jd爬虫全流程requests+json+etree+pandas
今天打开pycharm发现去年十二月各种翻阅资料总结写的爬虫记录还在,记录下
温馨提示:爬虫玩得越行,你就越刑。切忌在合法合理情况下使用。
中国python爬虫违法违规案例大汇总:https://blog.csdn.net/huang5333/article/details/114656888
下面开始正题,先来个最终获取数据图
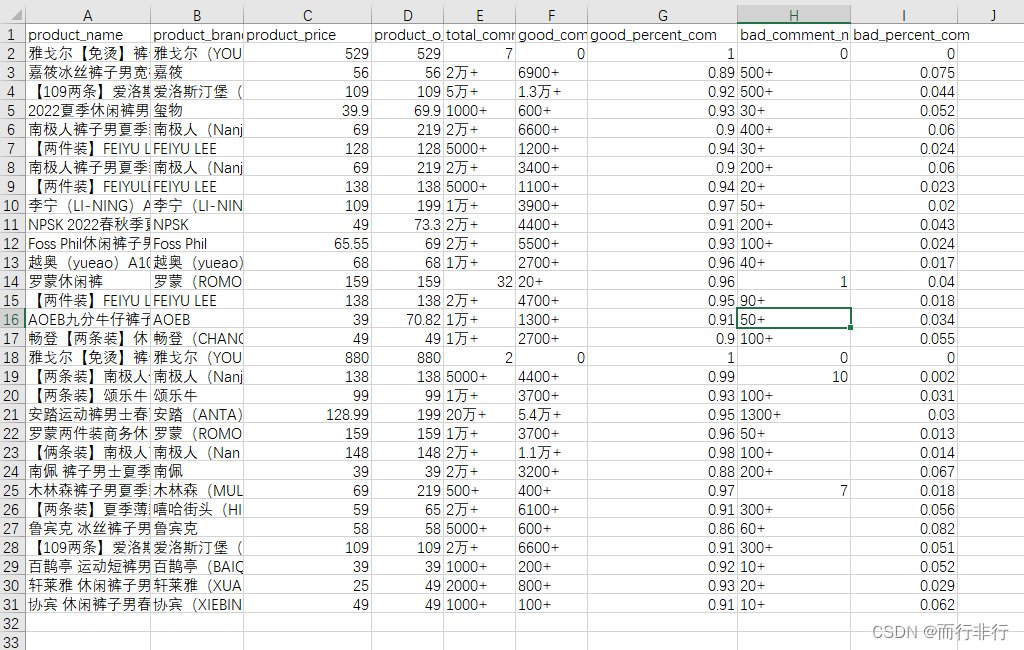
思路:
1、输入关键字,获取每个物品URL
2、将所获取的URL存储到一个集合中A,当使用时,从集合取出一条,集合数量A-1
3、取出一条URL,抓取信息数据
4、存储数据
一、获取页面URL
模拟在搜索栏输入关键字,获取页面物品URL(目前代码只能获取30条URL)
例如:url = ‘https://search.jd.com/Search?keyword=小米8’
import requestsfrom lxml import etreeheaders = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) ' 'Chrome/92.0.4515.131 Safari/537.36'}class url_data: def get_url(self, url): urls = list() response = requests.get(url, headers=headers) response.encoding = 'utf-8' detail = etree.HTML(response.text) # etree转HTML for i in range(30): [product_name] = detail.xpath( '//*[@id="J_goodsList"]/ul/li[' + str(i + 1) + ' ]/div/div[1]/a/@href') # 商品url # print("href:" + str(product_name)) urls.append(str(product_name)) print(urls) return urlsif __name__ == '__main__': url = 'https://search.jd.com/Search?keyword=小米8' u = url_data() u.get_url(url)二、保存URL到集合中
class URLManager(object): def __init__(self): # 设定新url与以爬取url集合 self.new_urls = set() self.old_urls = set() def save_new_url(self, url): # 将单条新url保存到待爬取集合中 if url is not None: if url not in self.new_urls and url not in self.old_urls: print("保存新URL:{}".format(url)) self.new_urls.add(url) def save_new_urls(self, url_list): # 批量保存url for url in url_list: self.save_new_url(url) def get_new_url(self): # 取出一条未爬取的url,同时保存到以爬取url中 if self.get_new_url_num() > 0: url = self.new_urls.pop() self.old_urls.add(url) return url else: return None def get_new_url_num(self): # 返回未爬取的url数量 return len(self.new_urls) def get_old_url_num(self): # 返回已经爬取的url数量 return len(self.old_urls)三、取数
提示:当前创作和你的工作、学习是什么样的关系
例如:
- 创作是否已经是你生活的一部分了
- 有限的精力下,如何平衡创作和工作学习
import reimport requestsimport jsonfrom lxml import etreeimport pandas as pd# 代理headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) ' 'Chrome/92.0.4515.131 Safari/537.36'}class JDdata: def get_data(self, url): # data = list() # 取出商品id global product_name, title url_p = 'https://item.jd.com/(.*?).html' Goods_id = re.findall(url_p, url, re.S) # print(Goods_id) response = requests.get(url, headers=headers) response.encoding = 'utf-8' detail = etree.HTML(response.text) # etr转HTML """---------------名称------------------------""" try: # [product_name] = detail.xpath('//*[@id = "detail"]/div[2]/div[1]/div[1]/ul[3]/li[1]/@title') [product_name] = detail.xpath('//*[@id="detail"]/div[2]/div[1]/div[1]/ul[2]/li[1]/@title') # 商品名称 # print("商品名称:" + str(product_name)) except: print('商品名称无法抓取,请查看设置的“xpath”格式') """---------------品牌------------------------""" # [product_brand] = detail.xpath('//*[@id="parameter-brand"]/li/a/text()') # 品牌 [product_brand] = detail.xpath('//*[@id="parameter-brand"]/li/a/text()') print("品牌:" + str(product_brand)) """---------------标题------------------------""" # [title] = detail.xpath('/html/body/div[6]/div/div[2]/div[1]/text()') # 标题 # # title = str(title).strip() # print("标题:" + str(title).strip()) """---------------价格------------------------""" # 请求价格信息json p = requests.get('https:' + '//p.3.cn/prices/mgets?skuIds=J_' + Goods_id[0], headers=headers) # 请求商品价格json [product_dict] = json.loads(p.text) # 获取商品价格 product_m_price = product_dict['m'] # 最高价格 product_price = product_dict['p'] # 当前价格 product_o_price = product_dict['op'] # 指导价格 # print('最高价格:' + str(product_m_price)) # print("商品价格:" + str(product_price)) # print("指导价格:" + str(product_o_price)) # 请求评论信息json c = requests.get('https://club.jd.com/comment/productCommentSummaries.action?referenceIds=' + Goods_id[0], headers=headers) comment_dict = json.loads(c.text.split('[')[-1].split(']')[0]) # json内容截取 total_comment_num = comment_dict['CommentCountStr'] good_comment_num = comment_dict['GoodCountStr'] good_percent_com = comment_dict['GoodRate'] bad_comment_num = comment_dict['PoorCountStr'] bad_percent_com = comment_dict['PoorRate'] # print('总评论数为:' + str(total_comment_num)) # print('好评数:' + str(good_comment_num)) # print('好评率:' + str(good_percent_com)) # print('差评数:' + str(bad_comment_num)) # print('差评率:' + str(bad_percent_com)) print('差评率:' + str(bad_percent_com)) data = pd.DataFrame([[str(product_name), str(product_brand).strip(), product_price, product_o_price, str(total_comment_num), str(good_comment_num), str(good_percent_com), str(bad_comment_num), str(bad_percent_com)]],columns=['product_name', 'product_brand', 'product_price', 'product_o_price', 'total_comment_num', 'good_comment_num', 'good_percent_com', 'bad_comment_num', 'bad_percent_com']) return data# 测试if __name__ == '__main__': url = 'https://item.jd.com/100020693650.html' jd = JDdata() jd.get_data(url)四、存储数据
import osimport pandas as pdclass DataSave: # 指定数据保存的文件路径 def __init__(self, path): self.path = path def save(self, data): # 判断文件路径是否存在,不存在自动创建添加数据,否则追加数据,去重表头 if not os.path.exists(self.path): print('--->' + '\'' + self.path + '\'' + '路径不存在') print('--->' + '已自动创建该路径') data.to_csv(self.path, encoding='utf_8_sig', index=False, index_label=False, mode='a') print('--->' + '数据首次保存') else: data.to_csv(self.path, encoding='utf_8_sig', index=False, mode='a', header=False, index_label=False) print('--->' + '数据追加保存')if __name__ == "__main__": data = pd.DataFrame([['李王三', '48', '男'], ['张一五', '43', '男']], columns=['name', 'age', 'sex']) save_path = 'E:\\jd.csv' ds = DataSave(save_path) ds.save(data)五、任务调度
from urlmanager import URLManagerfrom goods_data import JDdatafrom url_data import url_datafrom save_data import DataSaveheaders = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) ' 'Chrome/92.0.4515.131 Safari/537.36'}class Scheduler: def __init__(self, path, root_url): # 初始化各个组件 self.url_manager = URLManager() self.url_data = url_data() self.jd_data = JDdata() self.save_data = DataSave(path) self.root_url = root_url # self.count = count def run_spider(self): # 先添加一条url到未爬取url集合中 self.url_manager.save_new_url(self.root_url) # 获取一条未爬取url url = self.url_manager.get_new_url() # 通过搜索商品获得的所有url(目前是30条) new_urls = self.url_data.get_url(url) # 将获取到的url保存到未爬取url集合中 self.url_manager.save_new_urls(new_urls) # print(new_urls) # 保存数据到本地文件 # self.data_save.save(data) # get_new_url会减少一条url,所以只需判断大于0 while len(self.url_manager.new_urls) > 0: url = self.url_manager.get_new_url() url = 'https:' + url print(url) # print(url) data = self.jd_data.get_data(url) self.save_data.save(data)if __name__ == "__main__": root_url = "https://search.jd.com/Search?keyword=裤子" save_url = "E:\\jd.csv" Spider = Scheduler(save_url, root_url) Spider.run_spider()
