奇*信往期模拟笔试知识点总结
文章目录
- 奇真题重点
-
- 前情摘要
- 2020秋招-3
- 2020秋招-2
- 2020秋招-1
- 2021春招-1
- 2021春招-2
- 2020技术支持-1
- 2020技术支持-2
奇真题重点
前情摘要
前段时间在boss直聘看着这个公司在济南也有课投递岗位,索性试了试,没想到前几天真的收到笔试邀请了,确实收到邮件那段时间感觉很激动,想着反正给我机会了,我索性就试试吧,先去牛客网找到对应的公司的往年秋招春招试题,刚开始没想到题目这么难,还有编程题,刚刚上手确实不太行,等多做两道之后发现秋招比春招容易太多了,,所以还是尽早冲秋招吧,本来这家公司就不是主要做Java的,所以看起来没什么可投递的岗位。这会算是提前感受了一波秋招的压力,Java部分其实还可以接收,但是这里的题目太多的Linux和计算机网络与安全相关的东西,所以为了准备这次笔试,很多东西我只能去记忆,然后看一些解析或者博客去理解,这几天时间真吸收不了这么多知识,这几天脑子都昏昏的。
等我真正去做笔试题目的时候发现,仿佛走错考场了,迎面而来的很多也还都是一些计算机网络和操作系统相关的知识,关于Java技术的东西几乎没有。算是有一点点小失落,不过很感谢这段时间自己有在为这个笔试努力吸收知识,也初步感受到秋招春招时这种大厂的难度,自己接下来这段时间一方面是要去坚持写算法题,坚持自己动手而不是看别人写,也不是抄代码;另一方面就是加强Java及其相关技术栈的理论知识的基础,同时也结合实战,这样自己的思考会更多,对项目的理解也会更深刻很多。总之多尝试吧,有实习先实习,外包也算是一点经验,发现长时间学不到太多东西的话就只能及时止损,自己多去刷算法,学技术。
这篇博客算是这几天自己的一段总结,也是方便自己和大家下个阶段的复习。

2020秋招-3
-
对一个文件的访问,常由 用户访问权限和文件属性 共同限制
-
TCP是面向连接的,UDP是面向无连接的
-
一个有向无环图 存在 拓扑排序
-
存在一个数字组成的序列[a1,a2,…,aN],若要统计所有数字出现的次数 ,使用 哈希表 比较合适
-
存在若干个字符串,若要查找具有相同前缀的字符串,Trie树 比较合适
Trie树是一种树形结构,是一种哈希树的变种。典型应用是用于统计,排序和保存大量的字符串(但不仅限于字符串), 所以经常被搜索引擎系统用于文本词频统计。它的优点是:利用字符串的公共前缀来减少查询时间,最大限度地减少无谓的字符串比较,查询效率比哈希树高。
-
辗转相除法 是用来求解两个正整数的最大公约数的算法
-
epoll ET模式必须配合non-blocking IO使用
epoll的两种模式,EL边缘模式和TL水平模式。epoll默认使用TL,TL支持非阻塞IO
-
在一个空目录下执行umask 333; touch hello;命令后,hello文件的权限为 r–r–r– (r4w2x1)
-
在DNS系统测试时,假设named进程号是53,如何通知进程重读配置文件 kill -HUP 53
使用kill -l 命令列出所有可用信号
最常用的信号是:
1(HUP):重新加载进程 9(KILL):杀死一个进程 15(TERM):正常停止一个进程
-
视图 可用于 限制对表中特定行或列中的数据的访问
-
DROP VIEW 视图名 删除视图
-
NAT(网络地址转换器):可同时实现地址和端口转换,IPv6可能需要NAT(NAT是一种路由器)
-
IPv6过渡技术:隧道技术(DS-Lite 6RD)、双栈技术、地址翻译(协议转换)技术
应用层 :HTTP\SMTP\POP3 表示层:ASCII 会话层: RPC\SOCKETS
传输层: TCP\UDP 网络层: ARP\路由 数据链路层:交换机,网桥,令牌环
物理层:集线器,双绞线,光纤
-
final修饰的类不可以被继承,修饰的变量不可以被改变,但它修饰的方法可以重载,可以被继承,但是不能被子类覆盖(重写)
重载与覆盖有什么区别?
定义区别
①重载是指不同的函数使用相同的函数名,但是函数的参数个数或类型不同。调用的时候根据函数的参数来区别不同的函数。
②覆盖(也叫重写)是指在派生类中重新对基类中的虚函数(注意是虚函数)重新实现。即函数名和参数都一样,只是函数的实现体不一样。2.类的关系区别
覆盖是子类和父类之间的关系,是垂直关系;重载是同一个类中方法之间的关系,是水平关系。
-
String s = new String(“xyz”);创建了几个StringObject 两个或一个都有可能
> 如果在常量池中已经存在“xyz”,那么不会继续创建,只创建一个new String("xyz")的对象。如果常> 量池中没有,则会创建两个对象,一个是对象的值“xyz”,一个是new String("xyz")的对象。 -
在下列4条语句的前提下:
Integer i01 = -128;
int i02 = -128;
Integer i03 =Integer.valueOf(-128);
Integer i04 = new Integer(-128);
以下输出结果为false的是:System.out.println(i03 == i04);
Integer i01=-128的时候,会调用Integer的valueOf方法,
这个方法就是返回一个Integer对象,只是在返回之前,看作了一个判断,判断当前i的值是否在[-128,127]区别,且IntegerCache中是否存在此对象,如果存在,则直接返回引用,否则,创建一个新的对象。
在这里的话,因为程序初次运行,没有-128,所以,直接创建了一个新的对象。int i02=-128,这是一个基本类型,存储在栈中。
Integer i03 =Integer.valueOf(-128);因为IntegerCache中已经存在此对象,所以,直接返回引用。
Integer i04 = new Integer(-128);直接创建一个新的对象。
System.out.println(i01== i02); i01是Integer对象,i02是int,这里比较的不是地址,而是值。Integer会自动拆箱成int,然后进行值的比较。所以,为真。
System.out.println(i01== i03);因为i03返回的是i01的引用,所以,为真。
System.out.println(i03==i04);因为i04是重新创建的对象,所以i03,i04是指向不同的对象,因此比较结果为假。
System.out.println(i02== i04);因为i02是基本类型,所以此时i04会自动拆箱,进行值比较,所以,结果为真。
-
Reboot是重启, shutdown -s 是关机, shutdown -r是重启, netstat是显示网络状态 half关机
-
下列属于Linux开机启动过程的是:运行第一个进程init(进程号永远为1)读取MBR的引导文件(grub,lilo)引导linux内核,注意不会进入相应的运行级别
-
inode(索引节点):每一个文件都有对应的inode,里面包含了与该文件有关的一些信息,特殊文件(比如乱码文件名)可以通过inode的方式删除, inode节点一般是
128字节或256字节` -
关于bash : 0代表脚本的名称, 0代表脚本的名称,0代表脚本的名称,@代表所有位置参数,KaTeX parse error: Expected 'EOF', got '#' at position 1: #̲ 代表位置参数的数量,(11)代表第11个位置参数的值
$$ Shell本身的PID(ProcessID)
$! Shell最后运行的后台Process的PID
$? 最后运行的命令的结束代码(返回值)
$- 使用Set命令设定的Flag一览
∗ 所 有 参 数 列 表 。 如 " * 所有参数列表。如" ∗所有参数列表。如"*“用「”」括起来的情况、以"$1 $2 … $n"的形式输出所有参数。
@ 所 有 参 数 列 表 。 如 " @ 所有参数列表。如" @所有参数列表。如"@“用「”」括起来的情况、以"$1" “ 2 " … " 2" … " 2"…"n” 的形式输出所有参数。
$# 添加到Shell的参数个数
$0 Shell本身的文件名
1 ~ 1~ 1~n 添加到Shell的各参数值。$1是第1参数、$2是第2参数…。 -
TRUNCATE TABLE(清空数据,删除重建表)和DELETE的区别:
1. truncate 是删除表再创建,delete 是逐条删除
2. truncate 重置auto_increment的值。而delete不会
3. truncate 不知道删除了几条,而delete知道
4. 当被用于带分区的表时,truncate 会保留分区 -
TCP协议运行时阶段:创建、传输、终止
-
超文本传输安全协议(HTTPS):非对称加密和对称加密都使用了。 HTTPS是在HTTP的基础上增加了SSL层,服务器和客户端传输数据前先采用非对称加密算法生产一个秘钥,再用这个秘钥使用对称加密算法加密要传输的数据,这样做即保证了秘钥的安全,又提高了数据加密效率。
-
守护线程:
- 任何一个非守护线程(用户线程)没有结束,守护线程就全部工作
- 当最后一个非守护线程结束时,守护线程随着JVM一同结束工作
- GC是守护线程
- 守护线程产生的新线程也是守护线程
-
public修饰接口,final可以修饰接口中的变量为常量
-
老板一共需要给某个员工发奖金n元,可以选择一次发1元,也可以选择一次发2元,也可以选择一次发3元。请问老板给这位员工发放完n元奖金共有多少种不同的方法?
数据范围:1 <= n <= 10
//满足递归f(n) = f(n-1) + f(n-2) + ... + f(1) + 1public class GiveMoney {public static void main(String[] args){Scanner scanner = new Scanner(System.in);System.out.print("输入要发的奖金");int number = scanner.nextInt();System.out.println ("您有" + give (number) + "种方法发完" + number + "元奖金!!"); }/ * 获取发奖金的方法个数 * @param number * @return */public static int give(Integer number) {if(number == 1) return 1;int count = 0;for(int i = number - 1; i >= 1; i--) {count = give(i) + count;}return count + 1;}} -
/ * 撤销 * @author: William * @time:2022-05-16 *//* * 撤销/恢复操作具有广泛的用途,比如word文档中输入一个单词,可以点撤销,然后可以再恢复。编程实现如下功能: 从标准输入读取到一个字符串,字符串可包含0个或多个单词,单词以空格或者tab分隔; 如果遇到 "undo" 字符串,表示"撤销"操作,前一个字符串被撤销掉; 如果遇到"redo"字符串,表示恢复刚才撤销掉的字符串.例如: 输入字符串 "hello undo redo world.", 对字符串中的 undo 和 redo 处理后, 最终输出的结果为 "hello world." */public class Revocation {/* * 先初始化两个栈stack和redo,然后利用双栈求解。遍历词表:遇到普通词就压入stack,并清空redo栈,因为此时写入了一个新词,再往前的词已经找不回来了;遇到undo就从stack中弹栈至redo;遇到redo就从redo中弹栈至stack。最终stack中的词就是最后保留下来的词 */public static void main(String[] args) {Scanner sc = new Scanner(System.in); String str=sc.nextLine(); Stack stack=ctrlZ1(str); System.out.println(String.join(" ", stack)); }public static Stack ctrlZ1(String str) {Stack<String> stack = new Stack<>();Stack<String> redoStack = new Stack<>();List<String> list = new ArrayList<>(Arrays.asList(str.replace("\t", " ").split(" ")));for(int i = 0; i < list.size(); i++) {if("undo".equals(list.get(i))) {if(!stack.isEmpty()) {redoStack.push(stack.pop());}}else if("redo".equals(list.get(i))) {if(!redoStack.empty()) {stack.push(redoStack.pop());}}else {redoStack.clear();stack.push(list.get(i));}}return stack;}}
2020秋招-2
-
如何判定一个头指针为head的带头结点的单链表为空表 -> head->next==null
-
对于顺序存储的有序表(1,2,3,4,5,6,7,8,9),若采用折半查找查找元素4,需要查 4 次
向下取整 (right-left) >> 1;折半查找也称二分查找。
首先,假设表中元素是按升序排列,将表中间位置记录的关键字与查找关键字比较,如果两者相等,则查找成功;否则利用中间位置记录将表分成前、后两个子表,如果中间位置记录的关键字大于查找关键字,则进一步查找前一子表,否则进一步查找后一子表。重复以上过程,直到找到满足条件的记录,使查找成功,或直到子表不存在为止,此时查找不成功。
- redis在的有序集合中在数据量极少的情况下使用 压缩表
redis的数据类型都是通过多种数据结构来实现,主要是出于时间和空间的考虑,当数据量小的时候通过数组下标访问最快,占用内存最小【压缩列表是数组的变种,允许存储的数据大小不同】
-
HashMap与HashTable的区别
底层数据结构不同:jdk1.7底层都是数组+链表,但jdk1.8 HashMap加入了红黑树
Hashtable 是不允许键或值为 null 的,HashMap 的键值则都可以为 null。
添加key-value的hash值算法不同:HashMap添加元素时,是使用自定义的哈希算法,而HashTable是直接采用key的hashCode()
实现方式不同:Hashtable 继承的是 Dictionary类,而 HashMap 继承的是 AbstractMap 类。
初始化容量不同:HashMap 的初始容量为:16,Hashtable 初始容量为:11,两者的负载因子默认都是:0.75。
扩容机制不同:当已用容量>总容量 * 负载因子时,HashMap 扩容规则为当前容量翻倍,Hashtable 扩容规则为当前容量翻倍 +1。
支持的遍历种类不同:HashMap只支持Iterator遍历,而HashTable支持Iterator和Enumeration两种方式遍历
迭代器不同:HashMap的迭代器(Iterator)是fail-fast迭代器,而Hashtable的enumerator迭代器不是fail-fast的。所以当有其它线程改变了HashMap的结构(增加或者移除元素),将会抛出ConcurrentModificationException,但迭代器本身的remove()方法移除元素则不会抛出ConcurrentModificationException异常。但这并不是一个一定发生的行为,要看JVM。而Hashtable 则不会。
部分API不同:HashMap不支持contains(Object value)方法,没有重写toString()方法,而HashTable支持contains(Object value)方法,而且重写了toString()方法
同步性不同: Hashtable是同步(synchronized)的,适用于多线程环境,
而hashmap不是同步的,适用于单线程环境。多个线程可以共享一个Hashtable;而如果没有正确的同步的话,多个线程是不能共享HashMap的。 -
进程与线程:
- 进程间切换比线程间切换开销大
- 进程是系统进行资源分配和调度的一个独立单位
- 线程可以与同一个进程的其他的线程共享进程所拥有的全部资源
-
ctime 可以得到系统当地时区的时间
-
监听 80端口 需要root权限
-
使用 代理服务器 的客户端可以不配置DNS就可以访问web界面
-
//以下代码执行的结果显示是多少public class Test{ public static void main(String [] args){ int count = 0; int num = 0; for(int i = 0;i <=100;i++){ num = num + i; count = count++; } System.out.println(num*count); }}// 0 count=count++;就是一直把0赋给count -
jvm 使用 unicode 表示
-
关于符号连接与硬连接的说法,正确的是:创建符号连接时,将创建一个inode;删除硬连接源文件后,连接文件还可以继续访问
Linux中包括两种链接:硬链接(Hard Link)和软链接(Soft Link),软链接又称为符号链接(Symbolic link)。
硬链接
硬链接是文件的别名。从技术上讲,他们公用一个inode(inode中包含了一个文件的所有必要的信息,说inode就是文件也是没有问题的)。
由于linux下的文件是通过索引节点(Inode)来识别文件,硬链接也可以认为是一个指向文件索引节点的指针,系统并不为它重新分配inode,
每添加一个一个硬链接,文件的链接数就加1, 删除一个则链接数减1。
大多数系统不允许创建一个目录的硬链接。在允许创建目录硬链接的系统上,只有超级用户才能才能这样做。
不能创建跨文件系统(分区)的硬链接(这些限制在POSIX中都不是强制性的)。
软链接(符号链接) 软链接是一种特殊的文件类型,其中包含对另一个 文件/目录 以 绝对/相对 路径形式的引用. 软链接可以看做是对一个文件的间接指针,相当于windows下的快捷方式。软链接没有任何文件系统的限制,任何用户可以创建指向 文件/目录 的符号链接。甚至可以跨越不同机器、不同网络对文件进行链接。创建文件的软链接时,软链接会使用一个新的inode,所以软链接的inode号和文件的inode号不同(表明他们是两个不同的文件),软链接的inode里存放着指向文件的路径,删除源文件,软链接也无法使用了,因为文件的路径不存在了;删除软链接对原文件没有任何影响。当我们再次创建这个文件时(文件名与之前的相同),软链接又会重新指向这个文件(inode号与之前的不同了),而硬链接不会受其影响.当然软链接也有硬链接没有的缺点,因为链接文件包含有原文件的路径信息,所以当原文件从一个目录下移到其他目录中,再访问链接文件,系统就找不到了,而硬链接就没有这个缺陷,你想怎么移就怎么移;还有它要系统分配额外的空间用于建立新的索引节点和保存原文件的路径。
-
避免 死锁 的一个著名算法是 银行家算法
-
可重复读不可能发生:脏读、不可重复读,但是会发生幻读
READ UNCOMMITED(未提交读)
在RERAD UNCOMMITED级别,事务中的修改,即使没有提交,对其他事务也都是可见的。事务可以读取未提交的数据,这也成为脏读(Dirty Read)。这个级别会导致很多问题,从性能上说READ UNCOMMITED 不会比其他的级别好太多,但缺乏其他级别的好多好处,除非有非常必要的理由,在实际的应用中一般很少使用READ UNCOMMITED.
READ COMMITED (提交读)
大多数数据库系统的默认隔离级别都是READ COMMITED (但是MYSQL不是)。READ COMMITED 满足前面提到的隔离性的简单定义:一个事务开始时,只能看到已经提交的事务所做的修改。换句话说,一个事务从开始到提交之前,所做的任何修改对其他事务都 是不可见的。这个级别有时候也叫做不可重复的(nonerepeatable read),因为两次执行同样的查询,可能会得到不一样的结果。
REPEATABLE READ (可重复读)
REPEATABLE READ (可重复读) 解决了脏读问题。该级别保证了在同一个事务中多次读取同样的记录的结果是一致的。但是,理论上,可重复读隔离级别还是无法解决另一个幻读 (PhantomRead)的问题。所谓幻读,指的是当某个事务在读取某个范围内的记录时,另外一个事务又在该范围内插入了新的记录,当之前的事务再次读 取该范围的记录时,会产生幻行(Phantom Row)。InnoDB和XtraDB 存储引擎通过多版并发控制(MVCC ,Multivesion Concurrency Control )解决了幻读问题。
可重复读是Mysql 默认的事务隔离级别。
SERIALIZABLE(可串行化)
SERIALIZABLE是最高的隔离级别。它通过强制事务串行,避免了前面说的幻读问题。简单的来说,SERIALIZABLE会在读的每一行数据上 都加上锁,所以可能导致大量的超时和锁征用问题。实际应用中也很少用到这个隔离级别,只有在非常需要确保数据的一致性而且可以接受没有并发的情况,才可考 虑用该级别。
隔离级别 脏读可能性 不可重复读可能性 幻读可能性 加锁读
READ UNCOMMITED YES YES YES NO
READ COMMITED NO YES YES NO
REPEATABLE READ NO NO YES NO
SERIALIZABLE NO NO NO YES14
-
B+ Tree索引与Hash索引相比较
Hash索引和B+tree索引的区别
1、在查询速度上,如果是等值查询,那么Hash索引明显有绝对优势,因为只需要经过一次 Hash 算法即可找到相应的键值,复杂度为O(1);当然了,这个前提是键值都是唯一的。如果键值不是唯一(或存在Hash冲突),就需要先找到该键所在位置,然后再根据链表往后扫描,直到找到相应的数据,这时候复杂度会变成O(n),降低了Hash索引的查找效率。所以,Hash 索引通常不会用到重复值多的列上,比如列为性别、年龄的情况等(当然B+tree索引也不适合这种离散型低的字段上);
2、Hash 索引是无序的,如果是范围查询检索,这时候 Hash 索引就无法起到作用,即使原先是有序的键值,经过 Hash 算法后,也会变成不连续的了。因此
①、Hash 索引只支持等值比较查询、无法索成范围查询检索,B+tree索引的叶子节点形成有序链表,便于范围查询。
②、Hash 索引无法做 like ‘xxx%’ 这样的部分模糊查询,因为需要对 完整 key 做 Hash 计算,定位bucket。而 B+tree 索引具有最左前缀匹配,可以进行部分模糊查询。
③、Hash索引中存放的是经过Hash计算之后的Hash值,而且Hash值的大小关系并不一定和Hash运算前的键值完全一样,所以数据库无法利用索引的数据来避免任何排序运算。B+tree 索引的叶子节点形成有序链表,可用于排序。
3、Hash 索引不支持多列联合索引,对于联合索引来说,Hash 索引在计算 Hash 值的时候是将索引键合并后再一起计算 Hash 值,不会针对每个索引单独计算 Hash 值。因此如果用到联合索引的一个或者几个索引时,联合索引无法被利用;
4、因为存在哈希碰撞问题,在有大量重复键值情况下,哈希索引的效率极低。B+tree 所有查询都要找到叶子节点,性能稳定;
-
Linux系统下,可以用 netstat 命令查看系统端口的占用情况
-
truncate table可以删除全部记录,truncate比delete快
-
下列两个语句是正确的
Stream.generate(Math::random);Stream.of(1,2,3,4); -
Semaphore 属于 内核锁
1、mutex(互斥信号量)
mutex_init(&mutex);
mutex_lock(&mutex);、mutex_unlock(&mutex);
2、semaphore (信号量)
void sema_init (struct semaphore *sem, int val);
void down(struct semaphore * sem);
int down_interruptible(struct semaphore * sem);
void up(struct semaphore * sem);
3、rw_semaphore (读写信号量)
void init_rwsem(struct rw_semaphore *sem);
void down_read(struct rw_semaphore *sem);
void down_write(struct rw_semaphore *sem);
void up_read(struct rw_semaphore *sem);
void up_write(struct rw_semaphore *sem);
4、Spanlock(自旋锁)
spin_lock_init(x)、DEFINE_SPINLOCK(x)、SPIN_LOCK_UNLOCKED
spin_is_locked(x)、spin_unlock_wait(x)、spin_trylock(lock)
spin_lock(lock)、spin_unlock(lock)
spin_lock_irqsave(lock, flags)、spin_unlock_irqrestore(lock, flags)
spin_lock_irq(lock)、spin_unlock_irq(lock)
spin_lock_bh(lock)、spin_unlock_bh(lock)
spin_trylock_irqsave(lock, flags)
spin_trylock_irq(lock)
5、seqlock(顺序锁)
6、rwlock (读写锁)
rwlock_init(x)
read_trylock(lock)
write_trylock(lock)
read_lock_irqsave(lock, flags)
write_lock_irqsave(lock, flags)
read_unlock_irqrestore(lock, flags)
write_unlock_irqrestore(lock, flags)
7、RCU(read-copy-update)
8、BKL(大内核锁) // to be deleted
-
以下哪些是TCP连接断开过程中出现的状态? TIME_WAIT LAST_ACK FIN_WAIT_1,然后SYNC_RCVD不是
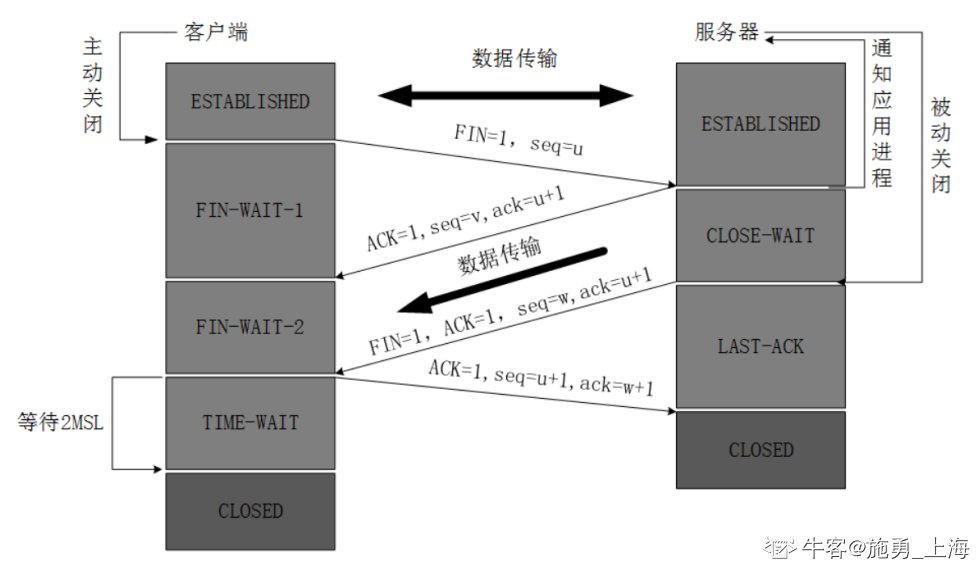
-
TCP四次挥手里会出现的报文:ACK FIN
-
关于高级运算符
UNION 运算符通过组合其他两个结果表(例如 TABLE1 和 TABLE2)并消去表中任何重复行而派生出一个结果表。当 ALL 随 UNION 一起使用时(即 UNION ALL),不消除重复行。两种情况下,派生表的每一行不是来自 TABLE1 就是来自 TABLE2
EXCEPT 运算符通过包括所有在 TABLE1 中但不在 TABLE2 中的行并消除所有重复行而派生出一个结果表。当 ALL 随 EXCEPT 一起使用时 (EXCEPT ALL),不消除重复行INTERSECT 运算符通过只包括 TABLE1 和 TABLE2 中都有的行并消除所有重复行而派生出一个结果表。当 ALL 随 INTERSECT 一起使用时 (INTERSECT ALL),不消除重复行 -
抓包工具:wireshark、tshark、tcpdump
-
cat、less、more三个指令都能查看文件内容
1、cat 后面跟要查看的文件,文件内容全部输出到屏幕,
2、more 文件内容或输出查看工具;
more 是我们最常用的工具之一,最常用的就是显示输出的内容,然后根据窗口的大小进行分页显示,然后还能提示文件的百分比;
3、less 查看文件内容 工具:
less 工具也是对文件或其它输出进行分页显示的工具,应该说是Linux正统查看文件内容的工具,功能极其强大;您是初学者,我建议您用less。由于less的内容太多,我们把最常用的介绍一下;
-b 设置缓冲区的大小
-e 当文件显示结束后,自动离开
-f 强迫打开特殊文件,例如外围设备代号、目录和二进制文件
-g 只标志最后搜索的关键词
-i 忽略搜索时的大小写
-m 显示类似more命令的百分比
-N 显示每行的行号
-o 将less 输出的内容在指定文件中保存起来
-Q 不使用警告音
-s 显示连续空行为一行
-S 行过长时间将超出部分舍弃
-x 将“tab”键显示为规定的数字空格
/字符串:向下搜索“字符串”的功能
?字符串:向上搜索“字符串”的功能
n:重复前一个搜索(与 / 或 ? 有关)
N:反向重复前一个搜索(与 / 或 ? 有关)关于less的动作
b 向后翻一页
d 向后翻半页
h 显示帮助界面
Q 退出less 命令
u 向前滚动半页
y 向前滚动一行
空格键 滚动一行
回车键 滚动一页4、head 工具,显示文件内容的前几行:
head 是显示一个文件的内容的前多少行;
用法比较简单;
head -n 行数值 文件名;比如我们显示/etc/profile的前10行内容,应该是:
[root@localhost ~]# head -n 10 /etc/profile5、tail 工具,显示文件内容的最后几行:
tail 是显示一个文件的内容的前多少行;
用法比较简单;
tail -n 行数值 文件名;比如我们显示/etc/profile的最后5行内容,应该是:
[root@localhost ~]# tail -n 5 /etc/profiletail -f /var/log/messages
参数-f使tail不停地去读最新的内容,这样有实时监视的效果 用Ctrl+c来终止! -
/ * 最大岛屿数量 * @author: William * @time:2022-04-10 */public class Num200 {class UnionFind{int count;int[] parent;int[] rank;public UnionFind(char[][] grid) {count = 0;int m = grid.length;//行数int n = grid[0].length;//列数parent = new int[m * n];rank = new int[m * n];for(int i = 0; i < m; i++) {for(int j = 0; j < n; j++) {if(grid[i][j] == '1') {parent[i * n + j] = i * n + j;//规律count++;}rank[i * n + j] = 0;}}}public int find(int i) {if(parent[i] != i) parent[i] = find(parent[i]);return parent[i];}public void union(int x, int y) {int rootX = find(x), rootY = find(y);if(rootX != rootY) {if(rank[rootX] > rank[rootY]) {parent[rootY] = rootX;}else if(rank[rootX] < rank[rootY]) {parent[rootX] = rootY;}else {parent[rootY] = rootX;//相等的情况rank[rootX] += 1;}count--;//维护数量}}public int getCount() {return count;}}public int numIslands(char[][] grid) { if (grid == null || grid.length == 0) { return 0; } int nr = grid.length; int nc = grid[0].length; int num_islands = 0; UnionFind uf = new UnionFind(grid); for (int r = 0; r < nr; ++r) { for (int c = 0; c < nc; ++c) { if (grid[r][c] == '1') { grid[r][c] = '0'; if (r - 1 >= 0 && grid[r-1][c] == '1') { uf.union(r * nc + c, (r-1) * nc + c); } if (r + 1 < nr && grid[r+1][c] == '1') { uf.union(r * nc + c, (r+1) * nc + c); } if (c - 1 >= 0 && grid[r][c-1] == '1') { uf.union(r * nc + c, r * nc + c - 1); } if (c + 1 < nc && grid[r][c+1] == '1') { uf.union(r * nc + c, r * nc + c + 1); } } } } return uf.getCount();}//dfs —— 重点掌握public int numIslands1(char[][] grid) {int count = 0;for(int i = 0; i < grid.length; i++) {//行数for(int j = 0; j < grid[0].length; j++) {//列数if(grid[i][j] == '1') {//满足条件就继续递归dfs(grid, i, j);count++;}}}return count;}private void dfs(char[][] grid, int i, int j) {//终止条件if(i < 0 || j < 0 || i >= grid.length || j >= grid[0].length || grid[i][j] == '0') return;grid[i][j] = '0';//走完要归0//分别向上下左右递归dfs(grid, i + 1, j);dfs(grid, i, j + 1);dfs(grid, i - 1, j);dfs(grid, i, j - 1);}//bfspublic int numIslands2(char[][] grid) {int count = 0;for(int i = 0; i < grid.length; i++) {for(int j =0; j < grid[0].length; j++) {if(grid[i][j] == '1') {bfs(grid, i, j);count++;}}}return count;}private void bfs(char[][] grid, int i, int j) {Queue<int[]> list = new LinkedList<>();list.add(new int[] {i, j});while(!list.isEmpty()) {int[] cur = list.remove();i = cur[0]; j = cur[1];if(0 <= i && i < grid.length && 0 <= j && j < grid[0].length && grid[i][j] == '1') {grid[i][j] = '0';list.add(new int[] {i + 1, j});list.add(new int[] {i - 1, j});list.add(new int[] {i, j + 1});list.add(new int[] {i, j - 1});}}}} -
//最长递增子序列class Solution { public int lengthOfLIS(int[] nums) { //dp[i] : 末位为 nums[i] 的 LIS 长度//dp[i] = max(dp[j]) + 1 (0 <= j < i)//ans = max(dp[i]) int[] dp = new int[nums.length]; int ans = 0; for(int i = 0; i < nums.length; i++){ //初始化 dp[i] = 1; for(int j = 0; j < i; j++){ if(nums[i] > nums[j]){ dp[i] = Math.max(dp[i], dp[j] + 1); } } ans = Math.max(ans, dp[i]); } return ans; }}
2020秋招-1
-
192.10.10.10是C类网络地址
1. A类IP地址 一个A类IP地址由1字节的网络地址和3字节主机地址组成,它主要为大型网络而设计的,网络地址的最高位必须是“0”, 地址范围从1.0.0.0 到127.0.0.0)。可用的A类网络有127个,每个网络能容纳1亿多个主机。其中127.0.0.1是一个特殊的IP地址,表示主机本身,用于本地机器的测试。
注:A:0-127,其中0代表任何地址,127为回环测试地址,因此,A类ip地址的实际范围是1-126.默认子网掩码为255.0.0.0
2. B类IP地址 一个B类IP地址由2个字节的网络地址和2个字节的主机地址组成,网络地址的最高位必须是“10”,地址范围从128.0.0.0到191.255.255.255。可用的B类网络有16382个,每个网络能容纳6万多个主机 。
注:B:128-191,其中128.0.0.0和191.255.0.0为保留ip,实际范围是128.1.0.0–191.254.0.0
3. C类IP地址 一个C类IP地址由3字节的网络地址和1字节的主机地址组成,网络地址的最高位必须是“110”。范围从192.0.0.0到223.255.255.255。C类网络可达209万余个,每个网络能容纳254个主机。
注:C:192-223,其中192.0.0.0和223.255.255.0为保留ip,实际范围是192.0.1.0–223.255.254.0
4. D类地址 用于多点广播(Multicast)。 D类IP地址第一个字节以“1 1 1 0”开始,它是一个专门保留的地址。它并不指向特定的网络,目前这一类地址被用在多点广播(Multicast)中。多点广播地址用来一次寻址一组计算机,它标识共享同一协议的一组计算机。224.0.0.0到239.255.255.255用于多点广播 。
5. E类IP地址 以“1 1 1 1 0”开始,为将来使用保留。240.0.0.0到255.255.255.254,255.255.255.255用于广播地址
全零(“0.0.0.0”)地址对应于当前主机。全“1”的IP地址(“255.255.255.255”)是当前子网的广播地址。
-
线程:一个线程被创建,不会立即开始运行;使用start()方法可以使一个线程成为可运行的,但是它不一定立即开始运行,获取CPU才可以执行;当一个线程因为抢先机制而停止运行时,它被放在可运行队列的后面;一个线程可能因为不同的停止原因停止并进入就绪状态
-
Java语言特点:通过虚拟机实现跨平台、致力于检查程序在编译和运行时的错误、自己操纵内存减少了内存出错的可能性。
Java还实现了真数组,避免了覆盖数据的可能。
注意,是避免数据覆盖的可能,而不是数据覆盖类型
真数组定义:- 在内存中连续分配。
- 数组所存在的内存空间为数组专用,避免了数据被覆盖的问题。
- 数组内存放的类型是确定的,唯一的
-
Java中的ClassLoader
Java系统提供3种类加载器:启动类加载器(Bootstrap ClassLoader) 扩展类加载器(Extension ClassLoader) 应用程序类加载器(Application ClassLoader).
《深入理解Java虚拟机》P228:对于任意一个类,都需要由加载它的类加载器和这个类本身一同确立其在Java虚拟机中的唯一性,每一个类加载器,都拥有一个独立的类名称空间。这句话可以表达得更通俗一些:比较两个类是否“相等”,只有在这两个类是由同一个类加载器加载的前提下才有意义,否则,即使这两个类来源于同一个Class文件,被同一个虚拟机加载,只要加载它们的类加载器不同,那么这两个类必定不相等。接口类是一种特殊类,因此对于同一接口不同的类装载器装载所获得的类是不相同的。
类只需加载一次就行,因此要保证类加载过程线程安全,防止类加载多次。
Java程序的类加载器采用双亲委派模型,实现双亲委派的代码集中在java.lang.ClassLoader的loadClass()方法中,此方法实现的大致逻辑是:先检查是否已经被加载,若没有加载则调用父类加载器的loadClass()方法,若父类加载器为空则默认使用启动类加载器作为父类加载器。如果父类加载失败,抛出ClassNotFoundException异常。
双亲委派模型的工作过程:如果一个类加载器收到了类加载的请求,它首先不会自己去尝试加载这个类,而是把这个请求委派给父类加载器去完成,每一个层次的类加载器都是如此,因此所有的加载请求最终都应该传送到顶层的启动类加载器中,只有当父加载器反馈自己无法完成这个加载请求时,子加载器才会尝试自己去加载。
应用程序类加载器(Application ClassLoader)负责加载用户类路径(ClassPath)上所指定的类库,不是所有的ClassLoader都加载此路径。
-
在fork出的进程中执行exec系列函数,不一定会继承的资源是 打开文件的fd
-
Linux防火墙:iptables和firewalld都是Linux上管理防火墙规则的工具;因为iptables会对一个请求遍历每个规则,直到遇到匹配的规则,所以规则顺序很重要
是数据包进入主机的第一道关卡。主要通过Netfilter和TCPwarppers两个机制进行管理。
Netfilter:数据包过滤机制
TCP Warappers:程序管理机制
关于数据包过滤机制有两个软件firewalld和iptables。
- firewalld提供了一个动态管理的具备IP v4和IP v6的设置和支持。
- iptables通过控制端口来控制服务,firewalld通过控制协议来控制端口。
-
exit 命令可以退出交互式shell
-
缓冲技术 主要用于 提高主机和设备交换信息的速度
-
一个进程释放一种资源将有可能导致一个或多个进程 由阻塞变就绪
-
业界流行的分布式一致性协议:
弱一致性:
最终一致性:DNS、Gossip协议等
强一致性:
同步、Paxos、Raft、ZAB
-
您有一个名为Customer的表。您需要添加一个名为District的新列 应该使用
ALTER TABLE Customer ADD (District INTEGER) -
要授予用户读取表中数据的权限 使用 GRANT SELECT
-
char 与 varchar
char(n) 若存入字符数小于n,则以空格补于其后,查询之时再将空格去掉。所以char类型存储的字符串末尾不能有空格,varchar不限于此
char(n)固定长度,char(4)不管是存入几个字符,都将占用4个字节,varchar是存入的实际字符数+1个字节(n255),所以varchar(4),存入3个字符将占用4个字节
char类型的字符串检索速度要比varchar类型的快
varchar可指定n,text不能指定,内部存储varchar是存入的实际字符数+1个字节(n255),text是实际字符数+2个字节
-
72.16.192.9/26 的计算出的IP地址范围是 172.16.192.0-172.16.192.63

-
下面不属于应用层的协议是 ICMP
-
关于Annotation:是一个接口;可以被继承;可用于编译检查;使用@interface关键字定义
-
get filter of 都是Optional类的方法
-
关于Http状态码:
2XX表示请求成功
3XX表示服务器端重定向请求资源以完成请求
4XX表示客户端错误,或者请求的服务端资源不存在
5XX表示服务端错误 -
TCP作为面向流的协议,提供可靠的、面向连接的运输服务,并且提供点对点通信
UDP作为面向报文的协议,不提供可靠交付,并且不需要连接,不仅仅对点对点,也支持多播和广播 -
关于函数的参数传递
> 传值时函数内部对值的修改并不会引发外部值的变化> 传指针时能修改指针指向的对象> 传引用时函数内部对值的改变会引发外部值的改变> 无论传值传引用还是传指针,传递的都是一份拷贝> Java中传递引用数据类型的时候也是值传递。参数的地址值没有变。 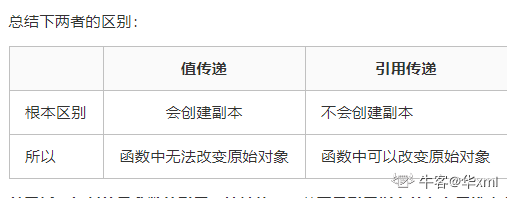 -
关于线程安全的说法:可重入函数一定是线程安全函数;线程安全函数可以依赖于单一资源的锁
经常会出现多个任务调用同一个函数的情况。如果有一个函数不幸被设计成为这样:那么不同任务调用这个函数时可能修改其他任务调用这个函数的数据,从而导致不可预料的后果。这样的函数是不安全的函数,也叫不可重入函数
一个可重入的函数简单来说就是可以被中断的函数,也就是说,可以在这个函数执行的任何时刻中断它,转入OS调度下去执行另外一段代码,而返回控制时不会出现什么错误;而不可重入的函数由于使用了一些系统资源,比如全局变量区,中断向量表等,所以它如果被中断的话,可能会出现问题,这类函数是不能运行在多任务环境下的。
-
聚簇索引:将数据 按照索引的顺序排列,使得存储进去的数据是非逻辑性的排列,类似于字典;查找快,增删改比较复杂 索引的叶子节点就是对应的数据节点,索引与数据没有分开放
-
HTTP请求方式中的请求方法:HEAD、CONNECT、OPTIONS、TRACE
-
/ * 200以内正整数的阶乘 * @author: William * @time:2022-05-17 */public class Factorial {//动态规划思想//状态转移方程:dp[i] = dp[i - 1] * (i + 1)public static void main(String[] args) {Scanner sc = new Scanner(System.in);int n = sc.nextInt();if(n >= 1 && n <= 200) {BigInteger[] dp = new BigInteger[n];dp[0] = BigInteger.valueOf(1);dp[1] = BigInteger.valueOf(2);for(int i = 2; i < n; i++) {dp[i] = BigInteger.valueOf(i + 1).multiply(dp[i - 1]);}System.out.println(dp[n - 1]);}else {System.out.println("Error");}}} -
/ * 最大路径和 * @author: William * @time:2022-05-17 *//* * 有一个m*n 的网格,在每个格子上有一个非0 整数。 * 你每次只能向下或者向右移动一格,求你从左上角移动到最右下角,路径上数字和的最大值。 实例1:[ [2,3,1], [2,5,3], [4,2,1]]输出:14解释:2->3->5->3->1 路径和的最大值 */public class MaxValue {//思路:原地dp //转移方程:f(i, j) = f(i - 1, j) + f(i, j - 1);public int maxValue(int[][] matrix) {int m = matrix.length, n = matrix[0].length;for(int i = 1; i < m; i++) {matrix[i][0] += matrix[i - 1][0];}for(int j = 1; j < n; j++) {matrix[0][j] += matrix[0][j - 1];}for(int i = 1; i < m; i++) {for(int j = 1; j < n; j++) {matrix[i][j] += Math.max(matrix[i - 1][j], matrix[i][j - 1]);}}return matrix[m - 1][n - 1];}}
2021春招-1
-
RSTP边缘端口的作用及特性
-
边缘端口收到BPDU时会失去边缘端口的角色状态,重新参与生成树选举
-
边缘端口在P/A机制中不受SYNC同步的影响,不会阻塞端口
-
边缘端口UP之后可以快速进入forwarding状态,不需要等待30s的转发时延
-
ASBR Summary LSA 是由 ABR路由器 产生的
-
IPv4 最大支持的报文字节数为 65535
-
Truncate会删除表中的所有数据;delete删除后表结构还在;Drop会从数据库中删除表,所有的数据行;
delete语句为DML( Data Manipulation Language ),这个操作会被放到 rollback segment中,事务提交后才生效。如果有相应的 tigger,执行的时候将被触发。
truncate、drop是DLL(data define language),操作立即生效,原数据不放到 rollback segment中,不能回滚
-
mysql中的简化操作视图是很好的简化对象,可以操作的是 查看,存放(视图的本质是表,表作用就是查看和存放数据)
-
一个进程从执行状态转换到阻塞状态的可能原因是本进程 需要等待其他进程的执行结果,执行了P操作
运行态:进程占用CPU,并在CPU上运行;
就绪态:进程已经具备运行条件,但是CPU还没有分配过来;运行—>就绪: 时间片用完。
就绪—>运行:运行的进程的时间片用完,调度就转到就绪队列中选择合适的进程分配CPU
运行—>阻塞:发生了I/O请求或等待某件事的发生
阻塞—>就绪:进程所等待的事件发生,就进入就绪队列P操作是阻塞作用
V操作是唤醒作用 -
二叉树是一种逻辑结构,与数据的存储结构无关
-
对于JVM内存配置参数:-Xmx10240m -Xms10240m -Xmn5120m -XXSurvivorRatio=3, 其最小内存值和Survivor区总大小分别是(10240m, 2048m)
-Xms:初始堆大小。
-Xmn:堆内存的年轻代大小,堆内存最大值和年轻代的差值就是老年代的大小。-XX:NewSize=n:设置年轻代大小-XX:NewRatio=n 设置年轻代和年老代的比值。如n为2,表示年轻代与年老代比值为1:2,年轻代占整个年轻代年老代和的1/3。-XX:SurvivorRatio=n年轻代中Eden区与两个Survivor区的比值,注意Survivor区有两个。如n为3,表示Eden:Survivor=3:2,一个Survivor区占整个年轻代的1/5。
所以本题中内存值为10240m
survivor=5120/5*2=2048m【3:2,年轻代总量5120】
-
Map是接口,所以不能实例化
-
已知二叉树的后序遍历序列是cefdbga,中序遍历序列是cbedfag,它的层序遍历序列是 abgcdef(到时候再确定一下)
-
循环队列的队满条件 (ring.end+1)%maxsize == ring.front
-
进程间通信效率最高的方式是 共享内存
-
export 查看并设置环境变量;cat 显示指定文件的全部内容; echo 输出字符串; env 看环境变量
-
关于范式的说法:
有关系模式R(A,B,C,D,E,F),函数依赖集F={(A,B)→E,(A,C)→F,(A,D)→B,B→C,C→D},则(A、C)是R的候选码;第二范式是完全依赖,消除了部分依赖 -
项目表中虽然设置索引,但是效果不是很明显,问题可能是 :where中索引列有计算;复合索引未使用左列字段
-
对象序列化:使用ObjectOutputStream类完成对象存储,使用ObjectInputStream类完成对象读取
对象序列化的所属类需要实现Serializable接口 -
& nohup & ctrl+z 命令可以让前台进程转为后台执行
-
零拷贝:零拷贝技术可以有效缓解Linux I/O 性能问题,避免用户态和内核态的频繁切换
Linux中的Sendfile是只发生在内核态的数据传输接口,没有用户态的参与,自然避免了用户态数据拷贝 -
关于同步异步,阻塞与非阻塞:
- 同步和异步关注的是消息通信机制
- 阻塞和非阻塞关注的是程序在等待调用结果时的状态
- 异步操作后,可以不使用回调函数来获取操作结果
- 非阻塞操作,必定是异步的
-
一个网段150.25.0.0 的子网掩码是255.255.224.0,那么(150.25.3.25/150.25.30.30)是该网段中有效的主机地址 (不理解)
-
关于IGMPv1 和IGMPv2 (一脸懵逼)
IGMP三个版本的比较项目 IGMPv1 IGMPv2 IGMPv3 查询器选举方式 依靠组播路由协议 PIM选举 同网段组播路由器之间竞争选举 同网段组播路由器之间竞争选举 普遍组查询报文 支持 支持 支持 成员报告报文 支持 支持 支持 特定组查询报文 不支持 支持 支持 成员离开报文 不支持 支持 没有定义专门的成员离开报文,成员离开通过特定类型的报告报文来传达 特定源组查询报文 不支持 不支持 支持 指定组播源 不支持 不支持 支持 可识别报文协议版本 IGMPv1 IGMPv1、IGMPv2 IGMPv1、IGMPv2、IGMPv3 ASM模型 支持 支持 支持 SSM模型 需要IGMP SSM Mapping技术支持 需要IGMP SSM Mapping技术支持 -
/ * 能参加的最多会议数 * @author: William * @time:2022-05-17 */public class MaxMeeting {public int AttendMeetings(int[][] times) {Arrays.sort(times, (a, b) -> a[1] - b[1]);int count = 0, end = 0;for(int i = 0; i < times.length; i++) {if(end <= times[i][0]) {count++;end = times[i][1];//时间往后推}}return count;}/* * 复杂度分析 *排序时间复杂度O(nlogn),遍历时间复杂度O(n), *因此算法的瓶颈在于排序,整体时间复杂度为O(nlogn)。 *遍历过程仅使用了有限几个变量,因此空间复杂度为O(1),但由于是对引用类型排序, *因此内部使用归并排序,空间复杂度为O(n),算法整体的空间复杂度为O(n)。 */} -
/ * 黄金瞳 * @author: William * @time:2022-05-17 *//* * 小庄在一次机缘巧合的机会,眼睛获取了黄金瞳, * 黄金瞳的功能是可以看到m种物品10天以后的价格。 * 但是这些物品属于限购物资,最多只能购买一定的数量。 * 现在小庄有资金x可以投资这些物品,如何操作才能实现10天后资产价值最大。 * * 这个题思路并不难,从左往右进行暴力递归的尝试, * 写出递归逻辑后就可以改成记忆化搜索或者动态规划 */class Item { public int limit; public int cur; public int future; public Item(int limit){ this.limit = limit; }}public class MyPackage {public static void main(String[] args) {Scanner sc = new Scanner(System.in);int x = sc.nextInt();int m = sc.nextInt();Item[] items = new Item[m];for(int i = 0; i < m; i++) {items[i] = new Item(sc.nextInt());}for(int i = 0; i < m; i++){ items[i].cur = sc.nextInt(); } for(int i = 0; i < m; i++){ items[i].future = sc.nextInt(); } int[][] dp = new int[m][x + 1]; System.out.println(Math.max(x, dfs(items, 0, x, dp)));}private static int dfs(Item[] items, int index, int rest, int[][] dp) { if(index == items.length || rest < items[index].cur){ // 钱不够或物品到头了,后面都无法再产生收益,直接返回剩下的钱 return rest; } if(dp[index][rest] > 0){ return dp[index][rest]; } // 不选当前物品 int p1 = dfs(items, index + 1, rest, dp); // 选当前物品 int p2 = 0; for(int nums = 0; nums <= items[index].limit && nums * items[index].cur <= rest; nums++){ p2 = Math.max(p2, nums * items[index].future + dfs(items, index + 1, rest - nums * items[index].cur, dp)); } dp[index][rest] = Math.max(p1, p2); return dp[index][rest]; }}
2021春招-2
- IP数据报操作特点 :每个分组自身携带有足够的信息,它的传送是被单独处理的;在整个传送过程中,不需建立虚电路;网络节点要为每个分组做出路由选择
数据报是通过网络传输数据的基本单元,包含报头和数据本身,其中报头描述了数据的目的地址及与其他数据 之间的关系。
在数据操作方式中,每个数据报自身携带足够的信息,它的传送是被单独处理的。 整个数据传送过程中,不需要建立虚电路,网络节点为每个数据报作路由选择,各数据报不能保证按顺序到达目的节点,有些还可能丢失
-
对于路由表 在缺省的情况下,如果一台路由器同时运行了RIP和OSPF两种动态路由协议,则在路由表中只会显示OSPF发现的路由,因为OSPF协议的优先级更高
所有的动态路由协议在TCP/IP协议栈中都属于应用层的协议。但是不同的路由协议使用的底层协议不同。
OSPF将协议报文直接封装在IP报文中,协议号89,由于IP协议本身是不可靠传输协议,所以OSPF传输的可靠性需要协议本身来保证。
BGP使用TCP作为传输协议,提高了协议的可靠性,TCP的端口号是179。
RIP使用UDP作为传输协议,端口号520。IS-IS协议是开放系统互联(OSI)协议中的网络层协议,IS-IS协议基础是CLNP(Connectionless Network Protocol,无连接网络协议)
-
在DNS的资源记录的是 表示主机名到IP地址的映射
-
用户不能在包括GROUP BY子句的视图上执行任何DML操作
-
关于SQL优化:(需要注意的是:具体SQL具体分析,不一定join就比子查询快)
-
类似分页功能的SQL,可以先用主键关联,然后返回结果集,会提高效率;
-
多表联接查询时,关联字段类型尽量一致,并且都要有索引;
-
使用TEXT/BLOB类型建议拆分到子表中,不要和主表放在一起,避免SELECT*的时候读性能太差
-
在单处理机计算机系统中,多道程序的执行具有(程序执行宏观上并行、微观上串行、设备和处理机可以并行( 通道技术可以实现I/O设备与CPU并行 ))的特点
1、多道:即计算机内存中同时存放几道相互独立的程序。
2、宏观上并行:同时进入 系统的几道程序都处于运行过程中,即它们先后开始了各自的运行,但都未运行完毕。
3、微观上串行:从微观上看,内存中的多道程序轮流地或分时地占有处理机。
-
可抢占式静态优先数算法 可能引起进程长时间得不到运行
因为静态优先算法,不管是可抢占的还是不可抢占的,都会发生饥饿的现象,因为优先级低得进程会长时间得不到运行。
为了解决静态优先算法的问题,所谓动态是指:在创建进程时所赋予的优先权,是可以随进程的推进或随其等待时间的增加而改变的,以便获得更好的调度性能。
-
有 3 个节点的二叉树有 5 种形态 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-s5ncpPZI-1652960693476)(C:\Users\22529\AppData\Roaming\Typora\typora-user-images\1652778019703.png)]
-
abstract不能与final并列修饰同一个类;abstract类中可以有private成员;abstract方法必须在abstract类中;static方法不能处理非static的属性(静态方法,只能调用静态资源,但是静态方法中创建了对象,此对象可以调用非静态属性)
-
给定的一组权值(2,4,5,9) ,构造 huffman 树,该树的带权外部路径长度为 37
>1.从小到大进行排序, 将每一个数据,每个数据都是一个节点 , 每个节点可以看成是一颗最简单的二叉树>2.取出根节点权值最小的两颗二叉树>3.组成一颗新的二叉树, 该新的二叉树的根节点的权值是前面两颗二叉树根节点权值的和>4.再将这颗新的二叉树,以根节点的权值大小 再次排序, 不断重复 1-2-3-4 的步骤,直到数列中,所有的数据都被处理,就得到一颗赫夫曼树>>构建哈夫曼树,先合并最小的权值2和4得到节点6,然后合并最小的5和6得到节点11,最后合并11和9得到根节点20。2和4到根节点有3条边,5到根节点有2条边,9到根节点有1条边,带权路径长度为:(2+4)×3+5×2+9×1=37 -
红黑树特征:每个红色结点的两个子结点都是黑色;根节点是黑色;每个叶子节点都是NIL,颜色为黑色;从一个节点到该节点的子孙节点的所有路径上包含相同数目的黑节点
-
在一个具有n个单元的顺序栈中,假定以地址低端(即0单元)作为栈底,以top作为栈顶指针,当做出栈处理时,top变化为 top–
-
二叉树 最大节点数计算方法,(2n)-1个节点,每层最大节点数2n-1;
-
新建目录的连接数为2;块设备文件主要指存储设备;脚本文件实际是经过组织的多个可执行文件的有序集合
-
在Linux系统下,如下的几项中,与其它类型不一样的是 (D)
A. fopen() B.printf() C.malloc() D.open()
open是linux下的底层系统调用函数,fopen与freopen c/c++下的标准I/O库函数,带输入/输出缓冲 -
Linux DBUS :DBUS是一种低延迟、低开销、高可用的进程间通信机制;支持进程一对一和多对多的通信;提供一种高效的进程间通信机制,主要用于进程间函数调用以及进程间信号广播;使用二进制协议
-
DECLARE CURSOR 可以用来申明游标
-
关于FTP:采用主动模式传输还是采用被动模式传输由客户端决定;客户端在在私网,穿越单nat场景下,如果不开启alog功能,只有被动模式才可以正常建立数据连接;客户端和服务端都在私网,穿越双nat场景下,如果不开启alg功能,只有主动模式可以正常建立数据连接
-
网际控制报文协议(ICMP):ICMP封装在IP数据报的数据部分;ICMP属于网络层的协议;ICMP是IP协议的必须的一个部分;ICMP可以用来进行拥塞控制
-
drop table在什么场景下使用 删除速度快,不可带where
-
视图:视图可以和表一起使用;为了创建视图,必须具有足够的访问权限;更新视图可以先用DROP再用CREATE;视图不能有关联的触发器
-
在类方法中调用本类的类方法时可直接调用
-
Java语言中的方法必定隶属于某一类(对象),调用方法与过程或函数相同; Java中 静态方法是类成员 非静态方法是实例成员
-
关于makefile:makefile文件保存了编译器和连接器的参数选项;主要包含了五个东西:显示规则、隐晦规则、变量定义、文件指示和注释;默认的情况下,make命令会在当前目录下按顺序找寻文件名为"GNUmakefile"、“makefile”、“Makefile”的文件, 找到了解释这个文件
makefile文件保存了编译器和连接器的参数选项,还表述了所有源文件之间的关系(源代码文件需要的特定的包含文件,可执行文件要求包含的目标文件模块及库等).创建程序(make程序)首先读取makefile文件,然后再激活编译器,汇编器,资源编译器和连接器以便产生最后的输出,最后输出并生成的通常是可执行文件.创建程序利用内置的推理规则来激活编译器,以便通过对特定CPP文件的编译来产生特定的OBJ文件.
Makefile里主要包含了五个东西:显式规则、隐晦规则、变量定义、文件指示和注释。
1、显式规则。显式规则说明了,如何生成一个或多的的目标文件。这是由Makefile的书写者明显指出,要生成的文件,文件的依赖文件,生成的命令。 2、隐晦规则。由于我们的make有自动推导的功能,所以隐晦的规则可以让我们比较粗糙地简略地书写Makefile,这是由make所支持的。
3、变量的定义。在Makefile中我们要定义一系列的变量,变量一般都是字符串,这个有点你C语言中的宏,当Makefile被执行时,其中的变量都会被扩展到相应的引用位置上。
4、文件指示。其包括了三个部分,一个是在一个Makefile中引用另一个Makefile,就像C语言中的include一样;另一个是指根据某些情况指定Makefile中的有效部分,就像C语言中的预编译#if一样;还有就是定义一个多行的命令。有关这一部分的内容,我会在后续的部分中讲述。
5、注释。Makefile中只有行注释,和UNIX的Shell脚本一样,其注释是用“#”字符,这个就像C/C++中的“//”一样。如果你要在你的Makefile中使用“#”字符,可以用反斜框进行转义,如:“#”。
默认的情况下,make命令会在当前目录下按顺序找寻文件名为“GNUmakefile”、“makefile”、“Makefile”的文件,找到了解释这个文件。在这三个文件名中,最好使用“Makefile”这个文件名,因为,这个文件名第一个字符为大写,这样有一种显目的感觉。最好不要用 “GNUmakefile”,这个文件是GNU的make识别的。有另外一些make只对全小写的“makefile”文件名敏感,但是基本上来说,大多数的make都支持“makefile”和“Makefile”这两种默认文件名。
在Makefile使用include关键字可以把别的Makefile包含进来,这很像C语言的#include,被包含的文件会原模原样的放在当前文件的包含位置。include的语法是:
include ; filename可以是当前操作系统Shell的文件模式(可以保含路径和通配符) -
有关例行调度任务 crontab 命令
当用户使用crontab这个命令来新建工作调度之后,该项工作就会被记录到/var/spool/cron里面去了,而且 是以账号来作为判别的
crontab执行的每一项工作都会被记录在/var/log/cron中 -
在Linux系统中,下列哪些方式可以用做进程间通信 管道、信号、套接字、文件锁
-
LINUX中进程在运行时的基本状态包括 就绪状态、执行状态、阻塞状态(注:没有睡眠状态)
-
/ * 最大体积 * @author: William * @time:2022-05-17 */public class MaxVolume {/ * 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可 * * 得到体积的最大可能值 * @param n long长整型 长方形的长宽高之和。长宽高都为质数。 * @return long长整型 */public static long getMaxVolume (long n) { List<Long> zhishu = ZhiShu(n); long res = 0l; for (long l:zhishu) { long ll = n - l; int i=0; int j=zhishu.size()-1; while(i<=j){ if((zhishu.get(i)+zhishu.get(j))<ll){ i++; }else if((zhishu.get(i)+zhishu.get(j))>ll){ j--; }else{ long ress = l*zhishu.get(i)*zhishu.get(j); res = res > ress ? res:ress; i++; } } } return res; // write code here } public static List<Long> ZhiShu(long x){ List<Long> list = new ArrayList<>(); for(long i=1l;i<x;i++){ if(isZhi(i)){ list.add(i); } } return list; } public static boolean isZhi(long num){ if(num == 2 || num == 3){ return true; } // 不在6的倍数两侧的一定不是质数 if(num % 6 != 1 && num % 6 != 5){ return false; } long temp = (long)Math.sqrt(num); // 在6的倍数两侧的也可能不是质数 for(long i = 5; i <= temp; i += 6){ if(num % i == 0 || num % (i + 2) == 0){ return false; } } // 排除所有,剩余的是质数 return true; }} -
/ * 摆放单车 * @author: William * @time:2022-05-17 *//* * 有n辆共享单车,编号依次为A,B,C,... 。现在要将单车整齐摆放, * 其中A车、B车属于特殊车型,并且B车比A车大, * 现要求B车必须摆在A车后,例如A-B-C, A-C-B等,有多少种摆放方法。备注:至少3辆单车。 */public class Bicycle {/* * 深度优先搜索 *DFS进行全排列得到所有的方案, *在生成方案的过程中检查方案是否满足所有A都在B之前 *(只需检查最后一个A是不是在第一个B之前), *同时计数,将满足题意的方案添加进结果字符串。 */static int count = 0; static StringBuilder res = new StringBuilder(); public static void main(String[] args) throws IOException { BufferedReader br = new BufferedReader(new InputStreamReader(System.in)); int n = Integer.parseInt(br.readLine()); String[] bikes = br.readLine().split(" "); permutation(bikes, 0, n - 1); res.append(count); System.out.println(res); } private static void permutation(String[] arr, int start, int end) { if(start == end){ if(isValid(arr)) { count ++; StringBuilder path = new StringBuilder(); for(int i = 0; i < arr.length; i++){ path.append(arr[i]); if(i < arr.length - 1){ path.append("-"); }else{ path.append(" "); } } res.append(path.toString()); } }else{ for(int i = start; i <= end; i++){ swap(arr, start, i); permutation(arr, start + 1, end); swap(arr, start, i); } } } private static boolean isValid(String[] arr) { int lastA = 0, firstB = 0; boolean flag = true; for(int i = 0; i < arr.length; i++){ if(flag && "B".equals(arr[i])){ firstB = i; flag = false; } if("A".equals(arr[i])){ lastA = i; } } return lastA < firstB; } private static void swap(String[] arr, int i, int j) { if(i != j){ String temp = arr[i]; arr[i] = arr[j]; arr[j] = temp; } }}
2020技术支持-1
-
ARP协议 实现的功能是 IP到物理地址的解析
-
针对一个有木马病毒的文件,逆向代码审计 能最全面的了解这个病毒的信息
-
FTP(应用层) 是基于 传输层的TCP 协议进行文件传输
-
FTP 协议控制平面使用的端口号为 21
-
编写文档时不使用宏及相关功能也有可能会感染宏病毒
-
Linux系统中拷贝非空文件夹MyDir到/tmp下并保留原始文件属性的命令是 CP -a MyDir /tmp
-
568A标准线序 白绿、绿、白橙、蓝、白蓝、橙、白棕棕
-
关于计算机系统与操作系统 操作系统是一种软件;计算机是一个资源集合体,包括软件资源和硬件资源;计算机硬件是操作系统赖以工作的实体,操作系统的运行离不开计算机硬件的支持
-
172.10.12.254 不是私有地址
什么是私有地址?如何分类?
在现在的网络中,IP地址分为公网IP地址和私有IP地址。
公网IP是在Internet使用的IP地址,而私有IP地址则是在局域网中使用的IP地址。
私有IP地址是一段保留的IP地址,只使用在局域网中,无法在Internet上使用。
当私有网络内的主机要与位于公网上的主机进行通讯时必须经过地址转换,将其私有地址转换为合法公网地址才能对外访问。
NAT-Network Address Translation 网络地址转换
所谓的私有地址就是在互联网上不使用,而被用在局域网络中的地址
A类 10.0.0.0 --10.255.255.255
B类 172.16.0.0–172.31.255.255
C类 192.168.0.0–192.168.255.2551. A类地址
⑴ A类地址第1字节为网络地址,其它3个字节为主机地址。另外第1个字节的最高位固定为0。
⑵ A类地址范围:1.0.0.1到126.255.255.254。
⑶ A类地址中的私有地址和保留地址:
①10.0.0.0到10.255.255.255是私有地址(所谓的私有地址就是在互联网上不使用,而被用在局域网络中的地址)。
② 127.0.0.0到127.255.255.255是保留地址,用做循环测试用的。
2. B类地址
⑴ B类地址第1字节和第2字节为网络地址,其它2个字节为主机地址。另外第1个字节的前两位固定为10。
⑵ B类地址范围:128.0.0.1到191.255.255.254。
⑶ B类地址的私有地址和保留地址
① 172.16.0.0到172.31.255.255是私有地址
②169.254.0.0到169.254.255.255是保留地址。如果你的IP地址是自动获取IP地址,而你在网络上又没有找到可用的DHCP服务器,这时你将会从169.254.0.0到169.254.255.255中临得获得一个IP地址。
3. C类地址
⑴C类地址第1字节、第2字节和第3个字节为网络地址,第4个个字节为主机地址。另外第1个字节的前三位固定为110。
⑵ C类地址范围:192.0.0.1到223.255.255.254。
⑶ C类地址中的私有地址:192.168.0.0到192.168.255.255是私有地址。
-
LINUX系统查看系统动态进程的命令是 top free 显示内存状态,lastcomm 显示以前使用过的命令的信息
df 报告文件系统磁盘空间的使用情况 -
DLL动态链接库是在程序运行过程中动态载入
-
每个 虚拟局域网 是个 独立的广播域
-
常见的网络安全工具有 wvs, sqlmap, burp
-
一段地址 10.15.10.0/26 有(62)个可用主机地址
-
当数据帧到达交换机时,源MAC地址和传入端口号 信息会记录到交换机的MAC地址映射表中
-
任何两个并发进程之间 可能存在同步或互斥关系
-
一种既有利于短小作业又兼顾到长作业的作业调度算法是 最高响应比优先
-
OSPF里普通区域必须通过骨干区域进行数据传递
-
xss 是一种被动性攻击方式
-
跨站脚本攻击XSS包括 :存储型跨站、反射型跨站、DOM跨站
-
SSL(Security Socket Layer) 使用 对称加密 提供保密性,使用消息认证码提供消息完整性 (个人查找资料是对称非对称加密方式都有)
-
MD5 不能用于文本加密
MD5消息摘要算法,属Hash算法一类。MD5算法对输入任意长度的消息进行运行,产生一个128位的消息摘要(32位的数字字母混合码)。
MD5主要特点:
不可逆,相同数据的MD5值肯定一样,不同数据的MD5值不一样
(一个MD5理论上的确是可能对应无数多个原文的,因为MD5是有限多个的而原文可以是无数多个。比如主流使用的MD5将任意长度的“字节串映射为一个128bit的大整数。也就是一共有2128种可能,大概是3.4*1038,这个数字是有限多个的,而但是世界上可以被用来加密的原文则会有无数的可能性)MD5的性质:
1、压缩性:任意长度的数据,算出的MD5值长度都是固定的(相当于超损压缩)。
2、容易计算:从原数据计算出MD5值很容易。
3、抗修改性:对原数据进行任何改动,哪怕只修改1个字节,所得到的MD5值都有很大区别。
4、弱抗碰撞:已知原数据和其MD5值,想找到一个具有相同MD5值的数据(即伪造数据)是非常困难的。
5、强抗碰撞:想找到两个不同的数据,使它们具有相同的MD5值,是非常困难的。 -
SSL提供 HTTP、FTP、和TCP/IP 协议上的数据安全
-
OpenStack ( 是一系列开源工具(或开源项目)的组合,主要使用池化虚拟资源来构建和管理私有云及公共云 )主要包含的模块 Nova、Swift
-
创建进程必须具备的是:创建进程控制块、为进程分配内存、将进程控制块链入控制队列(注意:但不一定要由调度程序为进程分配CPU)
-
与传统的LAN 相比,VLAN 具有以下优势 :增强通讯的安全性、增强网络的健壮性、用户不受物理设备的限制,VLAN用户可以处于网络中的任何地方、减少移动和改变的代价
-
TCP/IP网络模型有几层?由下至上分别为哪几层?
> 5层,物理层、数据链路层、网络层、传输层、应用层。> 或4层,网络接口层、网络层、传输层、应用层 -
简述OSPF与RIP的区别
RIP&OSPF管理距离分别是:120和110
1.RIP协议一条路由有15跳(网关或路由器)的限制,如果一个RIP网络路由跨越超过15跳(路由器),则它认为网络不可到达,而OSPF对跨越路由器的个数没有限制。2.OSPF协议支持可变长度子网掩码(VLSM),RIP则不支持,这使得RIP协议对当前IP地址的缺乏和可变长度子网掩码的灵活性缺少支持。
3.RIP协议不是针对网络的实际情况而是定期地广播路由表,这对网络的带宽资源是个极大的浪费,特别对大型的广域网。OSPF协议的路由广播更新只发生在路由状态变化的时候,采用IP多路广播来发送链路状态更新信息,这样对带宽是个节约。
4.RIP网络是一个平面网络,对网络没有分层。OSPF在网络中建立起层次概念,在自治域中可以划分网络域,使路由的广播限制在一定的范围内,避免链路中继资源的浪费。
5.OSPF在路由广播时采用了授权机制,保证了网络安全
2020技术支持-2
-
一台物理机可以创建多个docker容器
-
ping 使用的是 ICMP 协议 进行的报文传递
-
DNS 服务使用的是 53 端口号
-
CMD 查看当前系统用户会话命令为 query user
-
进程间的基本关系为 相互独立与相互制约
-
根据《信息安全等级保护管理办法》规定,等保分为 5级
-
DOS攻击包括:Smurf攻击、Land攻击、Teardrop攻击
-
倒叙密码 属于 置换密码
-
在安全威胁较低的情况下,使用包过滤防火墙是因为方便、透明
-
如果想要使用 RAID 5 的磁盘阵列,最少要使用 3 个硬盘
-
中华人民共和国网络安全法》从 2017.6.1 开始施行
-
某公司私网网段地址为192.168.1.0/24,运营商分给企业一个公网IP ,动态端口转换 可以实现所有设备都能访问互联网
-
在可变分区存储管理中,最优适应分配算法要求对空闲区表项按 尺寸从小到达 进行排列
-
Tracert 诊断工具记录下每一个ICMP TTL超时消息的 源IP地址 ,从而可以向用户提供报文到达目的地所经过的IP地址
-
OSRF协议 要求 RID 在同一区域中必须且一旦选取后就是一个稳定状态
-
OFPS:
- 是典型的链路状态协议,对网络变化响应快速
- 同EIGRP一样,网络发生变化时触发增量更新
- OSPF是目前使用最多的路由协议
- 支持VLSM,属于无类的
-
关系型数据模型 的三个组成部分:数据结构、完整性规则、数据操作
-
蠕虫病毒是一种可自我复制的代码,会利用漏洞进行主动攻击,独立性强
-
从用户角度来看,表中存储的数据的逻辑结构是一张二维表,即表由行、列两部分组成,表通过行和列来组织数据。ORACLE的表名和列名都是不区分大小写的
-
在点到点网络中启用OSPF,hello报文发送的目标地址是:224.0.0.5
-
利用交换机进行安全数据收集,交换机数据在X端口,采集器在Y端口,端口镜像可以让采集器收集到有效数据情报;端口映射、端口复用、端口扫描 则都不可以。
-
全双工以太网运行方式 :在全双工模式下不会发生冲突、每个全双工节点都必须有一个专用的交换机端口
-
RSA、DSA 都属于 非对称加密
-
计算机网络 完成的基本功能是:数据处理、数据传输
-
请写出3个IP私网段和1个组播段
10.0.0.0 172.16.0.0 192.168.0.0 224.0.0.2 -
针对一台新的Windows系统主机,在入网前为保证系统更加安全你可以做哪些方面的工作
> 1.设置账户密码 2.本地安全策略优化 3.协议取舍 4.停止不需要的服务 5.优化注册表 6.设置系统防火墙规则 7.安装防病毒软件以及定时升级 8.及时给系统打补丁  开发者涨薪指南
开发者涨薪指南  48位大咖的思考法则、工作方式、逻辑体系
48位大咖的思考法则、工作方式、逻辑体系

