完美解释:wenet-流式与非流式语音识别统一模型
Unified Streaming and Non-streaming Two-pass End-to-end Model for Speech Recognition[1] ,本文以该篇论文为主线,进行扩展。参考了很多大佬博客,非常感谢。如有错误,请指正。
流式与非流式语音识别统一模型-出门问问&西工大方案
1.模型结构
如下图所示,模型包含三个部分,分别为共享的Encoder、CTC解码器、Attention解码器,共享Encoder包含多层transformer或者conformer,CTC解码器为一个全连接层和一个softmax层,Attention解码器包含多层transformer层。(shared encoder只能看到有限的右边上下文。在第一遍中,CTC decoder 以流式模式进行运行。在第二遍中,shared decoder和CTC decoder的输出被使用。)
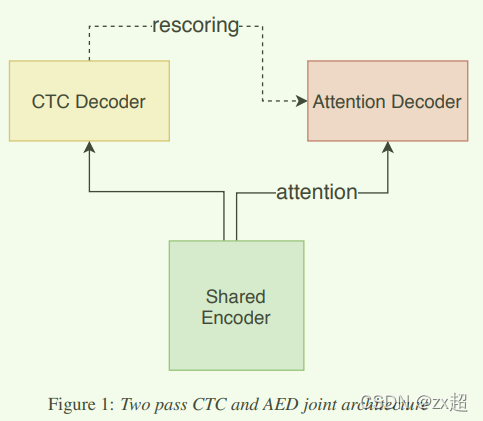
2. 模型训练
融合Loss。模型训练loss包含两个部分:帧级别 deocder 的CTC loss 和 label 级别 decoder 的 AED loss,如下列公式所示,其中x为输入的声学特征,y为音频标注序列,第一项为CTC loss,第二项为AED(attention encoder-decoder) loss。(代码中只看到了encoder的 帧级别ctc loss 和 encoder+decoder 的label级别的 ce loss )
x是输入声学特征,y是对应的模型输出结果,λ是平衡CTC和AED损失的权重。融合loss极大的简化训练通道,也帮助模型转换速度变快,并取得较好的效果。
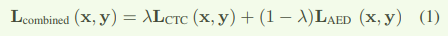
static Chunk Training。该机制使模型支持流式语音识别,流式语音识别需要shared encoder在传输信息时,能够进行流式传输。因此我们需要限制共享Encoder看到的未来信息。因为看到的越多,模型输出结果需要等待的时间越多。shared encoder逐chunk使用音频特征,大的chunk通常意味着高的延迟率和好的准确率。所以该论文综合考虑如下:
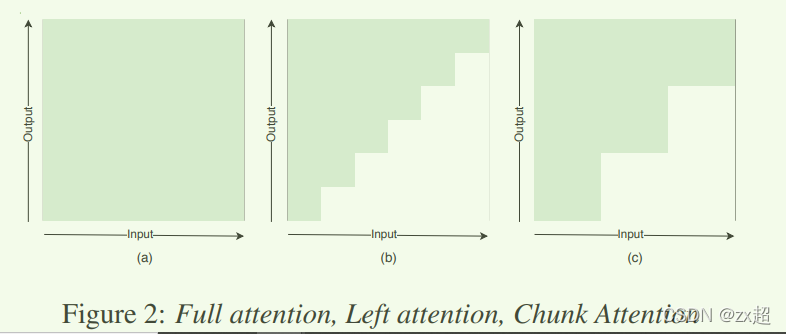
如下图所示,(a)为标准的self attention,在每个输入时刻t都需要依赖整句的输入。针对这一问题,最简单的流式思路,限制当前时刻t只看到历史信息,不看任何未来信息,如图(b)所示,但该方案会极大的影响模型识别效果。而另外一种常用的思路,限制当前时刻t看到有限的未来时刻信息(比如看到未来C帧信息),如图©所示。在模型训练中,Chunk的大小可以是固定的,也可以是动态调整的,chunk的大小影响了模型的实时率(RTF)。
【同时论文中提到:如果在纯左注意力情况下,右边的上下文通常能够提高性能。但是也要小心设计encoder layers的层数以及每层的right context,以控制整个模型的最终right context。】
dynam chunk training。在统一E2E模型思想的推动下,动态块训练被提出。可以在训练中对不同的批次使用动态块大小,动态块大小范围是从1到最大话语长度的均匀分布,即注意力从左上下文注意力到完整上下文注意力不等,模型捕获各种块大小的不同信息,并学习如何在提供不同的有限右上下文时进行准确的预测。将大小从 1 到 25 的块称为流式处理模型的流式处理块,将最大话语长度称为无流式处理模型的无流式处理块。但是,dynam chunk training方法的结果还不够好,因此接下来我们在训练过程中更改块大小的分布,如下所示:
在训练过程中,x 在每个批次中从 0 到 1.0 进行采样, l m a xl_{max} lmax 是当前批次的最大话语长度,U
是均匀分布。因此,块大小的分布发生了变化,一半是没有流式传输的完整块,另一半从 1 到 25 用于流式传输。
实验将表明,这是一种简单但有效的方法,通过动态块大小训练的模型与静态块训练相比具有可比的性能。 除了这种批处理级别方法之外,该论文还尝试了epoch 级别。对前半部分 epoch 使用完整块,对后半部分或依次使用流块。但这些策略行不通。
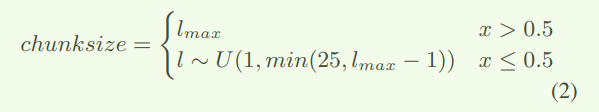
causal convolution。在Conformer中的卷积单元考虑左和右上下文。而总右上下文依赖于卷积层的上下文和conformer的堆叠层数。因此,这种结构不仅带来了额外的延迟,还毁了基于块的注意力的好处。即延迟因该是独立于网络结构上的,并且相关时间可以通过块来控制。为了克服这个问题,我们使用causal convolution。【在dynamic chunk training中使用】
3.解码
Wenet 在训练时同时使用了帧级别 deocder 的 CTC loss 和 label 级别 decoder 的 loss。因此在推断时可以使用多种不同的解码方式。目前 Wenet 支持四种解码算法:
- CTC greedy beam search,帧级别输出,解码过程不合并前缀,最终 n-best 上进行ctc序列处理。(选每一帧概率最高的输出,然后去重去blank,得到最终的序列输出。)
- CTC
prefix beam search,帧级别的解码,合并相同的 ctc 序列前缀。 - Attention decoder beam search, 基于 cross-attention 的 label 级别解码。
- CTC + attention rescoring , 将 CTC decoder 的 n-best 结果,通过 attention decoder 进行重打分。
论文解释:
CTC解码器以流式的方式输出一遍解码结果,二遍解码的时候,Attention解码器利用全局上下文的Attention信息,以便获取更好的识别结果。二遍解码的时候,有两种方式:
- 方式一:attention decoder mode。
忽略CTC的解码结果,Attention 解码器基于shared Encoder的输出,以自回归的方式,直接进行解码,输出最终识别结果(这种方式RTF较高);- 方式二:rescoring model。基于CTC解码的n-best hypothesis,Attention解码器以
teacher-forcing方式进行再重打分。best rescored hypothes作为最终的识别结果。该方式避免了自回归过程并完成了较好的RTF。此外,在attention得分的基础下,联合CTC权重得分是提高效果的一种简单方式,如以下公式。
解释teacher-forcing :
以seq2seq中的decoder为例,涉及到输入是以正确的单词还是以预测出来的单词。 两种方案:
- 当前时刻的输入和上一时刻的输出,是有关联的。具体来说就是,当前时刻的输入就是上一时刻的输出。
常用的以预测出来的单词作为输入存在的问题:其中某一个单词预测错了,后面会跟着错,模型很难收敛。- 不管上一时刻输出是什么,当前时刻的输入总是规定好的,按照给定的 target 进行输入。
以正确的单词(Ground Truth) 作为输入存在的问题:Overcorrect问题,导致输出出现语法错误Teacher Forcing 机制:介于二者之间
teacher_forcing_ratio参数:训练过程中的每个时刻,有一定概率使用上一时刻的输出作为输入,也有一定概率使用正确的target 作为输入。
(该论文teacher-forcing只在CTC decoder 输出n_best基础下,attention decoder训练和解码时都体现。 )
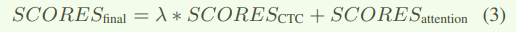
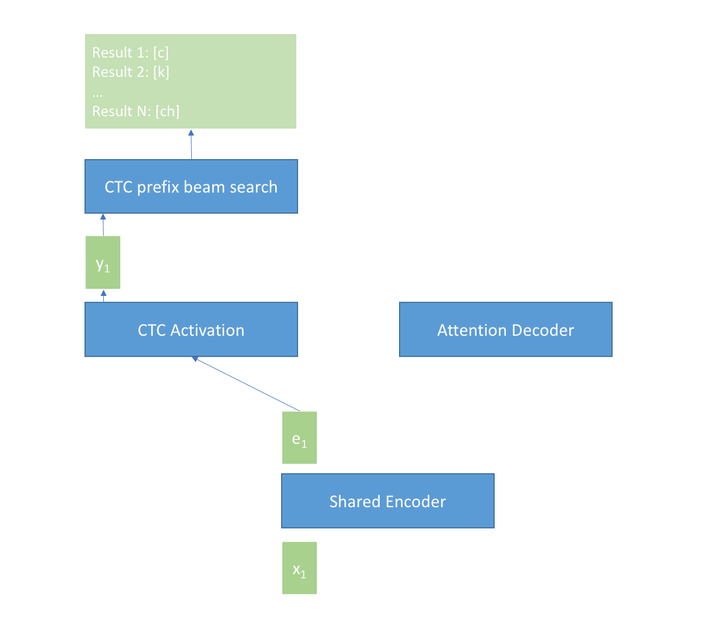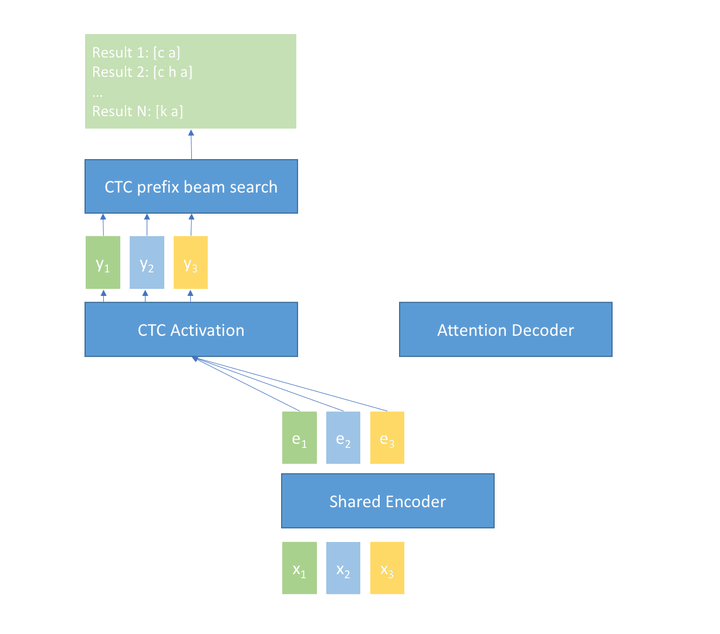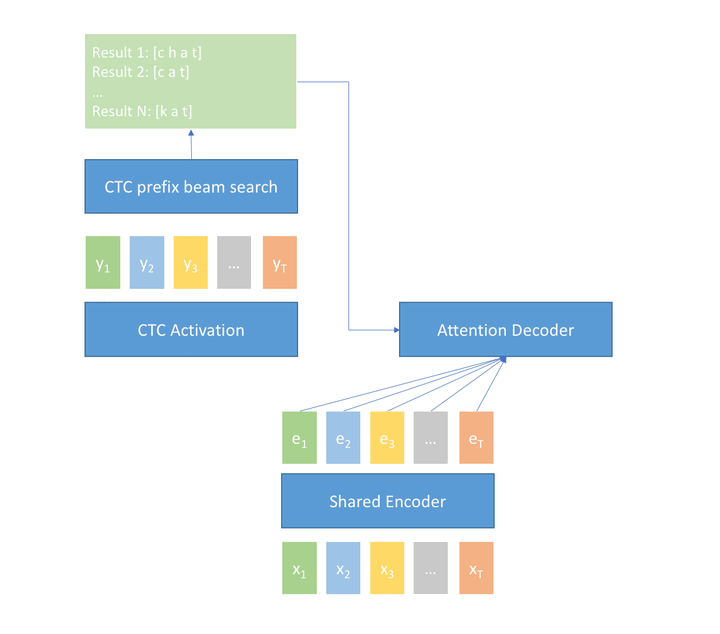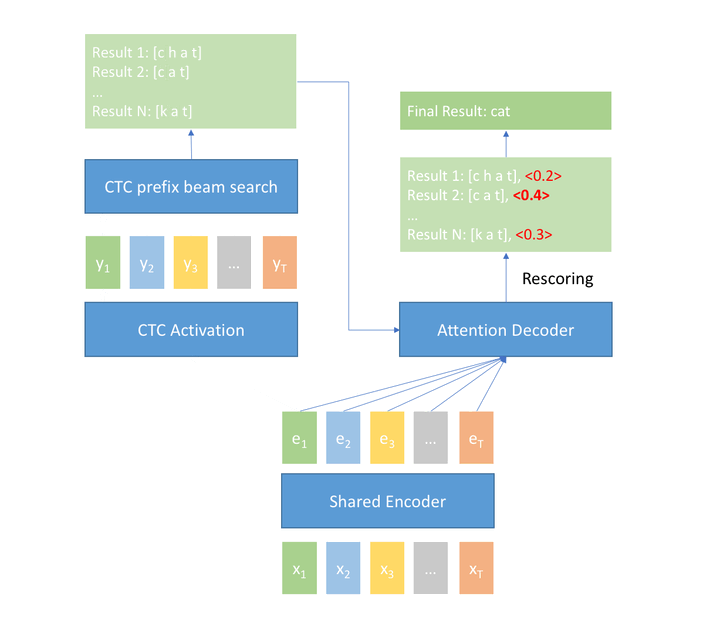
CTC prefix beam search + attention rescoring 方案可以利用 CTC decoder的输出作为流式结果,在损失很小准确率的情况下支持场景的流式需求,并最终利用 rescoring 改进结果,得到一个识别率更高的最终结果。 考虑一个实时字幕上屏的场景,当演讲者说话时,可利用 CTC decoder 的实时输出结果将字幕实时上屏,让听众立刻看到当前演讲内容的文本,在一句话结束时,会对文本内容进行重打分纠正,最终显示和进行归档的文本是准确率更高的结果。手机 / 车载等语音助理也同样适用该模式。
论文:First-Pass Large Vocabulary Continuous Speech Recognition using Bi-Directional Recurrent DNNs.
beam search缺点:CTC一般要与语言模型结合,提高准确率,因此必须有多个candidate,但也不能够穷尽每个frame每个token的组合,故有beam search。beam search的candidate会有很多相同的部分(有许多不同的路径在many-to-one map的过程中是相同的,但beam search却会将一部分舍去,这导致了很多有用的信息被舍弃了),而相同的部分应该把他们置信度加起来,否则会可能因为单一路径置信度偏小而错误排优,所以有了Prefix beam search。
CTC prefix beam search:维护的不是beam 个路径前缀,而是 beam 个标签前缀(存在不同的路径映射到相同规整化前缀),但仍需要考虑其之后的路径。每次更新的时候,输出的prefix序列已经是合并过blank和带blank的重复序列。每个prefix包含两个得分pb和pnb,该prefix最终的得分为pb+pnb。t 时刻遍历 beam*beam 个可能:分三种情况,blank、和之前重复、其他情况,分别更新 pb 和 pnb。最后根据这两个概率和选前 beam 个。prefix beam search详细解释1,解释2,解释3。
wenet 中prefix beam search代码: # cur_hyps: (prefix, (blank_ending_score, none_blank_ending_score)) # cur_hyps (prefix ,(pb, pnb))用于当前已经存在的前缀 prefix, 初始化为 空 # pb 对应前缀 prefix 以 blank 结尾的概率, 初始化为 1 (空前缀等价 blank) # pnb 对应前缀 prefix 以 非 blank 结尾的概率, 初始化为 0 (空前缀 没有 非 blank) cur_hyps = [(tuple(), (0.0, -float('inf')))] # 2. CTC beam search step by step for t in range(0, maxlen):logp = ctc_probs[t] # (vocab_size,) # key: prefix, value (pb, pnb), default value(-inf, -inf) # next_hpys 保存 t 时刻,扩展的路径 next_hyps = defaultdict(lambda: (-float('inf'), -float('inf'))) # 2.1 First beam prune: select topk best # 当前 t 时刻的 beam 个 top 输出 top_k_logp, top_k_index = logp.topk(beam_size) # (beam_size,) for s in top_k_index: s = s.item() ps = logp[s].item() for prefix, (pb, pnb) in cur_hyps: last = prefix[-1] if len(prefix) > 0 else None if s == 0: # blank # 扩展符号为 blank, 则当前前缀扩展后还是一样,有两种情况 # 情况1,前缀为结尾非 blank : 如 *a (a) + _ 后 变成 *a_ (*a), 而pnb 没改变 # 情况2,前缀为结尾 blank : 如 *a_ (*a) + _ 后 还是为 *a_ (*a), 所以 概率更新 n_pb(*a) += (pb(*a) * ps) + (pnb((*a) * ps) # 注: n_pb += 用累加是 n_pb 是时刻保存一样路径的概率和, 同理 n_pnb += 。 n_pb, n_pnb = next_hyps[prefix] n_pb = log_add([n_pb, pb + ps, pnb + ps]) next_hyps[prefix] = (n_pb, n_pnb) elif s == last: # 扩展符号非 blank 且与前缀最后字符相同,有两种情况 # 情况1,前缀结尾是非 blank : 如 *a + a 后 变成 (*a) , 从而更新pnb(*a) n_pnb += pnb * ps # 情况2,前缀结尾是 blank : 如 *a_ + a 后 变城 (*aa), 是另一个路径, 则新改路径 n_pnb(*aa) += pb(*a) * ps # Update *ss -> *s; n_pb, n_pnb = next_hyps[prefix] n_pnb = log_add([n_pnb, pnb + ps]) next_hyps[prefix] = (n_pb, n_pnb) # Update *s-s -> *ss, - is for blank n_prefix = prefix + (s, ) n_pb, n_pnb = next_hyps[n_prefix] n_pnb = log_add([n_pnb, pb + ps]) next_hyps[n_prefix] = (n_pb, n_pnb) else: # 扩展符号非 blank 且与前缀最后字符不同,则只有一种情况,就是扩展为另一个路径,此时更新这个路径概率 # 如 *a + c 后变后 (*ac) , *a_ + c 后也变为 (*ac) , 所以 n_pnb(*ac) += pb(*a) * ps + pnb(*a) * ps n_prefix = prefix + (s, ) n_pb, n_pnb = next_hyps[n_prefix] n_pnb = log_add([n_pnb, pb + ps, pnb + ps]) next_hyps[n_prefix] = (n_pb, n_pnb) # t 时刻重新更新保存 beam 个最优 前缀。 next_hyps = sorted(next_hyps.items(), key=lambda x: log_add(list(x[1])), reverse=True) cur_hyps = next_hyps[:beam_size]4. 实验
数据集:AISHELL-1
声学特征:一帧是80维FBank特征,拼接三维度pitch作为输入,其中窗长25ms,窗移10ms.
数据增强:语速扰动(0.9,1,1.1),SpecAugment。
论文:SpecAugment: A Simple Data Augmentation Methodfor Automatic Speech Recognition[3]
思想:SpecAugment是一种log梅尔声谱层面上的数据增强方法,可以将模型训练的过拟合问题转化为欠拟合问题,以便通过大网络和长时训练策略来缓解欠拟合问题,提升语音识别效果。
模型:
- 输入特征:log梅尔声谱
- 声谱增强:将log梅尔声谱的时域和频域看作二维图像,时间片长度为τ,频域长度ν
时间扭曲,穿过图像中心的水平直线上,(W,τ-W)范围内的随机点,向左或向右平移w距离,0=<w<=W;
时间掩蔽,沿时间轴方向的[ t 0 t_0t0, t 0 t_0t0+t)范围内的连续时间步进行掩蔽,其中0=<t0<τ,t服从[0,T]均匀分布;
频率掩蔽,沿频域轴方向的[ f 0 f_0f0, f 0 f_0f0+f)范围内的连续频率通道进行掩蔽,其中0=< f 0 f_0f0<ν,f服从[0,F]均匀分布;

实验模型配置:
subsampling layer:每个subsampling层包括2层卷积,卷积核大小3*3,步长为2;共使用了4层subsamping;
encoder layer:12层conformer,其中使用4 multihead attention,256 attention dimension,2048 feed forward dimension;
attention decoder layer:6层transformer,其中使用4 multihead attention,256 attention dimension,2048 feed forward dimension;
trick:gradient accumulation用于稳定训练,每4步更新一次参数;{Attention dropout,feedforward dropout;label smoothing regularization}防止over-fitting;
*解释gradient accumulation*普通训练函数,输进一个batch数据,计算一次梯度,更新一次网络; for i, (image, label) in enumerate(train_loader): pred = model(image) loss = criterion(pred, label) optimizer.zero_grad() # reset gradient,清除过往梯度; loss.backward() # 反向传播,计算当前梯度; optimizer.step() # 根据梯度更新网络参数; 梯度累加训练函数,梯度累加就是,每次获取1个batch的数据,计算1次梯度,梯度不清空,不断累加,累加一定次数后,根据累加的梯度更新网络参数,然后清空梯度,进行下一次循环。 for i,(image, label) in enumerate(train_loader):# 1. nput outputpred = model(image)loss = criterion(pred, label)# 2.1 loss regularizationloss = loss / accumulation_steps # 2.2 back propagationloss.backward() # 反向传播,计算当前梯度;# 3. update parameters of netif (i+1) % accumulation_steps == 0: # 梯度累加accumulation_steps次数之后,根据累加的梯度更新网络参数,然后清空梯度,进行下一个循环;# optimizer the netoptimizer.step() # update parameters of netoptimizer.zero_grad() # reset gradient一定条件下,batchsize 越大训练效果越好,梯度累加则实现了 batchsize 变相扩大,如果accumulation steps为 8,则batchsize '变相’扩大了8倍,解决显存受限的一个不错的trick,使用时需要注意,学习率也要适当放大。
BN是否有影响?BN的估算是在forward阶段就已经完成的,并不冲突,只是accumulation_steps=8和真实的batchsize放大八倍相比,效果自然是差一些,毕竟八倍Batchsize的BN估算出来的均值和方差肯定更精准一些。可以适当调低BN自己的momentum参数。
optimizer:Adam
learning rate:schedule with 25000 warm-up step
warm-up:一种优化学习率的方法,详细解释warm-up学习率预热的方法。
解码方法比较:

该实验探索了在非流式模型中两种不同解码器方法,着重比较attention decoder 和attention rescoring 之间的实时率(RTF),以及四种解码方式的识别结果。模型中使用了full context ,并且conformer使用标准卷积核大小为15被用于训练。AED decoder中,使用beam=10作为解码;CTC使用prefix beam search,用于形成top n_best hypothesises,作为最终重打分的参考信息。
第一组实验:attention decoder.
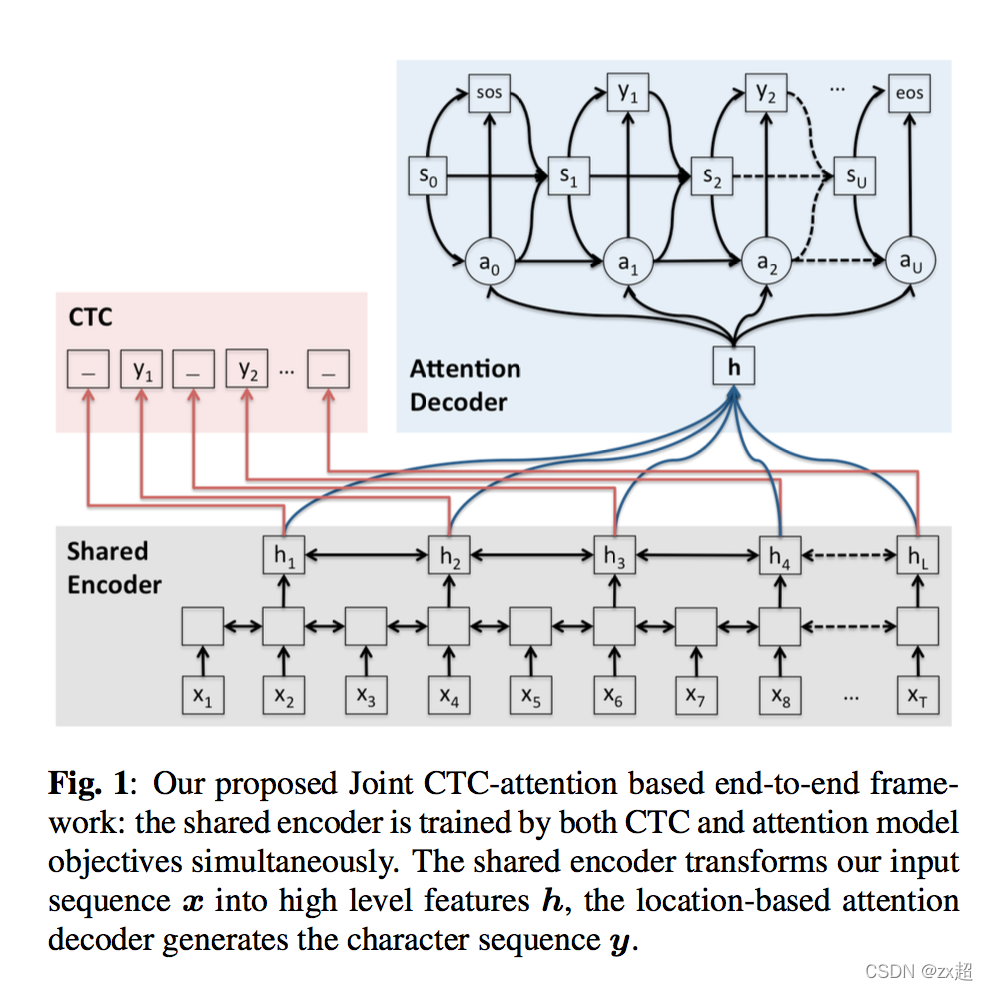
虽然Attention模型虽然效果好,但是还是有自身的问题[7],问题如下:
- 适合短语识别,对长句子识别比较差;
- noisy data的时候训练不稳定 ;
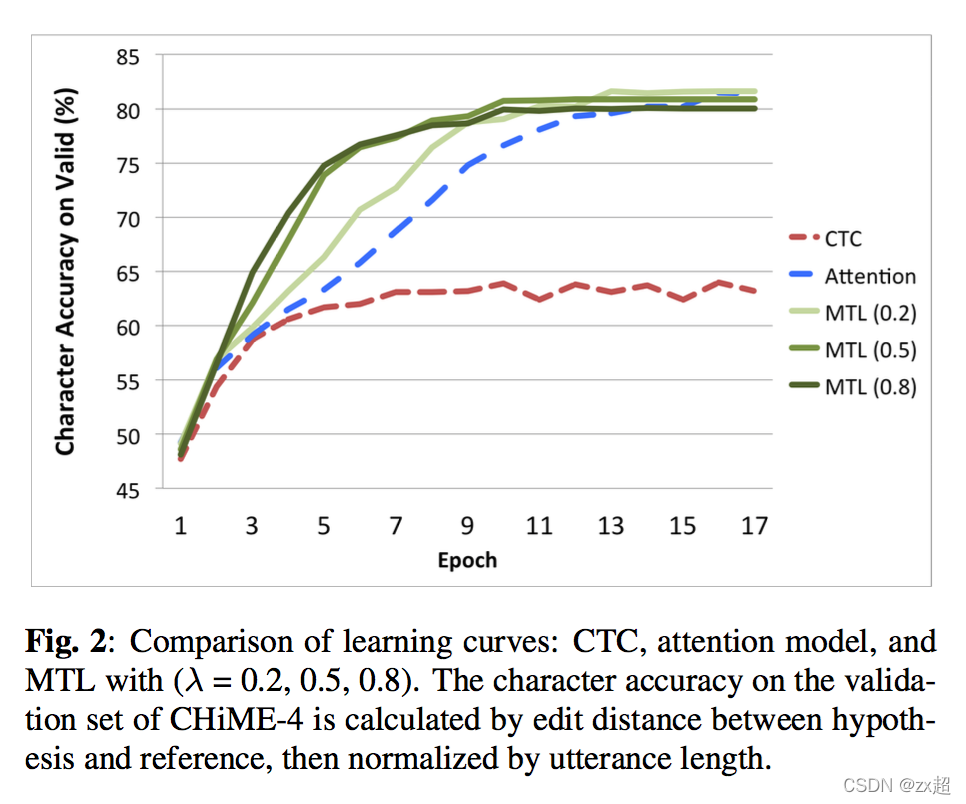
Suyoun Kim等人在2016年9月的文章[7]就对Attention与CTC结合对语音声学模型建模,论文中对比Attention模型还有CTC模型,Attention+CTC模型更快的收敛了,这得益于初始阶段CTC的阶段对齐更准确,使得Attention模型训练收敛更快。其结构如下所示:
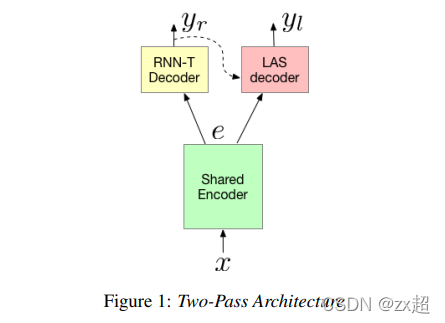
2019年,论文Two-Pass End-to-End Speech Recognition[8],提出了Two pass结构,wenet的灵感来源于这里。其结构如下:
第二组实验:ctc prefix beam search,这里ctc实时率不是该实验的重点,因此使用”/“表示。
第三、四组实验:attention rescoring,论文做了分析如下:
论文分析了ctc prefix beam search和attention rescoring之后,发现了ctc prefix beam search产生很多错误,可以通过attention rescoring策略来纠正。但是一些CTC 解码正确结果也会在attention rescoring之后,被校正成错误,意味着CTC在某些情况下发挥着重要作用。因此,需要添加CTC权重得分。并且测试了0.1到0.9的不同CTC权重得分,得出当λ=0.5时,是最稳定的。
同时论文也分析了不同RTF原因:
由于标准attention decoder以自回归方式运行,这很耗时,而attention rescoring仅使用attention decoder进行重新评分,因此可以并行处理,理论上应该更快。因此,在这里论文还研究了attention decoder和attention rescoring方法的RTF,并且在Pytorch的解码过程中使用单线程。如表1所示,与解码中的注意力解码器相比,我们通过注意力重新评分的速度提高了2.40倍。 总而言之,我们可以看到注意力重新评分既更快又准确。
动态和静态chunk训练方式比较:
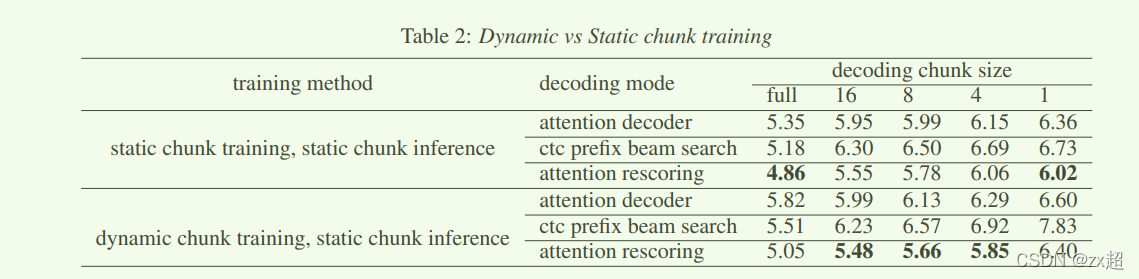
5.整体流程
训练: Forward, encoder 选择full attention / dynamic chunk 跑完,根据encoder out 和 label text,计算出帧级别的ctc loss。然后encoder out 和 label text(shifted right)做attention decoder,得到predict text ,再与label text,计算label 级的ce。最后loss 按权重相加。
推理:CTC + attention rescoring 的情况:Encoder 使用指定的chunk size 解码,得到流式的encoder out,使用CTC prefix beam search进行解码,得到beam个序列hyps及其得分,encoder out 和hyps(shifted right) 去attention decoder ,得到 beam个序列对应对得分(beam_size,length,class维度 )(最后一维做softmax,length个概率相加,得到该序列得分),再和ctc得分按权重相加,再排序。得到最好的输出结果。
shifted right右移一位,是为了解码区最初初始化时第一次输入,并将其统一定义为特定值。
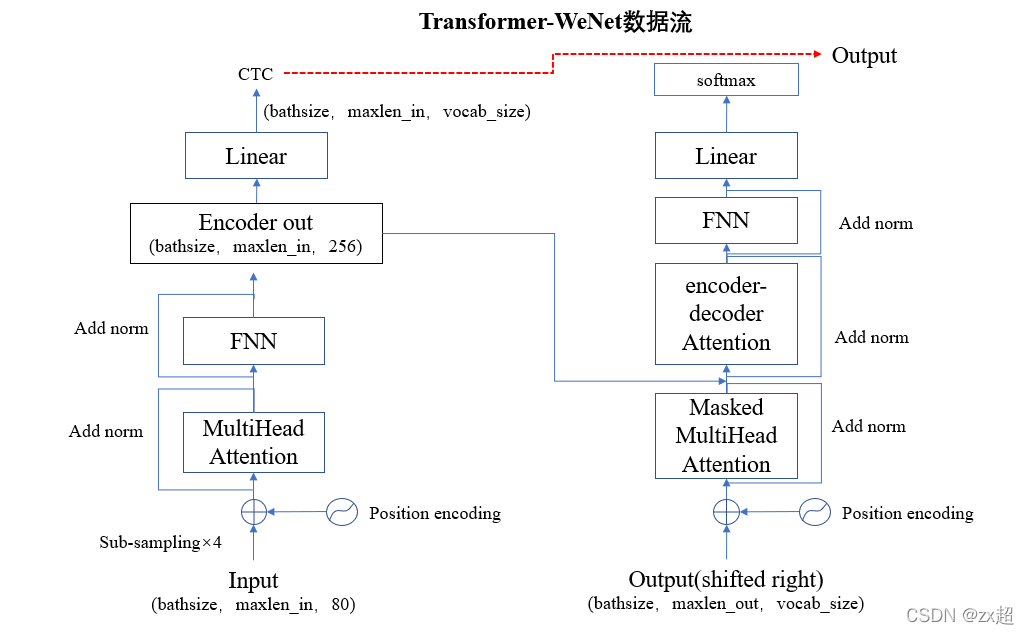
wenet-transformer数据流图:
6.模型部署[10]
WeNet设计流程:
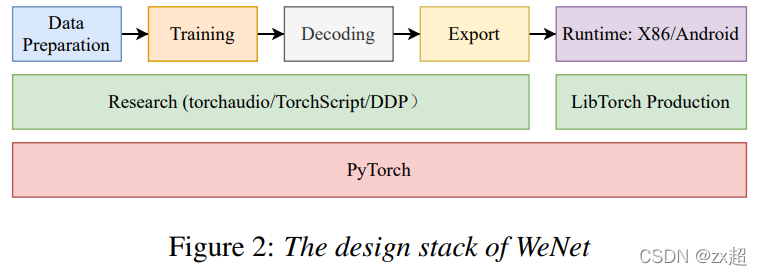
torchaudio: 音频处理工具包
TorchScript: 是一种从PyTorch代码创建可序列化和可优化模型的方法。通过torch.jit.script(model),将pytorch模型转为torchscript模型,可以将转化的模型在高性能环境(例如C ++)中运行。【torch.jit.trace可以将pt模型转为TracedModule,但容易追踪不到if else 控制流,所以不建议用】解释1,2,3
DDP: 分布式数据并行,加快模型训练。解释1,2,3
LibTorch: 是pytorch推出的C++接口版本,支持CPU端和GPU端的部署和训练。主要是为了满足一些工业场景主体代码是C++实现的。在部署使用,用于加载模型,加快解码(前向推理)速度。
模型导出:
Wenet 模型全部由 Torchscript 编写,可以直接导出为支持 libtorch 运行时推断的模型,在运行时,利用 libtorch 导出的接口完成网络前向计算,而特征提取和解码算法则通过 C++ 代码实现.
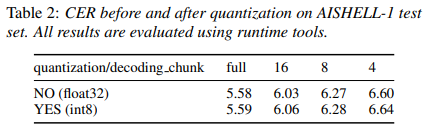
模型裁剪: Wenet 模型量化没有带来性能损失
目前 Wenet 使用 dynamic 量化来对模型进行压缩,该量化方法对代码结构破坏最小,而且也最为便捷。量化后的模型性能几乎没有损失。
实时率:Wenet 的实时率可达 0.1 以内。
实时率即处理时间 / 语音时长。更低的实时率意味着可以用更少的计算资源处理更多的语音,即能够为企业带来更低的服务器运营成本。通过模型量化,Wenet 的实时率在服务器端和手机端均可以达到 0.1 以下。即处理 10 秒音频需要的时间不超过 1 秒。

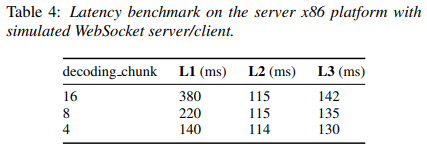
延时性能:
语音识别中存在多种延时需要考虑,如流式识别时用户感知到的实时回显的延时,如一句话说完后完成整句识别的延时。我们考虑三种延时:
L1: 模型结构带来的流式延时
L2: 重打分计算部分带来的延时
L3: 用户说话,到最终重打分后的结果之间的时间间隔。
Wenet 的演示非常低,其不到 0.4s 的流式延时和 0.14s 的整句延时,使得用户在使用时几乎感受不到延时.
参考:
[1] Unified Streaming and Non-streaming Two-pass End-to-end Model for Speech Recognition
[2] https://www.cnblogs.com/zy230530/p/13682080.html
[3] SpecAugment: A Simple Data Augmentation Methodfor Automatic Speech Recognition
[4] https://www.cnblogs.com/zy230530/p/13682080.html
[5] https://www.zhihu.com/question/303070254
[6] https://www.cnblogs.com/dahu-daqing/p/14805678.html
[7] JOINT CTC-ATTENTION BASED END-TO-END SPEECH RECOGNITIONUSING MULTI-TASK LEARNING
[8] Two-Pass End-to-End Speech Recognition
[9] https://zhuanlan.zhihu.com/p/335560775
[10] WeNet: Production Oriented Streaming and Non-streaming End-to-End Speech Recognition Toolkit
[11] http://placebokkk.github.io/asr/2020/02/01/asr-ctc-decoder.html
[12] Tian Z K, Yi J Y, Tao J H, et al. Self-attention transducers for end- to-end speech recognition

