Kafka实战《原理》
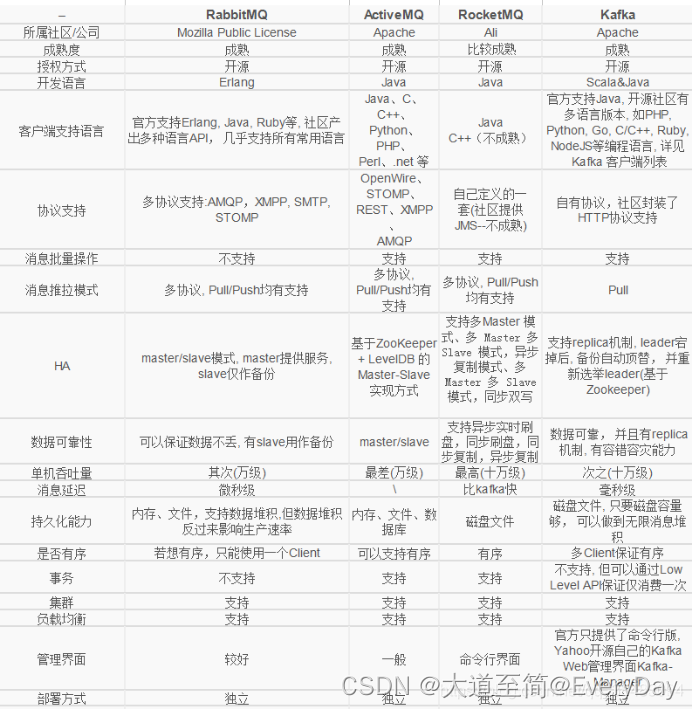
定义
传统定义:Kafka是一个分布式的基于发布订阅模式的消息队列,主要用于大数据实时处理领域。
最新定义: Kafka是一个开源的分布式事件流平台,主要用于高性能的数据通道,流分析,数据集成和关键任务应用。
消息队列
应用场景
1,异步处理
2,系统解耦
3,流量削峰
4,日志处理
5,消息通讯
两种模式
点对点模式: 消费者主动拉取数据,消息收到后清除消息
发布/订阅模式:
- 可以有个多个topic主题
- 消费者消费数据之后,不删除数据
- 每个消费者独立,都可以消费数据
kafka架构
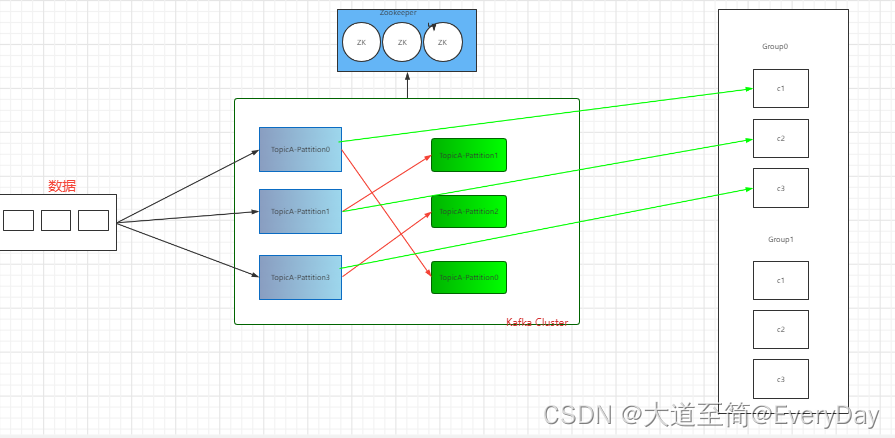
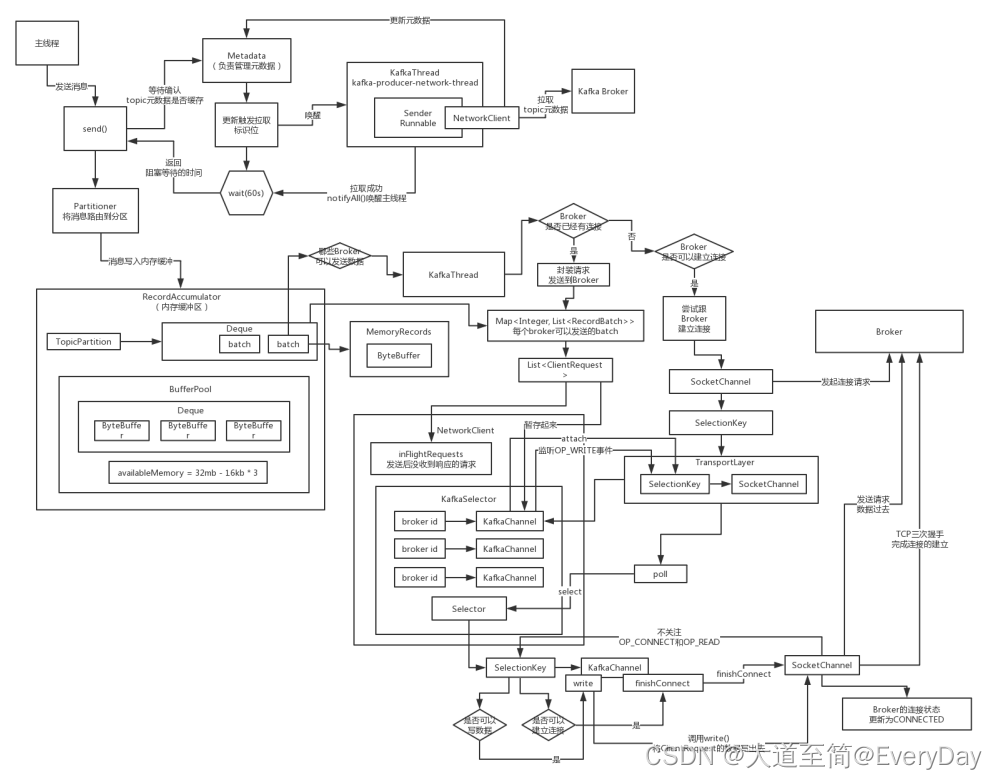
1)Producer: 消息生产者,就是向kafka broker 发消息的客户端
2)Consumer: 消息消费者,向Kafka broker取消息的客户端
3)Consumer Group: 消费者组,由多个消费者组成。每个消费者负责消费不同分区的数据,一个分区只能有一个组内消费者消费;消费者组之间相互不影响。
4)Broker:一台kafka服务器就是一个broker。一个集群有多个broker组成。一个broker可以容纳多个topic。
5)Topic:可以理解为一个队列,生产者和消费者面向都是一个Topic。
6)Partition:为了实现扩展性,一个非常大的topic可以分不到多个broker上,一个topic可以分为多个partition,每个partition是一个有序的队列。
7)Replica:副本,一个topic的每个分区都有若干个副本,一个leader和若干个Follwoer。
8)Leader:每个分区的多个副本的主,生产者发送数据的对象及消费者消费数据的对象都是Leader。
9)Follwower: 每个分区多个副本的从,实时的从Leader中同步数据,保持和Leader的数据同步。Leader发生故障的时候,某个Follower会成为新的Leader。
集群部署
1 官方下载地址
2 配置
#创建目录mkdir /opt/module/#解压tar -zxvf kafka_2.12-3.0.0.tgz -C /opt/module/# 进入module目录并修改目录名称cd /opt/module/mv kafka_2.12-3.0.0/ kafka#修改配置文件cd config/vim server.properties输入一下内容


3 分别在 ah102和ah103 上修改配置文件/opt/module/kafka/config/server.properties
中的 broker.id=1、 broker.id=2
注: broker.id 不得重复,整个集群中唯一。
4 启动集群
4.1 启动zk集群
4.2 启动kafka集群
./bin/kafka-server-start.sh -daemon config/server.properties集群启停脚本
vi kf.sh
#! /bin/bashcase $1 in"start"){for i in hadoop102 hadoop103 hadoop104doecho " --------启动 $i Kafka-------"ssh $i "/opt/module/kafka/bin/kafka-server-start.sh -daemon /opt/module/kafka/config/server.properties"done};;"stop"){for i in ah101 ah102 ah103doecho " --------停止 $i Kafka-------"ssh $i "/opt/module/kafka/bin/kafka-server-stop.sh "done};;esac# 添加权限chmod -x kf.sh#启动命令 kf.sh start #停止命令 kf.sh stop注意: 停止 Kafka 集群时,一定要等 Kafka 所有节点进程全部停止后再停止 Zookeeper
集群。因为 Zookeeper 集群当中记录着 Kafka 集群相关信息, Zookeeper 集群一旦先停止,
Kafka 集群就没有办法再获取停止进程的信息,只能手动杀死 Kafka 进程了
未完待续。。。
 创作打卡挑战赛
创作打卡挑战赛  赢取流量/现金/CSDN周边激励大奖三国人物百科
赢取流量/现金/CSDN周边激励大奖三国人物百科

