【LeetCode-SQL专项突破】-第3天:字符串处理函数/正则
📢📢📢📣📣📣
哈喽!大家好,我是【IT邦德】,江湖人称jeames007,10年DBA工作经验
一位上进心十足的【大数据领域博主】!😜😜😜
中国DBA联盟(ACDU)成员,目前从事DBA及程序编程
擅长主流数据Oracle、MySQL、PG 运维开发,备份恢复,安装迁移,性能优化、故障应急处理等。
✨ 如果有对【数据库】感兴趣的【小可爱】,欢迎关注【IT邦德】💞💞💞
❤️❤️❤️感谢各位大可爱小可爱!❤️❤️❤️
文章目录
- 前言
-
- 1667. 修复表中的名字
- 1484. 按日期分组销售产品
- 1527. 患某种疾病的患者
前言
SQL每个人都要用,但是用来衡量产出的并不是SQL本身,你需要用这个工具,去创造其它的价值。
1667. 修复表中的名字
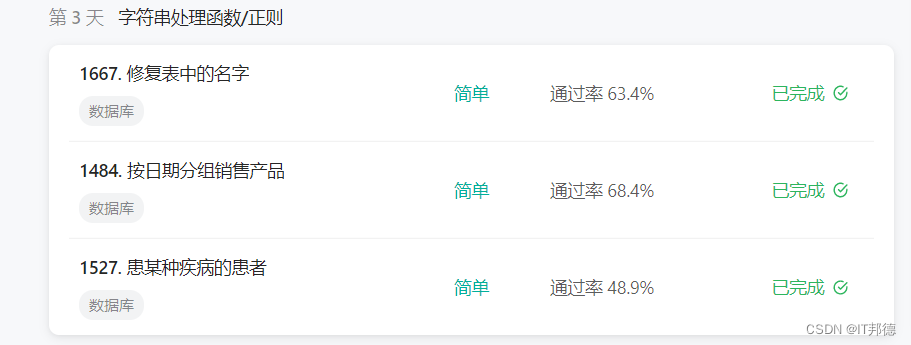
🚀 表: Users+----------------+---------+| Column Name | Type |+----------------+---------+| user_id | int || name | varchar |+----------------+---------+user_id 是该表的主键。该表包含用户的 ID 和名字。名字仅由小写和大写字符组成。🚀 需求编写一个 SQL 查询来修复名字,使得只有第一个字符是大写的,其余都是小写的。返回按 user_id 排序的结果表。查询结果格式示例如下。示例 1:输入:Users table:+---------+-------+| user_id | name |+---------+-------+| 1| aLice || 2| bOB |+---------+-------+输出:+---------+-------+| user_id | name |+---------+-------+| 1| Alice || 2| Bob |+---------+-------+🐴🐴 答案# Write your MySQL query statement belowselect user_id,concat(upper(left(name,1)),lower(substr(name,2))) namefrom Usersorder by user_id/* Write your T-SQL query statement below */select user_id,UPPER(substring(name,1,1))+LOWER(substring(name,2,len(name)-1)) namefrom Usersorder by user_id/* Write your PL/SQL query statement below */select user_id "user_id",initcap(name) "name"from Usersorder by 1
1484. 按日期分组销售产品
🚀表 Activities:+-------------+---------+| 列名 | 类型 |+-------------+---------+| sell_date | date || product | varchar |+-------------+---------+此表没有主键,它可能包含重复项。此表的每一行都包含产品名称和在市场上销售的日期。🚀 需求编写一个 SQL 查询来查找每个日期、销售的不同产品的数量及其名称。每个日期的销售产品名称应按词典序排列。返回按 sell_date 排序的结果表。查询结果格式如下例所示。 示例 1:输入:Activities 表:+------------+-------------+| sell_date | product |+------------+-------------+| 2020-05-30 | Headphone || 2020-06-01 | Pencil || 2020-06-02 | Mask || 2020-05-30 | Basketball || 2020-06-01 | Bible|| 2020-06-02 | Mask || 2020-05-30 | T-Shirt |+------------+-------------+输出:+------------+----------+------------------------------+| sell_date | num_sold | products|+------------+----------+------------------------------+| 2020-05-30 | 3 | Basketball,Headphone,T-shirt || 2020-06-01 | 2 | Bible,Pencil || 2020-06-02 | 1 | Mask |+------------+----------+------------------------------+解释:对于2020-05-30,出售的物品是 (Headphone, Basketball, T-shirt),按词典序排列,并用逗号 ',' 分隔。对于2020-06-01,出售的物品是 (Pencil, Bible),按词典序排列,并用逗号分隔。对于2020-06-02,出售的物品是 (Mask),只需返回该物品名。🐴🐴 答案# Write your MySQL query statement belowselect sell_date, count(distinct product) as num_sold, group_concat(distinct product) as productsfrom Activitiesgroup by sell_date/* Write your T-SQL query statement below */SELECT STUFF((SELECT ','+product FROM Activities for xml path('')),1,1,'') /* Write your T-SQL query statement below */select sell_date,count(distinct product) as num_sold,stuff((select distinct ','+product from Activities a where a.sell_date=b.sell_date for xml path('')),1,1,'') AS products from Activities b group by sell_date/* Write your PL/SQL query statement below */select sell_date "sell_date", count(distinct product) as "num_sold", wm_concat(distinct product) as "products"from Activitiesgroup by sell_date
1527. 患某种疾病的患者
🚀 患者信息表: Patients+--------------+---------+| Column Name | Type |+--------------+---------+| patient_id | int || patient_name | varchar || conditions | varchar |+--------------+---------+patient_id (患者 ID)是该表的主键。'conditions' (疾病)包含 0 个或以上的疾病代码,以空格分隔。这个表包含医院中患者的信息。写一条 SQL 语句,查询患有 I 类糖尿病的患者 ID (patient_id)、患者姓名(patient_name)以及其患有的所有疾病代码(conditions)。I 类糖尿病的代码总是包含前缀 DIAB1 。按 任意顺序 返回结果表。查询结果格式如下示例所示。 🚀 需求示例 1:输入:Patients表:+------------+--------------+--------------+| patient_id | patient_name | conditions |+------------+--------------+--------------+| 1 | Daniel| YFEV COUGH || 2 | Alice ||| 3 | Bob | DIAB100 MYOP || 4 | George| ACNE DIAB100 || 5 | Alain | DIAB201 |+------------+--------------+--------------+输出:+------------+--------------+--------------+| patient_id | patient_name | conditions |+------------+--------------+--------------+| 3 | Bob | DIAB100 MYOP || 4 | George| ACNE DIAB100 | +------------+--------------+--------------+解释:Bob 和 George 都患有代码以 DIAB1 开头的疾病。🐴🐴 答案# Write your MySQL query statement belowSELECT select * FROM PatientsWHERE conditions REGEXP '^DIAB1|\\sDIAB1'/* Write your PL/SQL query statement below */select patient_id "patient_id", patient_name "patient_name", conditions "conditions" from Patients where regexp_like(conditions,'^DIAB1|\ s*DIAB1') 以下为Oracle的正则表达式^匹配一个字符串的开始。如果与“m” 的match_parameter一起使用,则匹配表达式中任何位置的行的开头。$匹配字符串的结尾。如果与“m” 的match_parameter一起使用,则匹配表达式中任何位置的行的末尾。*匹配零个或多个。+匹配一个或多个出现。?匹配零次或一次出现。。匹配任何字符,除了空。|用“OR”来指定多个选项。[]用于指定一个匹配列表,您尝试匹配列表中的任何一个字符。[^]用于指定一个不匹配的列表,您尝试匹配除列表中的字符以外的任何字符。()用于将表达式分组为一个子表达式。{M}匹配m次。{M,}至少匹配m次。{M,N}至少匹配m次,但不多于n次。\ nn是1到9之间的数字。在遇到\ n之前匹配在()内找到的第n个子表达式。[..]匹配一个可以多于一个字符的整理元素。[:]匹配字符类。[==]匹配等价类。\ d匹配一个数字字符。\ D匹配一个非数字字符。\ w匹配包括下划线的任何单词字符。\ W匹配任何非单词字符。\ s匹配任何空白字符,包括空格,制表符,换页符等等。\ S匹配任何非空白字符。\A在换行符之前匹配字符串的开头或匹配字符串的末尾。\Z匹配字符串的末尾。*?匹配前面的模式零次或多次发生。+?匹配前面的模式一个或多个事件。??匹配前面的模式零次或一次出现。{N}?匹配前面的模式n次。{N,}?匹配前面的模式至少n次。{N,M}?匹配前面的模式至少n次,但不超过m次。
体系化学习SQL,请关注CSDN博客
https://blog.csdn.net/weixin_41645135/category_11653817.html
