搭建大型分布式服务(三十四)十分钟搭SpringBoot积木 - 数据重放
系列文章目录

文章目录
- 系列文章目录
- 前言
-
-
- 一、本文要点
- 二、开发环境
- 三、容器模式
- 四、小结
-
前言
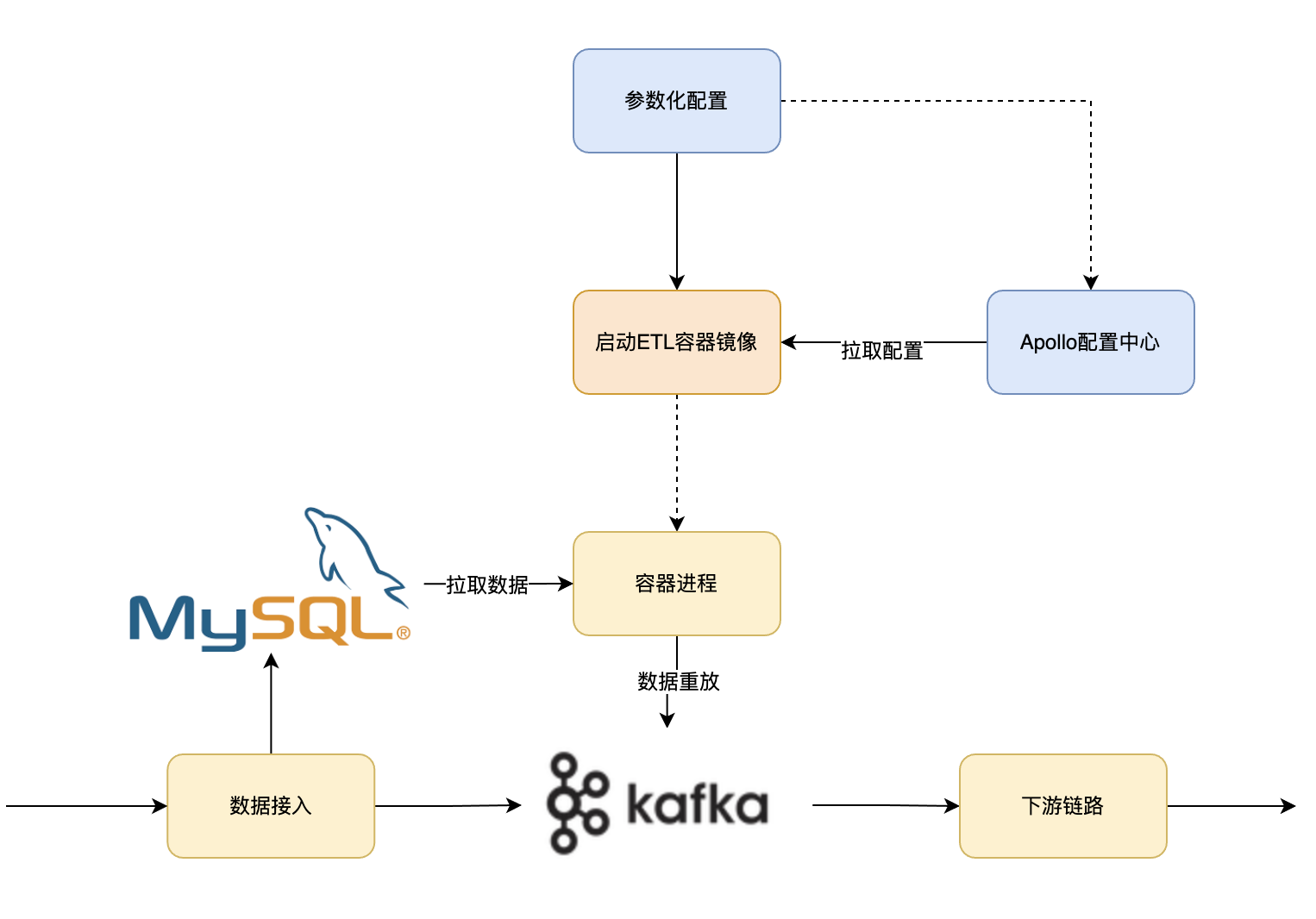
玩转SpringBoot,像搭积木一样简单。在实际数据加工处理的业务中,整体数据链路比较长。下游加工逻辑在频繁迭代的时候,往往需要把客户接入的请求进行数据重放,来达到灰度升级的目的。那怎样快速把客户接入的数据重放给下游链路呢?
一、本文要点
前面的文章,介绍了基于Jolt如何实现业务型的ETL工具,本文将介绍这款工具的实际应用场景,如何快速将DB数据快速重放到kafka。系列文章完整目录
- JSON to JSON
- JSON 结构转换
- Kafka 转存到 ES
- Kafka 转存到 DB
- DB 数据转KAFKA消息
- DB 数据转存ES
- 低代码平台
- SpringBoot积木
二、开发环境
- jdk 1.8
- maven 3.6.2
- springboot 2.4.3
- Jolt 0.1.5
- kafka 2.0
- es 6.8.2
- idea 2020
三、容器模式
1、新建容器
使用制作好的etl镜像,创建工作负载,参考文章:
《搭建大型分布式服务(二十五)如何将应用部署到TKE容器集群?》
《搭建大型分布式服务(二十七)如何通过Coding流水线CI/CD将SpringBoot服务部署到TKE容器集群》
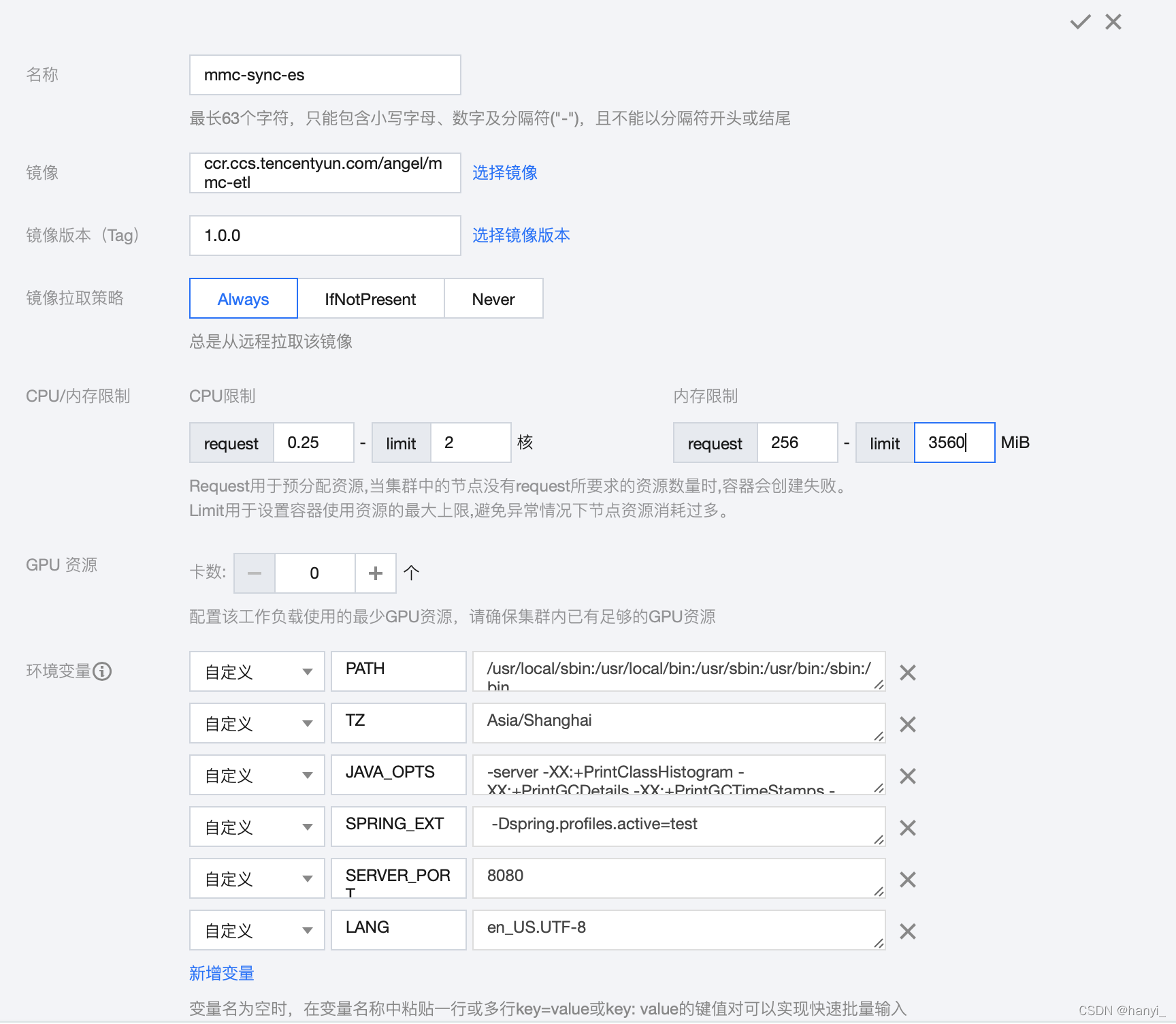
其中SPRING_EXT变量可以自定义profile的值,指定加载applicationn-xxx.properties文件的配置。
参考:《搭建大型分布式服务(三)SpringBoot多环境配置》
2、配置同步参数
(1)可以直接在Apollo配置中心直接修改profile对应环境的application.properties文件配置信息。
参考:《搭建大型分布式服务(十七)SpringBoot 配置托管到Apollo》
(2)也可以直接利用SpringBoot配置文件加载顺序原因,将文件application-xxx.properties挂载到容器config/application-xxx.properties目录,覆盖容器目录中的文件。
## 公共配置spring.datasource.driver-class-name=com.mysql.cj.jdbc.Driverspring.datasource.type=com.zaxxer.hikari.HikariDataSource# 输入 #spring.jolt.input.type=dbspring.jolt.input.db.objectId=1spring.jolt.input.db.range-sql=select min(id) startIndex, max(id) endIndex from t_book where 1=1 and id > ? spring.jolt.input.db.select-sql=select * from t_book where 1=1 and kaid = ? and id >= ? and id < ? spring.jolt.input.db.hikari.jdbc-url=jdbc:mysql://127.0.0.1:3306/book?useUnicode=true&characterEncoding=utf8&autoReconnect=true&useSSL=false&zeroDateTimeBehavior=convertToNull&allowMultiQueries=true&serverTimezone=GMT%2B8spring.jolt.input.db.hikari.username=rootspring.jolt.input.db.hikari.password=spring.jolt.input.db.hikari.minimum-idle=1spring.jolt.input.db.hikari.maximum-pool-size=15spring.jolt.input.db.hikari.auto-commit=truespring.jolt.input.db.hikari.idle-timeout=30000spring.jolt.input.db.hikari.pool-name=primary_poolspring.jolt.input.db.hikari.max-lifetime=1800000spring.jolt.input.db.hikari.connection-timeout=30001spring.jolt.input.db.hikari.connection-test-query=SELECT 1 FROM DUALspring.jolt.input.db.hikari.connection-init-sql=set names utf8mb4# 转换 #spring.jolt.spec.value=[{"operation":"shift","spec":{"data":{"bookId":"book_id", "bookName":"book_name"}}}]spring.jolt.spec.filter=# 输出 DBspring.jolt.output.mq.enabled=truespring.jolt.output.mq.topic=mmc-kafka-testspring.jolt.output.mq.producer.bootstrap-servers=127.0.0.1:9092spring.jolt.output.mq.producer.key-serializer=org.apache.kafka.common.serialization.StringSerializerspring.jolt.output.mq.producer.value-serializer=org.apache.kafka.common.serialization.StringSerializerspring.jolt.output.mq.partition-key=book_idspring.jolt.spec.value 是基于jolt转换逻辑的核心配置项,在这可以不用写任何java代码就可以实现db数据转换成kafka格式。
3、完成配置后,启动容器,db数据重放到kafka任务就已经正常运行。其中spring.jolt.input.db.range-sql配置控制扫表的条件,spring.jolt.input.db.select-sql控制从db里打捞数据的格式。
四、小结
至此,简单几步,本文就实现了db数据按任意格式重放到kafka了。下一篇《搭建大型分布式服务(三十五)基于JOLT的ETL工具 - DB数据迁移》
加我加群一起交流学习!更多干货下载、项目源码和大厂内推等着你
 |
 |
 |

