Java集合核心知识点整理
文章目录
-
-
- 1.集合思维导图
- 2.List详解
-
- 2.1 ArrayList(工作中常用,面试常问)
- 2.2 LinkedList(工作中基本不会用,面试也不常问)
- 2.3 Vector(几乎淘汰)
- 3.Set详解
-
- 3.1 HashSet
- 3.2 LinkedHashSet
- 3.3 TreeSet
- 4.Map
-
- 4.1 HashMap
- 4.2 为什么要改成数组+链表+红黑树呢?
- 4.2 LinkedHashMap
- 4.3 ConcurrentHashMap
- 4.4 TreeMap
- 4.5 HashTable(基本废弃)
-
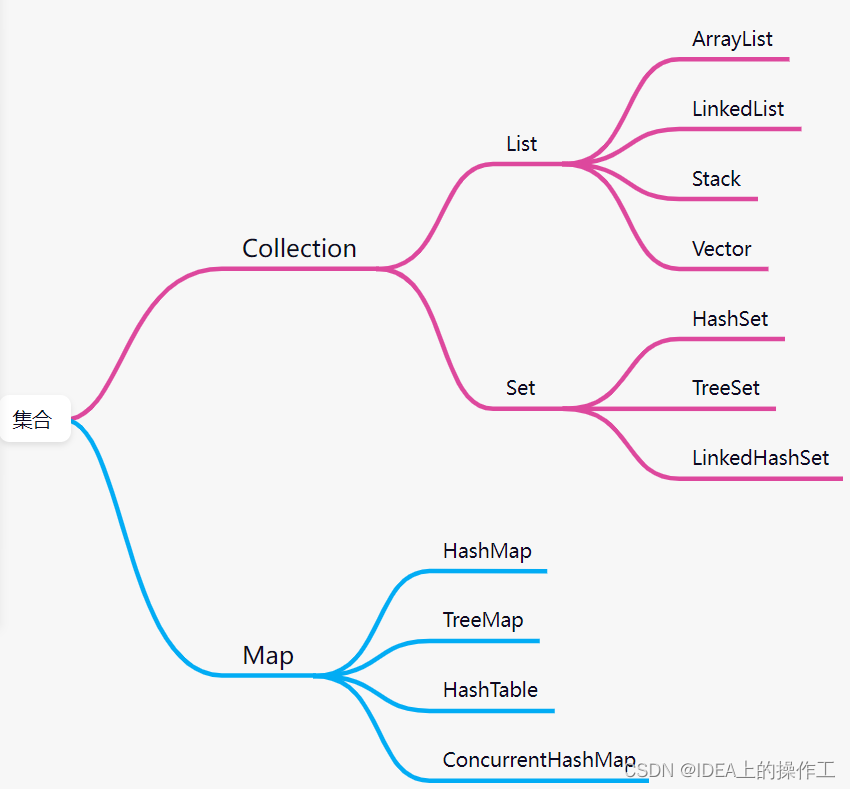
1.集合思维导图
2.List详解
List特点:元素有序,可重复
2.1 ArrayList(工作中常用,面试常问)
简单的分析一下源码(JDK1.8)
一、创建ArrayList
/ * Constructs an empty list with an initial capacity of ten. */ //空参构造函数创建 public ArrayList() { //JDK1.8只是初始化了一个空的Object[]数组,并没有给初始容量10.上面注释是JDK1.7的,官方改了代码没改注释。 this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA; }二、向ArrayList里添加元素
public boolean add(E e) { //判断是否需要进行扩容,此时因为是空数组,所以size是0 ensureCapacityInternal(size + 1); // Increments modCount!! //把元素添加到数组中 elementData[size++] = e; return true; } //此时minCapacity==1 private void ensureCapacityInternal(int minCapacity) { //calculateCapacity 计算容量 ensureExplicitCapacity(calculateCapacity(elementData, minCapacity)); } //计算容量的方法 private static int calculateCapacity(Object[] elementData, int minCapacity) { //如果此时数组是Object[] if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) { //返回10和传进来的参数(1)较大的,此时返回10 return Math.max(DEFAULT_CAPACITY, minCapacity); } return minCapacity; } //此时minCapacity==10 private void ensureExplicitCapacity(int minCapacity) { modCount++; // overflow-conscious code //10-0=10>0,故进入grow方法进行扩容 if (minCapacity - elementData.length > 0) grow(minCapacity); } //此时minCapacity==10 private void grow(int minCapacity) { // overflow-conscious code //oldCapacity ==0 int oldCapacity = elementData.length; //newCapacity ==0 int newCapacity = oldCapacity + (oldCapacity >> 1); //此时0-10<0 if (newCapacity - minCapacity < 0) //newCapacity ==10 newCapacity = minCapacity; if (newCapacity - MAX_ARRAY_SIZE > 0) newCapacity = hugeCapacity(minCapacity); // minCapacity is usually close to size, so this is a win: //把旧的数组复制给新的数组,然后容量是10 elementData = Arrays.copyOf(elementData, newCapacity); }小结:JDK1.8在创建空参的ArrayList时,只是初始化了空数组,没有给初始容量,当第一次调用add()方法时,给初始容量为10,当第11次调用add方法时,才会第二次扩容,扩容至原容量的1.5倍
底层:动态数组
特点:线程不安全、查询效率高,增删效率低
支持快速随机访问:get(int index)
2.2 LinkedList(工作中基本不会用,面试也不常问)
数据结构:双向链表
扩容机制:无需扩容
特点:插入和删除操作比ArrayList效率高,线程不安全
2.3 Vector(几乎淘汰)
扩容机制:按原容量2倍扩容
特点:线程安全,效率低
只是相比ArrayList线程安全,因为其方法都加了synchronized,所以效率低。
3.Set详解
Set特点:元素无序,不可重复
3.1 HashSet
底层是HashMap
特点:线程不安全,可以存null值
HashSet为什么是无序的?
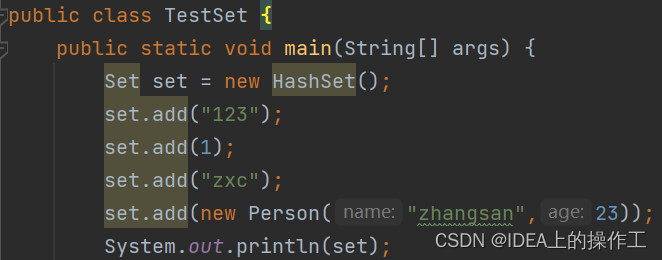

这段代码的输出结果和我们添加的顺序不一致,但这和Set无序并无因果关系。
实际上,我们在add元素时,存储的数据在底层数组中是根据数据的HashCode进行排序的。
HashSet添加元素的过程:当添加元素时,首先会调用元素所在类的hashcode方法,计算此元素的哈希值,此哈希值通过某种算法计算出在HashSet底层数组中的下标,然后看此下标有无值,如果没有,直接插入,如果有,则会调用此元素的equals方法,如果是true,则添加失败,如果false,则添加成功。所以,Hashset是不重复的。
3.2 LinkedHashSet
在原HashSet的底层基础上,加了两个指针,一个指向前一个元素,一个指向后一个元素。
3.3 TreeSet
数据结构:红黑树(平衡二叉树)
特点:确保集合元素是排序状态
排序方法:自然排序(实现Comparable接口)、定制排序(Comparator)
自然排序(实现Comparable接口):
public class TreeSetTest { public static void main(String[] args) { TreeSet<User> set = new TreeSet<>(); set.add(new User("eason",23)); set.add(new User("bill",24)); set.add(new User("jame",17)); set.add(new User("jame",18)); Iterator<User> iterator = set.iterator(); while (iterator.hasNext()){ System.out.println(iterator.next()); } }}@Datapublic class User implements Serializable,Comparable<User> { private String name; private int age; public User(String name, int age) { this.name = name; this.age = age; } @Override public boolean equals(Object o) { if (this == o) return true; if (o == null || getClass() != o.getClass()) return false; User user = (User) o; return age == user.age && name.equals(user.name); } @Override public int hashCode() { return Objects.hash(name, age); } @Override public int compareTo(User u) { int i = this.name.compareTo(u.name); if (i==0){ return this.age- u.age; } return i; }}定制排序:
public class TreeSetTest { public static void main(String[] args) { TreeSet<User> set = new TreeSet<>(new Comparator<User>() { @Override public int compare(User o1, User o2) { int i = o1.getName().compareTo(o2.getName()); if(i==0){ return o1.getAge()-o2.getAge(); } return i; } }); set.add(new User("eason",23)); set.add(new User("bill",24)); set.add(new User("jame",17)); set.add(new User("jame",18)); Iterator<User> iterator = set.iterator(); while (iterator.hasNext()){ System.out.println(iterator.next()); } }}4.Map
特点:双列数据,键值对形式
4.1 HashMap
数据结构及添加元素过程:
JDK1.8之前:数组+链表。使用Entry数组来存储key-value,每一个键值对组成了一个Entry实体,Entry类实际上是一个单向的链表结构,它具有next指针,指向下一个Entry实体,以此来解决Hash冲突的问题。HashMap实现一个内部类Entry,重要的属性有hash、key、value、next。
通过hash值找到当前元素存放的位置,如果位置上有值,则比较hash值和key值,如果hash值和key都相同,则直接覆盖。如果不同,则将要插入的数据加到链表中。
JDK1.8之后:数组+链表+红黑树。当链表长度大于阈值(默认为8)时,判断当前数组的长度是否小于64,如果小于64,先进行数组扩容,大于等于64,将链表转换为红黑树,为了减少搜索时间。
特点:线程不安全,效率高,可以存null键和null值,key不能重复,value可以重复。
扩容机制:
JDK1.8无参构造时,不再给定默认容量16,只初始化了加载因子等于0.75,当第一次put时,创建长度为16的数组,数组类型是Node[],之后按2倍扩容。
有参构造时,根据传入的容量计算一个大于等于该容量的最小的2的N次方。例如:传3,容量为4,传4,容量为4,传5,容量为8…之后按2倍扩容。
4.2 为什么要改成数组+链表+红黑树呢?
为了提升当发生hash冲突严重时,链表过长,查找性能低。
4.2 LinkedHashMap
在原有的HashMap底层结构上,添加了一堆指针,指向前一个和后一个元素,对于频繁的便利操作,效率高于HashMap。
4.3 ConcurrentHashMap
特点:线程安全
4.4 TreeMap
数据结构:底层是红黑树
特点:按照添加的key-value进行排序
4.5 HashTable(基本废弃)
特点:线程安全,效率低,不能存null键和null值
默认值是11,扩容为2倍+1

