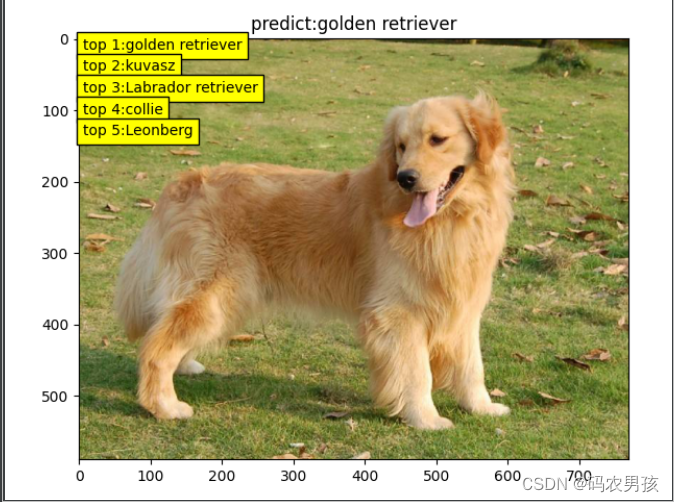
采用在Imagenet上预训练的VGG16模型进行分类测试


预训练权重下载
'vgg11': 'https://download.pytorch.org/models/vgg11-bbd30ac9.pth',
'vgg13': 'https://download.pytorch.org/models/vgg13-c768596a.pth',
'vgg16': 'https://download.pytorch.org/models/vgg16-397923af.pth',
'vgg19': 'https://download.pytorch.org/models/vgg19-dcbb9e9d.pth',
'vgg11_bn': 'https://download.pytorch.org/models/vgg11_bn-6002323d.pth',
'vgg13_bn': 'https://download.pytorch.org/models/vgg13_bn-abd245e5.pth',
'vgg16_bn': 'https://download.pytorch.org/models/vgg16_bn-6c64b313.pth',
'vgg19_bn': 'https://download.pytorch.org/models/vgg19_bn-c79401a0.pth',
进行分类测试
def img_transform(img_rgb, transform=None): """ 将数据转换为模型读取的形式 :param img_rgb: PIL Image :param transform: torchvision.transform :return: tensor """ if transform is None: raise ValueError("找不到transform!必须有transform对img进行处理") img_t = transform(img_rgb) return img_tdef process_img(path_img): # hard code norm_mean = [0.485, 0.456, 0.406] norm_std = [0.229, 0.224, 0.225] inference_transform = transforms.Compose([ transforms.Resize(256), transforms.CenterCrop((224, 224)), transforms.ToTensor(), transforms.Normalize(norm_mean, norm_std), ]) # path --> img img_rgb = Image.open(path_img).convert('RGB') # img --> tensor img_tensor = img_transform(img_rgb, inference_transform) img_tensor.unsqueeze_(0) # chw --> bchw img_tensor = img_tensor.to(device) return img_tensor, img_rgbdef load_class_names(p_clsnames, p_clsnames_cn): """ 加载标签名 :param p_clsnames: :param p_clsnames_cn: :return: """ with open(p_clsnames, "r") as f: class_names = json.load(f) with open(p_clsnames_cn, encoding='UTF-8') as f: # 设置文件对象 class_names_cn = f.readlines() return class_names, class_names_cnif __name__ == "__main__": # config path_state_dict = os.path.join(BASE_DIR, "..", "data", "vgg16-397923af.pth") # path_img = os.path.join(BASE_DIR, "..", "..", "Data","Golden Retriever from baidu.jpg") path_img = os.path.join(BASE_DIR, "..", "data", "Golden Retriever from baidu.jpg") path_classnames = os.path.join(BASE_DIR, "..", "data", "imagenet1000.json") path_classnames_cn = os.path.join(BASE_DIR, "..", "data","imagenet_classnames.txt") # load class names cls_n, cls_n_cn = load_class_names(path_classnames, path_classnames_cn) # 1/5 load img img_tensor, img_rgb = process_img(path_img) # 2/5 load model vgg_model = get_vgg16(path_state_dict, device, True) # 3/5 inference tensor --> vector with torch.no_grad(): time_tic = time.time() outputs = vgg_model(img_tensor) time_toc = time.time() # 4/5 index to class names _, pred_int = torch.max(outputs.data, 1) _, top5_idx = torch.topk(outputs.data, 5, dim=1) pred_idx = int(pred_int.cpu().numpy()) pred_str, pred_cn = cls_n[pred_idx], cls_n_cn[pred_idx] print("img: {} is: {}\n{}".format(os.path.basename(path_img), pred_str, pred_cn)) print("time consuming:{:.2f}s".format(time_toc - time_tic)) # 5/5 visualization plt.imshow(img_rgb) plt.title("predict:{}".format(pred_str)) top5_num = top5_idx.cpu().numpy().squeeze() text_str = [cls_n[t] for t in top5_num] for idx in range(len(top5_num)): plt.text(5, 15+idx*30, "top {}:{}".format(idx+1, text_str[idx]), bbox=dict(fc='yellow')) plt.show()结果展示