【Kafka】第二篇-Kafka的核心概念及分区消费规则
【上一篇【Kafka】第一篇-初识Kafka】
学习路线
-
- Kafka核心概念
-
-
- Producer:
- Consumer:
- Consumer Group:
- Broker:
- Topic:
- Partition:
- Replica:
- Leader:
- Follower:
- Zookeeper:
-
- kafka消息发送策略
- 消费端消费指定分区
- 消息消费原理
-
-
- 1、在有多个partition以及多个consumer的情况下,消费者是如何负载均衡消费消息?
- 2、 同一个consumer group 里面的 consumer如何去分配应该消费哪个分区里的消息?
-
- 何时触发分区消费策略?
- 如何保存消费端的消费位置
-
-
- offset(称之为偏移量)
- 对于应用层的消费来说,每次消费一个消息并且提交以后,会保存当前消费到的最近的一个 offset,那么 offset 保存在哪里?
-
- 消息消费确认方式
-
-
- 自动确认
- 手动确认
-
- 消息的存储
- Kafka集群
Kafka核心概念
Producer:
消息生产者,向 Kafka Broker 发消息的客户端;
Consumer:
消息消费者,从 Kafka Broker 取消息的客户端;
Consumer Group:
- 消费者组,消费者组内每个消费者负责消费不同分区(可以看做是topic下的队列)的数据,提高消费能力,一个分区只能由组内一个消费者消费,消费者组之间互不影响,所有的消费者都属于某个消费者组,即消费者组是逻辑上的一个订阅者;(组内竞争,组之间平等);
Broker:
- 一台 Kafka 机器就是一个 broker,一个集群由多个 broker 组成,一个 broker 可以容纳多个 topic;
Topic:
- Topic是一个存储消息的逻辑上的概念,不是物理上的,可以认为是一个消息集合,topic将消息进行了分类,生产者和消费者面向的是同一个 topic,从物理上来说,不同的 topic 的消息是分开存储的,每个 topic 可以有多个生产者向它发送消息,也可以有多个消费者去消费其中的消息;
Partition:
-
为了实现扩展性,提高并发能力,一个topic可以分为多个 partition(每个 Topic 至少有一个分区),每个 partition 是一个有序的队列;
-
同一 topic 下的不同分区包含的消息是不同的。每个消息在被添加到分区时,都会被分配一个 offset(称之为偏移量),它是消息在此分区中的唯一编号,kafka 通过 offset保证消息在分区内有有序的(有顺序的),offset 的顺序不跨分区,即 kafka只保证在同一个分区内的消息是有序的;
-
下图中,对于名字为 MyTopic的 topic,做了 3 个分区,分别是p0、p1、p2,每一条消息发送到 broker 时,会根据 partition 的规则选择存储到哪一个 partition,如果partition规则设置合理,那么所有的消息会均匀的分布在不同的partition中;
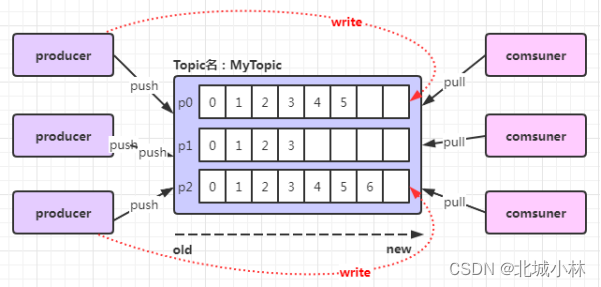
-
partition是以文件的形式存储在文件系统中,比如创建一个名为 MyTopic 的 topic,其中有 3 个 partition,那么在kafka 的数据目录(默认是/tmp/kafka-log)中就有 3 个目录MyTopic-0、MyTopic-1、MyTopic-2,命名规则是-;
比如:
./kafka-topics.sh --create --zookeeper 192.168.1.1:2181 --replication-factor 1 --partitions 3 --topic abc- Kafka默认情况下一个topic只有一个partition,可以通过kafka的config目录下的server.properties进行配置:
num.partitions=1或者是通过命令修改分区数:
./kafka-topics.sh –zookeeper localhost:2181 -alter –partitions 5 –topic mytopicReplica:
- 副本,为实现备份的功能,保证集群中的某个节点发生故障时,该节点上的 partition 数据不丢失,且 Kafka 仍然能够继续工作,Kafka 提供了副本机制,一个 topic 的每个分区都有多个副本,一个leader和多个follower;
Leader:
- 每个分区多个副本中的“主”副本,生产者发送数据的对象,以及消费者消费数据的对象,都是 leader;
Follower:
- 每个分区多个副本中的“从”副本,实时从 leader 中同步数据,保持和 leader 数据的同步,leader 发生故障时,某个follower会成为新的 leader;
设置副本数大于节点个数,将导致不能正常创建topic;
Zookeeper:
- Kafka 集群能够正常工作,需要依赖于 zookeeper,zookeeper 帮助 Kafka 存储和管理集群信息;
kafka消息发送策略
消息是 kafka 中最基本的数据单元,在 kafka 中,一条消息由 key、value 两部分构成,在发送一条消息时,我们可以指定key,那么 producer 会根据 key 和 partition 机制来判断当前这条消息应该发送并存储到哪个 partition 中;
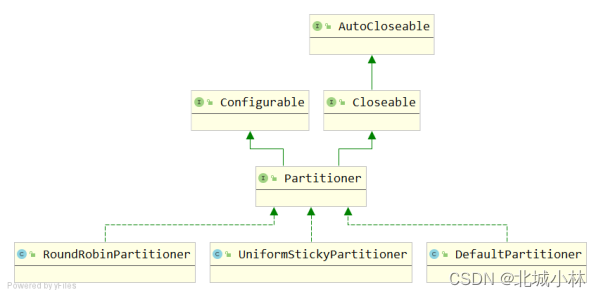
- 默认情况下是使用DefaultPartitioner实现分区的选择,如果key为空,则使用StickyPartitionCache进行分区选择;
- 我们也可以根据需要进行扩展producer的partition分区选择机制;
//自定义选择分区properties.put(ProducerConfig.PARTITIONER_CLASS_CONFIG, "com.beichengxiaolin.partition.MyPartition");消费端消费指定分区
- 通过下面的代码,就可以消费指定该topic下的0号分区,其他分区的数据就无法接收;
//消费指定分区的时候,不需要再订阅//kafkaConsumer.subscribe(Collections.singletonList(topic));//消费指定的分区TopicPartition topicPartition = new TopicPartition(topic, 0);kafkaConsumer.assign(Arrays.asList(topicPartition));消息消费原理
- 在实际应用中,每个 topic 都会有多个partitions,多个partitions的好处在于,一方面能够对broker上的消息进行分片,有效减少消息的容量从而提升io 性能,另外一方面,可以提高消费端的消费能力,通过多个consumer去消费同一个topic,也就是消费端的负载均衡机制;
1、在有多个partition以及多个consumer的情况下,消费者是如何负载均衡消费消息?
- Kafka有consumer group的概念, 也就是group.id一样的consumer 属于同一个consumer group,组内的所有消费者协调在一起来消费topic的所有分区,当然每一个分区只能由同一个消费组内的某一个consumer 来消费;
2、 同一个consumer group 里面的 consumer如何去分配应该消费哪个分区里的消息?
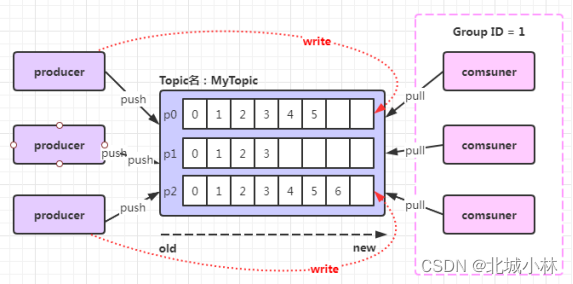
- (1)如上图,3 个分区,3 个消费者,那么这 3 个消费者会分别消费MyTopic 这个topic 的 3 个分区,也就是每个 consumer 消费一个partition;
- (2)同一group中的消费者对于一个topic中的多个partition,存在一定的分区消费分配策略;
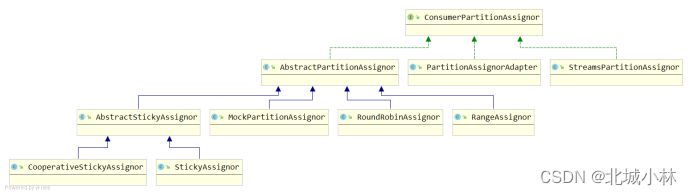
- 在kafka中有几种分区消费分配策略,一种是Range范围分区消费分配策略(默认)、另一种是RoundRobin轮询分区分配策略,通过partition.assignment.strategy参数来设置;
何时触发分区消费策略?
当出现以下几种情况时,kafka会进行一次分区消费分配策略操作,也就是 kafka consumer 的 rebalance(重新负载均衡)
- 同一个 consumer group 内新增了消费者;
- 消费者离开当前所属的 consumer group,比如主动停机或者宕机;
- topic 新增了分区(也就是分区数量发生了变化);
kafka consuemr 的 rebalance 机制规定了一个consumer group下的所有 consumer 如何达成一致来分配订阅 topic的每个分区,而具体如何执行分区策略,就是前面提到过的两种(现在有4种)内置的分区策略,同时kafka 对于分配策略提供了可插拔的实现方式,即除了这两种内置的分区策略外,还可以创建自己的分区分配策略;
- 实现org.apache.kafka.clients.consumer.ConsumerPartitionAssignor接口,实现里面的assign方法;
如何保存消费端的消费位置
offset(称之为偏移量)
- 每个 topic可以划分多个分区(每个 Topic 至少有一个分区),同一topic 下的不同分区包含的消息是不同的,每个消息在被添加到分区时,都会被分配一个 offset(称之为偏移量),它是消息在此分区中的唯一编号,kafka 通过 offset 保证消息在分区内的顺序,offset 的顺序不跨分区,即 kafka 只保证在同一个分区内的消息是有序的;
对于应用层的消费来说,每次消费一个消息并且提交以后,会保存当前消费到的最近的一个 offset,那么 offset 保存在哪里?
- 在 kafka 中,提供了一个__consumer_offsets 的一个topic, 把offset信 息 写 入 到 这 个 topic 中,__consumer_offsets保存了每个 consumer group某一时刻提交的 offset 信息,__consumer_offsets 默认有50个分区;
首先找到这个 consumer_group 保存在哪个分区中: - 计算公式
Math.abs(“groupid”.hashCode())%groupMetadataTopicPartitionCount ; 由于默认情况下,groupMetadataTopicPartitionCount 有50个分区;
int partition = Math.abs(MyConsumer.class.getSimpleName().hashCode()) % 50;System.out.println(partition);算得到的结果为:28, 意味着当前的 consumer_group 的位移信息保存在__consumer_offsets 这个topic的第 28 个分区;
执行如下命令,可以查看当前 consumer_goup 中的offset 位移信息:
./kafka-console-consumer.sh --topic __consumer_offsets --bootstrap-server 192.168.172.127:9092 --formatter输出结果:
"kafka.coordinator.group.GroupMetadataManager\$OffsetsMessageFormatter" --partition 28从输出结果中,我们就可以看到 test 这个 topic 的 offset的位移日志;

消息消费确认方式
自动确认

手动确认
手动异步确认consumer. commitASync() //手动异步ack手动同步确认consumer. commitSync() //手动异步ack消息的存储
kafka 是使用日志文件的方式来保存生产者和发送者的消息,每条消息都有一个 offset 值来表示它在分区中的偏移量,Kafka 中存储的一般都是海量的消息数据,为了避免日志文件过大,Log 并不是直接对应在一个磁盘上的日志文件,而是对应磁盘上的一个目录,这个目录的明明规则是_,
- 比如创建一个名为 firstTopic 的 topic,其中有 3 个 partition,那么在 kafka 的数据目录(/tmp/kafka-log)中就有 3 个目录,firstTopic-0、firstTopic-1、firstTopic-2;
Kafka集群
(集群配置比较简单,里面的细节比较多)
- 1、kafka是一个压缩包,直接解压即可使用,所以我们就解压三个kafka;
- 2、配置kafka集群:
- (1)三台分别配置为:
broker.id=1、broker.id=2、broker.id=3该配置项是每个broker的唯一id,取值在0~255之间;
- (2)三台分别配置listener=PAINTEXT:IP:PORT
listeners=PLAINTEXT://192.168.1.1:9091listeners=PLAINTEXT://192.168.1.1:9092listeners=PLAINTEXT://192.168.1.1:9093三台分别配置advertised.listeners=PAINTEXT:IP:PORT
advertised.listeners=PLAINTEXT://192.168.1.1:9091advertised.listeners=PLAINTEXT://192.168.1.1:9092advertised.listeners=PLAINTEXT://192.168.1.1:9093- (3)配置日志目录
log.dirs=/usr/local/kafka_2.13-2.5.0-01/logs/kafka-logslog.dirs=/usr/local/kafka_2.13-2.5.0-02/logs/kafka-logslog.dirs=/usr/local/kafka_2.13-2.5.0-03/logs/kafka-logs这是极为重要的配置项,kafka所有数据就是写入这个目录下的磁盘文件中的;
- (4)配置zookeeper连接地址
zookeeper.connect=localhost:2181- 如果zookeeper是集群,则:
zookeeper.connect=localhost:2181,localhost:2182,localhost:2183
