冰冰学习笔记:一步一步带你实现《双向带头循环链表》
欢迎各位大佬光临本文章!!!
还请各位大佬提出宝贵的意见,如发现文章错误请联系冰冰,冰冰一定会虚心接受,及时改正。
本系列文章为冰冰学习编程的学习笔记,如果对您也有帮助,还请各位大佬、帅哥、美女点点支持,您的每一分关心都是我坚持的动力。
我的博客地址:bingbing~bang的博客_CSDN博客
https://blog.csdn.net/bingbing_bang?type=blog
我的gitee:冰冰棒 (bingbingsupercool) - Gitee.com

系列文章推荐
冰冰学习笔记:一步一步带你实现《顺序表》
冰冰学习笔记:一步一步带你实现《单链表》
目录
系列文章推荐
前言
一、双向带头循环链表结构分析
1.1什么是双向带头循环链表
1.2双向带头循环链表的优势
二、双向带头循环链表的实现
2.1链表初始化函数
2.2链表任意位置之前插入函数
2.3链表打印函数
2.4链表任意位置删除函数
2.5链表尾插、尾删
2.6链表头插、头删
2.7链表查找与修改
2.8链表元素个数计算
2.9链表销毁
总结
前言
在前面的文章中我们实现了《顺序表》、《单链表》这些存储数据的结构,但是,这两种结构并非完美结构,更多的是作为基础学习,或者作为OJ题目的结构。那真正完美的数据存储结构是什么样的呢?今天我们就来讲解一下完美的链表结构:《双向带头循环链表》。为什么说它完美呢?因为该链表结构存储数据,删除数据,修改数据,查找数据的功能实现的复杂度均为O(1),最省时,并且操起来最简单。下面我们一步一步的实现该链表。
一、双向带头循环链表结构分析
1.1什么是双向带头循环链表
双向带头循环链表是结构最复杂,但是实现最简单的链表。该链表结构中包含两个指针,一个指针指向链表的下一个结点,一个指针指向链表的上一个结点。并且该链表存在一个头指针,这个指针不存储有效数据,仅作为链表的标头,用来连接其他的结点。头结点在函数初始化的时候创建,在链表程序结束的时候销毁,各种删除操作均不会改变头结点。并且该链表结构中不会存在NULL指针,头结点的prev连接尾结点,尾结点的next连接头结点。双向带头循环链表如下图所示。
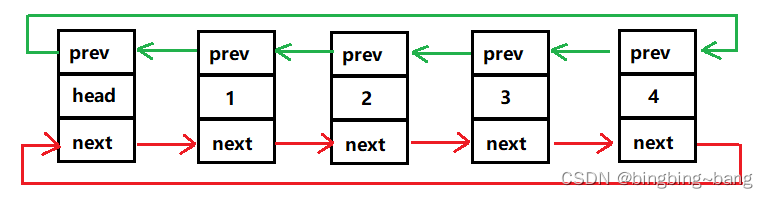
1.2双向带头循环链表的优势
双向带头循环链表最大的优势就是操作简单,无论是进行尾插还是头插,利用头指针head中的prev和next都可以快速找到。尾删头删都不用遍历去寻找结点,直接利用头结点就可以找到。虽然结构复杂,但是功能实现很容易,利用prev可以很容易的找到每个结点的前一个结点,增删查改仅仅对当前的结点操作就可以访问相邻的结点,进行连接删除操作。而单向链表的尾插尾增都需要遍历链表,复杂度相对较高。
二、双向带头循环链表的实现
现在我们开始一步一步实现链表的各种功能,在这之前我们先创建链表的结构。由于链表为双向的,所以我们在创建结构的时候需要开辟两个结构体指针,一个用来保存前面的结点,一个用来保存下一个结点。因此结构如下所示:

2.1链表初始化函数
以前我们在创建单链表的时候需要将初始化的链表更改为传过来的指针,因此我们通常使用的是二级指针,用以更改结构体指针本身。但是,双向带头循环链表由于具有头指针,头插,头增都不在需要改变链表的头,仅需要将结点插入到头结点head的后面即可,所以我们不在需要二级指针了。我们初始化的时候直接返回链表头结点的地址。
由于头插、尾插等函数开辟结点的方式是一样的,我们封装成一个函数,方便统一调用。开辟的新节点的两个指针都置空,具体连接放在具体函数调用中进行。
函数代码:
ListNode* BuyListNode(LTDataType x){ListNode* newnode = (ListNode*)malloc(sizeof(ListNode));if ( newnode == NULL ){perror("BuyListNode::malloc");exit(-1);}newnode->next = NULL;newnode->prev = NULL;newnode->Data = x;return newnode;}初始化函数的功能就是创建链表的头结点,头结点不存储有效数据,其内部的指针应该指向自己。此处初始化时将头结点的数据初始化为-1。
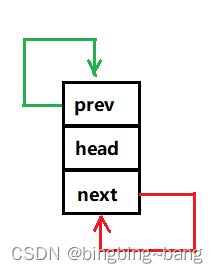
具体代码:
ListNode* ListInit(){ListNode* head = BuyListNode(-1);head->next = head;head->prev = head;return head;}2.2链表任意位置之前插入函数
现在我们搭建插入数据函数,我们先写任意位置之前插入函数,这样在写头插尾插的时候可以直接复用,就不用单独编写,减少工作量。
任意位置之前的插入函数需要接收两个参数,指向链表任意位置的pos指针,以及插入数据x。如下图所示,我们要在数据 2 之前插入一个数据 5 ,pos指向的就是数据 2 存储的结点。我们只需要将pos之前的结点保存在posprev中,然后开辟一个新节点newnode,将数据5放入Data中,再将newnode的next连接到pos,pos的prev连接到newnode,newnode与pos之前的结点posprev在进行连接。具体连接过程如下图所示:
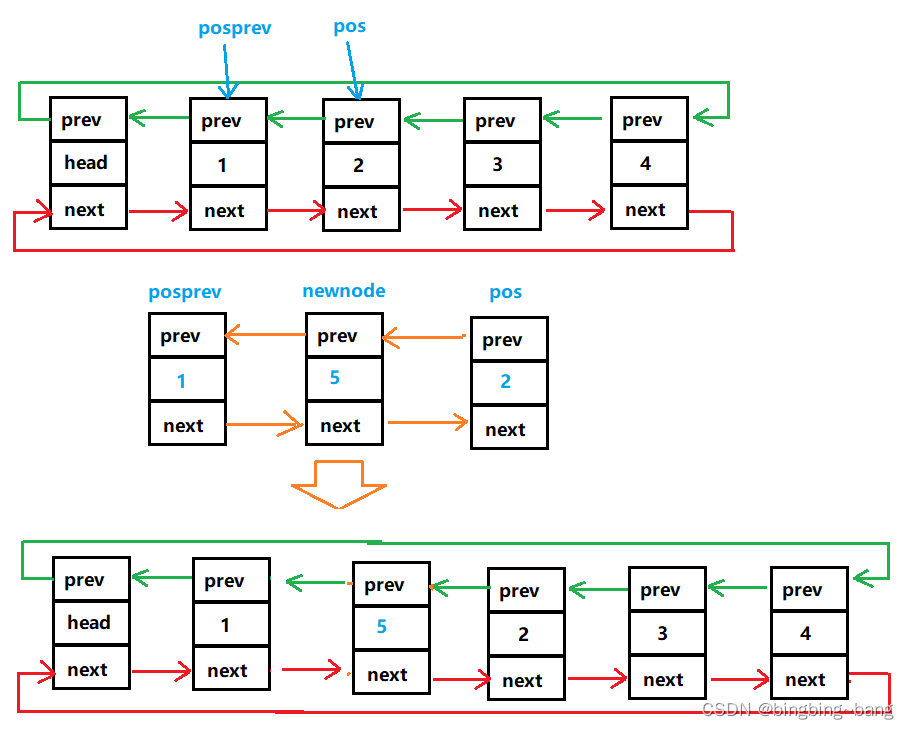
那如果链表只有head头结点呢,能否进行插入呢?答案是肯定呢,如果链表只有一个结点,即pos指向的就是head,那在pos之前插入就相当于尾插。代码不需要改变直接就可以插入。
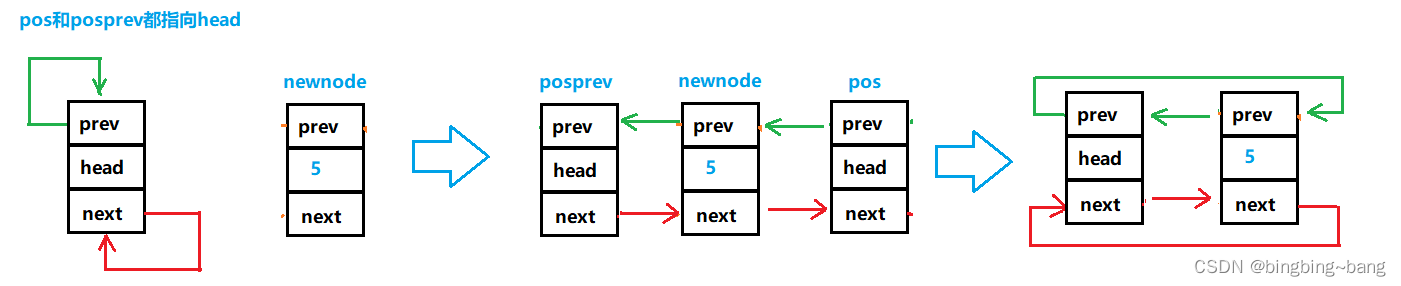
2.3链表打印函数
链表的打印函数要格外注意,由于双向带头循环链表中不包含NULL 指针,因此我们遍历链表的时候不能将cur指针指向NULL为结束标志。既然链表是循环的,并且头结点是不需要打印数据的,所以我们可以将cur指向头结点的下一个结点作为遍历起点,当再次回到head时,说明遍历结束,打印停止。

代码实现:
void ListPrint(ListNode* phead){assert(phead);ListNode* cur = phead->next;while ( cur != phead ){printf("%d ", cur->Data);cur = cur->next;}printf("\n");}2.4链表任意位置删除函数
链表任意位置的删除函数需要事先接收一个pos指针,然后进入链表将pos处的指针进行释放,然后将其前面和后面的指针连接即可。
但是我们要注意一点,需要判断链表是否只有头结点,如果只有头结点的情况下再将其删除,后面的链表操作必然会引起错误,因此我们需要添加断言判断。
因此,具体的删除步骤是:函数接收pos指针,代表删除的位置。然后判断是否为空指针或者是否链表仅含有头结点,在两种情况都不满足的时候开始删除结点。先通过pos的前趋指针找到pos之前的结点将其保存到posprev指针中,然后通过后趋指针找到pos后面的结点保存到posnext中,连接posprev和posnext,最后释放pos结点。

实现代码:
void ListErase(ListNode* pos){assert(pos);assert(pos->next != pos);ListNode* posprev = pos->prev;ListNode* posnext = pos->next;posprev->next = pos->next;posnext->prev = posprev;free(pos);}2.5链表尾插、尾删
链表的尾插尾删函数内部都可以直接使用任意位置的插入以及pos之前删除的函数,当然我们也可以自己写。那我们就得通过链表找到尾部才能操作。
有的人就说了,我们直接遍历不就可以吗,遍历的方法适合单链表来找尾部,带头双向循环链表是不能遍历的,一是链表为循环结构,内部没有空指针,无法确定尾部;二是链表遍历找尾部,时间复杂度再次变为O(N),不适合。
既然链表结构为带头双向循环,我们完全可以通过头结点的前趋指针找到尾部,因为是循环结构,链表内部必然首尾相接。那就简单了,尾增只需要将新结点连接即可,尾删则直接释放尾结点,并且将尾结点前面的结点与头结点再次连接即可。
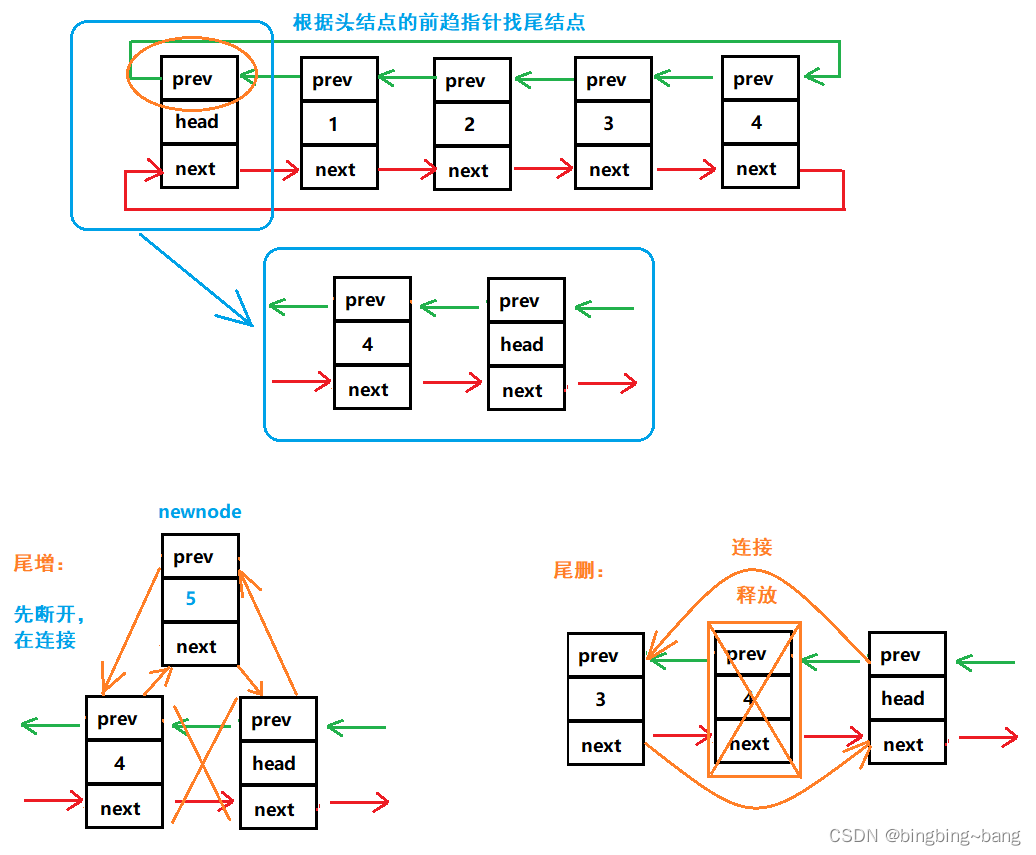
尾增尾删代码实现:
注意:复用pos之前插入的时候,传过去的是head,因为尾部就是在head的前面;复用任意位置删除的时候,传过去的是head->prev。
//尾插函数void ListPushBack(ListNode* phead, LTDataType x){assert(phead);ListNode* newnode = BuyListNode(x);ListNode* tail = phead->prev;tail->next = newnode;newnode->prev = tail;newnode->next = phead;phead->prev = newnode;//复用pos之前插入//ListInsert(phead, x);}//尾删函数void ListPopBack(ListNode* phead){assert(phead);assert(phead->next != phead);ListNode* tail = phead->prev;ListNode* tailprev = tail->prev;tailprev->next = phead;phead->prev = tailprev;free(tail);//复用任意位置删除//ListErase(phead->prev);}2.6链表头插、头删
头插,头删函数的实现类似与尾插,head->next指向的就是以一个元素的位置,我们只需要将newnode连接在head后面就完成了头插。将head的后面的结点释放,在连接就完成了头删。函数复用也和尾插尾删类似,head->next之前插入就是头插,删除head->next的位置就是头删。
头插头删代码实现:
//头插函数void ListPushFront(ListNode* phead, LTDataType x){assert(phead);ListNode* newnode = BuyListNode(x);ListNode* headnext = phead->next;phead->next = newnode;newnode->prev = phead;newnode->next = headnext;headnext->prev = newnode;//复用pos之前插入//ListInsert(phead->next,x);}//头删函数void ListPopFront(ListNode* phead){assert(phead);assert(phead->next != phead);ListNode* headnext = phead->next->next;ListNode* head = phead->next;phead->next = headnext;headnext->prev = phead;free(head);//复用任意位置删除//ListErase(phead->next);}2.7链表查找与修改
与单链表实现方式类似,遍历链表找寻每个结点Data的数值是否等于x,等于就返回此节点的地址,找不到就返回NULL,只不过循环停下的方式与打印函数一样,判断的是是否回到头结点。
修改函数也不用单独编写,利用查找返回的结点地址直接修改就行。
代码实现:
ListNode* ListFind(ListNode* phead, LTDataType x){assert(phead);ListNode* cur = phead->next;while ( cur != phead ){if ( cur->Data == x ){return cur;}else{cur = cur->next;}}return NULL;}2.8链表元素个数计算
链表元素个数计算的函数实现方式比较简单,直接遍历链表进行计数即可。但是我们要减少调用次数,因为按照此方法计算,每次都要遍历链表,时间复杂度每次都是O(N)。
当然我们也有很好的方式,就是在开始搭建的时候创建新的结构体,里面包含链表结构,也包含链表长度size,每次调用函数的时候做出相应的改变,具体变更代码我将放入我的仓库中,可自行下载观看。
代码实现:
int ListSize(ListNode* phead){assert(phead);ListNode* cur = phead->next;int size = 0;while ( cur != phead ){size++;cur = cur->next;}return size;}2.9链表销毁
链表销毁函数就是在推出链表时调用该函数,将里面的结点全部释放,然后再将头结点释放,我们可以调用任意结点删除函数进行释放,最后释放掉头结点head。具体实现方式:使用cur遍历链表,使用tmp保存cur->next,然后将cur指向的结点释放,再将cur变更为tmp。退出循环后释放掉头结点。
void ListDestory(ListNode* phead){ListNode* cur = phead->next;while ( cur != phead ){ListNode* tmp = cur->next;ListErase(cur);cur = tmp;}free(phead);}总结
本文所介绍的是链表结构中最完美的形式,具有相当多的优点,但是顺序表之所以没有被链表完全替代,是因为二者各有应用的领域。在存储空间上,顺序表的物理空间连续性是链表不能替代的,因此顺序表支持随机访问,并且cpu的缓存利用率高。但是在数据存储删除等反面,链表的优势便展露无遗,每种方式都是O(1)的算法复杂度,极大的节省了运行时间,并且按需申请释放,不会造成空间浪费。
最后附上链表代码仓库链接:
更改部分代码,增加部分代码 · 1fe7b87 · 冰冰棒/数据结构仓库 - Gitee.com![]() https://gitee.com/bingbingsurercool/data-structure-warehouse/commit/1fe7b872a47ece09d7208d65ba3ce202dbdf8f81带头双向循环链表新版本 · 63c2466 · 冰冰棒/数据结构仓库 - Gitee.com
https://gitee.com/bingbingsurercool/data-structure-warehouse/commit/1fe7b872a47ece09d7208d65ba3ce202dbdf8f81带头双向循环链表新版本 · 63c2466 · 冰冰棒/数据结构仓库 - Gitee.com![]() https://gitee.com/bingbingsurercool/data-structure-warehouse/commit/63c24661b4261cde698f714bba2af9da88d1eb85
https://gitee.com/bingbingsurercool/data-structure-warehouse/commit/63c24661b4261cde698f714bba2af9da88d1eb85

