅可以充当备份存储,保护你的代码免受数据丢失的风险,还可以让团队成员之间轻松地共享代码、查看代码变更、进行代码审查等

主流的远程仓库有 GitHub (gay hub)全球最大的同行交友社区,以及服务器在国内的 gitee(码云)。由于 GitHub 服务器在国外,方便起见,这里以码云为例,供初学者参考,GitHub 流程与 gitee 类似
注册
注册登录 gitee.com 网站以后,添加主邮箱为自己本地 git 仓库设置的邮箱,注意一定要相同,否则无法正确提交 如果忘记了本地设置的邮箱地址:
-
可以打开控制台输入
git config --list重新查看邮箱地址 -
当然也可以使用
git config --global user.email你的邮箱地址重新覆盖原来的邮箱地址
邮箱设置界面不要勾选不公开我的邮箱地址,否则也无法正常提交

仓库新建
可以选择创建一个远程仓库的项目 (可以多个),创建界面如下

勾选完成后选择创建,创建后, 会得到一个远程仓库的地址链接,一般是以.git结尾的地址
地址分为两种最常用的两种传输协议:
-
HTTPS协议: 需要输入用户名和密码
https://gitee.com/(userName)/(repositoryName).gitssh -
SSH协议: 需要配置密钥,可免密码登录
git@gitee.com:userName/repositoryName.git
选择SSH路径,界面如下

SSH配置
我们可以在本机一次性配置 SSH 以后免密登录,SSH 密钥组成和作用如下:
-
作用: 实现本地仓库和 gitee 平台之间免登录的加密数据传输
-
组成: id_rsa (私钥文件,存放于客户端的电脑中即可)、id_rsa.pub (公钥文件,需要配置到 gitee 平台中)
私钥加密的信息,只能通过公钥解密。公钥加密的信息,只能通过私钥解密。安全性高!
SSH 密钥创建与使用步骤:
-
先在本机生成一个密钥 (以后也可以重新生成、重新配置),打开一个终端,输入以下命令:
ssh-keygen -t rsa -C \"你注册账号的邮箱\" -
连续敲击 3 次回车,即可在
C:\\Users\\用户名文件夹.ssh目录中生成id_rsa和id_rsa.pub两个文件 -
使用 VSCode 打开
id_rsa.pub文件,复制里面的文本内容 -
粘贴配置到 码云 -> 设置 -> ssh 公钥 中即可
-
如果为 mac ,可进入以下教程查看:mac获取公钥
初始化空仓库
先给本地仓库配置个远程仓库的地址, 建立仓库之间的链接
由于每次 push 操作都需要带上远程仓库的地址,十分麻烦,我们可以给仓库设置一个别名
# 给远程仓库设置一个别名 git remote add 仓库别名 仓库地址 git remote add origin git@gitee.com:(username)/repository.git # 删除 origin 这个别名 git remote remove origin # 使用 -u 记录 push 到远端分支的默认值,将来直接 git push 即可 git push -u 仓库别名 分支名 
下面为实际操作举例:
- 随便新建一个项目文件夹,初始化 git,随后在项目文件中随便填充点内容,这里我新增一个
.gitignore文件,随后暂存提交到本地 git 库

- 输入以下命令:
# 注意:这里的existing_git_repo是你的项目根路径 # 如果你是在项目文件夹开启的终端,忽略此行 cd existing_git_repo # 添加远程仓库关联,仓库别名origin,可以随意更改,后接ssh地址 # 此处的ssh是自动生成的,可以去gitee空仓库的代码页直接复制即可 git remote add origin git@gitee.com:li-houyi/test-factory.git # 第一次推送到远程时需要指定具体的分支,因为远程仓库并没有这个分支 # 使用 -u 记录 push 到远端分支的默认值,将来直接 git push 即可 git push -u origin \"master\" - 出现此页面即为成功:

注意:推送的本地仓库一定要非空并且本地暂存提交过,不然会报错!这点也很好理解,你传个空的项目到一个空仓库,这可不得给你报错吗
- 推送成功后重新进入 gitee 仓库页面查看是否正确推送

空仓库创建成功后可以在管理页面将仓库开源,当然也可以不设置开源(默认私有)
克隆项目
如果你想要从远程仓库克隆一份项目代码到本地进行开发,可以使用 git clone 命令
git clone [options] [directory] # directory(可选)克隆后的本地仓库所处的目录名称(默认创建与远程仓库名字相同的目录) 常见选项:
-
-b或--branch: 指定要克隆的远程仓库的特定分支,它不会影响克隆操作所获取的分支数量,而只是指定了默认要检出的分支(不指定则默认克隆远程仓库的主分支) -
--depth: 指定克隆的深度,即只克隆指定数量的提交历史 -
–single-branch: 仅克隆指定分支以及该分支上的历史记录,不下载其他分支
-
–recurse-submodules: 初始化并克隆子模块的内容
-
-n 或 --no-checkout: 克隆后不立即检出任何分支,保留 HEAD 指向原始仓库的默认分支
-
-o或--origin: 自定义远程仓库的别名。 -
-u或--set-upstream-to=/: 设置追踪关系,使得本地分支自动与指定的远程分支关联
如果项目只有一个分支,那么以上代码执行完毕就已经克隆结束了(git clone 默认拉取 master 分支),不过实际开发中,并非只有一个分支,于是我们还需执行以下步骤:
- 在本地建分支,分支名与远程分支名相同,查看远程分支名使用
git branch -r
git checkout -b 对应远程分支名 - 拉取远程分支 (不要在 master 分支直接拉取对应分支的代码,切换到新建的分支)
# 每次拉取都需要指定远程仓库名和分支名 git pull 远程仓库名 分支名 - 以上两行命令可以合并写做一行(创建并拉取远程分支代码)
git checkout -b 分支名 origin/分支名 - 拓展: 设置
git pull默认拉取的分支(设置本地分支与远程分支相关联)
git branch --set-upstream-to=origin/远程分支名 本地分支名 Git远程仓库流程回顾
Step1:

Step2:

Step3:

Step4:

Git常用命令总览
本命令默认远程仓库名为origin、默认远程仓库主分支名为master、为必填项,[]为可选项

黑客&网络安全如何学习
今天只要你给我的文章点赞,我私藏的网安学习资料一样免费共享给你们,来看看有哪些东西。
1.学习路线图
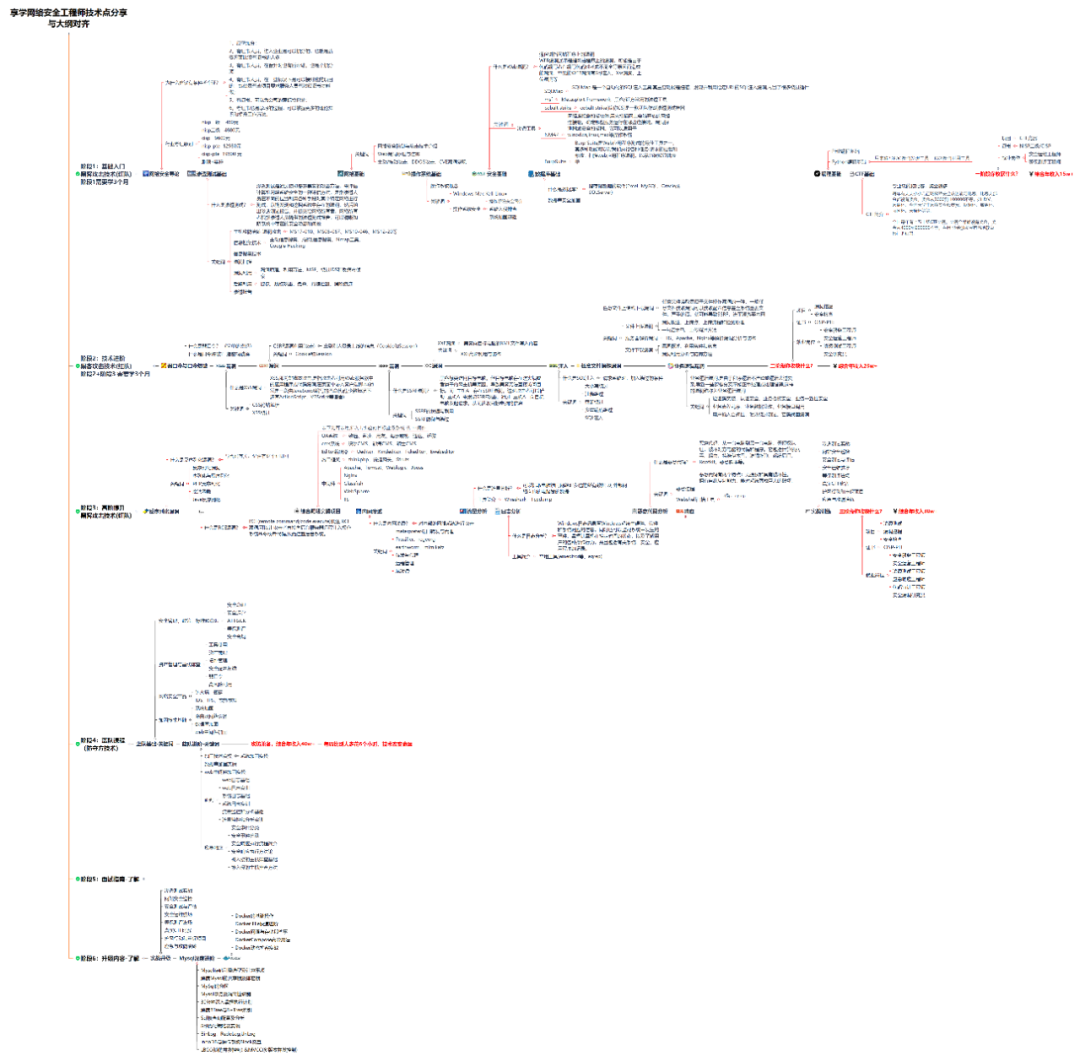
攻击和防守要学的东西也不少,具体要学的东西我都写在了上面的路线图,如果你能学完它们,你去就业和接私活完全没有问题。
2.视频教程
网上虽然也有很多的学习资源,但基本上都残缺不全的,这是我自己录的网安视频教程,上面路线图的每一个知识点,我都有配套的视频讲解。
内容涵盖了网络安全法学习、网络安全运营等保测评、渗透测试基础、漏洞详解、计算机基础知识等,都是网络安全入门必知必会的学习内容。

(都打包成一块的了,不能一一展开,总共300多集)
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
CSDN大礼包:《黑客&网络安全入门&进阶学习资源包》免费分享
3.技术文档和电子书
技术文档也是我自己整理的,包括我参加大型网安行动、CTF和挖SRC漏洞的经验和技术要点,电子书也有200多本,由于内容的敏感性,我就不一一展示了。

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
CSDN大礼包:《黑客&网络安全入门&进阶学习资源包》免费分享
4.工具包、面试题和源码
“工欲善其事必先利其器”我为大家总结出了最受欢迎的几十款款黑客工具。涉及范围主要集中在 信息收集、Android黑客工具、自动化工具、网络钓鱼等,感兴趣的同学不容错过。
还有我视频里讲的案例源码和对应的工具包,需要的话也可以拿走。

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
CSDN大礼包:《黑客&网络安全入门&进阶学习资源包》免费分享
最后就是我这几年整理的网安方面的面试题,如果你是要找网安方面的工作,它们绝对能帮你大忙。
这些题目都是大家在面试深信服、奇安信、腾讯或者其它大厂面试时经常遇到的,如果大家有好的题目或者好的见解欢迎分享。
参考解析:深信服官网、奇安信官网、Freebuf、csdn等
内容特点:条理清晰,含图像化表示更加易懂。
内容概要:包括 内网、操作系统、协议、渗透测试、安服、漏洞、注入、XSS、CSRF、SSRF、文件上传、文件下载、文件包含、XXE、逻辑漏洞、工具、SQLmap、NMAP、BP、MSF…

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
CSDN大礼包:《黑客&网络安全入门&进阶学习资源包》免费分享

