数据库五章其二第一讲 ——SQL
目录
本人会用几天时间把在学校学到的整个数据库知识全盘托出,如果能看懂并且明白我接下来所写的博文,相信对你数据库提升、对行业软件理解、以后工作有很大帮助。
由于SQL部分内容实在太多,我会把整个第二章分成四个小部分来细讲
其二第一讲
目录
第二讲其一:SQL
•2.1 SQL概述
SQL的组成部分
SQL的特点
•2.2 SQL数据定义语言
创建数据库
含义
•【例2.1】创建数据库“图书管理”
CREATE DATABASE 图书管理
•【例2.4】删除数据库
DROP DATABASE 数据库名 [ , … n ]
•【例2.3】删除“图书管理”数据库:
DROP DATABASE 图书管理
•【例2.4】删除MY1和MY2数据库:
DROP DATABASE MY1, MY2
SQL中的数据类型
1. SQL中的数据类型
数据完整性约束
举例说明
2. 表中的约束条件
例一:
接下来我们用student表进行举例
student的结构
例 创建“student”表
例二:
接下来我们用stulesson(选课表)表进行举例
stulesson 的结构
例 创建“stulesson”表
修改表
删除表
下面我们再创建图书表Book
创建图书表Book语句
下面我们再创建读者表Reader
创建读者表Reader语句
下面我们再创建借阅表Borrow
创建借阅表Borrow语句
•2.1 SQL概述
SQL的产生和发展
• 1970 年,美国 IBM 研究中心的 E.F.Codd 连续发表多篇论文,提出关系模型。 • 1972 年, 最初的 SQL 原型 SQUARE 出现, 作为 IBM 公司 San Jose 研究室的 SYSTEM R 的一部分。 • 1974 年, Boyce 和 Chamberlin 把 SQUARE 修改为 SEQUEL 语言。后来 SEQUEL 简称为 SQL (Structured Query Language ) ,即 “ 结构化查询语言 ” 。 • 1986 年 10 月, ANSI 公布最早的 SQL 标准,并将其作为关系数据库管理系统的标准语言。 • 1987 年 6 月, ISO 采纳 SQL 为国际标准。 • 目前最新的 SQL 版本是 SQL-2003 ,又称 SQL4 。
SQL的组成部分
|
SQL功能 |
命令 |
|
数据定义语言 (Data Definition Language,简称DDL) |
CREATE 、ALTER 、DROP |
|
数据操纵语言 (Data Manipulation Language,简称DML) |
INSERT、DELETE、UPDATE、SELECT |
|
数据控制语言 (Data Control Language,简称DCL) |
GRANT、REVOKE |
SQL的特点
(1)功能一体化
(2)高度非过程化
(3)面向集合的操作方式
(4)两种使用方式:命令行和嵌入到其他宿主语言(如Java等)方式
(5)简洁易学
1. SQL 语言集数据定义语言 DDL 、数据操纵语言 DML 、数据控制语言 DCL 于一体; 2. 相对于其他过程化语言(如 C 语言等编程语言),使用 SQL 语言进行数据操作,只须描述清楚要做什么,无须告诉计算机怎么做才能得到结果,即数据的存取路径、 SQL 语句操作过程都由系统自动完成。这大大减轻了用户的负担,并有利于提高数据独立性。 3. 菲关系数据模型采用的是面向记录的操作方式,操作对象是一条记录。而 SQL 采用集合操作方式,其查找对象查找结果都是数据的集合,每次插入删除更新操作的对象也是数据的集合。这种操作方式极大的提高了数据操作的效率。 4. SQL 语言可以直接以命令方式与数据库进行交互,也可以作为嵌入式语言嵌入到其他程序设计语言(如 Java 、 C 等)中,并且两种不同使用方式中 SQL 语言的语法结构基本上是一致的。 5. SQL 语言虽然功能强大,但其命令数量有限,共 9 个动词,其语法也比较简单,且使用习惯接近于自然语言(英语),因此很容易学习和掌握。
•2.2 SQL数据定义语言
创建数据库
• CREATE DATABASE 数据库名 • [ON [ < 文件格式 > [ , … n ] ] ] • [ LOG ON { < 文件格式 > [ , … n ] } ] • < 文件格式 > ::= • ( [ NAME = 逻辑文件名 , ] • FILENAME = ‘ 操作系统下的物理路径和文件名’ • [, SIZE = 文件初始大小 ] • [, MAXSIZE = 文件最大大小 | UNLIMITED ] • [, FILEGROWTH = 增量值 ] ) [ , … n]
提醒:各个数据库产品在创建数据库语句的细节会都有些不同,在这里以SQL SERVER2008创建数据库的语句为例进行讲解。
含义
• ON 关键字表示数据库是根据后面的参数来创建的; • n 是一个占位符,表明可为新数据库指定多个文件; • LOG ON 子句用于指定该数据库的事务日志文件; • NAME 用于指定数据库文件的逻辑文件名; • FILENAME 用于指定数据库文件的存放位置及在磁盘上的文件名; • SIZE 用于指定数据库文件的初始大小,可以加上 MB 或 KB ,默认为 MB ; • MAXSIZE 用于指定数据库文件的最大大小,可以加上 MB 或 KB ,默认为 MB 。省略此项表示最大大小无限制; • FILEGROWTH 用于指定数据库文件的增加量,可以加上 MB 或 KB 或 % ,默认为 MB 。省略此项表示不自动增长。
•【例2.1】创建数据库“图书管理”
CREATE DATABASE 图书管理
数据库管理系统会创建“图书管理”数据库,并自动为其创建数据文件和日志文件,且使用默认的名称和默认的存储空间分配方案。
•【例2.4】删除数据库
DROP DATABASE 数据库名 [ , … n ]
• 被删除的数据库不能是当前正在使用的数据库。 • 使用数据库删除语句可以一次删除多个数据库。
•【例2.3】删除“图书管理”数据库:
DROP DATABASE 图书管理
•【例2.4】删除MY1和MY2数据库:
DROP DATABASE MY1, MY2
SQL中的数据类型
• 数值型 • 字符串型 • 日期型 • 货币型 数值型 不同的数据库系统支持的数据类型不完全相同。这里主要讲解SQL Server 2008中支持的数据类型。
|
SQL Server |
SQL99 |
说明 |
| Bigint |
8字节,存储从–263 (– 9223372036854775808) 到263-1 (9223372036854775807) 范围的整数。 |
|
| Int |
Integer |
4字节,存储从–231(–2,147,483,648 ) 到231-1 ( 2,147,483,647 ) 范围的整数 |
| Smallint | Smallint |
2字节,存储从–215(–32,768 ) 到215-1 (32,767 ) 范围的整数 |
| Tinyint |
存储从 0 到 255 之间的整数 |
|
| Bit |
Bit |
存储1或0 |
|
numeric(p,q)或decimal(p,q) |
decimal |
定点精度和小数位数。使用最大精度时,有效值从 –1038 +1 到 1038 -1。其中,p为精度,指定小数点左边和右边可以存储的十进制数字的最大个数。q为小数位数,指定小数点右边可以存储的十进制数字的最大个数,0 <= q <= p。q的默认值为0 |
|
float |
float |
8字节,存储从 –1.79E + 308 到 1.79E + 308 范围的浮点型数 |
|
real |
4字节,存储从 –3.40E + 38 到 3.40E + 38 范围的浮点型数 |
字符串型
普通字符编码:不同国家或地区的编码长度不一样,英文字符占一个字节(8位),中文汉字占2个字节(16位);
Unicode编码(统一字符编码):将世界上所有的字符统一进行编码,所有字符均2字节。
|
SQL Server |
SQL99 |
说明 |
|
char(n) |
character |
固定长度的字符串类型,n表示字符串的最大长度,取值范围为1~8000 |
| varchar(n) |
character varying |
可变长度的字符串类型,n表示字符串的最大长度,取值范围为1~8000 |
|
text |
可存储231-1 (2,147,483,647) 个字符的大文本 |
|
|
nchar(n) |
national characte |
固定长度的 Unicode 数据,n表示字符串的最大长度,取值范围为1~4000 |
|
nvarchar(n) |
national character varying |
可变长度的 Unicode 数据,n表示字符串的最大长度,取值范围为1~4000 |
|
ntext |
最多可存储230-1 (1,073,741,823) 个字符的统一字符编码文本 |
|
|
binary(n) |
binary |
固定长度的二进制字符数据,n表示最大长度,取值范围为1~8000 |
|
varbinary(n) |
binary varying |
可变长度的二进制字符数据,n的取值范围为1~8000 |
| image |
大容量的、可变长度的二进制字符数据,可以存储多种格式的文件,最大约为2GB |
日期时间类型
SQL Server的日期时间数据类型是将日期和时间合起来存储,它没有单独存储的日期和时间类型,但SQL92或SQL99是将日期和时间类型分开,没有日期时间合起来存储的类型,在SQL92或SQL99中日期是Date类型,时间是Time类型。
|
SQL Server |
说明 |
|
Datetime |
占用8字节空间,存储从1753年1月1日到9999年12月31日的日期和时间数据,精确到百分之三秒(或 3.33 毫秒) |
| Smalldatetime |
占用4字节空间,存储从1900年1月1日到2079年6月6日的日期和时间数据,精确到分钟 |
常量
• 数值型数据常量: 12313 , 2.343 • 字符串类型的数据常量两端需用 单引号 括起来,如‘ how are you’ , ’1234’ , ’ 中国 ’ • 日期时间类型的数据常量也用单引号括起来,书写格式有以下几种: – ‘May 25 2012’ – ‘2012-05-25’ (最常用的书写格式) – ‘2012/05/25’ – ‘20120525’
货币类型
• 货币数据类型表示货币值。货币数据存储的精确度固定为四位小数,实际上货币类型的数据都是有4位小数的decimal类型的数据。SQL92或SQL99没有对应的货币类型。
|
SQL Server |
说明 |
|
money |
8字节,存储的货币数据值介于–263 (–922,337,203,685,477.5808) 与 263-1 (+922,337,203,685,477.5807) 之间,精确到货币单位的千分之十。最多可以包含19位数字 |
| Smallmoney |
4字节,存储的货币数据值介于 –214,748.3648 与 +214,748.3647 之间,精确到货币单位的千分之十 |
在创建表之前需要掌握的知识
1. SQL中的数据类型
数据完整性约束
• 主码约束: PRIMARY KEY • 非空约束: NOT NULL • 检查约束: CHECK ( 条件表达式 ) • 唯一值约束: UNIQUE • 默认值约束: DEFAULT 默认值 • 外码约束:
FOREIGN KEY (外码列) REFERENCES 表名(主码列)
举例说明
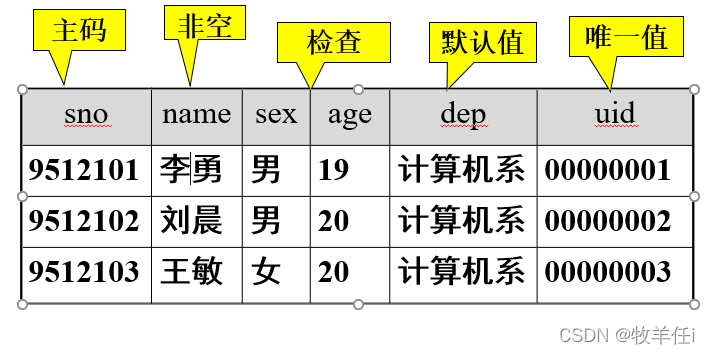
2. 表中的约束条件
创建表的语法结构
CREATE TABLE <表名>
(
<列名> <数据类型> [列级完整性约束定义]
{, <列名> <数据类型> [列级完整性约束
定义] … }
[, 表级完整性约束定义 ]
)
注释:
<表名>:所要定义的基本表的名字
<列名>:组成该表的各个属性(列)
<列级完整性约束条件>:涉及相应属性列的完整性约束条件
<表级完整性约束条件>:涉及一个或多个属性列的完整性约束条件
例一:
接下来我们用student表进行举例
|
sno |
name |
sex |
age |
dep |
uid |
|
09512101 |
李勇 |
男 |
19 |
计算机系 |
00000001 |
|
09512102 |
刘晨 |
男 |
20 |
计算机系 |
00000002 |
|
09512103 |
王敏 |
女 |
20 |
计算机系 |
00000003 |
student的结构
|
列名 |
数据类型 |
约束 |
说明 |
|
sno |
CHAR(8) |
主码 |
每个学生学号应非空且唯一 |
|
name |
CHAR(10) |
非空 |
姓名信息必须要保存 |
|
sex |
CHAR(2) |
检查 |
取“男”或“女” |
|
age |
INT |
检查 |
小于10,大于60的学生年龄无意义 |
|
dep |
VARCHAR(26) |
default |
默认值为“计算机系” |
|
uid |
CHAR(18) |
唯一值 |
每个人的身份证号是唯一 |
例 创建“student”表
CREATE TABLE student(sno CHAR(8) PRIMARY KEY ,name CHAR(10) NOT NULL ,sex CHAR(2) CHECK(sex ='男' OR sex ='女') ,age INT CHECK(age >=10 AND age <=60) ,dep VARCHAR(26) default '计算机系' ,uid CHAR(18) UNIQUE)例二:
接下来我们用stulesson(选课表)表进行举例
|
sno |
cname |
score |
|
001 |
数据库原理 |
90 |
|
003 |
数据库原理 |
80 |
|
003 |
C语言 |
75 |
stulesson 的结构
|
列名 |
数据类型 |
约束 |
说明 |
|
sno |
CHAR(8) |
|
|
|
cname |
CHAR(50) |
非空 |
姓名信息必须要保存 |
|
score |
INT |
检查 |
在0~100之间 |
例 创建“stulesson”表
CREATE TABLE stulesson(sno CHAR(8),cname CHAR(50) NOT NULL,score INT CHECK(score >=0 AND score <=100),PRIMARY KEY(sno, cname ), FOREIGN KEY(sno ) REFERENCES student(sno ) )修改表
• 语法格式:
ALTER TABLE <表名>
{[ ALTER COLUMN <列名> <新数据类型>]
-- 修改列定义
| [ ADD <列名> <数据类型> [约束] ]
-- 添加新列
| [ DROP COLUMN <列名> ] }
-- 删除列
•【例】为student表添加“班级”列,列的定义为 class CHAR(30)
ALTER TABLE student ADD class CHAR(30)
•【例】将class列修改为varchar(30)
ALTER TABLE student ALTER COLUMN class VARCHAR(30)
•【例】删除class列
ALTER TABLE student DROP COLUMN class
删除表
•语法:DROP TABLE <表名>{[,<表名>]…} •【例】删除“student ”
DROP TABLE student
•注意:有外码参照的表只能在外码所在表删除后才可以被删除。
下面我们再创建图书表Book
|
列名 |
数据类型 |
约束 |
描述 |
|
book_ID |
CHAR(10) |
主码 |
图书编号 |
|
name |
VARCHAR(30) |
非空 |
图书的名称 |
|
author |
VARCHAR(10) |
|
图书的作者 |
|
publish |
VARCHAR(20) |
|
出版社 |
|
price |
DECIMAL(6,2) |
大于0 |
定价 |
|
classify |
Varchar(20) |
|
图书分类 |
创建图书表Book语句
CREATE TABLE Book (book_ID CHAR(10) PRIMARY KEY, name VARCHAR(30) NOT NULL, author VARCHAR(10) ,publish VARCHAR(20),priceDECIMAL(6,2) CHECK(price>0) ,Classify varchar(20) ) 其中 PRIMARY KEY 为主码约束,CHECK为检查约束
下面我们再创建读者表Reader
|
列名 |
数据类型 |
约束 |
描述 |
|
reader_ID |
CHAR(10) |
主码 |
读者编号 |
|
name |
VARCHAR(8) |
|
读者姓名 |
|
sex |
CHAR(2) |
|
读者性别 |
|
birthdate |
DATETIME |
|
读者的出生日期 |
创建读者表Reader语句
CREATE TABLE Reader (Reader_ID CHAR(10) PRIMARY KEY,name VARCHAR(8) ,sex CHAR(2),birthdate DATETIME)下面我们再创建借阅表Borrow
|
列名 |
数据类型 |
约束 |
描述 |
|
book_ID |
CHAR(10) |
组合主码;外码,参照Book表中的book_ID |
图书编号 |
|
reader_ID |
CHAR(10) |
组合主码;外码,参照Reader表中的reader_ID |
读者编号 |
|
borrowdate |
DATETIME |
|
借阅日期 |
|
returndate |
DATETIME |
|
还书日期 |
创建借阅表Borrow语句
CREATE TABLE Borrow(book_ID CHAR(10),Reader_ID CHAR(10),Borrowdate DATETIME,PRIMARY KEY(book_ID,Reader_ID), FOREIGN KEY(book_ID) REFERENCES Book(book_ID), FOREIGN KEY(Reader_ID) REFERENCES Reader(Reader_ID) )其中Book_ID 是外码,参照Book表的Book_ID
Reader_ID 是外码,参照Reader表的Reader_ID
数据库五章其二第二讲 ——SQL_熬夜程序员-CSDN博客![]() https://blog.csdn.net/rej177/article/details/122762751?spm=1001.2014.3001.5502
https://blog.csdn.net/rej177/article/details/122762751?spm=1001.2014.3001.5502

