BOOT 整合 ElasticSearch
整合前先理解几个概念 与关键字
- 索引 一组相似文档的集合
一个索引就是一个拥有几分相似特征的文档的集合。比如说,你可以有一个商品数据的索引,一个订单数据的索引,还有一个用户数据的索引。一个索引由一个名字来标识(必须全部是小写字母的),并且当我们要对这个索引中的文档进行索引、搜索、更新和删除的时候,都要使用到这个名字。
- 映射 用来定义索引存储文档的结构:字段、类型等
映射是定义一个文档和它所包含的字段如何被存储和索引的过程。在默认配置下,ES可以根据插入的数据自动地创建mapping,也可以手动创建mapping。 mapping中主要包括字段名、字段类型等
-
文档 索引中一条记录,可以被索引的最小单元
文档是索引中存储的一条条数据。一条文档是一个可被索引的最小单元。ES中的文档采用了轻量级的JSON格式数据来表示。
-
分片
Elasticsearch提供了将索引划分成多份的能力,这些份就叫做分片。当你创建一个索引的时候,你可以指定你想要的分片的数量。每个分片本身也是一个功能完善并且独立的“索引”,这个“索引”可以被放置 到集群中的任何节点上。
- 复制
Index的分片中一份或多份副本。
关键字对比
|
ElasticSearch |
对比 |
|
must |
相当于MySQL的and |
|
should |
相当于MySQL的or |
|
must_not |
相当于MySQL的not不等于 |
| gt | 大于 |
| git | 大于等于 |
| lt | 小于 |
| lte | 小于等于 |
|
match |
分词查询 |
|
term |
完全匹配 |
| fuzzy | 误拼写查询 |
| range | 范围查询 |
| wildcard | 模糊查询 |
| exists | 排除null |
| match_phrase | 短语匹配 |
| match_phrase和match区别 | match是分词匹配(将输入的词进行分词),match_phrase是短语匹配(输入文本进行查找) |
ES存储类型:
文本类型 - text
在Elasticsearch 5.4 版本开始, text取代了需要分词的string, 当一个字段需要用于全文搜索(会被分词), 比如产品名称、产品描述信息, 就应该使用text类型.
text的内容会被分词, 可以设置是否需要存储: “index”: “true|false” 。text类型的字段不能用于排序, 也很少用于聚合.
PUT website{"mappings": { "blog": { "properties": { "summary": {"type": "text", "index": "true"} } } }}关键字类型 - keyword
在Elasticsearch 5.4 版本开始, keyword取代了不需要分词的string.—— 当一个字段需要按照精确值进行过滤、排序、聚合等操作时, 就应该使用keyword类型.
keyword的内容不会被分词, 可以设置是否需要存储: “index”: “true|false”.
PUT website{"mappings": { "blog": { "properties": { "tags": {"type": "keyword", "index": "true"} } } }}数字类型 - 8种
|
类型 |
说明 |
|
byte |
有符号的8位整数, 范围: [-128 ~ 127] |
|
short |
有符号的16位整数, 范围: [-32768 ~ 32767] |
|
integer |
有符号的32位整数, 范围: [−231 ~ 231-1] |
|
long |
有符号的64位整数, 范围: [−263 ~ 263-1] |
|
float |
32位单精度浮点数 |
|
double |
64位双精度浮点数 |
|
half_float |
16位半精度IEEE 754浮点类型 |
|
scaled_float |
缩放类型的的浮点数, 比如price字段只需精确到分, 57.34缩放因子为100, 存储结果为5734 |
使用注意事项:
尽可能选择范围小的数据类型, 字段的长度越短, 索引和搜索的效率越高;优先考虑使用带缩放因子的浮点类型.
PUT shop{ "mappings": { "book": { "properties": { "name": {"type": "text"}, "quantity": {"type": "integer"}, // integer类型 "price": { "type": "scaled_float",// scaled_float类型 "scaling_factor": 100 } } } }}日期类型 - date
JSON没有日期数据类型, 所以在ES中, 日期可以是:包含格式化日期的字符串, “2018-10-01”, 或"2018/10/01 12:10:30"
代表时间毫秒数的长整型数字。代表时间秒数的整数.
如果时区未指定, 日期将被转换为UTC格式, 但存储的却是长整型的毫秒值.
可以自定义日期格式, 若未指定, 则使用默认格式: strict_date_optional_time||epoch_millis
// 添加映射PUT website{ "mappings": { "blog": { "properties": { "pub_date": {"type": "date"} // 日期类型 } } }}// 添加数据PUT website/blog/11{ "pub_date": "2018-10-10" }PUT website/blog/12{ "pub_date": "2018-10-10T12:00:00Z" }// Solr中默认使用的日期格式PUT website/blog/13{ "pub_date": "1589584930103" }// 时间的毫秒值(2) 多种日期格式:
多个格式使用双竖线||分隔, 每个格式都会被依次尝试, 直到找到匹配的.第一个格式用于将时间毫秒值转换为对应格式的字符串.
/ 添加映射PUT website{ "mappings": { "blog": { "properties": { "date": { "type": "date", // 可以接受如下类型的格式 "format": "yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis" } } } }}布尔类型 - boolean
可以接受表示真、假的字符串或数字:
真值: true, “true”, “on”, “yes”, “1”…
假值: false, “false”, “off”, “no”, “0”, “”(空字符串), 0.0, 0
二进制型 - binary
二进制类型是Base64编码字符串的二进制值, 不以默认的方式存储, 且不能被搜索. 有2个设置项:
(1) doc_values: 该字段是否需要存储到磁盘上, 方便以后用来排序、聚合或脚本查询. 接受true和false(默认);
(2) store: 该字段的值是否要和_source分开存储、检索, 意思是除了_source中, 是否要单独再存储一份. 接受true或false(默认).
// 添加映射PUT website{ "mappings": { "blog": { "properties": { "blob": {"type": "binary"} // 二进制 } } }}// 添加数据PUT website/blog/1{ "title": "Some binary blog", "blob": "hED903KSrA084fRiD5JLgY=="}注意: Base64编码的二进制值不能嵌入换行符\n, 逗号(0x2c)等符号.
范围类型 - range
range过滤允许我们按照制定范围查找一批数据
复杂数据类型Array
ES中没有专门的数组类型, 直接使用[]定义即可;
数组中所有的值必须是同一种数据类型, 不支持混合数据类型的数组:
① 字符串数组: [“one”, “two”]; ② 整数数组: [1, 2]; ③ 由数组组成的数组: [1, [2, 3]], 等价于[1, 2, 3]; ④ 对象数组: [{“name”: “Tom”, “age”: 20}, {“name”: “Jerry”, “age”: 18}].
注意:
- 动态添加数据时, 数组中第一个值的类型决定整个数组的类型;
- 不支持混合数组类型, 比如[1, “abc”];
- 数组可以包含null值, 空数组[]会被当做missing field —— 没有值的字段.
复杂数据类型Object
JSON文档是分层的: 文档可以包含内部对象, 内部对象也可以包含内部对象.
复杂数据类型嵌套类型 - nested
嵌套类型是对象数据类型的一个特例, 可以让array类型的对象被独立索引和搜索.
专门数据类型IP类型
IP类型的字段用于存储IPv4或IPv6的地址, 本质上是一个长整型字段.
添加映射
PUT employee{ "mappings": { "customer": { "properties": { "ip_addr": { "type": "ip" } } } }}添加数据
PUT employee/customer/1{ "ip_addr": "192.168.1.1" }计数数据类型 - token_counttoken_count类型用于统计字符串中的单词数量.
添加映射
PUT employee{ "mappings": { "customer": { "properties": { "name": {"type": "text", "fields": { "length": {"type": "token_count", "analyzer": "standard" } } } } } }}添加数据:
PUT employee/customer/1{ "name": "John Snow" }PUT employee/customer/2{ "name": "Tyrion Lannister" }查询数据
GET employee/customer/_search{ "query": { "term": { "name.length": 2 } }}整合SpringBoot
整合前熟悉几个重要的对象与构造器
| SearchRequest | 查询请求对象 |
| SearchResponse | 查询响应对象 |
| SearchSourceBuilder | 查询源构建器 |
| MatchQueryBuilder | 匹配查询构建器 |
|
BoolQueryBuilder |
布尔查询构建器 |
|
TermQueryBuilder |
词条查想构建器 |
|
QueryBuilders |
查询构建器工厂 |
|
AggregationBuilders |
聚合构建器工厂 |
|
TremsAggregationBuilder |
词条聚合构造器 |
|
Aggregations |
分组结果封装 |
|
Terms.Bucket |
桶 |
Spring boot中主要有Java REST Client、spring-data-elasticsearch两种方式可以整合ES 本文使用spring-data-elasticsearch
org.springframework.boot spring-boot-starter-data-elasticsearch配置文件
@Configurationpublic class RestClientConfig extends AbstractElasticsearchConfiguration { @Override @Bean public RestHighLevelClient elasticsearchClient() { final ClientConfiguration clientConfiguration = ClientConfiguration.builder() .connectedTo("localhost:9200") .build(); return RestClients.create(clientConfiguration).rest(); }}创建索引 并 映射 & 删除索引
put /products #products索引名称{ "mappings": { "properties": { "title": { // 字段名称 "type": "keyword" // 类型 }, "price": { // 字段名称 "type": "double" // 类型 }, "created_time": { // 字段名称 "type": "date" // 类型 }, "description": { // 字段名称 "type": "text", // 类型 "analyzer": "ik_max_word" // 开启分词器 } } }}#删除索引DELETE /productsBoot
@Resourceprivate RestHighLevelClient restHighLevelClient;/ * 创建索引 创建映射 */@Testvoid indexAndMapping() throws IOException { CreateIndexRequest createIndexRequest = new CreateIndexRequest("products"); createIndexRequest.mapping("{\n" + " \"properties\": {\n" + " \"title\":{\n" + " \"type\": \"keyword\"\n" + " },\n" + " \"price\":{\n" + " \"type\": \"double\"\n" + " },\n" + " \"created_time\":{\n" + " \"type\": \"date\"\n" + " },\n" + " \"description\":{\n" + " \"type\": \"text\",\n" + " \"analyzer\":\"ik_max_word\"\n" + " }\n" + " }\n" + " }", XContentType.JSON);//指定映射参数1:指定映射json结构 参数2:指定数据类型 CreateIndexResponse createIndexResponse = restHighLevelClient.indices().create(createIndexRequest, RequestOptions.DEFAULT); System.out.println("创建状态: "+createIndexResponse.isAcknowledged()); restHighLevelClient.close();//关闭资源}/ * 删除索引 */@Testpublic void testDeleteIndex() throws IOException { //参数 1: 删除索引对象 参数 2:请求配置对象 AcknowledgedResponse acknowledgedResponse = restHighLevelClient.indices().delete(new DeleteIndexRequest("products"), RequestOptions.DEFAULT); System.out.println(acknowledgedResponse.isAcknowledged());}添加 & 修改 数据
/ * @author 小影 * @create 2022-05-09 9:51 * @describe:商品 */@Datapublic class Product { private Integer id; // 标题 private String title; // 价格 private Double price; // 创建时间 private LocalDateTime createTime; // 描述 private String description;}/ * 添加数据(文档) * @throws IOException */@Testvoid testCreate() throws IOException { // param:索引名称 IndexRequest indexRequest = new IndexRequest("products"); // 要存储数据 Product product = new Product(); product.setId(1); product.setTitle("蜜汁小汉堡"); product.setCreateTime(LocalDateTime.now()); product.setPrice(3.0); product.setDescription("老八秘制小汉堡,好吃又管饱"); indexRequest.id(product.getId().toString());// 存储ID,不设置默认随机字符串 indexRequest.source(JSONUtil.toJsonStr(product), XContentType.JSON);//指定文档数据 //参数 1: 索引请求对象 参数 2:请求配置对象 IndexResponse indexResponse = restHighLevelClient.index(indexRequest, RequestOptions.DEFAULT); System.out.println(indexResponse.status());// CREATED:成功}修改和添加是一样的,传入的参数中的ID在es中存在即为修改,不同的是修改成功indexResponse.status()返回的 是OK,如果是添加返回的是CREATE

删除数据
/ * 删除数据(文档) */@Testpublic void testDelete() throws IOException { //参数 1: 删除请求对象 参数 2: 请求配置对象 DeleteRequest deleteRequest = new DeleteRequest("products", "5W25poAB9vN9HF984Etg"); DeleteResponse deleteResponse = restHighLevelClient.delete(deleteRequest, RequestOptions.DEFAULT); System.out.println(deleteResponse.status());// 成功返回OK}根据ID查询数据
/ * 基于id 查询数据(文档) */@Testpublic void testQueryById() throws IOException { GetRequest getRequest = new GetRequest("products", "1"); //参数 1: 查询请求对象 参数 2:请求配置对象 返回值: 查询响应对象 GetResponse getResponse = restHighLevelClient.get(getRequest, RequestOptions.DEFAULT); System.out.println("id: "+getResponse.getId()); System.out.println("source: "+getResponse.getSourceAsString());}
查询所有数据
/ * 查询所有数据(文档) * 查询所有matchAllQuery */@Testpublic void testMatchAll() throws IOException { SearchRequest searchRequest = new SearchRequest("products"); //指定搜索索引 SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();//指定条件对象 sourceBuilder.query(QueryBuilders.matchAllQuery());//查询所有 searchRequest.source(sourceBuilder);//指定查询条件 SearchResponse searchResponse = restHighLevelClient.search(searchRequest,RequestOptions.DEFAULT);//参数 1:搜索请求对象 参数2: 请求配置对象 返回值:查询结果对象 System.out.println("总条数: " + searchResponse.getHits().getTotalHits().value); System.out.println("最大得分: " + searchResponse.getHits().getMaxScore()); //获取结果 SearchHit[] hits = searchResponse.getHits().getHits(); for (SearchHit hit : hits) { String id = hit.getId(); System.out.println("id: "+ id +" source: "+hit.getSourceAsString()); }} 
不同条件查询(关键字、范围、前缀、通配符、多个ID、多个字段)
注意:es只能匹配单字符 不能搜索词语的问题 ES默认分词规则不能支持中文,通过安装IK Analysis for Elasticsearch支持中文分词。
分词器下载地址,切记要与es版本一致:Releases · medcl/elasticsearch-analysis-ik · GitHub
/ * 不同条件查询 term(关键词查询) */@Testpublic void testQuery() throws IOException { //1.term 关键词 只能匹配单字符 不能搜索词语的问题 ES默认分词规则不能支持中文,通过安装IK Analysis for Elasticsearch支持中文分词。 //query(QueryBuilders.termQuery("description","小汉堡")); //2.range 范围 价格在0-6之间的数据 //query(QueryBuilders.rangeQuery("price").gt(0).lte(6)); //3.prefix 前缀 //query(QueryBuilders.prefixQuery("title","s蜜汁")); //4.wildcard 通配符查询 ? 一个字符 * 任意多个字符 //query(QueryBuilders.wildcardQuery("title","*小汉堡*")); //5.ids 多个指定 id 查询 //query(QueryBuilders.idsQuery().addIds("1").addIds("2")); //6.multi_match 多字段查询 query(QueryBuilders.multiMatchQuery("豆腐","title","description"));}public void query(QueryBuilder queryBuilder) throws IOException { SearchRequest searchRequest = new SearchRequest("products");//指定搜索索引 SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();//指定条件对象 sourceBuilder.query(queryBuilder);//指定查询条件 searchRequest.source(sourceBuilder); SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);//参数 1:搜索请求对象 参数2: 请求配置对象 返回值:查询结果对象 System.out.println("符合条件总数: "+searchResponse.getHits().getTotalHits().value); System.out.println("获取文档最大分数: "+searchResponse.getHits().getMaxScore()); SearchHit[] hits = searchResponse.getHits().getHits(); for (SearchHit hit : hits) { System.out.println("id: "+hit.getId()+" source: "+hit.getSourceAsString()); }}分页、排序、指定返回字段、高亮结果
/ * 查询所有 * 分页查询 form 起始位置默认0开始 size 每页展示记录数 * 排序 sort * 返回指定的字段 fetchSource 用来指定查询文档返回那些字段 * 高亮结果 highlighter */@Testpublic void testSearch() throws IOException { SearchRequest searchRequest = new SearchRequest("products"); SearchSourceBuilder sourceBuilder = new SearchSourceBuilder(); //创建高亮器 HighlightBuilder highlightBuilder = new HighlightBuilder(); highlightBuilder.requireFieldMatch(false).field("description").field("title").preTags("").postTags(""); sourceBuilder.query(QueryBuilders.termQuery("description","简简单单")) .from(0) //起始位置 start = (page-1)*size .size(10)//每页显示条数 默认返回 10条 .sort("price", SortOrder.ASC)//指定排序字段 参数 1: 根据哪个字段排序 参数 2:排序方式 [asc,desc] .fetchSource(new String[]{},new String[]{"create_time"})//参数 1: 包含字段数组 参数 2:排除字段数组 .highlighter(highlightBuilder);//高亮搜索结果 searchRequest.source(sourceBuilder); SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT); System.out.println("符合条件总数: "+searchResponse.getHits().getTotalHits().value); System.out.println("获取文档最大分数: "+searchResponse.getHits().getMaxScore()); SearchHit[] hits = searchResponse.getHits().getHits(); for (SearchHit hit : hits) { System.out.println("id: "+hit.getId()+" source: "+hit.getSourceAsString()); //获取高亮字段 Map highlightFields = hit.getHighlightFields(); if (highlightFields.containsKey("description")){ System.out.println("description高亮结果: "+highlightFields.get("description").fragments()[0]); } if (highlightFields.containsKey("title")){ System.out.println("title高亮结果: "+highlightFields.get("title").fragments()[0]); } }}过滤查询
过滤查询,其实准确来说,ES中的查询操作分为2种: 查询(query)和过滤(filter)。查询即是之前提到的query查询,它 (查询)默认会计算每个返回文档的得分,然后根据得分排序。而过滤(filter)只会筛选出符合的文档,并不计算 得分,而且它可以缓存文档 。所以,单从性能考虑,过滤比查询更快。 换句话说过滤适合在大范围筛选数据,而查询则适合精确匹配数据。一般应用时, 应先使用过滤操作过滤数据, 然后使用查询匹配数据。
/ * query : 查询精确查询 查询计算文档得分 并根据文档得分进行返回 * filter query : 过滤查询 用来在大量数据中筛选出本地查询相关数据 不会计算文档得分 经常使用 filter query 结果进行缓存 * 注意: 一旦使用 query 和 filterQuery es 优先执行 filter Query 然后再执行 query 所以使用filter query 查询会比较快 */@Testpublic void testFilterQuery() throws IOException { SearchRequest searchRequest = new SearchRequest("products"); SearchSourceBuilder sourceBuilder = new SearchSourceBuilder(); sourceBuilder .query(QueryBuilders.termQuery("description","老八")) .postFilter(QueryBuilders.idsQuery().addIds("1").addIds("2").addIds("3"));//用来指定过滤条件 searchRequest.source(sourceBuilder); SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT); System.out.println("符合条件总数: "+searchResponse.getHits().getTotalHits().value); System.out.println("获取文档最大分数: "+searchResponse.getHits().getMaxScore()); SearchHit[] hits = searchResponse.getHits().getHits(); for (SearchHit hit : hits) { System.out.println("id: "+hit.getId()+" source: "+hit.getSourceAsString()); }}聚合查询 max(ParsedMax)、 min(ParsedMin) 、sum(ParsedSum)、 avg(ParsedAvg)
es语法:
先根据某个字段分组 此案例中根据价格分组
GET /products/_search{ "query": { "term": { "title": { "value": "老八米饭" } } }, "aggs": { "price_gooup": { "terms": { "field": "price" } } }}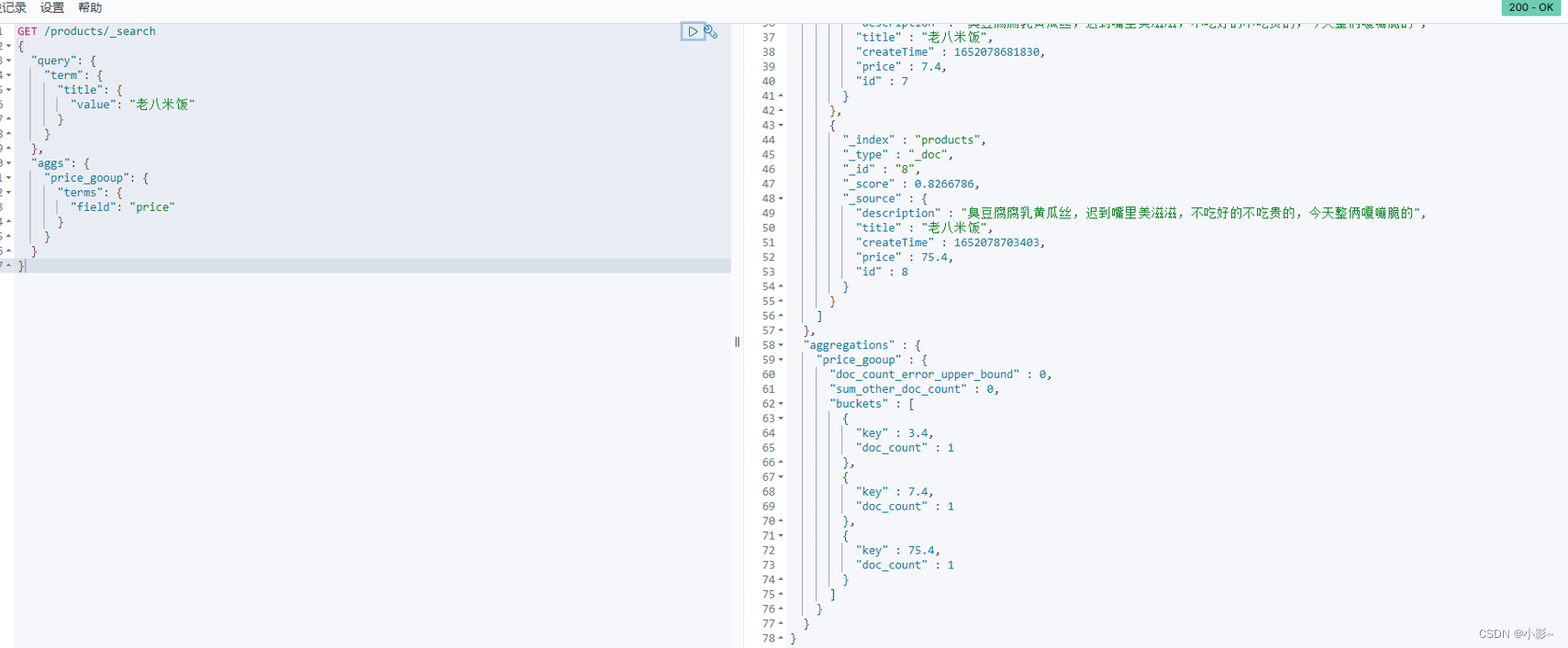
之后就可以操作
求最大值
GET /products/_search{ "aggs": { "price_max": { "max": { "field": "price" } } }}求最小值
GET /products/_search{ "aggs": { "price_min": { "min": { "field": "price" } } }}求平均值
GET /products/_search{ "aggs": { "price_avg": { "avg": { "field": "price" } } }}....
/ * max(ParsedMax) min(ParsedMin) sum(ParsedSum) avg(ParsedAvg) 聚合函数 桶中只有一个返回值 */@Testpublic void testAggsFunction() throws IOException { SearchRequest searchRequest = new SearchRequest("products"); SearchSourceBuilder sourceBuilder = new SearchSourceBuilder(); sourceBuilder .query(QueryBuilders.matchAllQuery()) //查询条件 //.aggregation(AggregationBuilders.sum("price_sum").field("price"))//用来设置聚合处理 sum //.aggregation(AggregationBuilders.avg("price_avg").field("price")) //用来设置聚合处理 avg .aggregation(AggregationBuilders.max("price_min").field("price")) //max .size(0);//默认查询所有进行聚合 searchRequest.source(sourceBuilder); SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT); Aggregations aggregations = searchResponse.getAggregations(); ParsedMax parsedMax = aggregations.get("price_min"); System.out.println(parsedMax.getValue());}nested嵌套对象 关联查询
需求:通过传递一系列评论来存储博客文章及其所有评论。数据结构如下:
{ "title": "牛人集结地", "body": "随便评论", "comments": [ { "name": "张三", "age": 33, "rating": 6, "comment": "找我牛逼", "commented_on": "22 Nov 2022" }, { "name": "老八", "age": 33, "rating": 9, "comment": "吃俩柠檬整点蒜,简简单单一顿饭,美食界里我老八,今天给你们吃沙拉", "commented_on": "25 Nov 2022" }, { "name": "吕小布", "age": 35, "rating": 6, "comment": "踏遍青楼人未老,请用汇仁肾宝", "commented_on": "21 Nov 2022" } ]}#创建索引PUT /blog_new{ "mappings": { "properties":{ "title":{ "type":"text" }, "body":{ "type":"text" }, "comments":{ "type":"nested", "properties": { "name": {"type": "text" }, "comment": {"type": "text" }, "age": {"type": "short" }, "rating": {"type": "short" }, "commented_on": {"type": "text" } } } } }}/ * 添加关联信息 */@Testpublic void addParent() throws IOException { IndexRequest indexRequest = new IndexRequest("blog_new"); String id = UUID.randomUUID().toString(); Blog blog = new Blog(); blog.setBody("随便评论"); blog.setTitle("牛人集结地"); List list = new ArrayList(); Comments comments1 = new Comments(); comments1.setName("张三"); comments1.setAge(33); comments1.setRating(6); comments1.setComment("找我牛逼"); comments1.setCommented_on("22 Nov 2022"); Comments comments2 = new Comments(); comments2.setName("老八"); comments2.setAge(33); comments2.setRating(9); comments2.setComment("吃俩柠檬整点蒜,简简单单一顿饭,美食界里我老八,今天给你们吃沙拉"); comments2.setCommented_on("25 Nov 2022"); Comments comments3 = new Comments(); comments3.setName("吕小布"); comments3.setAge(35); comments3.setRating(6); comments3.setComment("踏遍青楼人未老,请用汇仁肾宝"); comments3.setCommented_on("21 Nov 2022"); list.add(comments1); list.add(comments2); list.add(comments3); blog.setComments(list); String source = JSON.toJSONString(blog); System.out.println("source = " + source); indexRequest.id("W_DKq4ABHdN8KsLXQ2ZR"); indexRequest.source(source, XContentType.JSON); IndexResponse indexResponse = restHighLevelClient.index(indexRequest, RequestOptions.DEFAULT); System.out.println(indexResponse.status());} 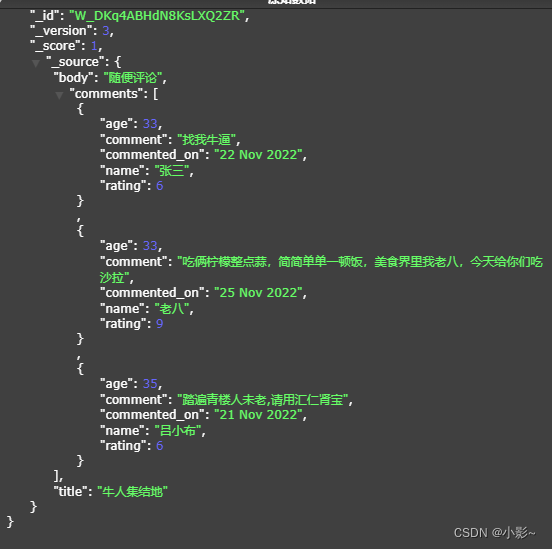
查询:
@Testpublic void testGet() throws IOException { SearchRequest request = new SearchRequest("blog_new"); // 初始化需要查询的索引 //查询student 字段下的hobby字段下的name字段的值 等于篮球的学生,这里特别注意第一层必须是你查询的字段的前一层字段 // 查询条件1 comment存在老八 QueryBuilder one = QueryBuilders.nestedQuery("comments", QueryBuilders.boolQuery() .must(QueryBuilders.matchQuery("comments.comment", "老八")), ScoreMode.Total); // 并且年龄在33 QueryBuilder two = QueryBuilders.nestedQuery("comments", QueryBuilders.boolQuery() .must(QueryBuilders.matchQuery("comments.age", "33")), ScoreMode.Total); BoolQueryBuilder queryBuilder = QueryBuilders.boolQuery(); // 初始化 最后组合成的条件 queryBuilder.must(one); queryBuilder.must(two); //初始化条件builer SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder(); //加入组合成的条件到builder searchSourceBuilder.query(queryBuilder); //设置查询的分页 第一个从0开始 searchSourceBuilder.from(0); //每页的大小为2 searchSourceBuilder.size(2); //初始化索引中加入 builder request.source(searchSourceBuilder); try { SearchResponse searchResponse = restHighLevelClient.search(request, RequestOptions.DEFAULT); SearchHit[] hits = searchResponse.getHits().getHits(); //这里把数据转成实体 List res = new ArrayList(); for (SearchHit hit : hits) { res.add(JSON.parseObject(hit.getSourceAsString(), Blog.class)); } System.out.println(JSON.toJSONString(res)); } catch (Exception e) { e.printStackTrace(); }}缺点:更新某个内容只能把这条数据,都替换,删除某个子对象也是
自己根据案例改的工具类
/ * @author 小影 * @create 2022-05-09 14:54 * @describe:ElasticSearch工具类 */@Componentpublic class EsUtil { private static final Logger logger = LoggerFactory.getLogger(EsUtil.class); @Resource private RestHighLevelClient restHighLevelClient; / * 判断一个索引是否存在 * * @param indexName * @return */ public boolean isExistsIndex(String indexName) { GetIndexRequest request = new GetIndexRequest(); try { boolean exists = restHighLevelClient.indices().exists(request.indices(indexName), RequestOptions.DEFAULT); return exists; } catch (IOException e) { e.printStackTrace(); } return false; } / * 删除索引 * * @param indexName 索引名称 * @return * @throws IOException */ public boolean DeleteIndex(String indexName) { //参数 1: 删除索引对象 参数 2:请求配置对象 AcknowledgedResponse acknowledgedResponse = null; try { acknowledgedResponse = restHighLevelClient.indices().delete(new DeleteIndexRequest(indexName), RequestOptions.DEFAULT); } catch (IOException e) { e.printStackTrace(); } return acknowledgedResponse.isAcknowledged() == true ? true : false; } / * 添加数据 & 修改数据 * * @param indexName 索引名称 * @param id 数据id * @param dataJson 要存储的数据JSON格式 * @return ID在es库中不存在即为添加, 存在修改 */ public boolean createData(String indexName, String id, String dataJson) { try { // param:索引名称 IndexRequest indexRequest = new IndexRequest(indexName); indexRequest.id(id);// 存储ID,不设置默认随机字符串 indexRequest.source(dataJson, XContentType.JSON);//指定文档数据 //参数 1: 索引请求对象 参数 2:请求配置对象 IndexResponse indexResponse = restHighLevelClient.index(indexRequest, RequestOptions.DEFAULT); System.err.println(indexResponse); System.out.println(indexResponse.status()); if (indexResponse.status() == RestStatus.CREATED || indexResponse.status() == RestStatus.OK) { return true; } } catch (IOException e) { e.printStackTrace(); } return false; } / * 根据ID删除数据 * * @param indexName 索引名称 * @param id ID * @return */ public boolean deleteDataById(String indexName, String id) { DeleteResponse deleteResponse = null; try { DeleteRequest deleteRequest = new DeleteRequest(indexName, id); deleteResponse = restHighLevelClient.delete(deleteRequest, RequestOptions.DEFAULT); } catch (IOException e) { e.printStackTrace(); } return deleteResponse.status() == RestStatus.OK; } / * 根据ID查询数据(文档) * * @param indexName * @param id * @return */ public String queryById(String indexName, String id) { try { GetRequest getRequest = new GetRequest(indexName, id); //参数 1: 查询请求对象 参数 2:请求配置对象 返回值: 查询响应对象 GetResponse getResponse = restHighLevelClient.get(getRequest, RequestOptions.DEFAULT); return getResponse.getSourceAsString(); } catch (IOException e) { e.printStackTrace(); } return null; } / * 查询所有:查询、分页 * * @param indexName 索引名称 * @param pageNo 页码 * @param pageSize 页大小 * @return */ public SearchHit[] queryAll(String indexName, Integer pageNo, Integer pageSize) { SearchResponse searchResponse = null;//参数 1:搜索请求对象 参数2: 请求配置对象 返回值:查询结果对象 try { SearchRequest searchRequest = new SearchRequest(indexName); //指定搜索索引 SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();//指定条件对象 sourceBuilder.query(QueryBuilders.matchAllQuery())//查询所有 .from((pageNo - 1) * pageSize) .size(pageSize); searchRequest.source(sourceBuilder);//指定查询条件 searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT); } catch (IOException e) { e.printStackTrace(); } return searchResponse.getHits().getHits(); } / * 调用通用查询借鉴 * * @throws IOException */ public void testQuery() throws IOException { //1.term 关键词 只能匹配单字符 不能搜索词语的问题 ES默认分词规则不能支持中文,通过安装IK Analysis for Elasticsearch支持中文分词。 //query(QueryBuilders.termQuery("description","小汉堡")); //2.range 范围 价格在0-6之间的数据 //query(QueryBuilders.rangeQuery("price").gt(0).lte(6)); //3.prefix 前缀 //query(QueryBuilders.prefixQuery("title","s蜜汁")); //4.wildcard 通配符查询 ? 一个字符 * 任意多个字符 //query(QueryBuilders.wildcardQuery("title","*小汉堡*")); //5.ids 多个指定 id 查询 //query(QueryBuilders.idsQuery().addIds("1").addIds("2")); //6.multi_match 多字段查询 query(QueryBuilders.multiMatchQuery("豆腐", "title", "description")); } / * 通用查询 * * @param queryBuilder * @throws IOException */ public SearchHit[] query(QueryBuilder queryBuilder) throws IOException { SearchRequest searchRequest = new SearchRequest("products");//指定搜索索引 SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();//指定条件对象 sourceBuilder.query(queryBuilder);//指定查询条件 searchRequest.source(sourceBuilder); SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);//参数 1:搜索请求对象 参数2: 请求配置对象 返回值:查询结果对象 SearchHit[] hits = searchResponse.getHits().getHits(); return hits; }}这是小编在开发学习使用和总结, 这中间或许也存在着不足,希望可以得到大家的理解和建议。如有侵权联系小编!

