【实战排障】K8s三则报错解决:节点加入失败、APIServer连接异常、资源获取错误_[preflight] running pre-flight checks error execut
问题一、node节点加入集群失败(残留文件/端口占用)
构建三节点k8s集群过程中(已完成初始化),其余node节点加入k8s集群时报错。
1、报错片段
[root@node01 docker]# kubeadm join 11.0.1.173:6443 --token dj2kc8.h3h0ep3jkmtry355 \\ --discovery-token-ca-cert-hash sha256:7f01426026c45d3dcd60e67f825356d4896e681de0a08f7846322eb01f4e9b76 [preflight] Running pre-flight checkserror execution phase preflight: [preflight] Some fatal errors occurred:[ERROR FileAvailable--etc-kubernetes-kubelet.conf]: /etc/kubernetes/kubelet.conf already exists[ERROR Port-10250]: Port 10250 is in use[ERROR FileAvailable--etc-kubernetes-pki-ca.crt]: /etc/kubernetes/pki/ca.crt already exists[preflight] If you know what you are doing, you can make a check non-fatal with `--ignore-preflight-errors=...`2、根因分析

通过报错信息\"[ERROR FileAvailable--etc-kubernetes-kubelet.conf]: /etc/kubernetes/kubelet.conf already exists
[ERROR Port-10250]: Port 10250 is in use
[ERROR FileAvailable--etc-kubernetes-pki-ca.crt]: /etc/kubernetes/pki/ca.crt already exists
\",我们可以得出当前节点存在之前k8s安装的残留文件,因此加入集群失败。
3、解决思路
(1)清理残留
#1、重置kubeadm(如果之前初始化过)sudo kubeadm reset --forcesystemctl status kubelet #确认未残留旧服务#2、手动删除残留文件sudo rm -rf /etc/kubernetes/*sudo rm -rf /var/lib/kubelet/*sudo rm -rf /var/lib/etcd/*sudo rm -rf /var/lib/etcd/*sudo rm -rf ~/.kube/#3、清理网络接口(Flannel/calico)sudo ip link delete cni0sudo ip link delete flannel.1 2>/dev/null#4、释放被占用的端口(10250)sudo kill -9 $(sudo lsof -i :10250 -t)(2)重新加入集群
sudo kubeadm join 11.0.1.173:6443 \\ --token dj2kc8.h3h0ep3jkmtry355 \\ --discovery-token-ca-cert-hash sha256:7f01426026c45d3dcd60e67f825356d4896e681de0a08f7846322eb01f4e9b76 \\ --ignore-preflight-errors=Port-10250 # 仅在确认端口冲突可忽略时使用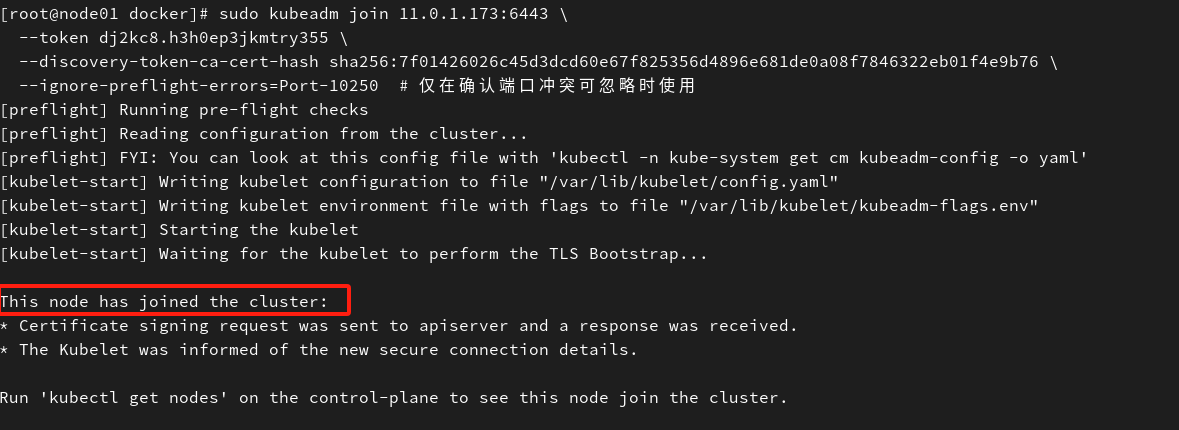
(3)注意事项
-------token失效(24h有效)
#在master节点重新生成有效tokenkubeadm token create --print-join-command-------网络插件( 需确保running)
#查看网络插件状态kubectl get pods -n kube-system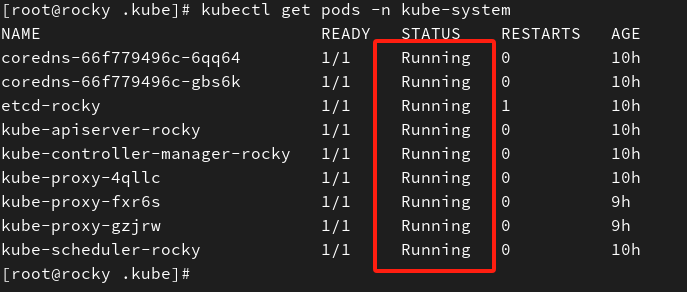
-------时间同步、防火墙、docker/containerd
#所有节点时间必须同步sudo timedatectl set-ntp true#防火墙端口开放sudo firewalld-cmd --add-port={6443,10250,2379,2380}/tcp --permanentsudo firewalld-cmd --reload#docker/containerdsudo systemctl restart docker containerd按照以上步骤排查处理node节点加入集群报错问题,若仍失败,请结合\"journalctl -u kubelet\"看日志输出结果继续进行具体排查。
问题二、APIServer连接异常(kubeconfig/DNS问题)
在node节点使用\"kubectl get nodes\"命令时出现报错。
1、报错片段
[root@node01 docker]# kubectl get noedsE0527 15:38:23.832617 126941 memcache.go:265] couldn\'t get current server API group list: Get \"http://localhost:8080/api?timeout=32s\": dial tcp: lookup localhost on 8.8.8.8:53: no such hostE0527 15:38:23.882251 126941 memcache.go:265] couldn\'t get current server API group list: Get \"http://localhost:8080/api?timeout=32s\": dial tcp: lookup localhost on 8.8.8.8:53: no such hostE0527 15:38:23.934448 126941 memcache.go:265] couldn\'t get current server API group list: Get \"http://localhost:8080/api?timeout=32s\": dial tcp: lookup localhost on 8.8.8.8:53: no such hostE0527 15:38:23.986633 126941 memcache.go:265] couldn\'t get current server API group list: Get \"http://localhost:8080/api?timeout=32s\": dial tcp: lookup localhost on 8.8.8.8:53: no such hostE0527 15:38:24.053044 126941 memcache.go:265] couldn\'t get current server API group list: Get \"http://localhost:8080/api?timeout=32s\": dial tcp: lookup localhost on 8.8.8.8:53: no such hostUnable to connect to the server: dial tcp: lookup localhost on 8.8.8.8:53: no such host2、根因分析
这个报错显示kubectl未正确连接到Api Server,尝试默认连接http://localhost:8080(没配置kubeconfig或环境变量),且查不到localhost域名(DNS解析失败)。
3、解决思路
(1)确认kubectl配置文件有无,或默认路径是否存在(如果文件不存在或内容错误,kubectl会默认尝试连接localhost:8080,失败是正常的)
[root@node01 ~]# echo $KUBECONFIG/root/.kube/config[root@node01 ~]# ls ~/.kube/configls: 无法访问 \'/root/.kube/config\': 没有那个文件或目录这时,我们可以用这几条命令进行修复。
mkdir -p ~/.kubecp -i /etc/kubernetes/admin.conf ~/.kube/configchown $(id -u):$(id -g) ~/.kube/config我这里直接手动创建,有config这个文件之后就能通过\"kubectl get nodes\"正常看到各个节点的状态了。
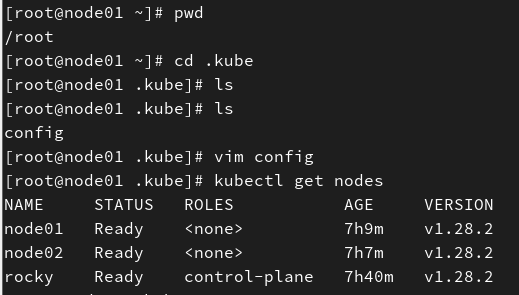
(2)根据\"lookup localhost on 8.8.8.8:53: no such host\"的报错,我们查看/etc/hosts文件,确认/etc/hosts文件里是否有localhost。
#检查cat /etc/hosts |grep localhost#如果没有echo \"127.0.0.1 localhost\" >> /etc/hosts#重试kubectl get nodes(3)代理
如果你配置了代理http_proxy和https_proxy,kubectl、DNS也可能会异常。
#排查env |grep -i proxy#尝试临时取消unset http_proxyunset https_proxyunset HTTP_PROXYunset HTTPS_PROXY#重试kubectl get nodes问题三、资源获取失败(配置错误/版本兼容)
1、报错片段
[root@node02 ~]# kubectl get nodesE0527 21:56:54.255182 614678 memcache.go:265] couldn\'t get current server API group list: the server could not find the requested resourceE0527 21:56:54.255898 614678 memcache.go:265] couldn\'t get current server API group list: the server could not find the requested resourceE0527 21:56:54.258469 614678 memcache.go:265] couldn\'t get current server API group list: the server could not find the requested resourceE0527 21:56:54.259326 614678 memcache.go:265] couldn\'t get current server API group list: the server could not find the requested resourceE0527 21:56:54.261615 614678 memcache.go:265] couldn\'t get current server API group list: the server could not find the requested resourceError from server (NotFound): the server could not find the requested resource2、根因分析
此时kubectl可以连接Api Server,但尝试获取资源时,服务器找不到资源。原因可能是kubeconfig文件指向的Api Server地址错误(当前处于非master节点)或者kubectl与Api Server版本不兼容。
3、解决思路
复制kubeconfig并修改地址
#在master节点执行scp ~/.kube/config node02:/root/.kube/config然后在对应node节点修改~/.kube/config文件
#找到这一段server: https://127.0.0.1:6443#改成下面这一段server: https://master节点的ip:6443#检查kubectl get nodes上面是kubeconfig文件的问题,如果是版本兼容的问题,建议针对性的进行降级或升级。
总结
以上三类问题覆盖了K8s节点部署中的常见痛点,核心思路是:清理残留→检查配置→验证连通性。建议结合日志(journalctl -u kubelet)和集群状态(kubectl get pods -A)综合排查。
> 本文部分内容由 AI 辅助生成,结合本人实践整理而成,欢迎指正与交流。

