如何解决DeepStream拉流时延时越来越长的问题
DeepStream是基于GStreamer框架开发的,像GStreamer这种pipeline架构它有个毛病就是pipeline里任何一个element里的基于pipeline这个context下的同步计算耗时过长导致超过源端视频帧的发送间隔的话会导致整个pipeline里的视频数据流动速度下降从而产生帧积累,如果没有主动丢弃的话,视频播放离实时视频时间上自然相差越来越来多,也就是延时越来越长。加上一个边缘板子上拉几个IPC摄像头的流的话,边缘板子的CPU和GPU处理能力有限,还有长时间运行发热等因素影响导致计算速度变慢,下游插件的计算耗时也会慢慢变长,这样也会导致来不及处理的帧积累越来越多,视频延时越来越长。
但是我们有时在某些element里的同步计算是不可避免的,例如对帧调用模型进行推理,将推理结果发送给下游插件使用去进行结果分析产生分析数据上传云端,还有对视频中的敏感目标进行准实时打码等等这样的需求不可避免,而像调用模型进行推理,精度高的模型都大一点的,大一点的网络模型的推理时间稍长一点,加上数据预处理和推理结果的后处理时间,可能很难低于100ms,假如源端发送视频数据的FPS大于10,那么帧间隔就少于100ms了,这样就会慢慢产生帧积累而延时越来越长,那怎么解决这种问题呢?很显然需要进行主动丢帧才能跟得上实时视频的进度,怎么主动丢帧就是个坑。
像使用rtspsrc来拉取网络摄像头的RTSP流时,rtspsrc element有latency和drop-on-latency组合使用实现解码前丢帧,这样确实可以主动丢帧超过latency设置的值范围的帧数据,但是这样做有个很差的后果就是视频会出现花屏和抖动不清晰,这对后面模型推理非常不利,所以这种做对于有对视频进行推理分析需求的项目显然是不合适的!另外对于nvv4l2decoder,它有drop-frame-interval这样的属性可以设置间隔丢帧,这样做对于interval较大时可能影响不大,较小时丢帧频繁可能还是有花屏出现。
查了国外网上有人推荐在decode后面增加使用queue或者queue2,试了结果没作用,后来仔细看了queue2的说明,发现被误导了!这种element根本就不是用来丢帧的!而是用来缓冲平滑视频效果的!不管怎么调max_size_buffers、max-size-bytes、max-size-time之类的参数都没用的!
Deepstream Infer Plugin里本身的配置文件里也有个interval参数可调,但是这个参数也不能随便乱设,因为我们测试发现这个参数设置大了播放视频是快了,但是目标跟踪效果会差很多,后来我仔细看了nvinfer plugin的源码发现这个interval其实是用来跳过对帧进行推理,但是并没有把跳过推理的帧同时主动丢掉,而是继续往下游发了!这实际上就等同于跳过推理的帧的识别结果为没有识别出目标来!你可以想象这对于下游的目标跟踪插件的伤害有多大!咨询了NVIDIA技术支持,对于这个缺陷也没什么好办法,建议到decode那里主动丢帧或者使用videorate限制framerate,于是把这里的interval重新设置为0,在解码那里主动丢帧影响视频效果,那么可以试验的就是在解码后加videorate了,于是试验在decode后加videorate并设置framerate,实现类似如下的结构:
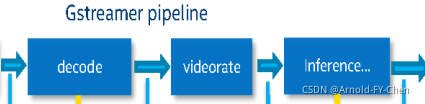
将framerate设置到较低的值,让帧间隔大于inference等下游插件的同步计算所耗费的最大时间,于是实现了视频播放稳定无延时累积(相对于实时视频的时间,绝对的无延时是不可能的,一般的直播软件系统能把延时控制到100ms以内就很优秀了,延时在1-2s以内都算可以接受的结果。我观察过电视台的网络电视相对于有线电视直播信号一般都有30s左右的延时,因为视频的录制切分保存和推流这些时间很难节省,但是这些对于做实时性要求不是很高的视频系统都足够了)。
另外,我们还有个在gstreamer基础上实现丢帧的秘密技术,可以说是终极大法:) 但是涉及到商业机密不便说。

