Mybaits源码赏析二:深度解析Mybaits的二级缓存机制
文章目录
前言
Mybaits的缓存是我们在面试中经常遇到的问题,我通宵了两天两夜彻底弄懂了mybaits缓存机制,纯手打,纯原创,希望大家收藏点赞转发一键三连,我将通过源码方面来解析Mybaits的二级缓存,让我们一起吊打面试官。一级缓存稍后更新,关注作者不迷路。
提示:以下是本篇文章正文内容,下面案例可供参考
一、深入了解二级缓存机制
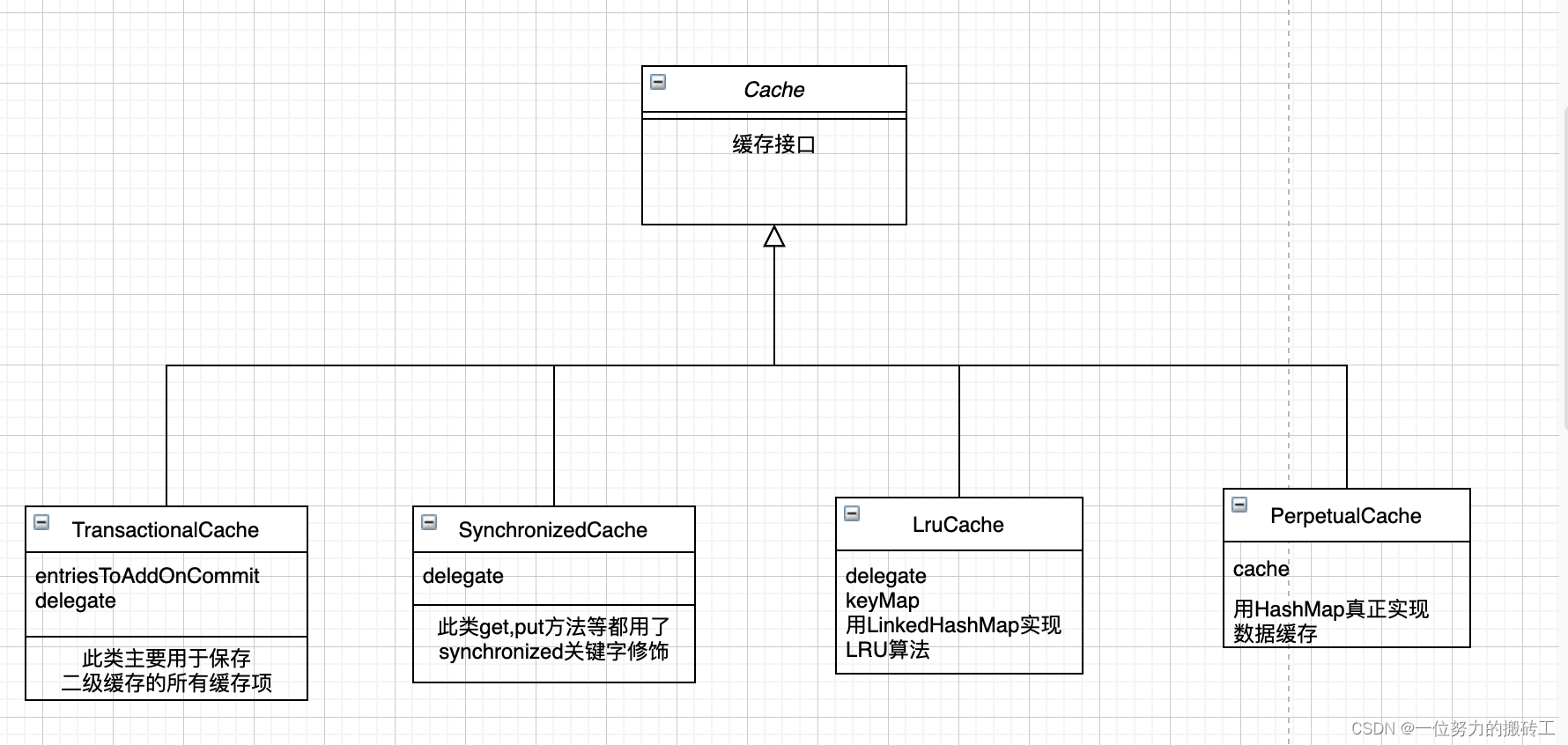
这是默认的二级缓存的实现方式,通过上图不难发现每个实现类中都有一个delegate属性,这个属性的类型就是接口Cache,这里采用了装饰者模式,下面我以注解@CacheNamespace揭开二级缓存的神秘面纱。
问题1: 这个注解是在什么时候被解析到的呢?
1.众所周知,mybaits设计大叔是先将我们的xml配置信息解析到一个configuration,下面这个方法是开始解析一系列标签开构建configuration对象
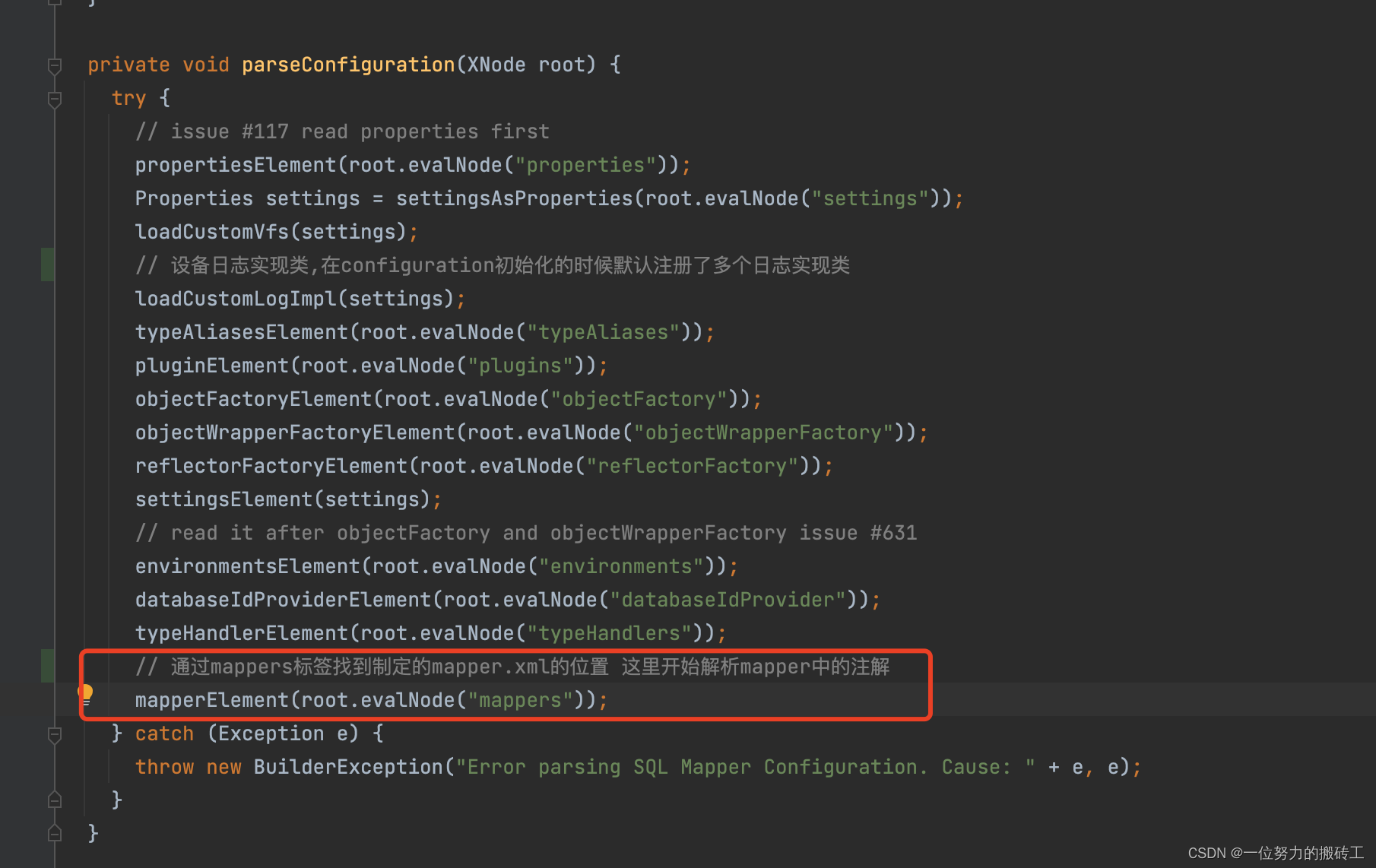
2.从解析mappers标签开始,调用bindMapperForNamespace()开始解析mapper上的标签
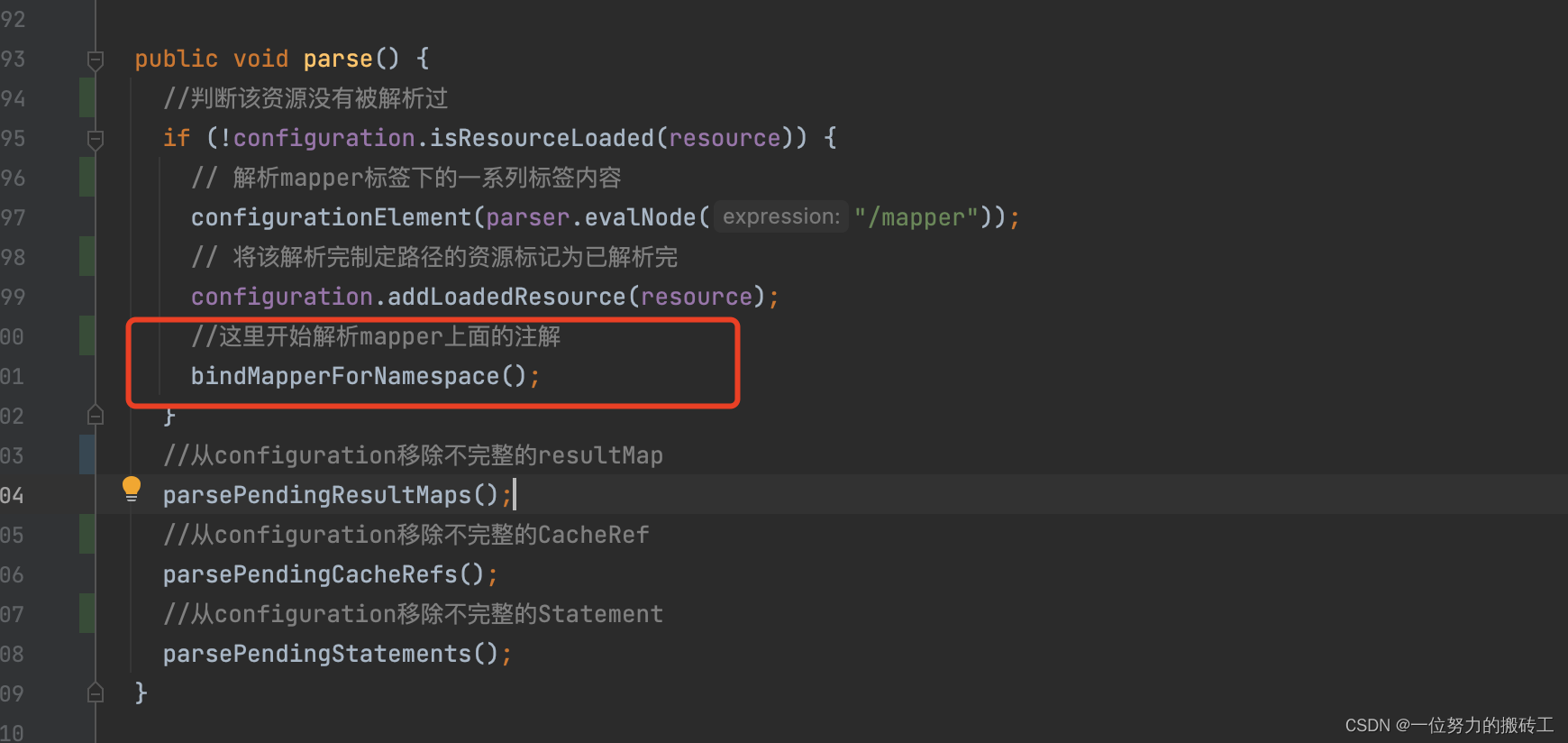
3.调用方法addMapper()开始解析…
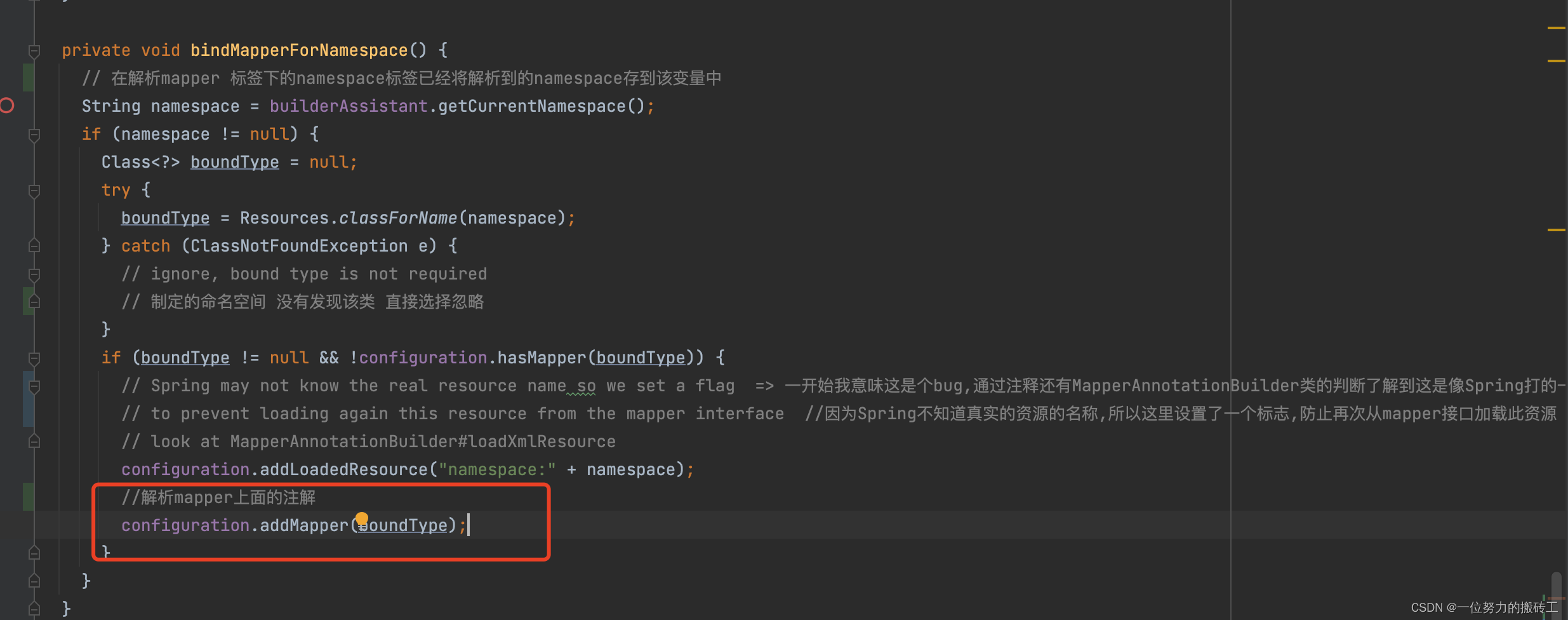
4.先构建MapperAnnotaionBuilder对象,然后调用parse()方法开始解析…
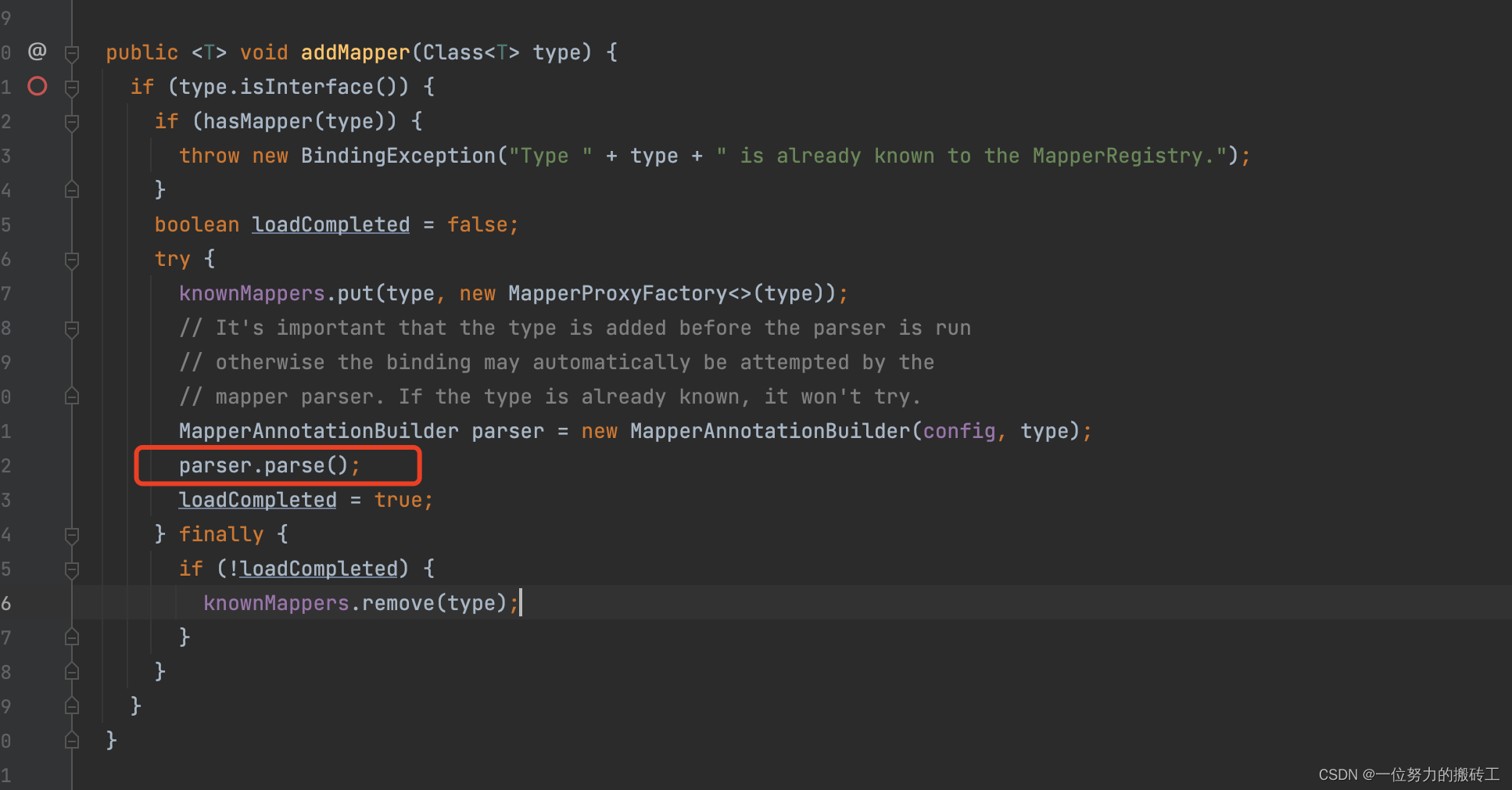
5.解析注解@CacheNamespace
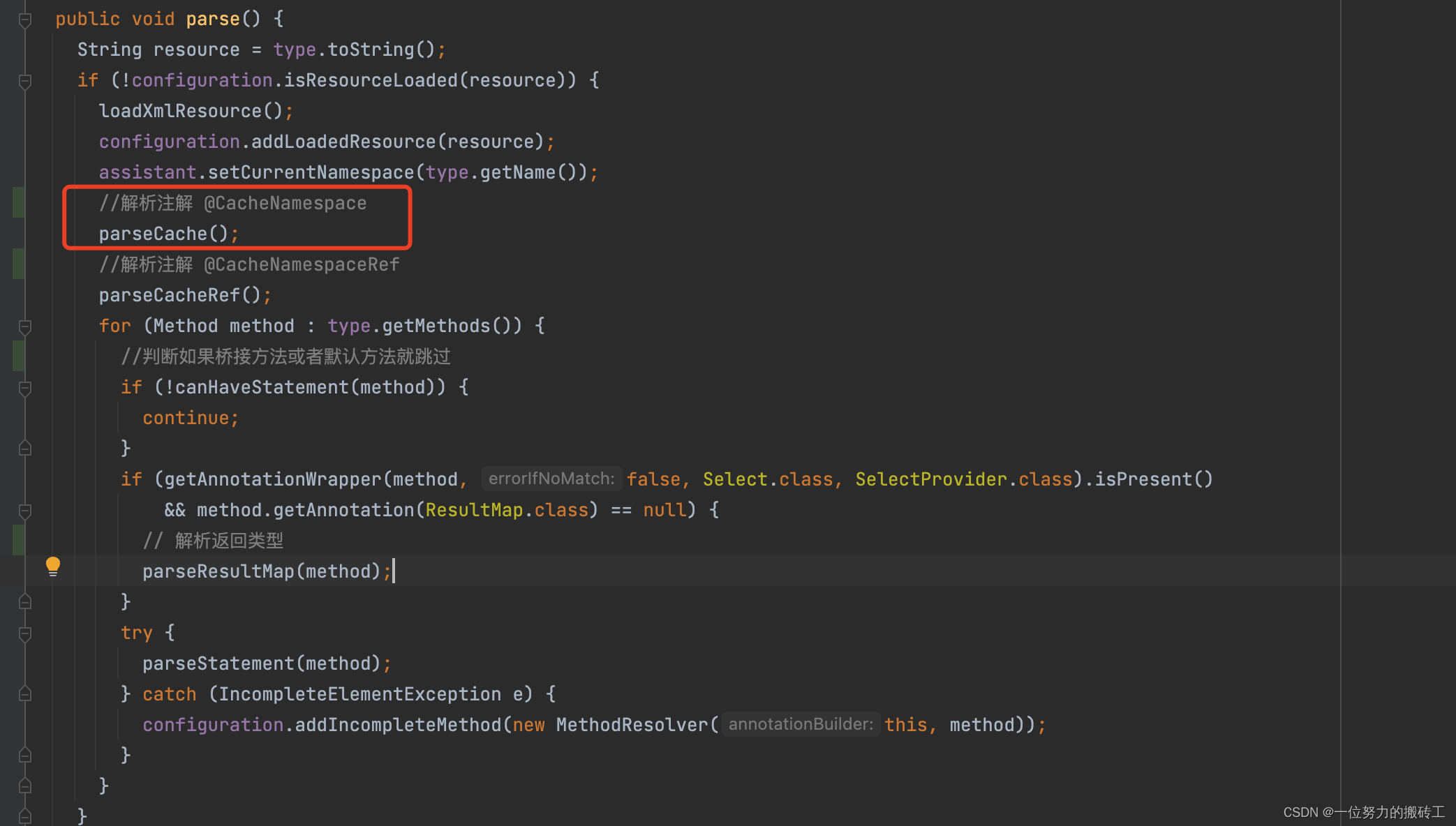
6.解析注解,创建缓存对象
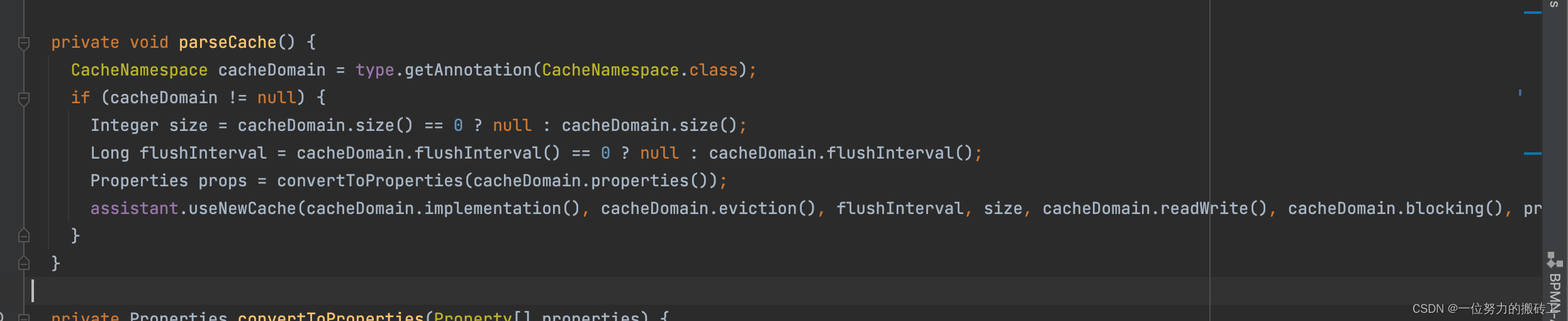
7.构建缓存对象,如果没有指定缓存的实现类默认就是PerpetualCache,默认的装饰者就是LruCache,也就是目前的cache对象是LruCache,里面的delegate(一开始我们说过每个缓存实现类都有此属性)
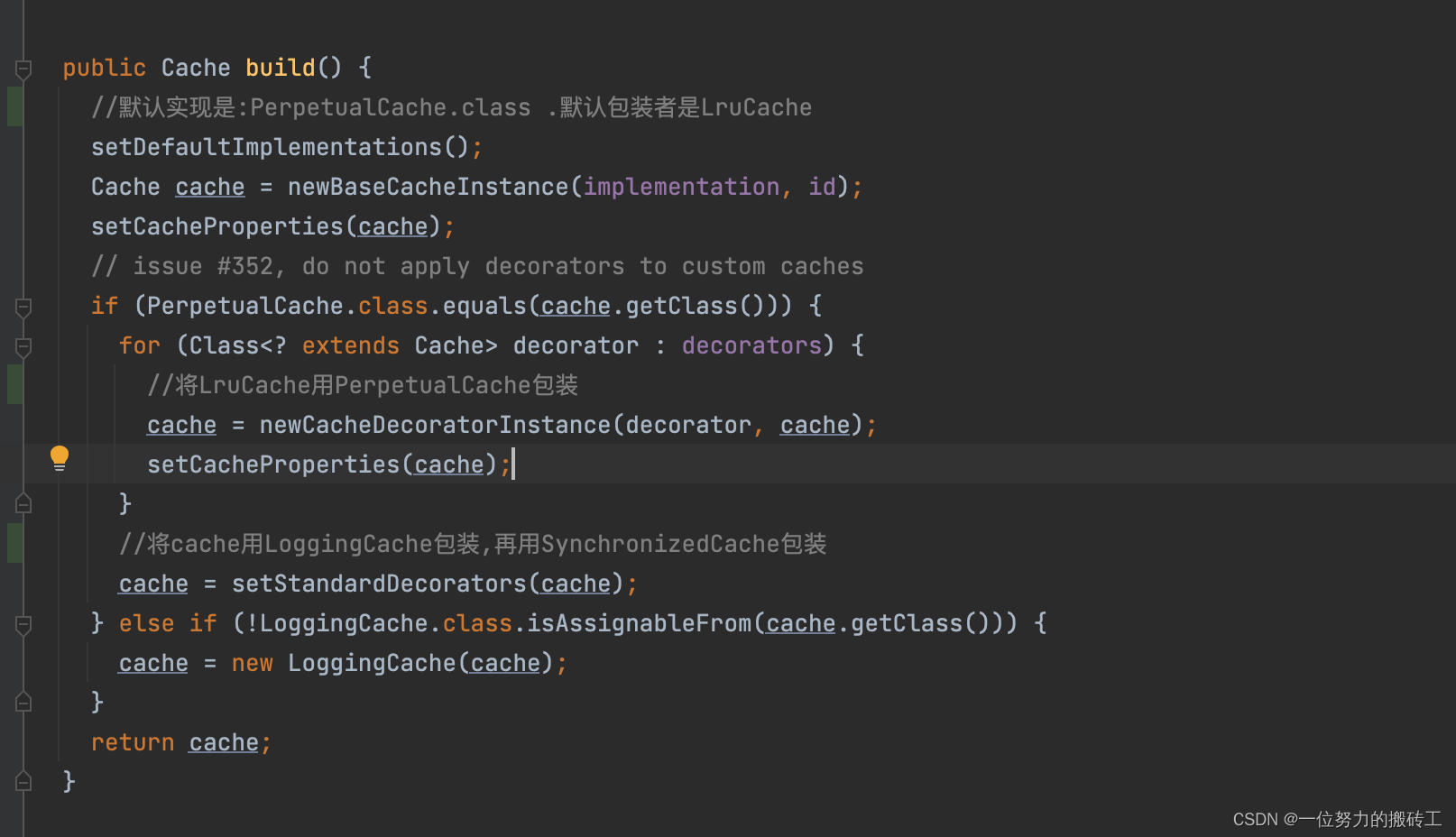
8.接着用SynchronizedCache包装,然后是LogginCache(可记录缓存命中次数),最后返回的cache对象就是SynchronizedCache包装了LogginCache,包装了LruCache,包装了PerpetualCache。至此解析结束。
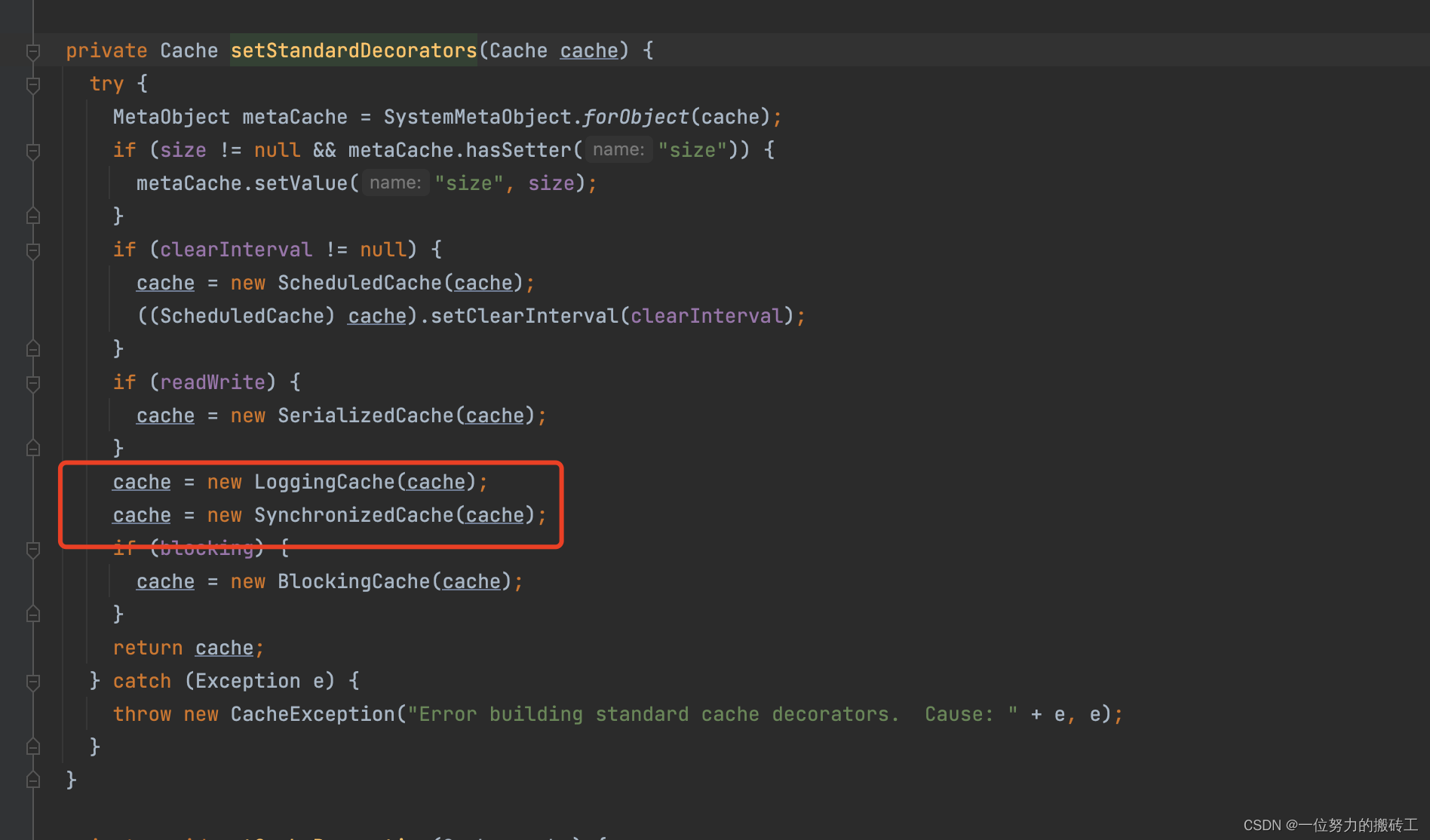
问题2: 这个缓存什么时候用到的呢?
下面我们以一个查询为例。首先,我们在mapper中只定义了接口,那么这些接口的方法是怎么运行的,是通过动态代理的方式生成了mapper的代理类,然后通过Executor执行器去执行query()方法,通过这里我们不难看出二级缓存的范围就是namespace,mapper级别的。
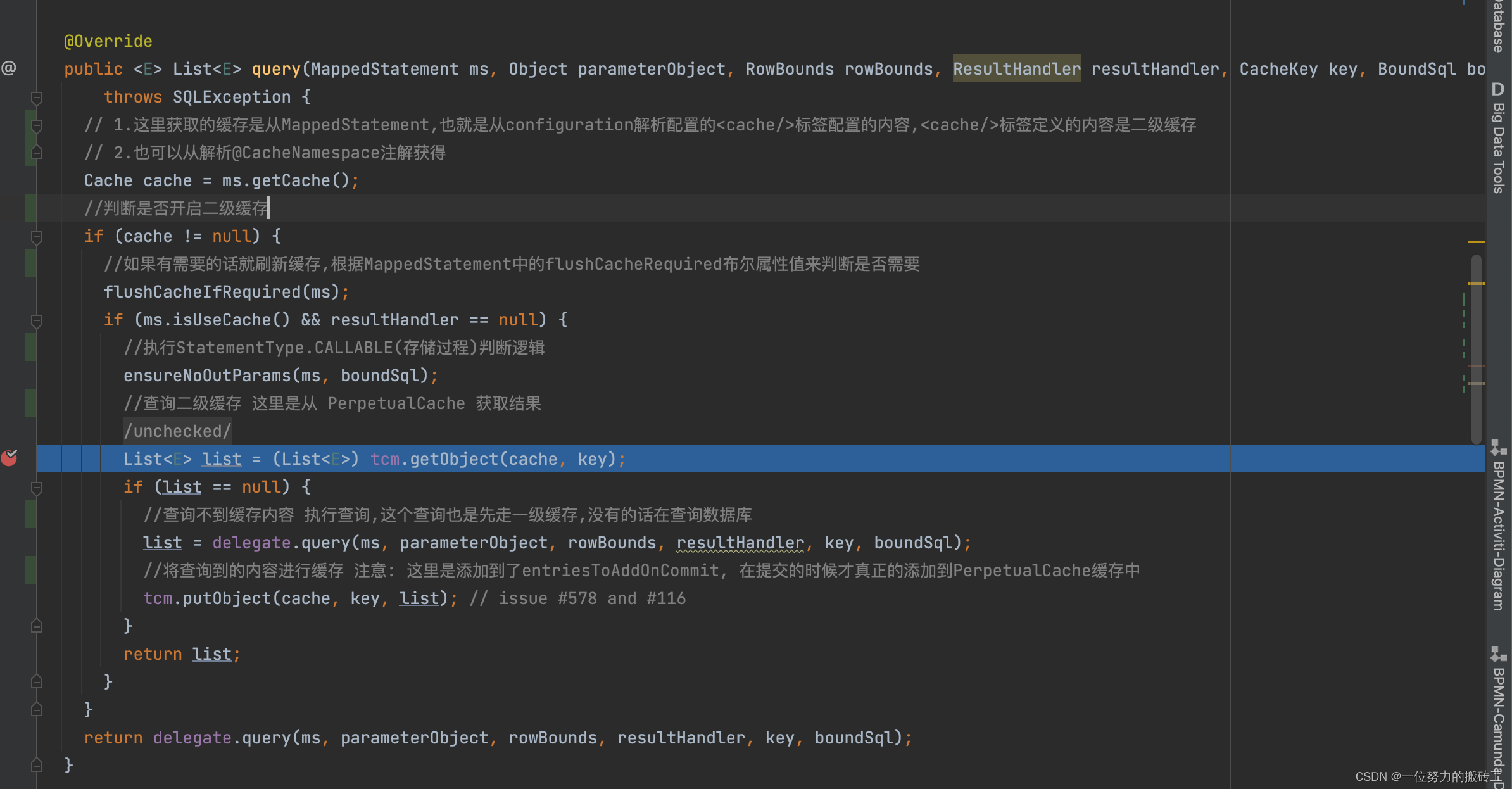
这里的tcm属性指的是TransactionalCacheManager(事务缓存管理器), 默认值就是new了一个新的TransactionalCache,然后调用getObject()方法,那么问题来了??mybaits设计大叔为啥搞个TransactionalCacheManager出来?直接通过定义的Cache类不可以吗?
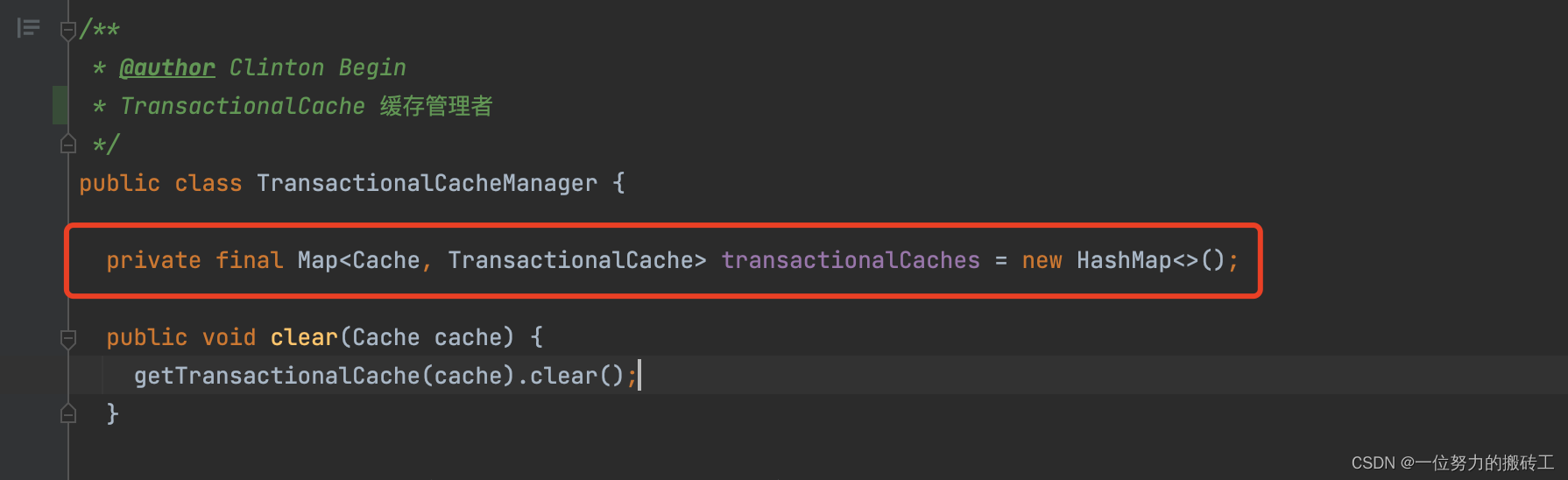
这里通过TransactionalCacheManager,主要是用来通过Map来缓存不同的Cache(实际key的作用)来对应的不同的事务管理缓存(二级缓存默认用的就是事务管理缓存,为啥用他,后面会讲)
然后调用方法getObject():
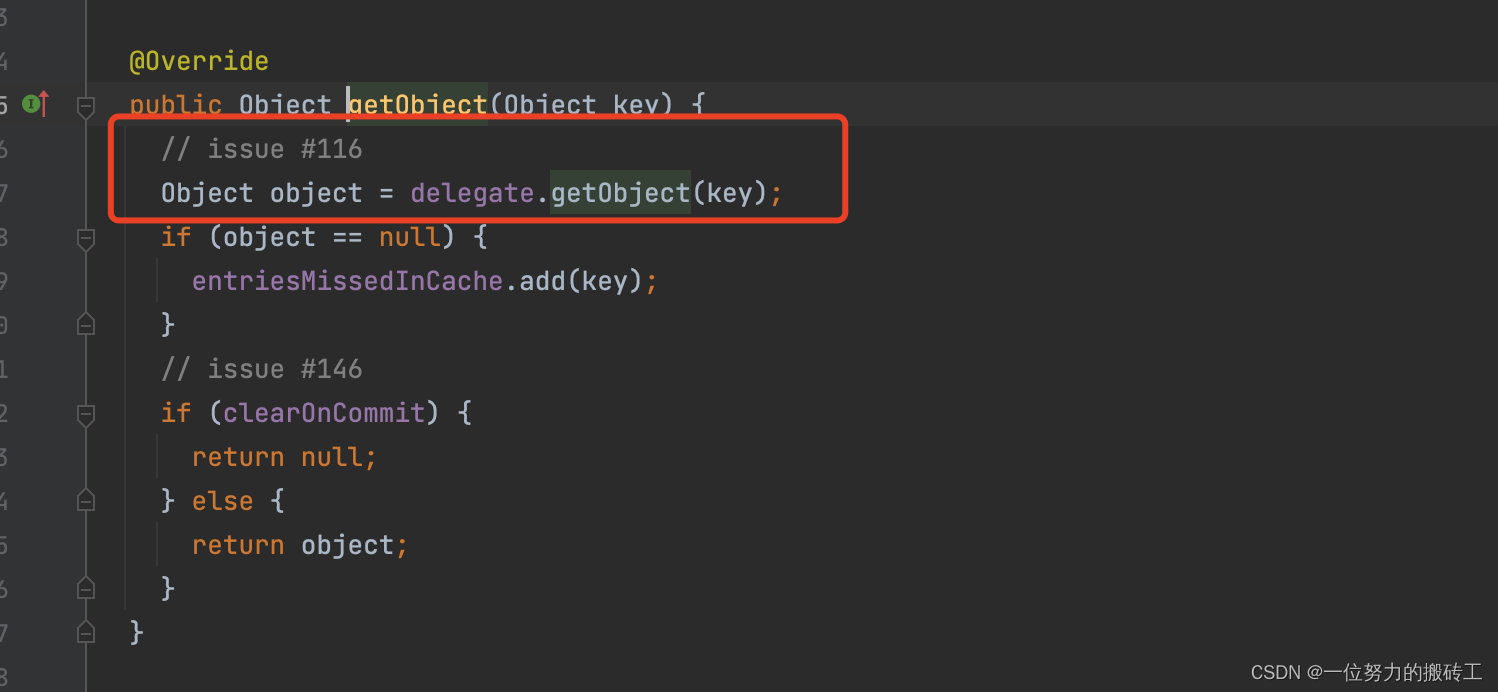
getObject()方法,又调用delegate.getObject(key),重复此方法,这里我们说过,之前缓存的对象是:
SynchronizedCache => LogginCache => LruCache => PerpetualCache,最后PerpetualCache里面的Map对象的数据。
然后将查询的数据添加到了entriesToAddOnCommit(通过字面意思也可以了解到在提交的时候添加)

好了,啥时候提交呢?
当然是在SqlSession关闭的时候:
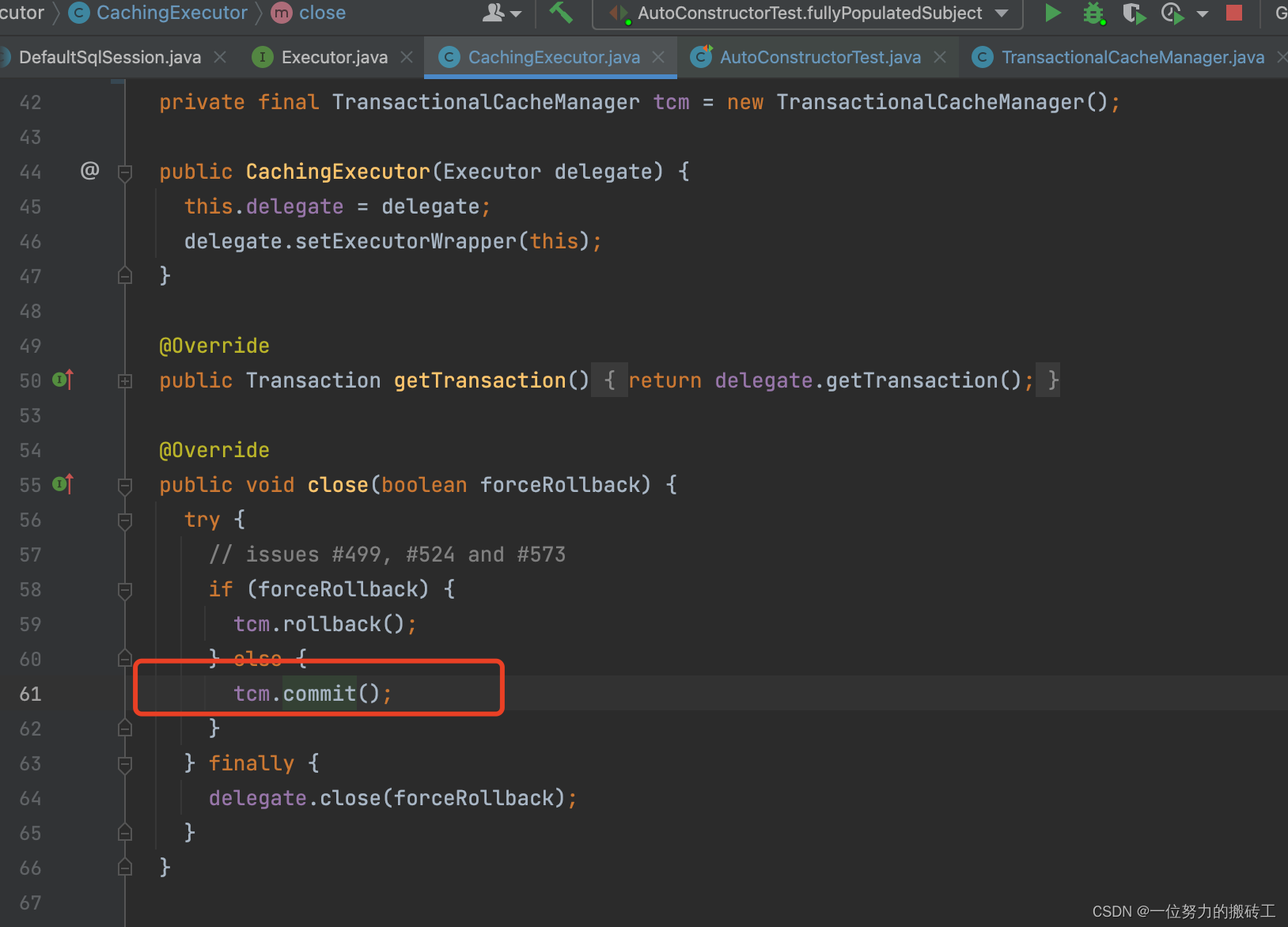
调用方法flushPendingEntries(), 刷新缓存从entriesToAddOnCommit,到真正存储PerpetualCache中
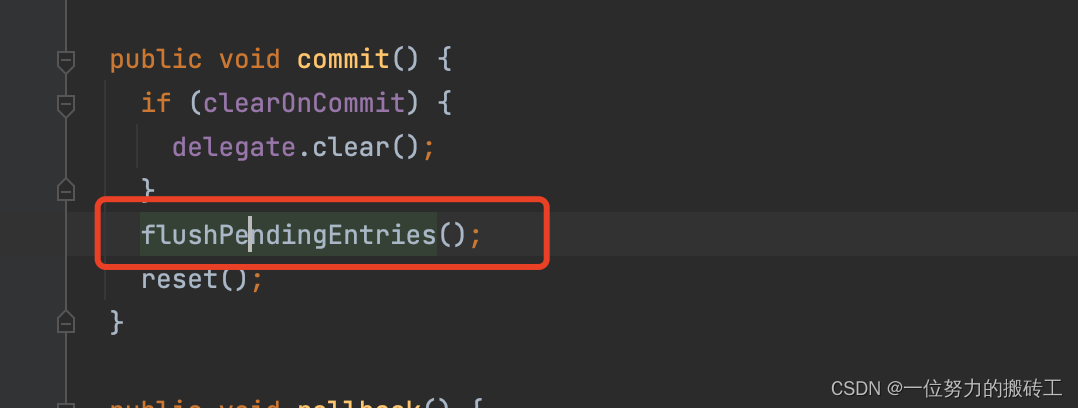
这里的delegate代表的是SynchronizedCache,然后SynchronizedCache => LogginCache => LruCache => PerpetualCache,最后PerpetualCache存到Map里面了。
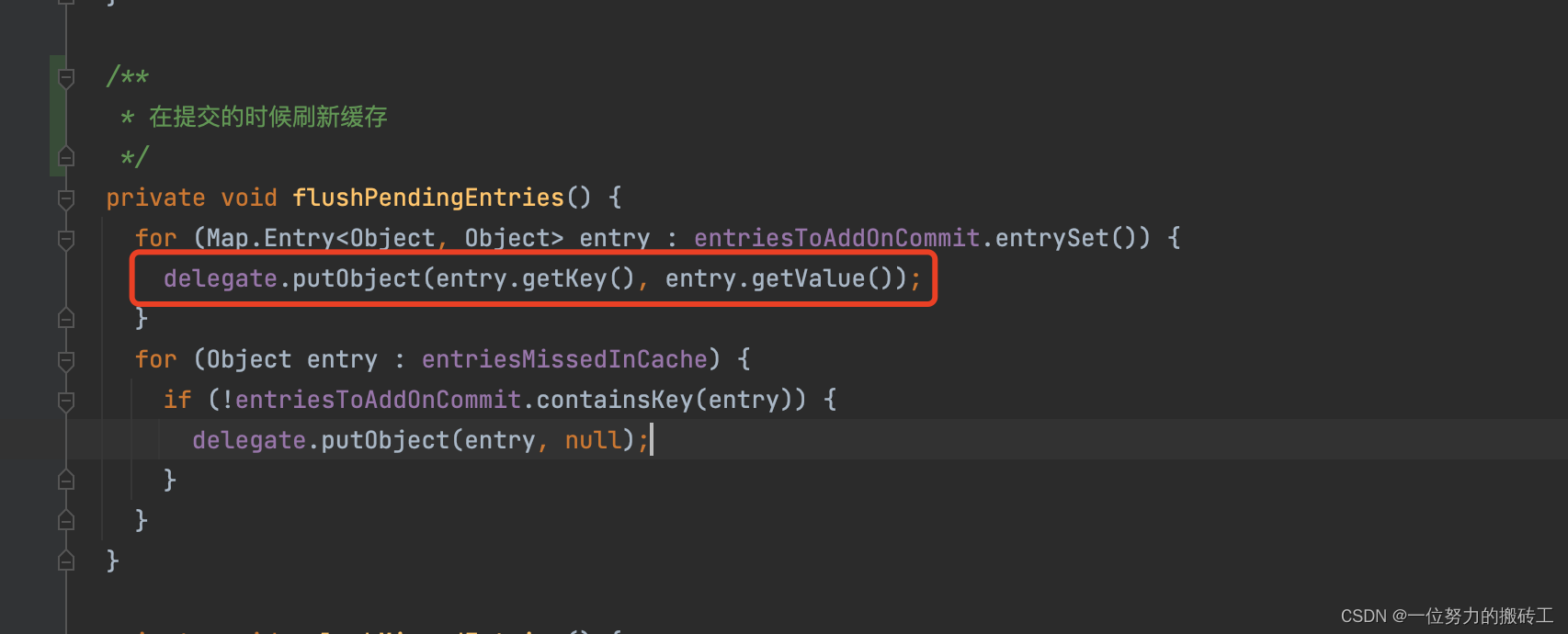
总结下来就是二级缓存是将查询到的数据,先缓存起来,等待提交的时候,然后才真正的使用。
问题3: 二级缓存有啥用??
一级缓存在SqlSession执行完毕,调用close()方法的时候,会被清空。而二级缓存不会在SqlSession关闭的时候被清空,同一个namespace下的缓存信息共用,也就是说二级缓存的生命周期比一级缓存时间更长。二级缓存只有在更新方法的时候会被清空,从这里可以看出mybaits采取的做法显示清空了缓存,然后执行update操作。当然我个人认为这里的刷新二级缓存与更新数据库应该是一个原子性的操作,试想一下一个更新操作在刷新完二级缓存以后,在没有执行更新之前,别的线程先进行了查询,然后往二级缓存里面放值,那么这个时候出现了脏数据。
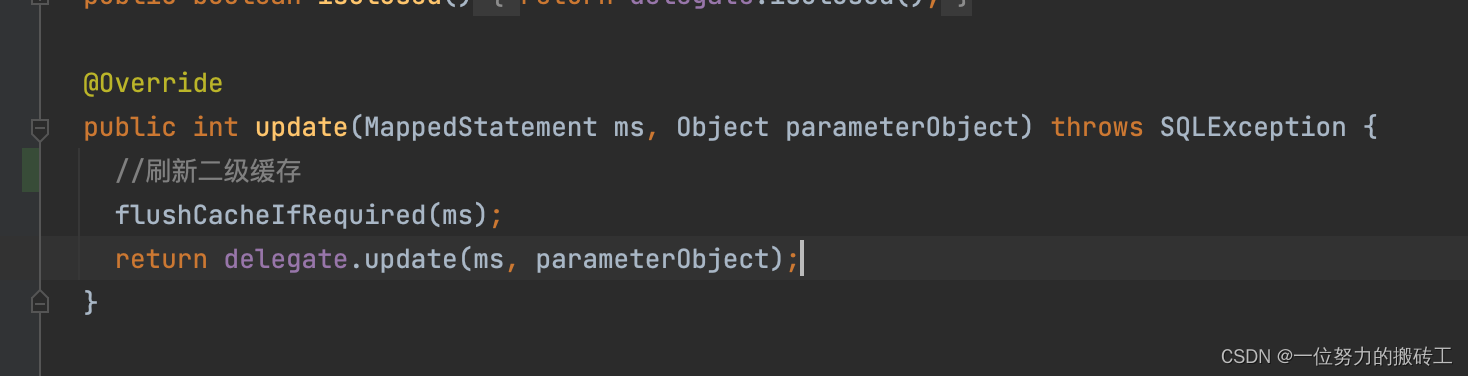
问题4: 二级缓存有啥弊端?
1.首先排除脏数据的问题不说,如果一个namespace下的方法更新方法比较多,那么就不适合用二级缓存,频繁的清空缓存,添加缓存也是比较消耗性能的。
2. 其次,现在我们的环境大多是分布式的环境,而二级缓存的机制是利用了本地Map进行缓存,所以在分布式的环境中必然会出现脏读。试想一下一个程序在两台机器上部署,一台机器更新了数据库的操作,更新了本地的缓存,而另一台没有更新缓存。当再来的请求走了另一台没有更新数据库的机器上时,这时候就出现了脏读的现象。所以说二级缓存形同虚设,非常鸡肋,一般在开发中除非对性能要求特别高的时候会用到,其他不推荐使用。
二、解决方案: 利用redis实现二级缓存
@Slf4jpublic class MybatisRedisCache implements Cache { final static String NAME_SPACE ="mybatis-cache:"; // 这里通过Spring容器获取redisTemplate,进行属性注入 private static RedisTemplate<String, Object> redisTemplate; private static int cacheSec; private final String id; / * The {@code ReadWriteLock}. */ private final ReadWriteLock readWriteLock = new ReentrantReadWriteLock(); public MybatisRedisCache(final String id) { if (id == null) { throw new IllegalArgumentException("Cache instances require an ID"); } log.warn("MybatisRedisCache:id=" + id); this.id = id; } public static void setCacheSec(int cacheSec) { MybatisRedisCache.cacheSec = cacheSec; } public static void setRedisTemplate(RedisTemplate<String, Object> redisTemplate) { MybatisRedisCache.redisTemplate = redisTemplate; } @Override public ReadWriteLock getReadWriteLock() { return this.readWriteLock; } @Override public String getId() { return this.id; } @Override public void putObject(Object key, Object value) { try { log.debug(">>>>>>>>>>>>>>>>>>>>>>>>putObject: key=" + key + ",value=" + value); if (null != value) { if (cacheSec > 0) { // 这里简单起见, 先固定好了缓存的时长 // 也可以尝试 结合 在不同的mapper中指定特殊的缓存时长 // 也可以根据实际业务情况,制定缓存策略 redisTemplate.opsForValue().set(NAME_SPACE + key.toString(), value, cacheSec, TimeUnit.SECONDS); } else { redisTemplate.opsForValue().set(NAME_SPACE + key.toString(), value); } } } catch (Exception e) { e.printStackTrace(); log.error("redis保存数据异常!"); } } @Override public Object getObject(Object key) { try { log.debug(">>>>>>>>>>>>>>>>>>>>>>>>getObject: key=" + key); int size = this.getSize(); if (null != key) { // 这里很坑, 如果选用的redis序列化反序列化的方式不合适,在返回结果后可能会报类转换异常 return redisTemplate.opsForValue().get(NAME_SPACE + key.toString()); } } catch (Exception e) { e.printStackTrace(); log.error("redis获取数据异常!"); } return null; } @Override public Object removeObject(Object key) { try { if (null != key) return redisTemplate.delete(NAME_SPACE + key.toString()); } catch (Exception e) { e.printStackTrace(); log.error("redis获取数据异常!"); } return null; } @Override public void clear() { Set<String> keys = redisTemplate.keys(NAME_SPACE + "*"); if (CollectionUtil.isNotEmpty(keys)) { redisTemplate.delete(keys); } log.debug(">>>>>>>>>>>>>>>>>>>>>>>>clear"); } @Override public int getSize() { Set<String> keys = redisTemplate.keys(NAME_SPACE + "*"); if (CollectionUtil.isNotEmpty(keys)) { return keys.size(); } return 0; }}实现Cache接口,然后在注解中标明:

这样我们就成功用redis替换掉了本地存储的缺陷了。不过还是要慎重使用,有查询多的namespace可以用他来提升效率,更新多的不建议使用。

