Flink使用指南: Flink SQL自定义函数
系列文章目录
Flink使用指南: Watermark新版本使用
Flink使用指南: Kafka流表关联HBase维度表
目录
前言
一、Flink SQL 自定义函数有哪些?
二、标量函数(UDF)
三、表值函数(UDTF)
四、聚合函数(UDAGG)
五、表值聚合函数(UDTAGG)
总结
前言
Flink版本: 1.12.4
Scala版本:2.11
Java版本:1.8
《Flink使用指南》该系列博客是本人在日常使用Flink实时计算时的经验总结,从入门到熟悉的过程,会记录下官网的入门使用以及在使用过程中遇到的问题及解决办法。如果大家觉得博客写的不错,可以关注下博主。求关注~谢谢
提示:以下是本篇文章正文内容,下面案例可供参考
一、Flink SQL 自定义函数有哪些?
当前 Flink 有如下几种函数:
- 标量函数 将标量值转换成一个新标量值;
- 表值函数 将标量值转换成新的行数据;
- 聚合函数 将多行数据里的标量值转换成一个新标量值;
- 表值聚合函数 将多行数据里的标量值转换成新的行数据;
- 异步表值函数 是异步查询外部数据系统的特殊函数。
Flink SQL的自定义函数用于 SQL 查询前要先经过注册;而在用于 Table API 时,函数可以先注册后调用,也可以 内联 后直接使用。
二、标量函数(UDF)
自定义标量函数可以把 0 到多个标量值映射成 1 个标量值,数据类型里列出的任何数据类型都可作为求值方法的参数和返回值类型。
想要实现自定义标量函数,你需要扩展 org.apache.flink.table.functions 里面的 ScalarFunction 并且实现一个或者多个求值方法。标量函数的行为取决于你写的求值方法。求值方法必须是 public 的,而且名字必须是 eval。
代码如下(示例):
import org.apache.flink.table.annotation.InputGroupimport org.apache.flink.table.api._import org.apache.flink.table.functions.ScalarFunctionclass HashFunction extends ScalarFunction { // 接受任意类型输入,返回 INT 型输出 def eval(@DataTypeHint(inputGroup = InputGroup.ANY) o: AnyRef): Int { return o.hashCode(); }}val env = TableEnvironment.create(...)// 在 Table API 里不经注册直接“内联”调用函数env.from("MyTable").select(call(classOf[HashFunction], $"myField"))// 注册函数env.createTemporarySystemFunction("HashFunction", classOf[HashFunction])// 在 Table API 里调用注册好的函数env.from("MyTable").select(call("HashFunction", $"myField"))// 在 SQL 里调用注册好的函数env.sqlQuery("SELECT HashFunction(myField) FROM MyTable")三、表值函数(UDTF)
跟自定义标量函数一样,自定义表值函数的输入参数也可以是 0 到多个标量。但是跟标量函数只能返回一个值不同的是,它可以返回任意多行。返回的每一行可以包含 1 到多列,如果输出行只包含 1 列,会省略结构化信息并生成标量值,这个标量值在运行阶段会隐式地包装进行里。
要定义一个表值函数,你需要扩展 org.apache.flink.table.functions 下的 TableFunction,可以通过实现多个名为 eval 的方法对求值方法进行重载。像其他函数一样,输入和输出类型也可以通过反射自动提取出来。表值函数返回的表的类型取决于 TableFunction 类的泛型参数 T,不同于标量函数,表值函数的求值方法本身不包含返回类型,而是通过 collect(T) 方法来发送要输出的行。
在 Table API 中,表值函数是通过 .joinLateral(...) 或者 .leftOuterJoinLateral(...) 来使用的。joinLateral 算子会把外表(算子左侧的表)的每一行跟跟表值函数返回的所有行(位于算子右侧)进行 (cross)join。leftOuterJoinLateral 算子也是把外表(算子左侧的表)的每一行跟表值函数返回的所有行(位于算子右侧)进行(cross)join,并且如果表值函数返回 0 行也会保留外表的这一行。
在 SQL 里面用 JOIN 或者 以 ON TRUE 为条件的 LEFT JOIN 来配合 LATERAL TABLE() 的使用
代码如下(示例):
import org.apache.flink.table.annotation.DataTypeHintimport org.apache.flink.table.annotation.FunctionHintimport org.apache.flink.table.api._import org.apache.flink.table.functions.TableFunctionimport org.apache.flink.types.Row@FunctionHint(output = new DataTypeHint("ROW"))class SplitFunction extends TableFunction[Row] { def eval(str: String): Unit = { // use collect(...) to emit a row str.split(" ").foreach(s => collect(Row.of(s, Int.box(s.length)))) }}val env = TableEnvironment.create(...)// 在 Table API 里不经注册直接“内联”调用函数env .from("MyTable") .joinLateral(call(classOf[SplitFunction], $"myField") .select($"myField", $"word", $"length")env .from("MyTable") .leftOuterJoinLateral(call(classOf[SplitFunction], $"myField")) .select($"myField", $"word", $"length")// 在 Table API 里重命名函数字段env .from("MyTable") .leftOuterJoinLateral(call(classOf[SplitFunction], $"myField").as("newWord", "newLength")) .select($"myField", $"newWord", $"newLength")// 注册函数env.createTemporarySystemFunction("SplitFunction", classOf[SplitFunction])// 在 Table API 里调用注册好的函数env .from("MyTable") .joinLateral(call("SplitFunction", $"myField")) .select($"myField", $"word", $"length")env .from("MyTable") .leftOuterJoinLateral(call("SplitFunction", $"myField")) .select($"myField", $"word", $"length")// 在 SQL 里调用注册好的函数env.sqlQuery( "SELECT myField, word, length " + "FROM MyTable, LATERAL TABLE(SplitFunction(myField))");env.sqlQuery( "SELECT myField, word, length " + "FROM MyTable " + "LEFT JOIN LATERAL TABLE(SplitFunction(myField)) ON TRUE")// 在 SQL 里重命名函数字段env.sqlQuery( "SELECT myField, newWord, newLength " + "FROM MyTable " + "LEFT JOIN LATERAL TABLE(SplitFunction(myField)) AS T(newWord, newLength) ON TRUE")tips: 在当时测试时发现如果@FunctionHint中定义了数据类型为Int等类型时,在使用Collect收集数据时,要使用Int.box() 把int基本类型改成包装类型,不然会报错 : Error: the result type of an implicit conversion must be more specific than object。
四、聚合函数(UDAGG)
自定义聚合函数(UDAGG)是把一个表(一行或者多行,每行可以有一列或者多列)聚合成一个
标量值。
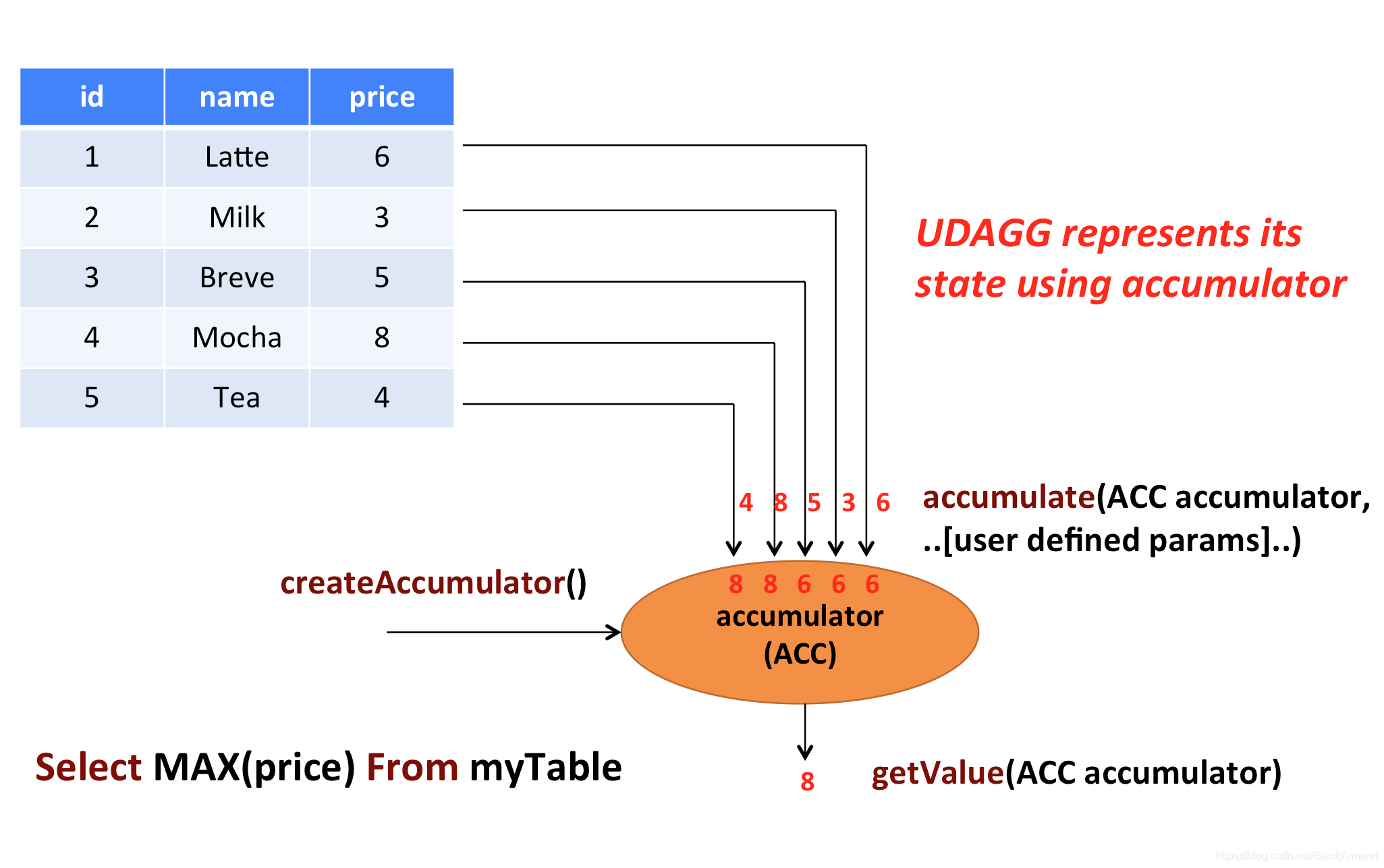
上面的图片展示了一个聚合的例子。假设你有一个关于饮料的表。表里面有三个字段,分别是 id、name、price,表里有 5 行数据。假设你需要找到所有饮料里最贵的饮料的价格,即执行一个 max() 聚合。你需要遍历所有 5 行数据,而结果就只有一个数值。
自定义聚合函数是通过扩展 AggregateFunction 来实现的。AggregateFunction 的工作过程如下。首先,它需要一个 accumulator,它是一个数据结构,存储了聚合的中间结果。通过调用 AggregateFunction 的 createAccumulator() 方法创建一个空的 accumulator。接下来,对于每一行数据,会调用 accumulate() 方法来更新 accumulator。当所有的数据都处理完了之后,通过调用 getValue 方法来计算和返回最终的结果。
下面几个方法是每个 AggregateFunction 必须要实现的:
createAccumulator()accumulate()getValue()
Flink 的类型推导在遇到复杂类型的时候可能会推导出错误的结果,比如那些非基本类型和普通的 POJO 类型的复杂类型。所以跟 ScalarFunction 和 TableFunction 一样,AggregateFunction 也提供了 AggregateFunction#getResultType() 和 AggregateFunction#getAccumulatorType() 来分别指定返回值类型和 accumulator 的类型,两个函数的返回值类型也都是 TypeInformation。
除了上面的方法,还有几个方法可以选择实现。这些方法有些可以让查询更加高效,而有些是在某些特定场景下必须要实现的。例如,如果聚合函数用在会话窗口(当两个会话窗口合并的时候需要 merge 他们的 accumulator)的话,merge() 方法就是必须要实现的。
AggregateFunction 的以下方法在某些场景下是必须实现的:
retract()在 boundedOVER窗口中是必须实现的。merge()在许多批式聚合和会话以及滚动窗口聚合中是必须实现的。除此之外,这个方法对于优化也很多帮助。例如,两阶段聚合优化就需要所有的AggregateFunction都实现merge方法。resetAccumulator()在许多批式聚合中是必须实现的。
AggregateFunction 的所有方法都必须是 public 的,不能是 static 的,而且名字必须跟上面写的一样。createAccumulator、getValue、getResultType 以及 getAccumulatorType 这几个函数是在抽象类 AggregateFunction 中定义的,而其他函数都是约定的方法。如果要定义一个聚合函数,你需要扩展 org.apache.flink.table.functions.AggregateFunction,并且实现一个(或者多个)accumulate 方法。accumulate 方法可以重载,每个方法的参数类型不同,并且支持变长参数。
代码如下(示例):
import java.lang.{Long => JLong, Integer => JInteger}import org.apache.flink.api.java.tuple.{Tuple1 => JTuple1}import org.apache.flink.api.java.typeutils.TupleTypeInfoimport org.apache.flink.table.api.Typesimport org.apache.flink.table.functions.AggregateFunction/ * Accumulator for WeightedAvg. */class WeightedAvgAccum extends JTuple1[JLong, JInteger] { sum = 0L count = 0}/ * Weighted Average user-defined aggregate function. */class WeightedAvg extends AggregateFunction[JLong, CountAccumulator] { override def createAccumulator(): WeightedAvgAccum = { new WeightedAvgAccum } override def getValue(acc: WeightedAvgAccum): JLong = { if (acc.count == 0) { null } else { acc.sum / acc.count } } def accumulate(acc: WeightedAvgAccum, iValue: JLong, iWeight: JInteger): Unit = { acc.sum += iValue * iWeight acc.count += iWeight } def retract(acc: WeightedAvgAccum, iValue: JLong, iWeight: JInteger): Unit = { acc.sum -= iValue * iWeight acc.count -= iWeight } def merge(acc: WeightedAvgAccum, it: java.lang.Iterable[WeightedAvgAccum]): Unit = { val iter = it.iterator() while (iter.hasNext) { val a = iter.next() acc.count += a.count acc.sum += a.sum } } def resetAccumulator(acc: WeightedAvgAccum): Unit = { acc.count = 0 acc.sum = 0L } override def getAccumulatorType: TypeInformation[WeightedAvgAccum] = { new TupleTypeInfo(classOf[WeightedAvgAccum], Types.LONG, Types.INT) } override def getResultType: TypeInformation[JLong] = Types.LONG}// 注册函数val tEnv: StreamTableEnvironment = ???tEnv.registerFunction("wAvg", new WeightedAvg())// 使用函数tEnv.sqlQuery("SELECT user, wAvg(points, level) AS avgPoints FROM userScores GROUP BY user")五、表值聚合函数(UDTAGG)
自定义表值聚合函数(UDTAGG)可以把一个表(一行或者多行,每行有一列或者多列)聚合成另一张表,结果中可以有多行多列。
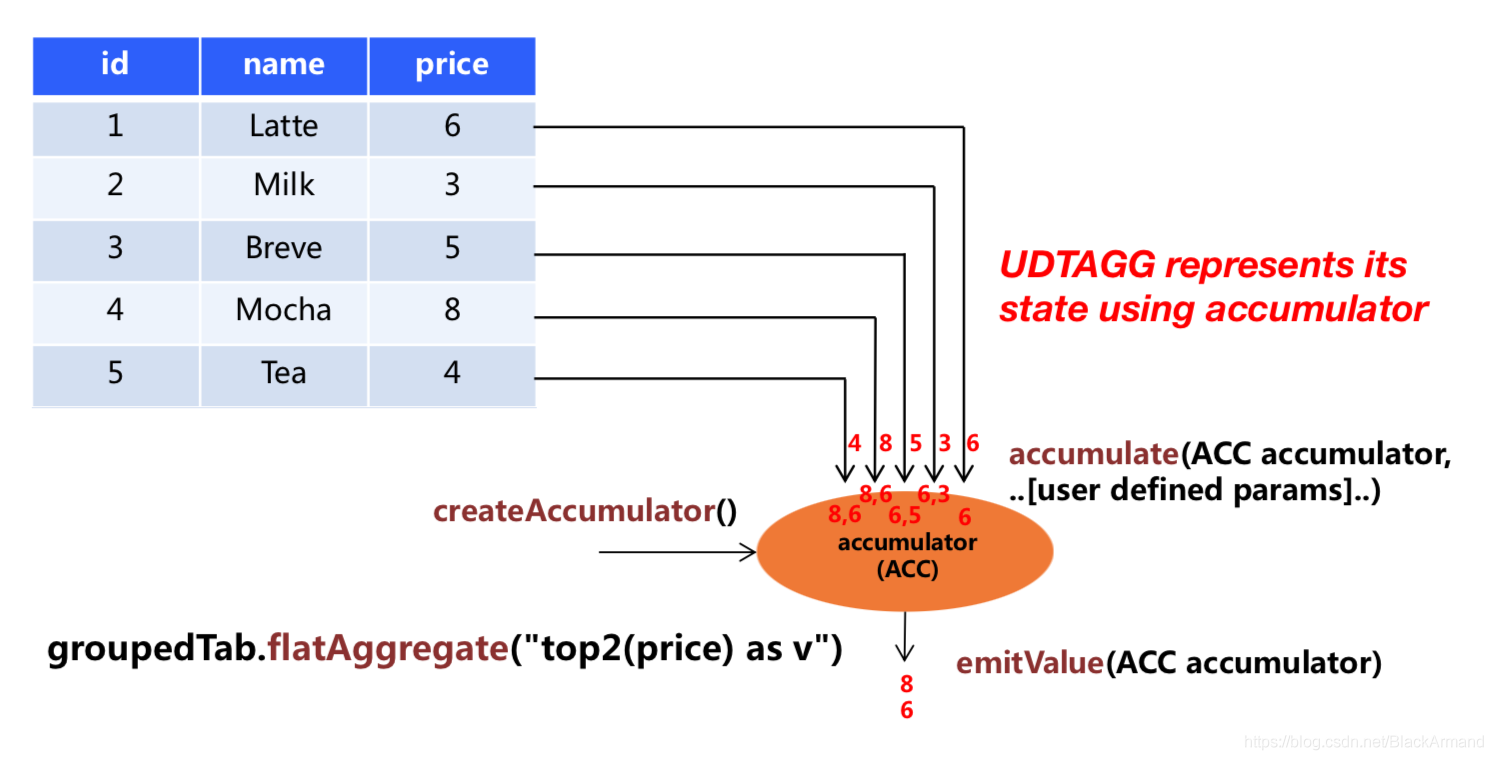
上图展示了一个表值聚合函数的例子。假设你有一个饮料的表,这个表有 3 列,分别是 id、name 和 price,一共有 5 行。假设你需要找到价格最高的两个饮料,类似于 top2() 表值聚合函数。你需要遍历所有 5 行数据,结果是有 2 行数据的一个表。
用户自定义表值聚合函数是通过扩展 TableAggregateFunction 类来实现的。一个 TableAggregateFunction 的工作过程如下。首先,它需要一个 accumulator,这个 accumulator 负责存储聚合的中间结果。 通过调用 TableAggregateFunction 的 createAccumulator 方法来构造一个空的 accumulator。接下来,对于每一行数据,会调用 accumulate 方法来更新 accumulator。当所有数据都处理完之后,调用 emitValue 方法来计算和返回最终的结果。
下面几个 TableAggregateFunction 的方法是必须要实现的:
createAccumulator()accumulate()
Flink 的类型推导在遇到复杂类型的时候可能会推导出错误的结果,比如那些非基本类型和普通的 POJO 类型的复杂类型。所以类似于 ScalarFunction 和 TableFunction,TableAggregateFunction 也提供了 TableAggregateFunction#getResultType() 和 TableAggregateFunction#getAccumulatorType() 方法来指定返回值类型和 accumulator 的类型,这两个方法都需要返回 TypeInformation。
除了上面的方法,还有几个其他的方法可以选择性的实现。有些方法可以让查询更加高效,而有些方法对于某些特定场景是必须要实现的。比如,在会话窗口(当两个会话窗口合并时会合并两个 accumulator)中使用聚合函数时,必须要实现merge() 方法。
下面几个 TableAggregateFunction 的方法在某些特定场景下是必须要实现的:
retract()在 boundedOVER窗口中的聚合函数必须要实现。merge()在许多批式聚合和以及流式会话和滑动窗口聚合中是必须要实现的。resetAccumulator()在许多批式聚合中是必须要实现的。emitValue()在批式聚合以及窗口聚合中是必须要实现的。
下面的 TableAggregateFunction 的方法可以提升流式任务的效率:
emitUpdateWithRetract()在 retract 模式下,该方法负责发送被更新的值。
emitValue 方法会发送所有 accumulator 给出的结果。拿 TopN 来说,emitValue 每次都会发送所有的最大的 n 个值。这在流式任务中可能会有一些性能问题。为了提升性能,用户可以实现 emitUpdateWithRetract 方法。这个方法在 retract 模式下会增量的输出结果,比如有数据更新了,我们必须要撤回老的数据,然后再发送新的数据。如果定义了 emitUpdateWithRetract 方法,那它会优先于 emitValue 方法被使用,因为一般认为 emitUpdateWithRetract 会更加高效,因为它的输出是增量的。
TableAggregateFunction 的所有方法都必须是 public 的、非 static 的,而且名字必须跟上面提到的一样。createAccumulator、getResultType 和 getAccumulatorType 这三个方法是在抽象父类 TableAggregateFunction 中定义的,而其他的方法都是约定的方法。要实现一个表值聚合函数,你必须扩展 org.apache.flink.table.functions.TableAggregateFunction,并且实现一个(或者多个)accumulate 方法。accumulate 方法可以有多个重载的方法,也可以支持变长参数。
import java.lang.{Integer => JInteger}import org.apache.flink.table.api.Typesimport org.apache.flink.table.functions.TableAggregateFunction/ * Accumulator for top2. */class Top2Accum { var first: JInteger = _ var second: JInteger = _}/ * The top2 user-defined table aggregate function. */class Top2 extends TableAggregateFunction[JTuple2[JInteger, JInteger], Top2Accum] { override def createAccumulator(): Top2Accum = { val acc = new Top2Accum acc.first = Int.MinValue acc.second = Int.MinValue acc } def accumulate(acc: Top2Accum, v: Int) { if (v > acc.first) { acc.second = acc.first acc.first = v } else if (v > acc.second) { acc.second = v } } def merge(acc: Top2Accum, its: JIterable[Top2Accum]): Unit = { val iter = its.iterator() while (iter.hasNext) { val top2 = iter.next() accumulate(acc, top2.first) accumulate(acc, top2.second) } } def emitValue(acc: Top2Accum, out: Collector[JTuple2[JInteger, JInteger]]): Unit = { // emit the value and rank if (acc.first != Int.MinValue) { out.collect(JTuple2.of(acc.first, 1)) } if (acc.second != Int.MinValue) { out.collect(JTuple2.of(acc.second, 2)) } }}// 初始化表val tab = ...// 使用函数tab .groupBy('key) .flatAggregate(top2('a) as ('v, 'rank)) .select('key, 'v, 'rank)总结
刚接触Flink实时计算时使用Stream API实现需求,慢慢接触Flink SQL后极大的加大了开发效率,看来SQL是未来的趋势。
欢迎大家扫一扫下面个人微信,我会拉大家进入大数据技术交流群,一起学习一起进步吧。


