SQL中,in和exists详解+案例
SQL中,in和exists详解+案例
-
- 1. 案例表结构
- 2. 什么是in
-
- 2.1 执行逻辑
- 3. 什么是exists
-
- 3.1 执行逻辑
1. 案例表结构
-
一张人员表:user
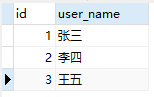
-
一张地区表:area

-
一张中间表:user_area
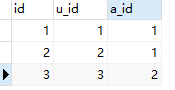
以当前初始数据表示我们知道:张三和李四两个人的地区是”成都“,王五的地区是”湖南“。
2. 什么是in
in 操作符允许我们在 where子句中规定多个值。我们在开发中最常用的就是in。
现在如果我们有一个需求:用一条sql查出地区属于”成都“的人员的名字。
SELECTuser_name FROMUSER WHEREid IN (SELECTua.u_id FROMuser_area uaINNER JOIN area a ON ua.a_id = a.id AND a.area_name = '成都') 这条sql包含了一个子查询,先从中间表查出满足条件的用户的id,再把这些查出来的id作为查询条件去user表中做in条件查询。所以sql简化出来就是这样的:
select user_name from user where id in (1,2) 2.1 执行逻辑
select * from A
where id in(select id from B)
in()只执行一次,它查出B表中的所有id字段并缓存起来之后,检查A表的id是否与B表中的id相等,如果等则
将A表的记录加入结果集中,直到遍历完A表的所有记录。
如果用伪代码来表示,可以这样理解:
List resultSet=[];Array A=(select * from A);Array B=(select id from B);for(int i=0;i<A.length;i++) { for(int j=0;j<B.length;j++) { if(A[i].id==B[j].id) { resultSet.add(A[i]); break; } }}return resultSet;可以看出,当B表数据较大时不适合使用in(),因为它会B表数据全部遍历一次.
结论:in()适合B表比A表数据小的情况
3. 什么是exists
exists运算符用于判断查询子句是否有记录,如果有一条或多条记录存在返回 True,否则返回 False。
(指定一个子查询,检测行的存在。遍历循环外表,然后看外表中的记录有没有和内表的数据一样的。匹配上就将结果放入结果集中。)
所以,使用exists的话,子查询实际上不会返回任何数据结果,只会返回true和false。如果我们用exists来完成之前的需求,改怎么做呢?
用一条sql查出地区属于”成都“的人员的名字。
SELECTuser_name FROMUSER AS a WHEREEXISTS (SELECTb.u_id FROMuser_area bINNER JOIN area c ON b.a_id = c.id AND c.area_name = '成都' WHEREa.id = b.u_id #重要的一行);3.1 执行逻辑
select a.* from A a
where exists(select 1 from B b where a.id=b.id)
exists()会执行A.length次,它并不缓存exists()结果集,因为exists()结果集的内容并不重要,重要的是结果集中是否有记录,如果有则返回true,没有则返回false.
如果用伪代码来表示,可以这样理解:
List resultSet=[];Array A=(select * from A)for(int i=0;i<A.length;i++) { if(exists(A[i].id) { //执行select 1 from B b where b.id=a.id是否有记录返回resultSet.add(A[i]); }}return resultSet;简单点一句话就是:会循环A表length次,每次会把A表的数据带到B表进行匹配,匹配上的话就加入结果集。
当B表比A表数据大时适合使用exists(),因为它没有那么遍历操作,只需要再执行一次查询就行.
结论:in()适合B表比A表数据大的情况

